はじめに
chainerのAdvent Calendar 2017 - Qiitaの1日目記事であるRealtime Multi-Person Pose Estimationの実装と以下の論文を参考に、人の動作の未来予測モデルの作成に挑戦してみました。
https://engineer.dena.jp/2017/11/chainerrealtime-multi-person-pose-estimation.html
https://arxiv.org/pdf/1704.05831.pdf
Learning to Generate Long-term Future via Hierarchical Prediction
概略はPose推定後の予測点群を時系列予測して、時系列予測された予測点群を用いてPose変化の予測画像の生成を行うものとなっています。Pose推定点群の時系列変化に注目するモデルとなっているため、背景に惑わされず、動作の未来予測を行えるモデルとなっています。
Pose推定の時系列予測を行うには、まずPose推定を行うモデルを作成しないといけないため、モデル作成コストが高いですが、Realtime Multi-Person Pose Estimationの学習済みモデルを使えば、Pose推定の時系列予測が可能ではないかと思い、挑戦してみました。
環境
Anaconda4.4.0 (python3.5.3)
OpenCV3
chainer2.0.0以降
構成
予測モデルとしては大きく分けて3つの構成からなっています。
①Pose推定モデル
これは公開されているRealtime Multi-Person Pose Estimationの学習済みモデルを使用します。詳細はChainerのAdvent Calendar 2017の1日目の記事を参照ください。
https://engineer.dena.jp/2017/11/chainerrealtime-multi-person-pose-estimation.html
②Pose推定ヒートマップの時系列予測モデル
Pose推定点群の時系列予測はLSTMを使うのが簡単かと思いますが、勉強も兼ねて以下のVisual Interaction Networksのモデルを参考に時系列予測してみました。これにより、LSTMのように過去フレーム情報を考慮した予測だけではなく、注目物体間の相互関係を取り入れた変化を学習できるようになると期待されます。元論文では物体間にバネ引力が働いた時の変化予測等が行われています。
今回扱うデータは扱う量が少ないので、そこまで考慮された学習が行われたかの確認はできませんが、勉強のためトライしてみました。
https://arxiv.org/pdf/1706.01433.pdf
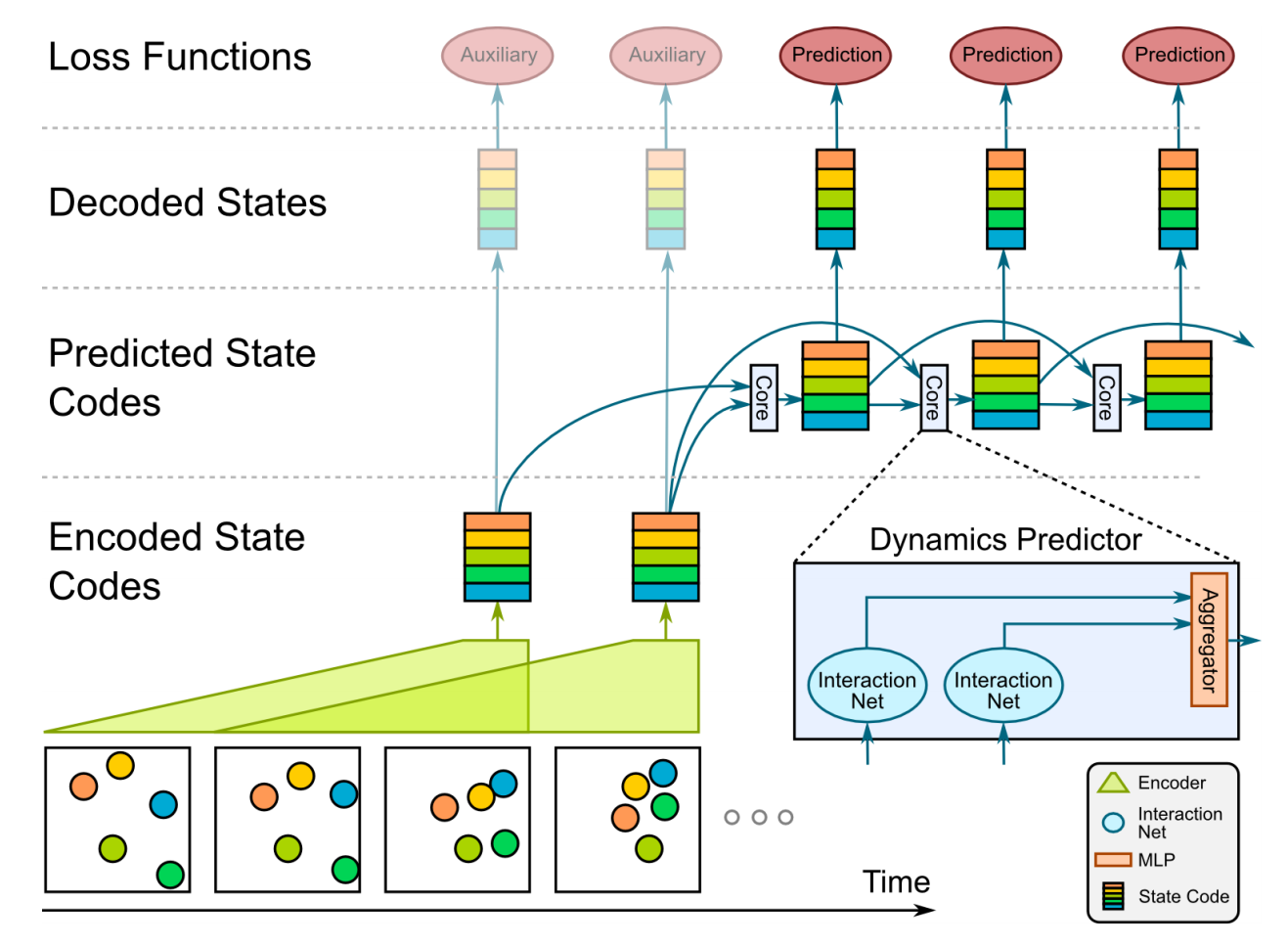
③Pose推定点群時系列予測結果からの画像生成
Pose推定点群時系列予測結果を用いて、未来の動作画像を生成します。
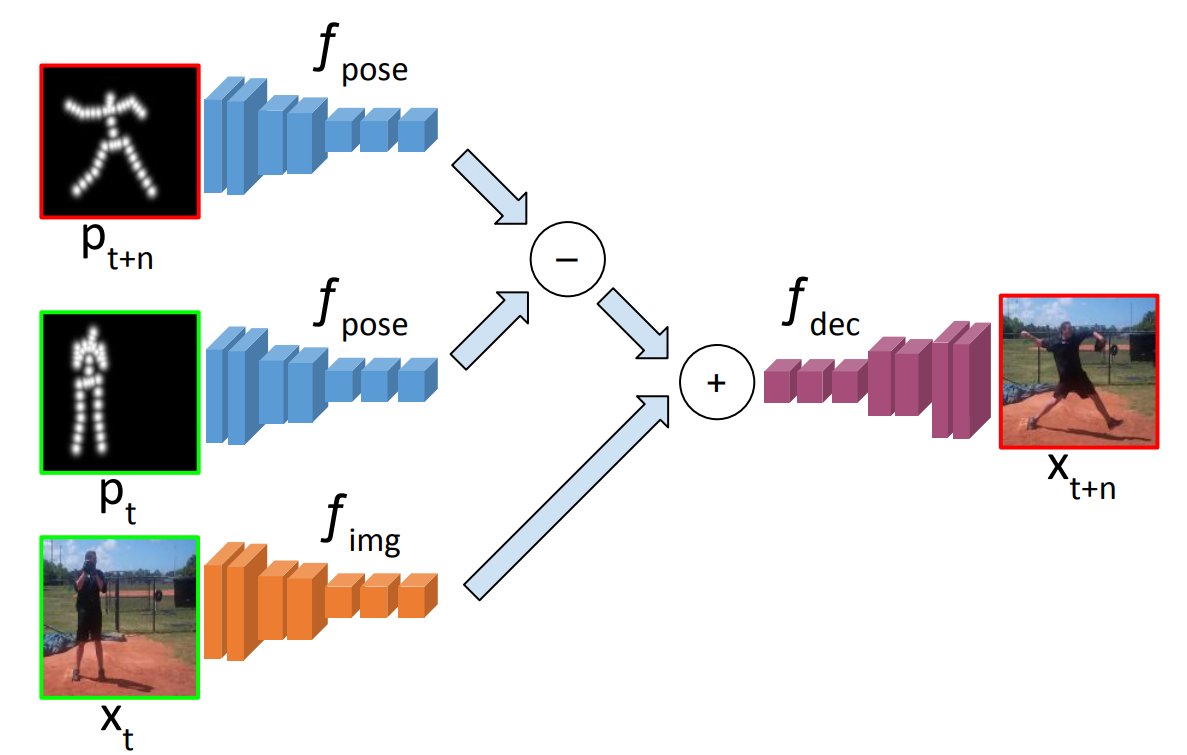
下図に示すように、予測画像生成X_t+1は時刻tおよび時刻t+1のPose推定点群f_pose_tとf_pose_t+1の差分情報を時刻t時の画像特徴マップX_t_fetureに加算して、その特徴マップをDeconvolution2Dで再構成することで生成します。
式:X_t+1 = Deconvolution_model((f_pose_t+1 - f_pose_t) + X_t_feture)
使用データ
いきなり大規模なデータセットの学習は扱いが難しかったので、個人的な趣味で初音ミクさんのライブ映像から、ある1シーンの連続フレーム40枚をキャプチャして学習データとしました。
今回はこのデータに過学習させることで、予測モデルの動作確認を行います。
使用データ例(左から5、12、18、25番目のFrame)

(背景が黒く、人物のみが写っているデータなので、扱いやすいと思って選んだのですが。
何フレームか途中でPose推定が一部の身体パーツ部分で正常に予測されない等もあり、
連続でPose推定が確実に行われていることを確認しながら収集した結果40枚程度しか
取れなかったという事情もあります。。(汗))
それぞれのモデル構成
①Pose推定モデル
これについては元記事のスクリプトをほぼお借りしている形になります。Pose推定時系列変化予測のために、ヒートマップデータと予測画像の生成のために、特徴マップを出力できるように追記を行っています。
https://github.com/DeNA/Chainer_Realtime_Multi-Person_Pose_Estimation/blob/master/pose_detector.py
②Pose推定ヒートマップの時系列予測モデル
Visual Interaction Networksを参考に実装しましたが、あくまで考え方を自分で解釈して実装したため、元論文の構造とは異なる部分が多々あります。
まず元論文では以下の図のように連続4枚フレームのうち3枚を選びだし、2枚ずつをCNNで特徴抽出します。その後、特徴マップに各物体間の位置情報を示したマップを追加し、さらにCNNをかけて、その時の状態を示したベクトルを得ます。ベクトル次元は注目物体の数だけ用意されており、これを2つずつ選ぶ組み合わせでMLPに入れ、出力結果を全ての組み合わせで総和します。この結果を1フレームずらして同じ処理をし、MLPで混ぜ合わせます。最初の3枚での処理が終わったら、1フレームずらしてもう一度処理し、最後に結果をまたMLPで総和します。
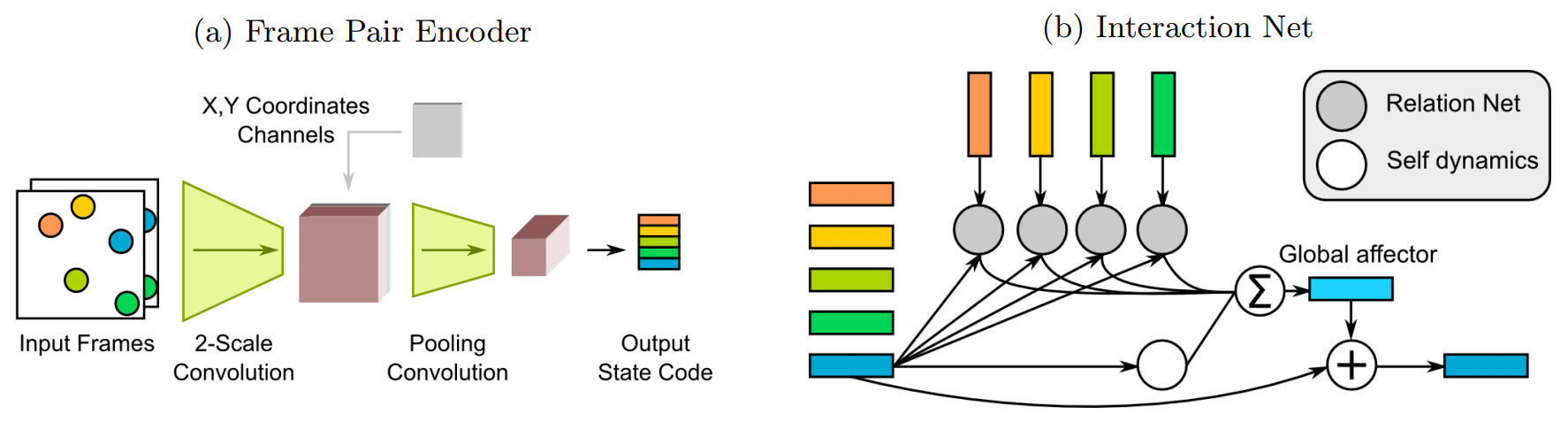
書いてて何を言っているか分からなくなってきましたが、、、(汗)
短く言うと、恐らく過去2フレーム分の物体の状態が区別されてベクトルの各次元に収まっており、その各次元を2つずつ組み合わせて取り出し、MLPで混ぜ合わせ、全ての組み合わせで総和することで、2つずつ関連性を学習するモデルであると予想されます。(これは一種のグラフ畳み込みであるという話も見かけました。)
よって今回はPose推定の結果から得られたヒートマップ情報(これは身体位置情報がチャンネルで分けられている。)を用いて身体位置チャンネルを状態ベクトルに変換することで、上記の物体の状態が区別されているベクトルを得ることができると考えられます。この時過去フレーム2つ分の各身体パーツの位置情報を各身体パーツチャンネル毎に一つのチャンネルにまとめておき、これをあとは2つずつ取り出してMLPで混ぜ合わせ総和していきます。
モデル部分のコードは以下のようになります。
色々解説を行わないといけない気がしますが、今回は省略します。すみません。
Pose推定から得られるヒートマップの出力次元は先頭にバッチサイズ次元を入れて(1,19,320,320)となります。2次元目は身体パーツの判定数に対応しており、このうち使用したデータには脚部など、写っておらず判定が行えないパーツがありますので、これについては0で置き換え処理を行っています。
class MEVIN(chainer.Chain):
insize = 320
def __init__(self):
super(MEVIN, self).__init__(
mlp1_1 = chainer.ChainList(
*[L.Linear(None,42*42)
for i in range(19)]),
mlp1_2 = chainer.ChainList(
*[L.Linear(None,4)
for i in range(19)]),
mlp2_1 = chainer.ChainList(
*[L.Linear(None,4)
for i in range(19*19)]),
mlp2_2 = chainer.ChainList(
*[L.Linear(None,2)
for i in range(19*19)]),
mlp3_1 = L.Linear(None,46*46),
mlp3_2 = L.Linear(None,46*46),
)
def __call__(self, x1,x2,x3,x4):
#print(x1.shape)
h1 = self.Mix_pofe(x1,x2,x3)
h2 = self.Mix_pofe(x2,x3,x4)
#print(len(h1))
h1 = self.Interaction(h1)
h2 = self.Interaction(h2)
h = self.Aggregator(h1,h2) # (1,1,42,42)
return h
def Mix_pofe(self,b_x,af_x,aff_x):
b_x_list = F.split_axis(b_x, 19, axis=0) #[(1,320,320),......]
af_x_list = F.split_axis(af_x, 19, axis=0) #[(1,320,320),......]
aff_x_list = F.split_axis(aff_x, 19, axis=0)
afb_x = []
for i in range(len(b_x_list)):
aff_af = F.concat((af_x_list[i],aff_x_list[i]),axis=1)
afb_x.append(F.expand_dims(F.concat((b_x_list[i],aff_af),axis=1),axis=0)) #(1,3,320,320)
return afb_x
def Interaction(self,afb_x):
F_mlp = []
for i in range(len(afb_x)):
img = F.resize_images(afb_x[i],(46,46))
pred = F.leaky_relu(self.mlp1_1[i](img))#(1,3,42,42) >> (1,42*42)
pred = F.leaky_relu(self.mlp1_2[i](pred))#(1,24*24) >> (1,4)
F_mlp.append(pred)
self_inter = []
inter = 0
for i in range(len(F_mlp)):
for ii in range(len(F_mlp)):
#print(i)
#print(ii)
if i == ii:
h = F.concat((F_mlp[i],F_mlp[ii]),axis=1)
h = F.leaky_relu(self.mlp2_1[i * 19 + ii](h)) #(1,4)
#print("chack",h)
self_inter.append(self.mlp2_2[i * 19 + ii](h)) #(1,2)
elif i != ii:
h = F.concat((F_mlp[i],F_mlp[ii]),axis=1)
h = F.leaky_relu(self.mlp2_1[i * 19 + ii](h)) #(1,4)
#print("test",h)
inter += F.leaky_relu(self.mlp2_2[i * 19 + ii](h))#(1,2)
for iii in range(len(self_inter)):
self_inter[iii] += inter
self_inter_add_inter = F.stack(self_inter, axis=1)
return self_inter_add_inter #(1,2*19)
def Aggregator(self,si_add1,si_add2):
h = F.concat((si_add1,si_add2),axis=1)#(1,2*19*2)
h = F.leaky_relu(self.mlp3_1(h)) #(1,42*42)
h = F.leaky_relu(self.mlp3_2(h)) #(1,42*42)
h = F.reshape(h,(h.data.shape[0],1,46,46))
return h
学習時は過去フレーム4枚から次の1枚を予測させ、出力結果と元データとの間の二乗和誤差を損失関数としています。
③Pose推定点群時系列予測結果からの画像生成
Pose推定結果を時刻前後で引き算し、前フレームの特徴マップに加算して再構成を行うモデルの学習は損失関数は以下の4つになります。
・予測フレームと元データとの二乗誤差を取る。
・予測フレームと元データをそれぞれ①で使用したPose推定の学習済みモデルに入力し、VGG構造の処理部分までの特徴マップを取り出し、特徴マップの二乗誤差を取る。
・再構成モデルをGeneratorと考えてLSGANの生成側の損失を取る。(係数0.0005を乗算)
・LSGANのDiscriminatorを作成し、敵対的損失を取る。(係数0.0005を乗算)
以上の4つの損失を用いることについては動作未来予測の参考論文で予測画像生成時に使用された損失になります。最後のGAN学習の損失について係数をかけているのは、そのまま学習した場合に発散してしまったため追加しました。実際どこまで効果があったかは検討できていませんが、入れる狙いとしては、生成される画像間で滑らかな画像が生成されることを期待していると予想されます。また二乗誤差のみの学習だとOptimizerの設定の仕方にもよりますが、データセットの画像を平均した画像が生成されてしまう恐れもあり、それを避ける目的もあるのではと思いました。
LSGAN部分のモデルは以下
入力は(1,128,46,46)を(1,3,368,368)に再構成します。(1,128,42,42)の特徴マップの全てのチャンネルにPose推定結果の前後差分を加算します。
class DisNet(chainer.Chain):#Discriminator
insize = 368
def __init__(self):
super(DisNet, self).__init__(
# cnn to make feature map
conv1_1=L.Convolution2D(in_channels=3, out_channels=64, ksize=3, stride=1, pad=1),
conv1_2=L.Convolution2D(in_channels=64, out_channels=64, ksize=4, stride=2, pad=1),
conv2_1=L.Convolution2D(in_channels=64, out_channels=128, ksize=3, stride=1, pad=1),
conv2_2=L.Convolution2D(in_channels=128, out_channels=128, ksize=4, stride=2, pad=1),
conv3_1=L.Convolution2D(in_channels=128, out_channels=256, ksize=3, stride=1, pad=1),
conv3_2=L.Convolution2D(in_channels=256, out_channels=256, ksize=3, stride=1, pad=1),
conv3_3=L.Convolution2D(in_channels=256, out_channels=256, ksize=3, stride=1, pad=1),
conv3_4=L.Convolution2D(in_channels=256, out_channels=256, ksize=4, stride=2, pad=1),
conv4_1=L.Convolution2D(in_channels=256, out_channels=512, ksize=3, stride=1, pad=1),
conv4_2=L.Convolution2D(in_channels=512, out_channels=512, ksize=3, stride=1, pad=1),
conv4_3_CPM=L.Convolution2D(in_channels=512, out_channels=256, ksize=3, stride=1, pad=1),
conv4_4_CPM=L.Convolution2D(in_channels=256, out_channels=128, ksize=3, stride=1, pad=1),
l5 = L.Linear(None,1),
)
def __call__(self, x):
h = F.leaky_relu(self.conv1_1(x))
h = F.leaky_relu(self.conv1_2(h))
#h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.leaky_relu(self.conv2_1(h))
h = F.leaky_relu(self.conv2_2(h))
#h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.leaky_relu(self.conv3_1(h))
h = F.leaky_relu(self.conv3_2(h))
h = F.leaky_relu(self.conv3_3(h))
h = F.leaky_relu(self.conv3_4(h))
#h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.leaky_relu(self.conv4_1(h))
h = F.leaky_relu(self.conv4_2(h))
h = F.leaky_relu(self.conv4_3_CPM(h))
h = F.leaky_relu(self.conv4_4_CPM(h))
h = self.l5(h)
return h
class GenNet(chainer.Chain):#Generator
def __init__(self):
super(GenNet, self).__init__(
# cnn to make feature map
conv1_1=L.Deconvolution2D(in_channels=64, out_channels=3, ksize=3, stride=1, pad=1),
conv1_2=L.Deconvolution2D(in_channels=64, out_channels=64, ksize=3, stride=1, pad=1),
conv2_1=L.Deconvolution2D(in_channels=128, out_channels=64, ksize=3, stride=1, pad=1),
conv2_2=L.Deconvolution2D(in_channels=128, out_channels=128, ksize=3, stride=1, pad=1),
conv3_1=L.Deconvolution2D(in_channels=256, out_channels=128, ksize=3, stride=1, pad=1),
conv3_2=L.Deconvolution2D(in_channels=256, out_channels=256, ksize=3, stride=1, pad=1),
conv3_3=L.Deconvolution2D(in_channels=256, out_channels=256, ksize=3, stride=1, pad=1),
conv3_4=L.Deconvolution2D(in_channels=256, out_channels=256, ksize=3, stride=1, pad=1),
conv4_1=L.Deconvolution2D(in_channels=512, out_channels=256, ksize=3, stride=1, pad=1),
conv4_2=L.Deconvolution2D(in_channels=512, out_channels=512, ksize=3, stride=1, pad=1),
conv4_3_CPM=L.Deconvolution2D(in_channels=256, out_channels=512, ksize=3, stride=1, pad=1),
conv4_4_CPM=L.Deconvolution2D(in_channels=128, out_channels=256, ksize=3, stride=1, pad=1),
upsamp14 = L.Deconvolution2D(in_channels=256, out_channels=256, ksize=4, stride=2, pad=1),
upsamp12 = L.Deconvolution2D(in_channels=128, out_channels=128, ksize=4, stride=2, pad=1),
upsamp11 = L.Deconvolution2D(in_channels=64, out_channels=64, ksize=4, stride=2, pad=1),
)
def __call__(self, x):
h = F.leaky_relu(self.conv4_4_CPM(x))
h = F.leaky_relu(self.conv4_3_CPM(h))
h = F.leaky_relu(self.conv4_2(h))
h = F.leaky_relu(self.conv4_1(h))
h = F.leaky_relu(self.upsamp14(h))
h = F.leaky_relu(self.conv3_4(h))
h = F.leaky_relu(self.conv3_3(h))
h = F.leaky_relu(self.conv3_2(h))
h = F.leaky_relu(self.conv3_1(h))
h = F.leaky_relu(self.upsamp12(h))
h = F.leaky_relu(self.conv2_2(h))
h = F.leaky_relu(self.conv2_1(h))
h = F.leaky_relu(self.upsamp11(h))
h = F.leaky_relu(self.conv1_2(h))
h = F.leaky_relu(self.conv1_1(h))
return h
学習ループは学習データも少量のため、300回程で止めています。(予測画像の生成については、それ以上行うと画像が乱れてしまったため)
学習結果
過去フレーム4枚を用いて次の1フレームを生成する処理は、各身体パーツの動作予測および画像の生成において、次の動作が見て分かる程度には生成できていると思われます。生成画像については細部がボヤけてしまっていますが、今回試した限りではこれ以上綺麗にはなりませんでした。


予測
予測時の処理はスタートフレームから4枚までを実データとし、その後のフレーム予測を行ってみました。(4枚目まで)学習の結果から1フレーム先の予測については、未来動作を確認でき、実データと同じ挙動であることが見て取れましたが、予測時の処理では、1フレーム先以降の予測結果は何らかの動作を予測しているものの、実データに一致しているとは言えないと思います。
ここでは載せていませんが、さらに先のフレームまで画像を生成すると人物画像そのものがどんどん乱れていきました。
未来フレームを予測するためのPose推定は予測生成された画像を用いているため、生成画像の細部の粗さが、さらに先の未来フレーム予測を難しくしているのではないかと思います。
予測結果① スタートフレーム0~3

予測フレーム4~7

予測フレーム4~7(Pose推定予測)
予測結果② スタートフレーム7~10

予測フレーム11~14

予測フレーム11~14(Pose推定予測)

感想
1フレーム先の予測については、過学習ではあるものの上手くフィッティングできているのではないかと思いました。しかし1フレームより先の予測については、今回あまり上手く行っていないと思います。勉強も兼ねてVINを参考にしたモデルを作成しましたが、やはりまずは簡単なモデルから試すのが基本かと思いますので、LSTMを用いた方法も時間ができたらやってみようと思います。
データについても汎化性能を評価するために、データを集めなければなりませんが、学習に都合の良いモーションデータを集めるのは大変なので、Unity等で自分でシミュレートしてデータを作ることができれば良いかなと思いました。
今回のモデルはPose推定が重要であるため、学習済みモデルが公開され、かつ自分が慣れているフレームワークでの実装が出たのは本当に有難いと思いました。しかし未来予測モデルとして作ってはいますが、リアルタイム性で考えると、処理速度が遅いので現実の方が先に行ってしまいます。(汗)強化学習で学習モデルがどのようなことを未来予測し評価を行ったのかを可視化する手段として使える・・・ということもないのでしょうか・・・・。
今回の予測に関しての実装は以下に学習済みデータと一緒に置いてみました。
https://github.com/ISakony/Future_motion_prediction_model-
訓練時のスクリプトは整理ができておらず、時間ができたらまとめたいと思います。