これは何
GraphQLも10歳になりました。
今や定番のAPIスタイル?になったGraphQLの世界は広く、数多くの用語・知識・ツールがあります。

この記事は、細かい実装やテクニックの話を脇に置いて、GraphQLとは何者なのか、その世界にはだいたい何があって、それらはどんな役割を持っているのか、広い視点で語ってみる試みです。
まず誕生の歴史を振り返り、今のGraphQL世界を概観し、最後に今後の見通しに進みます。
創世記
聖典 REST
GraphQLが生まれる前、Web APIたちはみな、RESTという設計原則に従って作られていました。
この原則を深く理解しているか、一字一句従うかはさておき、APIを作るのにRESTを考えないという人はいませんでした。
結果として、ほとんどのAPIはこのような形になっていました
- データをリソース(ユーザー・惑星・食べ物etc...)という小さな単位に切り分ける
- 各リソースを専用のURIで公開する https://api.com/planets/jupiter
- リソースへの要求を以下の形で受け付ける
- HTTPメソッド・・・要求の種別。
GETは取得 /POSTは更新 など - HTTPリクエストボディ・・・付加情報。 key=value式のシンプルな文字列
- HTTPメソッド・・・要求の種別。
GET https://api.com/animals/wombat //ウォンバットのことが知りたい
DELETE https://api.com/planets/pluto //惑星の冥王星を消滅させたい
POST https://api.com/planets
name=deathStar&diameter=100 //直径100kmのデス・スターを追加したい
HTTPの機能を素直に生かした、シンプルな設計です。
それもそのはず、RESTを最初に考えた人は、HTTPの主要な作者でもありました。
この原則のおかげで、特別なライブラリや知識がなくとも、世界のどこのAPIでも呼び出すことができました。
RESTの限界
長年のデファクトスタンダードだったRESTへの挑戦は、2013年、Facebookで起こります。
RESTなAPIでiOSアプリのニュースフィードを作っていたエンジニアたちは、以下の2つの問題で行き詰まっていました。
問題1 : 通信の多さ
Facebookのニュースフィードでは、
投稿→その投稿のコメント→そのコメントした人...
と、芋づる式に何層ものデータを取得する必要があります。
RESTなAPIでは「投稿」「コメント」「ユーザー」は別のURIで公開するので、
このように何往復も通信することになります。
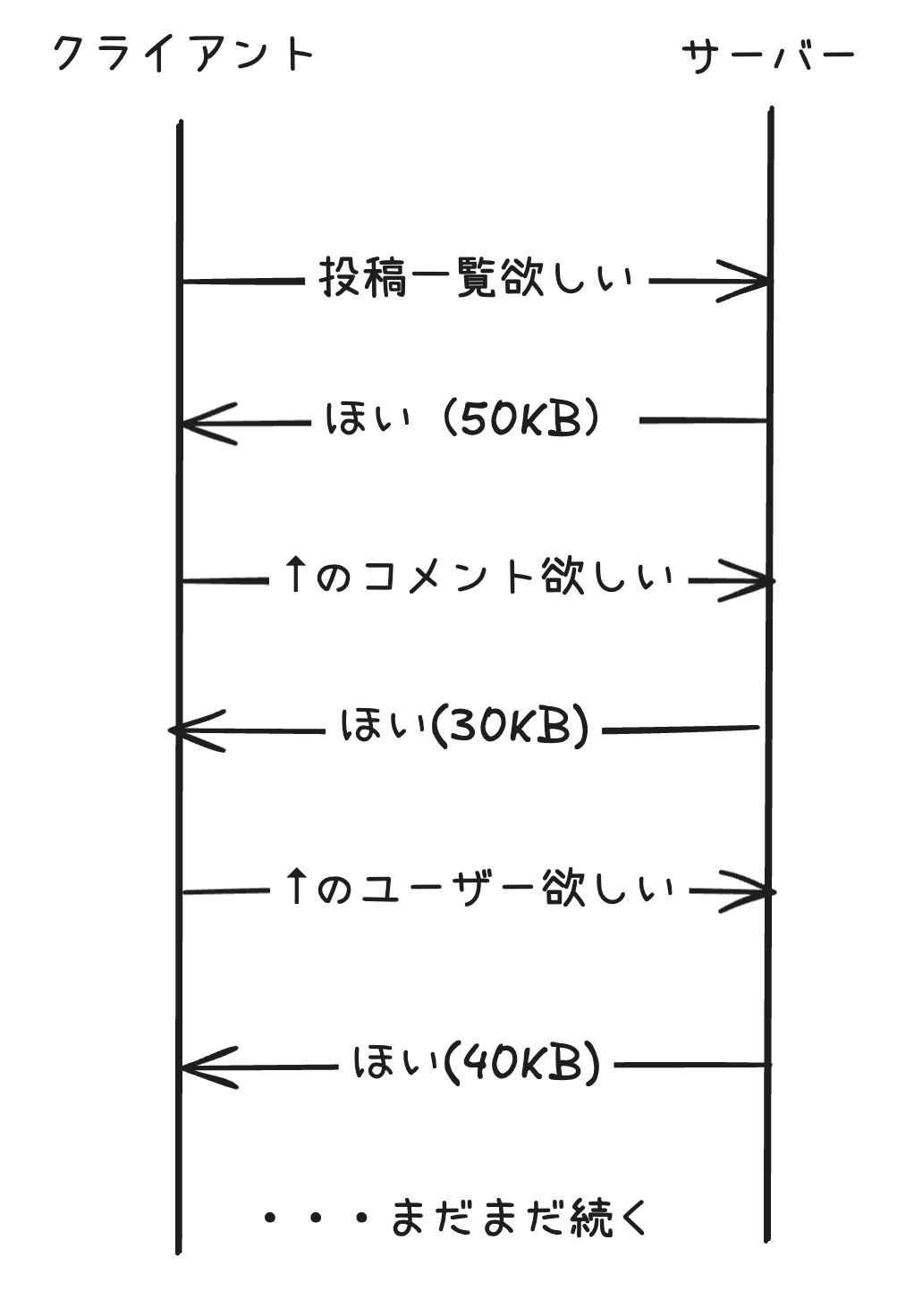
また、要求はリソース単位ですから、レスポンスには不要なデータもたくさん含まれます。
erikaさんのプロフィール画像が欲しくて/user/erikaを叩いても、erikaさんの全データ...名前、誕生日、出身地、趣味...が入った長い返答が帰ってくるわけです。
これらはRESTの定めた通りの挙動であり、そのためにアプリは悲しい遅さを発揮していたのでした。
問題2 : APIとクライアントの同期の難しさ
当時、APIの仕様ドキュメントと実装、それにAPIを利用するクライアントの間に、システム的な繋がりは何もありませんでした。それらを一致させるのは開発者たちの仕事です。
APIに変更を加える時、少しドキュメント更新をサボったりクライアントへの相談を忘れれば、アプリは簡単に壊れます。
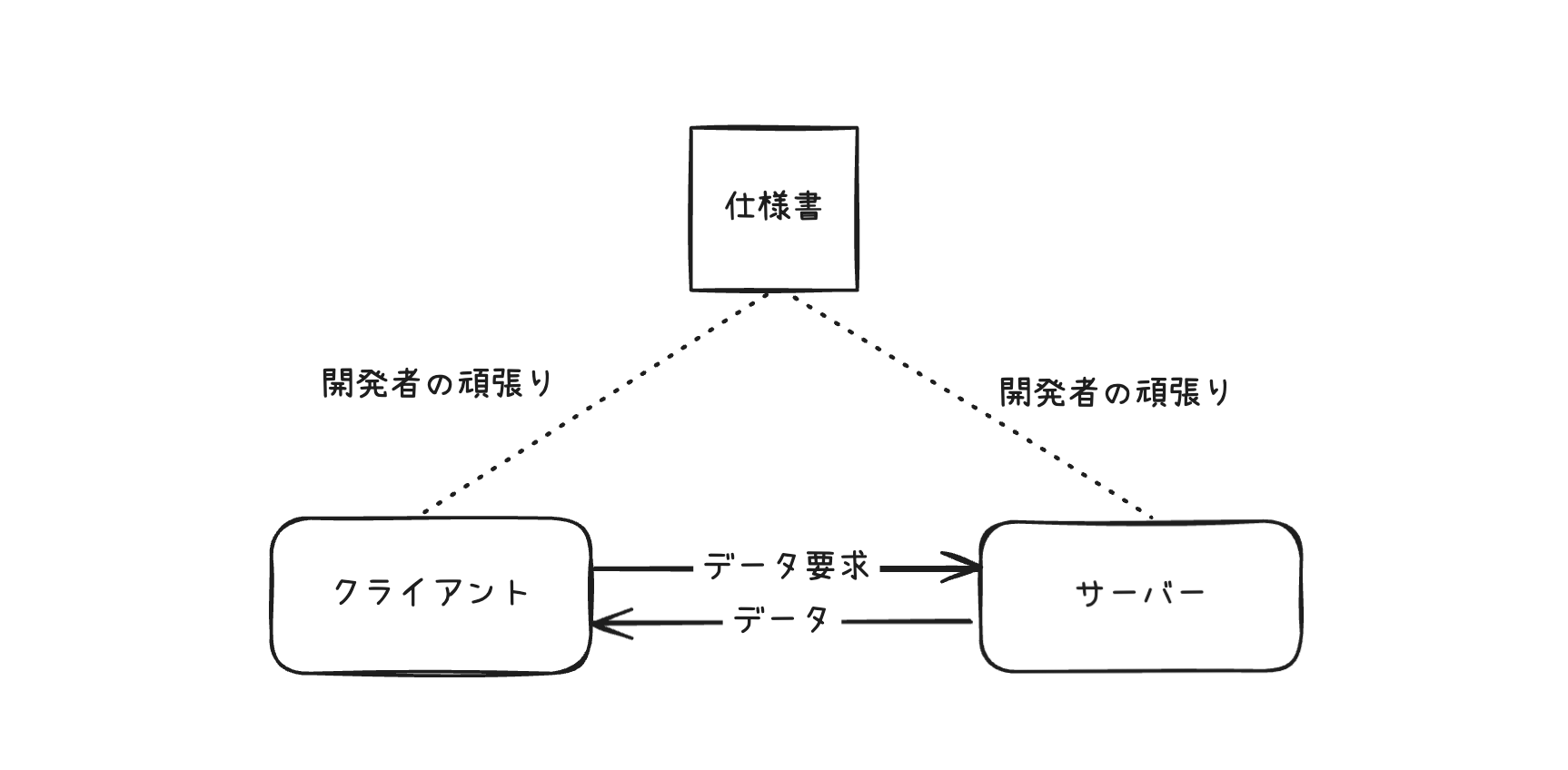
RESTはこの問題の原因ではありませんが、特に助けてもくれません。
そのためにアプリ開発は慎重にゆっくり進まざるを得ませんでした。
破戒の新システム
今までのAPI作りの限界に直面したエンジニアたちは、RESTに従わない画期的な新システムを自作します。
まず、全データの型を型ファイルに定義し、関係者が見られるサイトで公開しました。
次に前代未聞のAPIを作りました。
- URIは1つだけ
- メソッドはPOSTだけ
- 要求はリクエストボディーに、専用の新言語で書く
- 自分が型ファイル通りの返答ができることを、開発時にチェックする
- クライアントから型ファイルに合っていない要求が来ればエラーを返す
POST https://api.com/the_only_path
"????????" //要求(誰も読めない新言語)
最後に、このAPIと通信する専用ライブラリを作り、クライアントに配布しました。
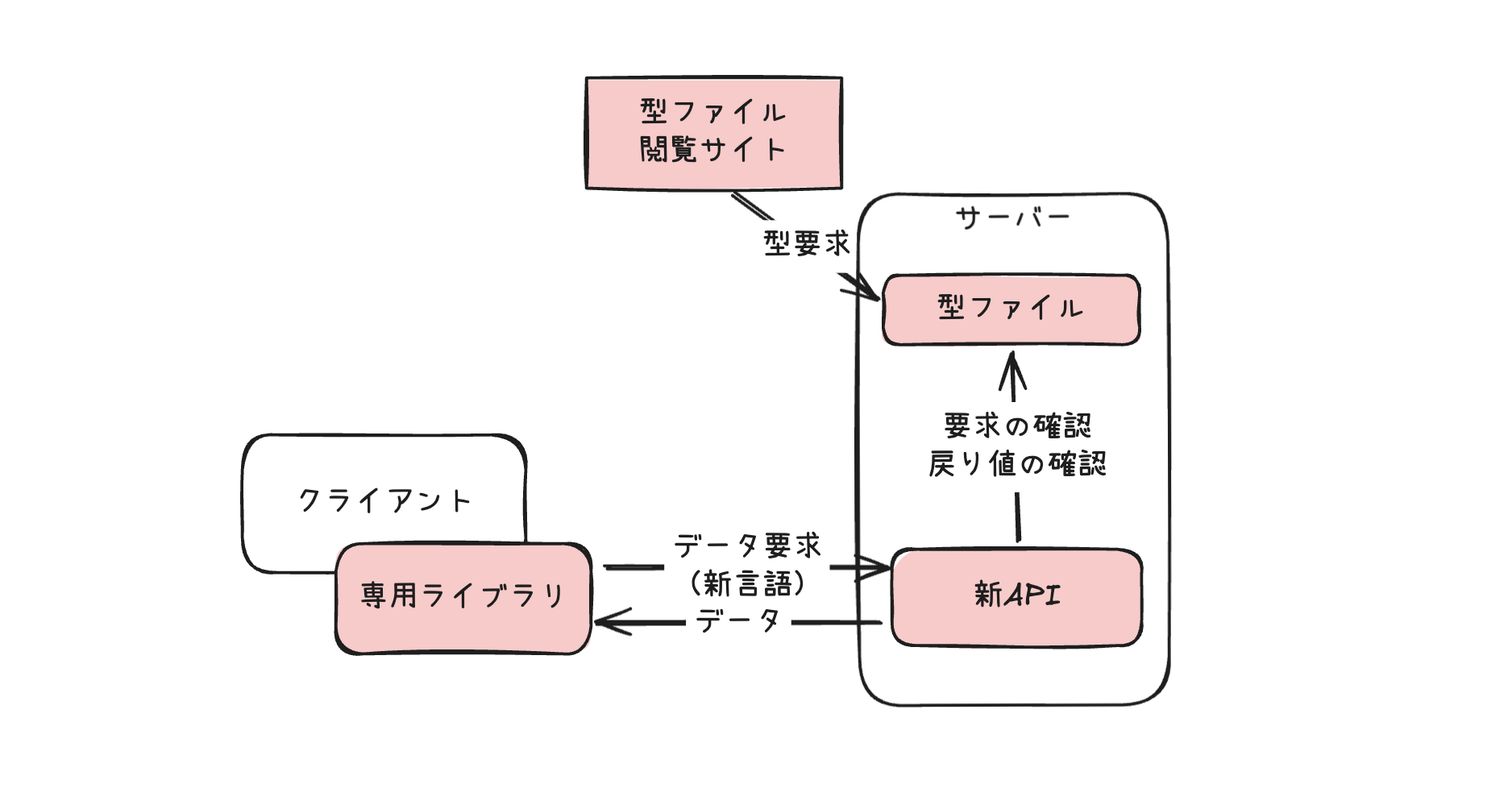
新システムは先ほどの困りごとを綺麗に解決しました。
第一に、最適なデータを1リクエストで取得できるようになりました。
新言語と新APIのペアはリソースという単位に縛れられません。
要求には「奈良公園の鹿の数と、ディズニーランドの鼠の数が知りたい」といったようにクライアントの欲しいものをいくつでも正確に記述でき、APIもそれに答える力を持ちますから、データ量は必要最低限になりました。
また「投稿と、その投稿についたコメントと、そのコメントをした人のプロフィール画像を下さい」といった芋づるのデータ要求も可能だったため、通信は一往復になりました。

第二に、データ型の一致をシステム的に保証することで、開発が安全で速くなりました。
皆で相談して型ファイルさえ決めれば、自動的に仕様書のようなページが公開され、サーバーとクライアントのコードも型通りなことがシステム的に保証されます。
動物型 {
体重 : number
名前 : string
}
と書き込めば、
API側で動物の名前を返し忘れるコードを書いたり、またはクライアント側で存在しない「動物の調理法」を要求するコードを書いた時にすぐ警告が出るわけです。
このシステムは大成功しました!
APIサーバーは、芋づる式に繋がったデータ=グラフを扱う新しいデータ要求言語(Query Launguege)を使うことにちなんで、GraphQLと名付けられました。
クライアントライブラリはRelayと名付けられました。
新世界の神となる
数年が経ちました。
Facebookの中核として定着したGraphQLは、講演や記事で紹介され、同じ悩みを抱えていた開発者たちに称賛されていました。
同じくFacebookから生まれたReactは数年前にオープンソース化され、すでにWEB界隈有数の人気者に育っていました。GraphQLも先輩に続けば、みんなにちやほや育ててもらえるでしょうか?
しかし悲しいかな、GraphQLはPHPプログラムでした。
フロントエンドのライブラリであるReactはWEB開発者なら誰でも候補に入れられますが、
サーバーのPHPプログラムであるGraphQLを使える人は限られます。よりによってPHPです!
そこで、GraphQLの飼い主たちは画期的な公開方法を思いつきます。
Reactと比べれば、GraphQLは実装として巨大なものではありません。皆に褒められているのは考え方と設計でした。
ですから、GraphQLの「仕様」...
- クエリ言語
- 型ファイルの言語と使い方
- サーバーの応答の仕方
...などを書き起こし、その文書をオープンソース化したのです。
まず仕様さえ良ければ、言語ごとの実装などは誰かがやってくれるというわけです。
はたして、OSSならぬ「オープンソース仕様」となったGraphQLは大ヒットしました。
半年も経たずに有名な言語での実装が揃いました。
Relayに続くクライアントライブラリや、他のGraphQL開発の補助ツールも作成され始めました。1年後にはGitHubがGraphQL APIを一般公開し、数年以内には大きなサービスが次々に本番採用していくことになりました。
1つの社内システムに過ぎなかったGraphQLは、有名な仕様に転生し、RESTから独立した1つの世界を作ったのでした。
GraphQLワールドマップ
今日、狭義のGraphQLは、
- クエリ言語仕様
- スキーマ言語仕様
- APIサーバー仕様
の3つのセットです。これらはGraphQL財団の管理のもと、GitHubのレポジトリでオープンソースに開発されています。そしてこの仕様を中心に、ライブラリや専用ツールの世界が広がっています。
ここからは、現在のGraphQL世界を俯瞰してみましょう。
ランタイム
アプリケーションが動作している時の登場人物です
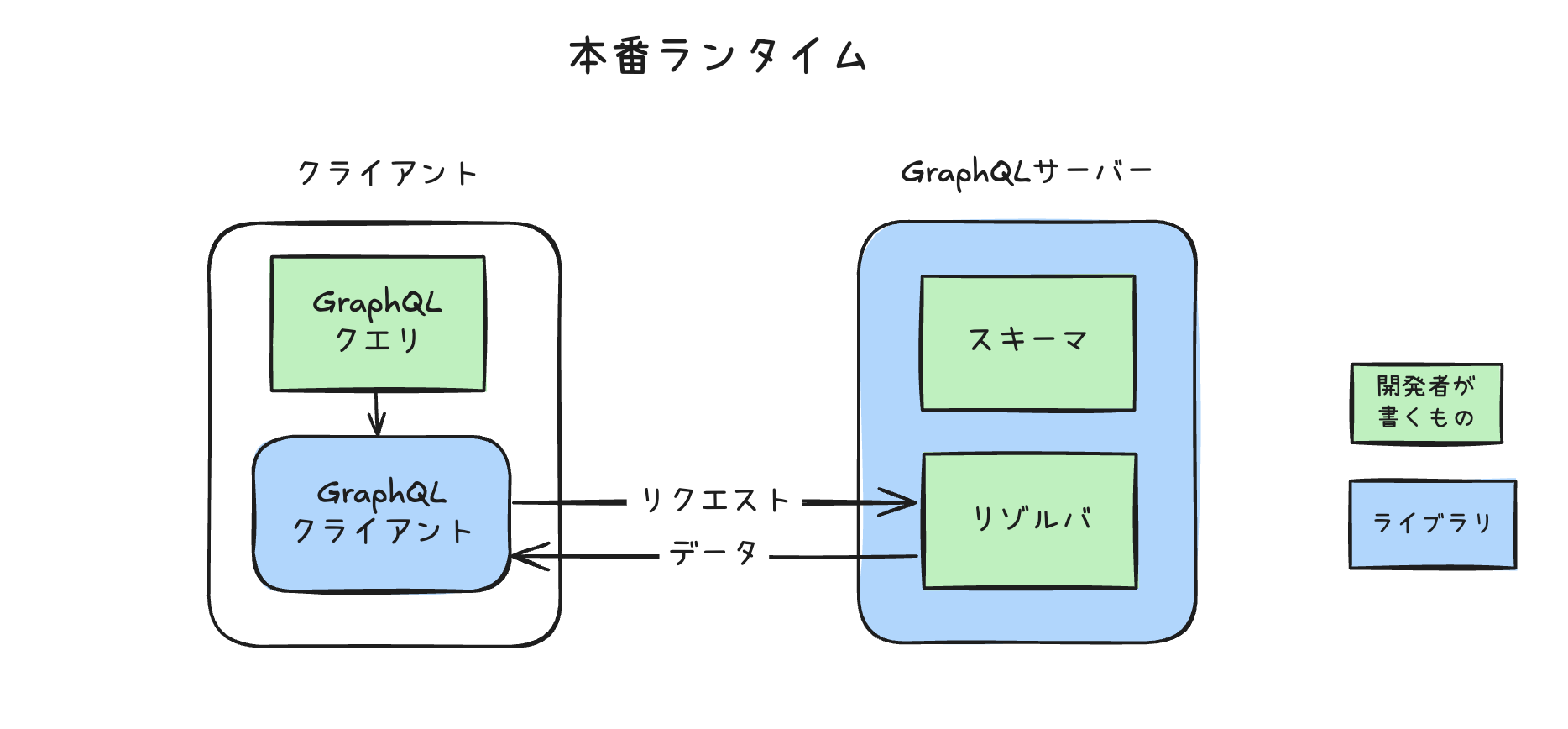
スキーマ
「型ファイル」の正式名称。GraphQLサービスの全要素に参照される聖典となります。
GraphQLスキーマ言語という独自の言語で記述します。(TypeScriptに似ていますが赤の他人です)
スキーマが定義しているのは
- 単一の値の型(文字列・数字・ENUM etc..)
- 値の集合体であるオブジェクト
- オブジェクトとオブジェクトのリンク
がグラフ状に繋がった、全データをカバーする型のネットワークです。
type Schedule {
movies: [Movie!]!
}
type Movie {
title: String!
actors: [Person!]!
}
type Person {
name: String!
birthday: Number!
}
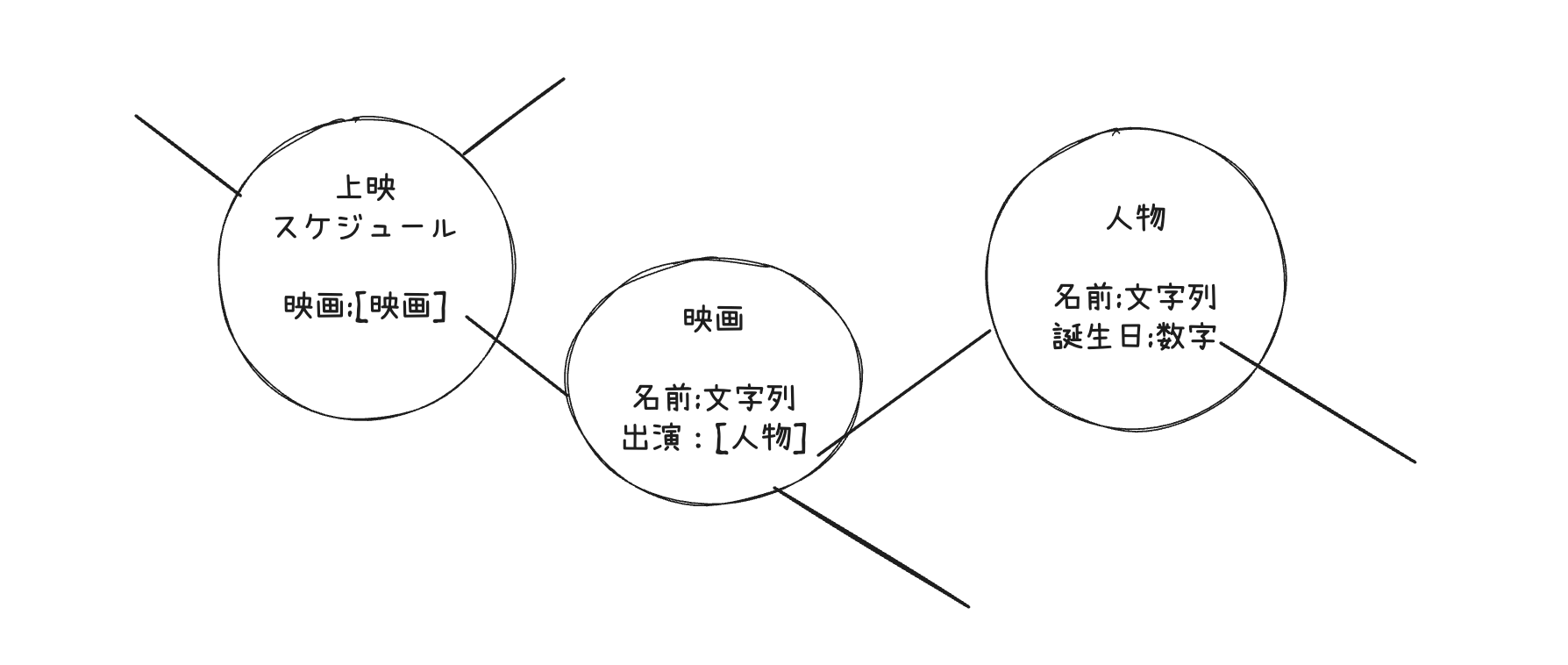
開発者が直接スキーマ言語で記入することもあれば、
他言語で書いた型をライブラリの機能でスキーマに変換することもあります。
リゾルバ
GraphQLクエリを受取り、データを返す関数です。
背後にあるファイル、DB、他のAPIなどからデータを引き出し、スキーマ通りの形に変えて返却する、APIの主役です。
function Query_person(id) {
return db.getPersonByID(id).then(
person => person
)
}
GraphQLサーバー
スキーマを保持し、レスポンスを提供するサーバーです。
有志や企業による多数のライブラリが提供されていて、開発者はそれらにスキーマとリゾルバ、多少の設定をすることでサーバーを立てることができます。
Node.jsではこの2つのライブラリが有名です
- Apollo Server 高機能な「GraphQLプラットフォーム」Apolloシリーズのサーバー部分
- GraphQL.js GraphQL財団チームがメンテする唯一の参照用実装
GraphQLクエリ
データ要求の定義です。GraphQL クエリ言語(後述)という?独自言語で記述します。
その内容は要求の
- 種類(query/mutate)
- 識別用の名前(「TOPページ用クエリ」とか)
- 欲しいオブジェクト(スキーマで定義されたもの)
- ↑の中で欲しいフィールド(これがまた別のオブジェクトだったり)
などです。
query topPage {
schedule {
movies {
name
actors {
name
birthday
}
}
}
}
GraphQL世界では、「クエリ」の意味が錯綜しています。
まず、GraphQLはGraph Query Launguegeの略語ではなく、GraphQLという固有名詞です。ですからクエリ言語は本来「GraphQLスキーマ言語」に対する「GraphQLクエリ言語」と呼ぶべきですが、馬から落馬しそうな語感のためか、あまりそうは呼ばれません。
また、要求を記した文字列は「GraphQLクエリ」または「GraphQLドキュメント」と2つの呼び名があります。「クエリ」のほうが一般的ですが、クエリ内の種別識別子がquery→取得、mutation→変更なので、これとの混乱を避けるときにはドキュメントと呼ぶようです。
また要求→処理までの一連の流れを「オペレーション」といいます。
つまり、
GraphQLクエリ言語でGraphQLクエリ(=GraphQLドキュメント)を記入してサーバーに送信することでGraphQLオペレーション(queryオペレーションやmutationオペレーション)を実行させる
ということです。
頭痛が痛くなってきます。
GraphQLクライアント
クエリを使って、APIサーバーからデータを取ってくるモジュールです。
クエリをサーバーに送れば良いのですから、Fetch APIで自作することもできますが、様々なライブラリが提供されていて、キャッシュ・複数クエリの統合などの追加機能を提供してくれます。
ライブラリは以下が有名です。
- Apollo Client Apolloシリーズのクライアント部分。別にApollo Server専用ではない
- urql
- Relay ←懐かしい兄弟!OSSになって現役です!
..ここまででサービスは動作しますが、これだけで挑むのはかなりのツワモノ

GraphQLのパワーの半分は開発時のツールにあります。
開発時
多くの場合、開発時にIDEとcodegenという補助ツールを使います。
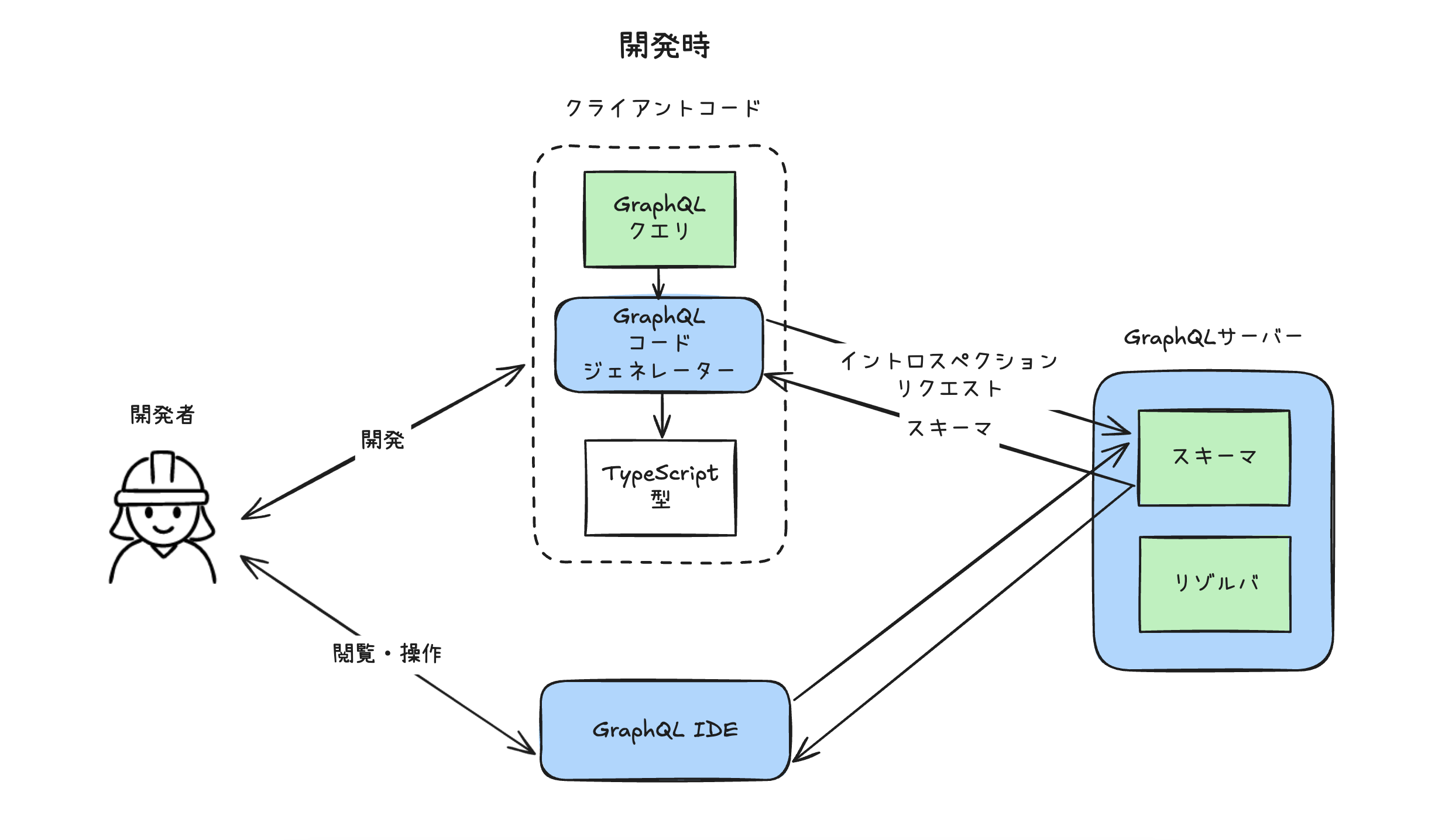
GraphQLサーバー(イントロスペクション)
同じサーバーが、開発用にはスキーマ自体も共有してくれます。
これをイントロスペクション(内省)機能と呼びます。自分で自分の持ってる型を振り返って反省?するからですかね。可愛いですね。
これを使われるとデータの構造が全て見えてしまうので、多くのサーバーはIPや認証で利用を制限します。
GraphQL IDE
IDEという大げさな名前ですが、スキーマの閲覧とクエリのお試しができるブラウザツールです。
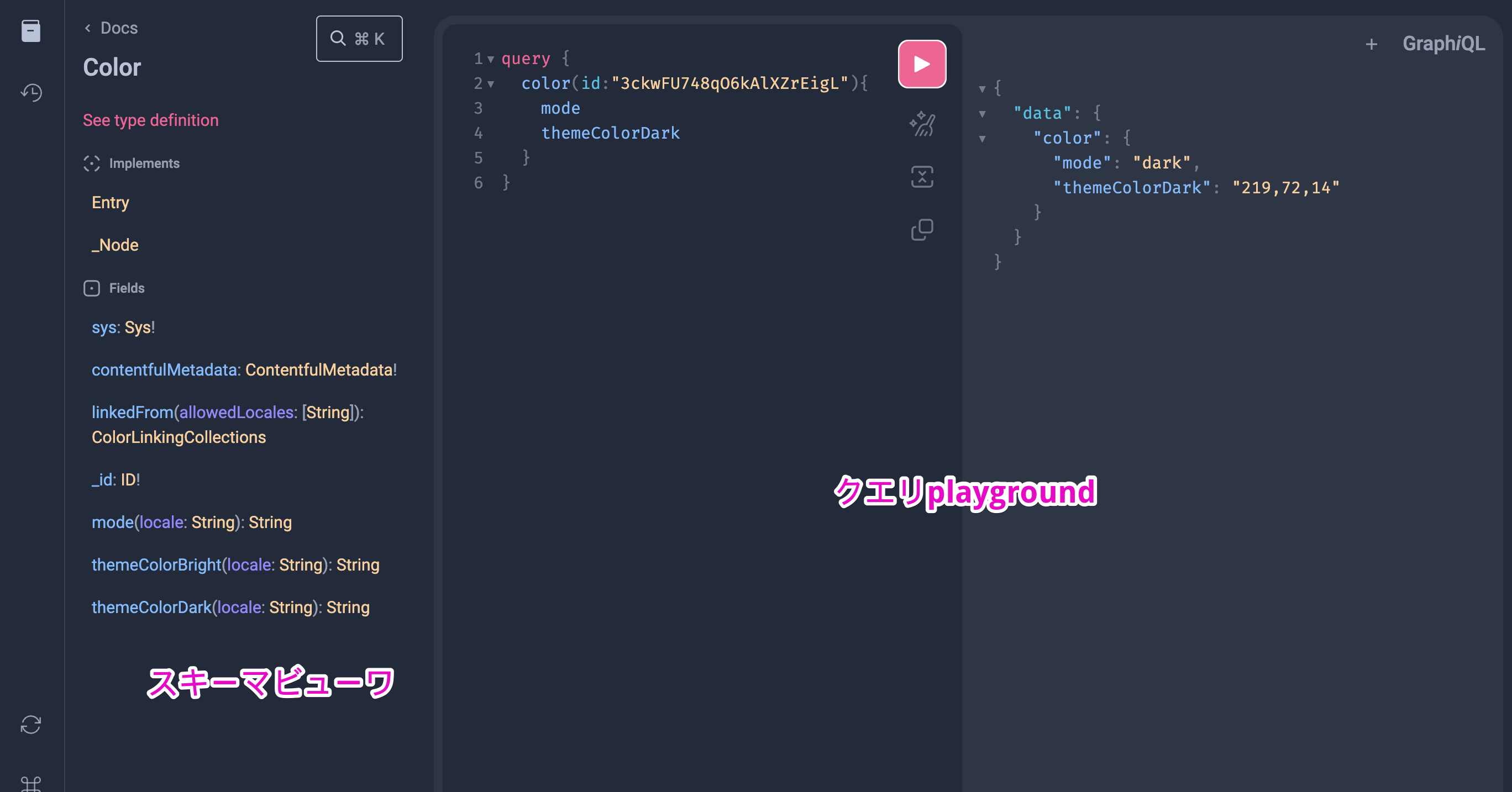
画面左側ではスキーマ全体を閲覧できます。「親タイプに戻る」「タイプ名で検索する」なども自由自在で、スキーマファイルを直接閲覧するよりはるかに快適です。いわば自動生成のAPI仕様書と言えます。
右側では、クエリを書いて実際にリクエストを出すことができます。自動補完が効き、スムーズにクエリを書くことができます。
以下が有名です
- Graphiql(グラフィカル) GraphQLチーム公式
- Apollo Sandbox Apollo Serverの付属機能
コードジェネレーター
TypeScriptを使うクライアント限定のツールです。
スキーマからTS型ファイルを生成しコードに混ぜ込むことで、
- クエリの書き方は正しいか
- 帰って来るデータはどんな形か
ソースコードを書いている時点で(!)教えてくれるライブラリが、コードジェネレーターです。開発機にだけ生息し、開発者のコマンドで目覚めて以下のように動きます
1.コード中のGraphQLクエリを探して読み込む
const topPageResponse = await gqlClient(`
query myQuery { //これだっ
topPage {
title
movies
}
}
`);
2.見つかったクエリでサーバーにイントロスペクション要求を出す
サーバー側はクエリが間違っていればエラーを返し、codegenもエラーを出して停止します。
合っていればスキーマを返してくれます。
3.スキーマをTypeScript型ファイルに変換し、専用フォルダに出力
//generated/types/**
export type MyQuery = {
topPage: {
title: string;
movies: Movie[];
};
};
4.なぜかAPIレスポンスに型がつく
この仕組みは筆者もよくわかりません。
ともかくコードジェネレーターはGraphQLが「APIとクライアントの同期の難しさ」を解決できた大きな理由です。
スキーマ(=仕様)とサーバーの同期は既にGraphQLサーバーの機能として存在します。ここにクライアント側のコードまで半自動的に同期し、3つの結合を完全にするのがcodegenです。
現在、筆者の知る限り選択肢は1つだけです
以上が、現在のGraphQL世界の大まかな地図です。
これから
GraphQLは
- スキーマを中心とした、API-クライアントの同期
- クライアントが100%カスタマイズできるデータ要求
- 繋がりあるデータたちの芋づる取得
などの大きなメリットを与えてくれる強力なソリューションであり、そのために現在でも多くのシステムで大活躍しています。
しかし、ワールドマップで見てきた通り、その導入やメンテナンスにはたくさんの特殊な知識・ツール・労力を要する、ハイコストな技術でもあります。また、パフォーマンスやキャッシュ面で構造的にRESTに敵わない点もあるようです。
10年が経ち、あの頃Facebookの直面していた問題を解決できるのは、もうGraphQLだけではなくなりました。
- REST APIの仕様書を標準化するOpen API
- クライアント・サーバーが両方TypeSciriptだと一瞬で型共有できる tRCP
- そもそも直接DBからデータを読むReact Server Component
GraphQLは複雑なグラフ状データを扱える最も本格的なソリューションとしてまだまだ活躍するかと思いますが、次の10年は、彼に影響を受けたり受けなかったりした後輩たちと競う時代かもしれません。
参考資料
- 公式サイト学習コーナー https://graphql.org/learn/
- 基調講演: GraphQL の簡単な歴史 - Lee Byron、GraphQL 共同作成者 https://www.youtube.com/watch?v=VjHWkBr3tjI
- The Truth About GraphQL https://www.youtube.com/watch?v=qgdiLcD2RL8&t=274s