はじめに
カメラの映像情報から車の操作をEnd-to-Endで学習したネットワーク構造が入力映像中のどこに注目して操作を行うようになっているのかを可視化するためのアルゴリズムについて提案を行っている。
ニューラルネットの判断がどのような基準で行われているのかの説明は内部構造の複雑さから困難であるが、この論文では上手く可視化して説明を行っていたので、参考になるかと思い読んでみた。簡単なネットワークを作ってテストも行ってみたので覚書を残す。
元論文
Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car
環境
python 2.7+
chainer 2.0.0a1
PIL 4.0.0
windows10のノートパソコンに
Anaconda2-4.3.0.1-Windows-x86_64を入れてchainerをpip installした環境
概略
車の自動操舵のためにPilotNetと呼ばれる下図右側ネットワーク構造でのEnd-to-Endの学習を提案しており、学習はカメラデータと運転する人間が生成した操舵角とが対になったデータセットを用いて訓練される。この論文の前の実験では、PilotNetは車線標識の有無にかかわらず、さまざまな運転条件で車線維持を成功裏に実行できることを実証されているらしい。今回は学習した内容の解析、ネットワークの操舵アクションの決定根拠を説明するために下図左側のようなアルゴリズムでネットワークが顕著に反応した箇所を可視化している。
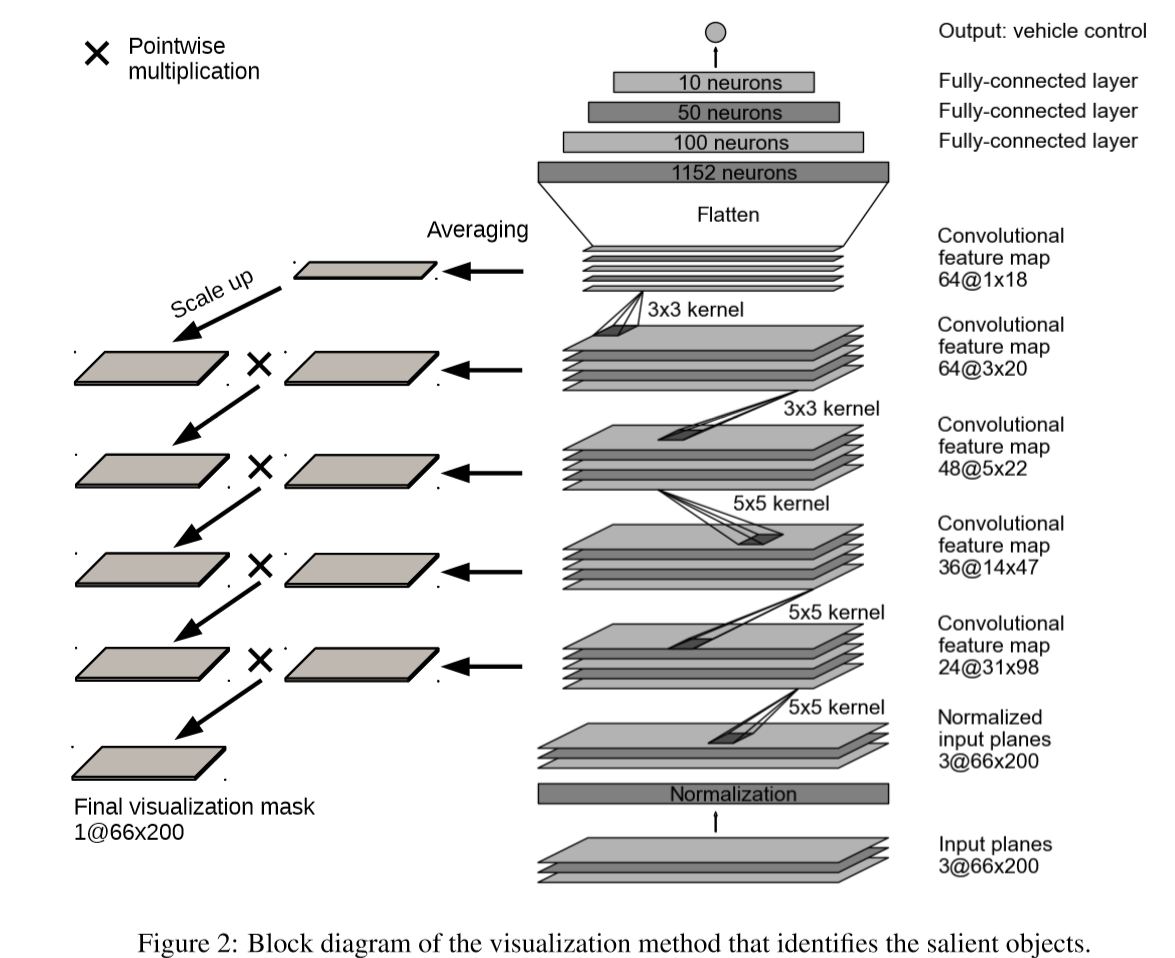
アルゴリズム
可視化マップの生成手順は以下のようになっている。
1 それぞれの層の活性化した特徴マップを平均する。
2 平均マップを下位層(入力に近い側)に渡す際に、サイズが異なっていれば
deconvolutionを利用してアップスケールしている。その際filter sizeおよびstride sizeはconvolution時と同じものを使用し、重みは1.0、バイアス0.0に設定する。
3 アップスケールされた上位層平均マップと一つ下の下位層平均マップとを掛け算する。(中間可視マスクと呼ぶ)
4 3で得られた中間可視マスクを2、3処理で繰り返して入力画像と同じサイズになるまで続ける。最終的に入力サイズと同じサイズの可視マスク(visualization mask)を得る。
簡易実装(MNISTデータでテスト)
以下の簡易的なCNN構造を作成し、MNISTデータで実験を行った。visualization maskを得る処理は、学習後に一枚ずつ画像を処理するpredict関数内で平均値計算を行う処理を追加し、visual_mask関数内で上記手順の2~3処理を繰り返してvisualization maskを得ている。
ネットワーク構造
class testCNN(chainer.Chain):
insize = 28
def __init__(self):
w = math.sqrt(2)
layers = {}
layers["conv1"] = L.Convolution2D(1, 96, 4, stride=2, pad=1)
layers["conv2"] = L.Convolution2D(96, 256, 4, stride=2, pad=1)
layers["conv3"] = L.Convolution2D(256, 384, 3, stride=1, pad=1)
layers["conv4"] = L.Convolution2D(384, 11, 3, stride=1, pad=1)
super(testCNN, self).__init__(**layers)
self.train = True
self.initialW = np.ones((1, 1, 4, 4)).astype(np.float32)#out_c,in_c
self.averageL0 = np.zeros((1, 1, 28, 28)).astype(np.float32)
self.averageL1 = np.zeros((1, 1, 14, 14)).astype(np.float32)
self.averageL2 = np.zeros((1, 1, 7, 7)).astype(np.float32)
self.averageL3 = np.zeros((1, 1, 7, 7)).astype(np.float32)
self.averageL4 = np.zeros((1, 1, 7, 7)).astype(np.float32)
def clear(self):
self.loss = None
self.accuracy = None
def __call__(self, x, t):
self.clear()
h = F.leaky_relu(self.conv1(x))
#print h.data.shape #320,96,14,14
h = F.leaky_relu(self.conv2(h))
#print h.data.shape #320,256,7,7
h = F.leaky_relu(self.conv3(h))
#print h.data.shape #384,7,7
h = F.leaky_relu(self.conv4(h))
#print h.data.shape #11,7,7
h = F.reshape(F.average_pooling_2d(h, h.data.shape[2]), (x.data.shape[0], 11))
self.loss = F.softmax_cross_entropy(h, t)
self.accuracy = F.accuracy(h, t)
self.h = h
return self.loss
def predict(self, x, t):#batchsize = 1
self.clear()
h = F.leaky_relu(self.conv1(x))
print len(h.data[0])
for i in range(len(h.data[0])):
self.averageL1[0][0] += h.data[0][i]
self.averageL1 /= len(h.data[0])
h = F.leaky_relu(self.conv2(h))
print len(h.data[0])
for i in range(len(h.data[0])):
self.averageL2[0][0] += h.data[0][i]
self.averageL2 /= len(h.data[0])
h = F.leaky_relu(self.conv3(h))
print len(h.data[0])
for i in range(len(h.data[0])):
self.averageL3[0][0] += h.data[0][i]
self.averageL3 /= len(h.data[0])
h = F.leaky_relu(self.conv4(h))
print len(h.data[0])
for i in range(len(h.data[0])):
self.averageL4[0][0] += h.data[0][i]
self.averageL4 /= len(h.data[0])
h = F.reshape(F.average_pooling_2d(h, h.data.shape[2]), (x.data.shape[0], 11))
self.accuracy = F.accuracy(h, t)
return h
def visual_mask(self):
z = self.averageL4 * self.averageL3
z = z * self.averageL2
z = F.deconvolution_2d(Variable(z),self.initialW,stride = 2,pad=1).data * self.averageL1
z = F.deconvolution_2d(Variable(z),self.initialW,stride = 2,pad=1).data
return z
詳細スクリプトはGitHub。 コメント等そのままになっており整理はできていませんが、ご参考までに。
ご指摘等ありましたら、よろしくお願いします。
結果
個人テスト結果例と、論文記載の図を下図に示す。
判定を行うために、活性化された箇所は文字の線の周辺となっている。論文内では操舵の根拠となる箇所(道路の線や、物体)で顕著な反応を示しており、顕著箇所を画像処理でズラす等を行うと、自動操舵の操舵角度にも影響がでることが確かめられている。
個人テスト結果例
入力



Visualization mask



論文の結果図

論文図では自動操舵に影響を与えた箇所のみがマスク図として得られている。
感想
CNNならばフィルターの可視化といった方法はあるが、枚数が多く関連を追うのが難しいと思っていた。この方法であれば、1枚の入力に、1枚の顕著特徴画像のセットで示せるのは便利そう。ただしMNISTデータはもともと普通にフィルターを可視化しても代々判定箇所が分かる(どのフィルターも数字の輪郭を取っているのがわかる)ため、あまり今回の方法の良さは出ていなかった。(むしろdeconvolutionで注目箇所がボヤけているように見える。)論文結果のように判定根拠となる箇所以外は無視するようなマスク図を得るために、もっと大きいタスクで使用してみたいと思った。あるいは強化学習のようになんらかのアクションと関連付けることで、同じ入力でも注目箇所が変わる様子が見えるのかもしれない。