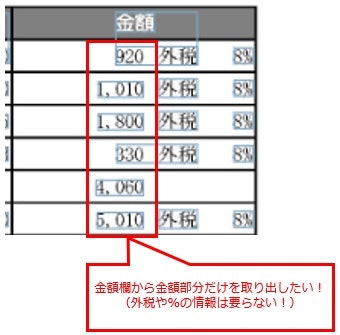
帳票例:テーブルの列から必要な部分だけを取り出す
以下の表では、「金額」というひとつの列の中に、金額・税区分(「外税」)・税率という3つの値が入っています。
ここでは、その中から純粋に金額部分だけを取り出したい場合に、どのように対処すればいいかを解説します。
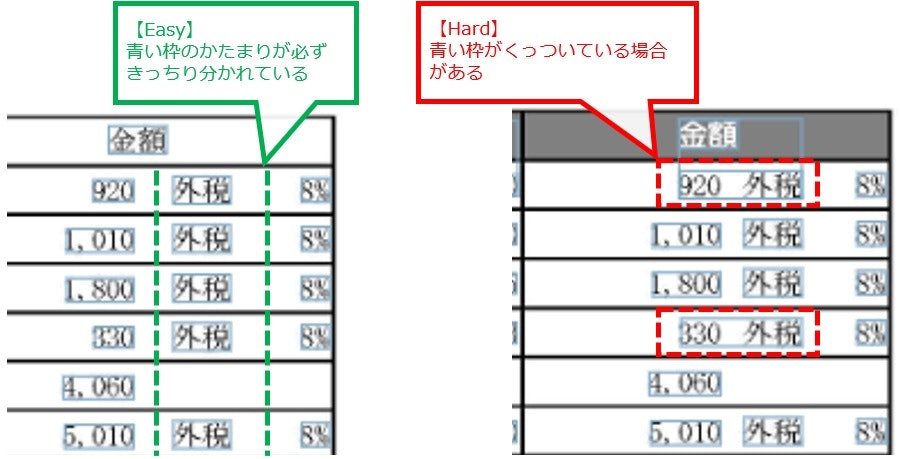
難易度の違い:表をよく見てみよう
このケース、実は表のつくりは同じでも、OCRの取得結果によって対処の方法が違います。
以下の図の左側のように、青い枠が分割したい項目別にきっちり分かれてとれている場合は、とても簡単に対応できます。
一方、図の右側のように、青い枠が項目をまたいでくっついている場合があると、少し対処が難しくなります。
このページでは両方ともやりかたを解説します。
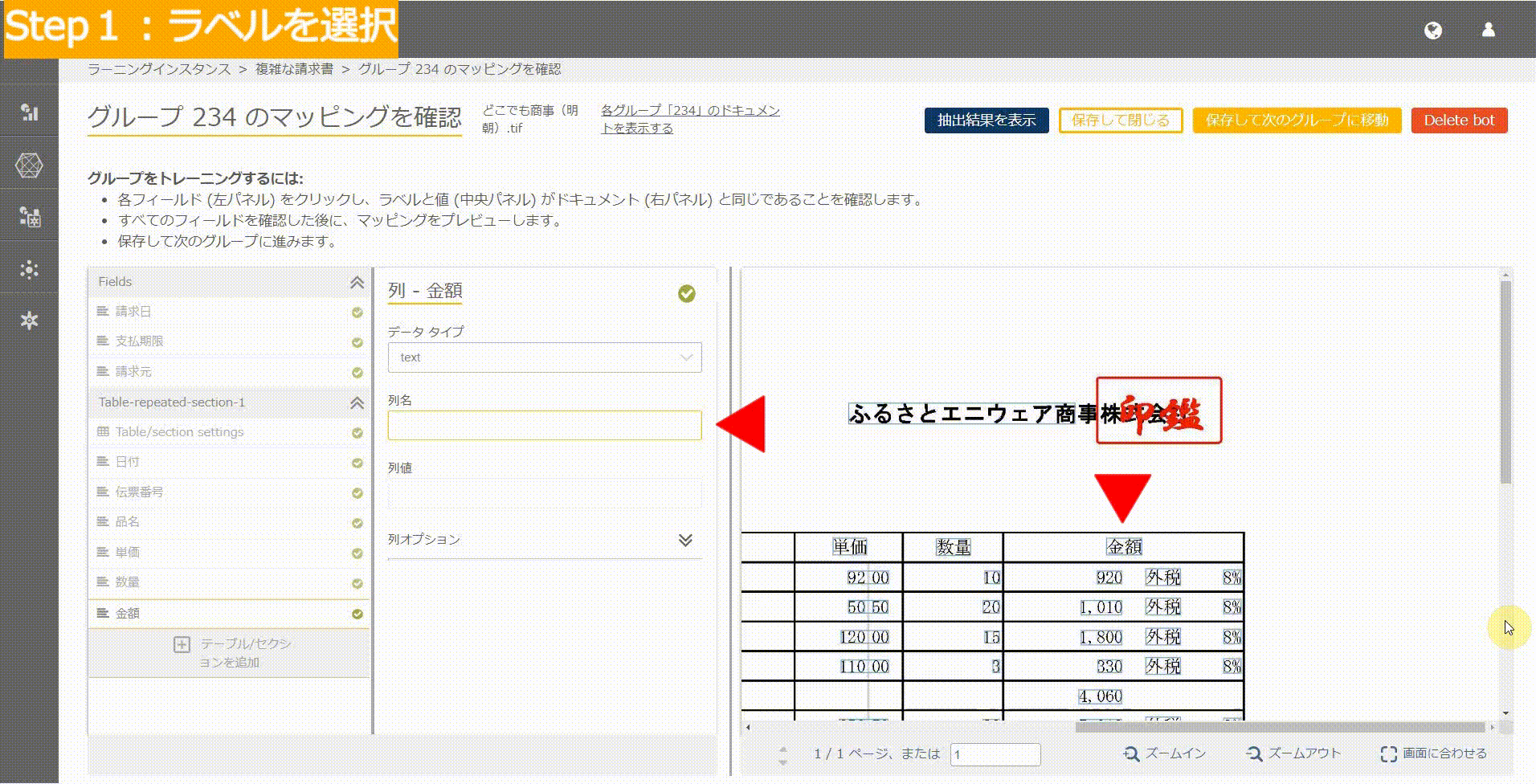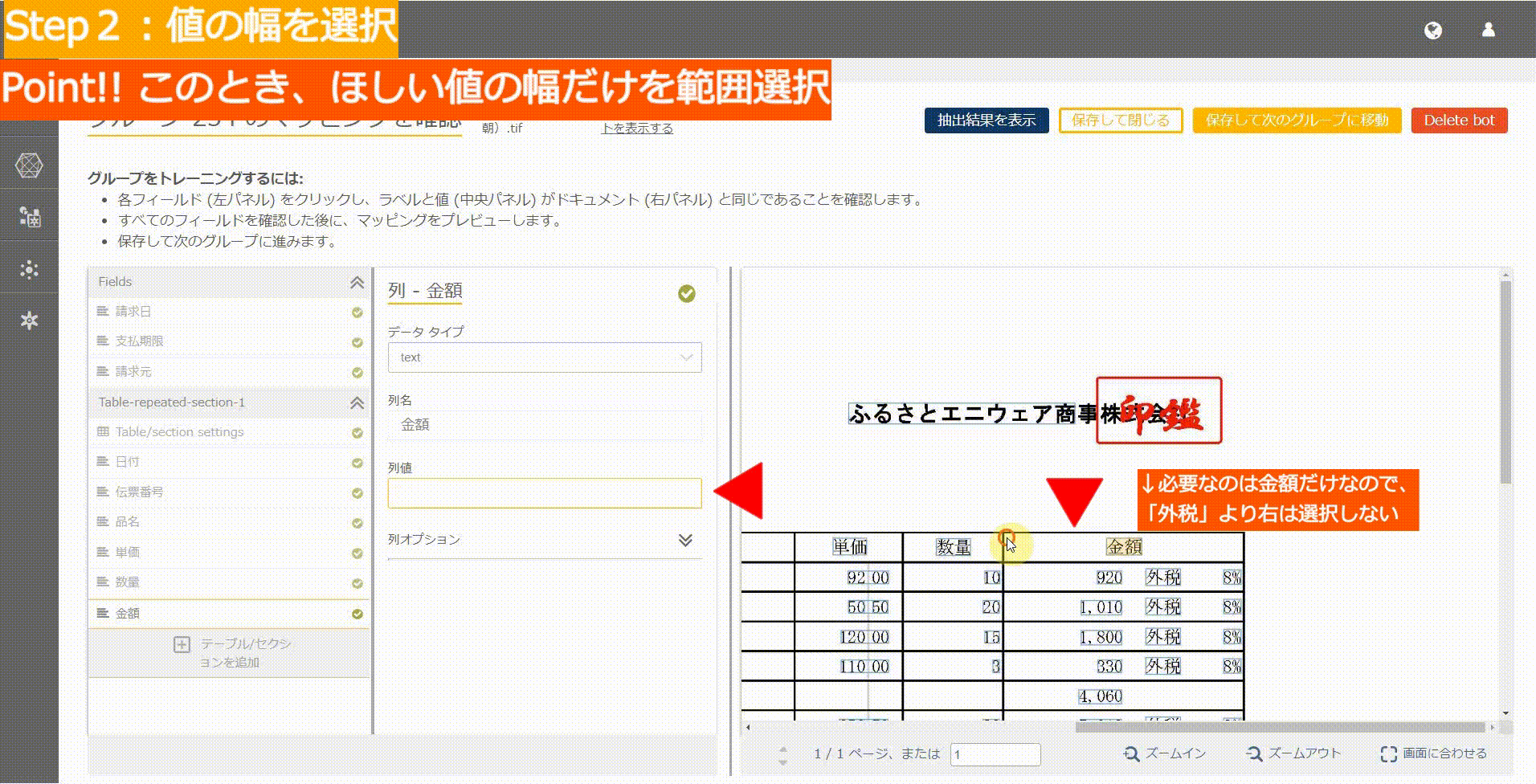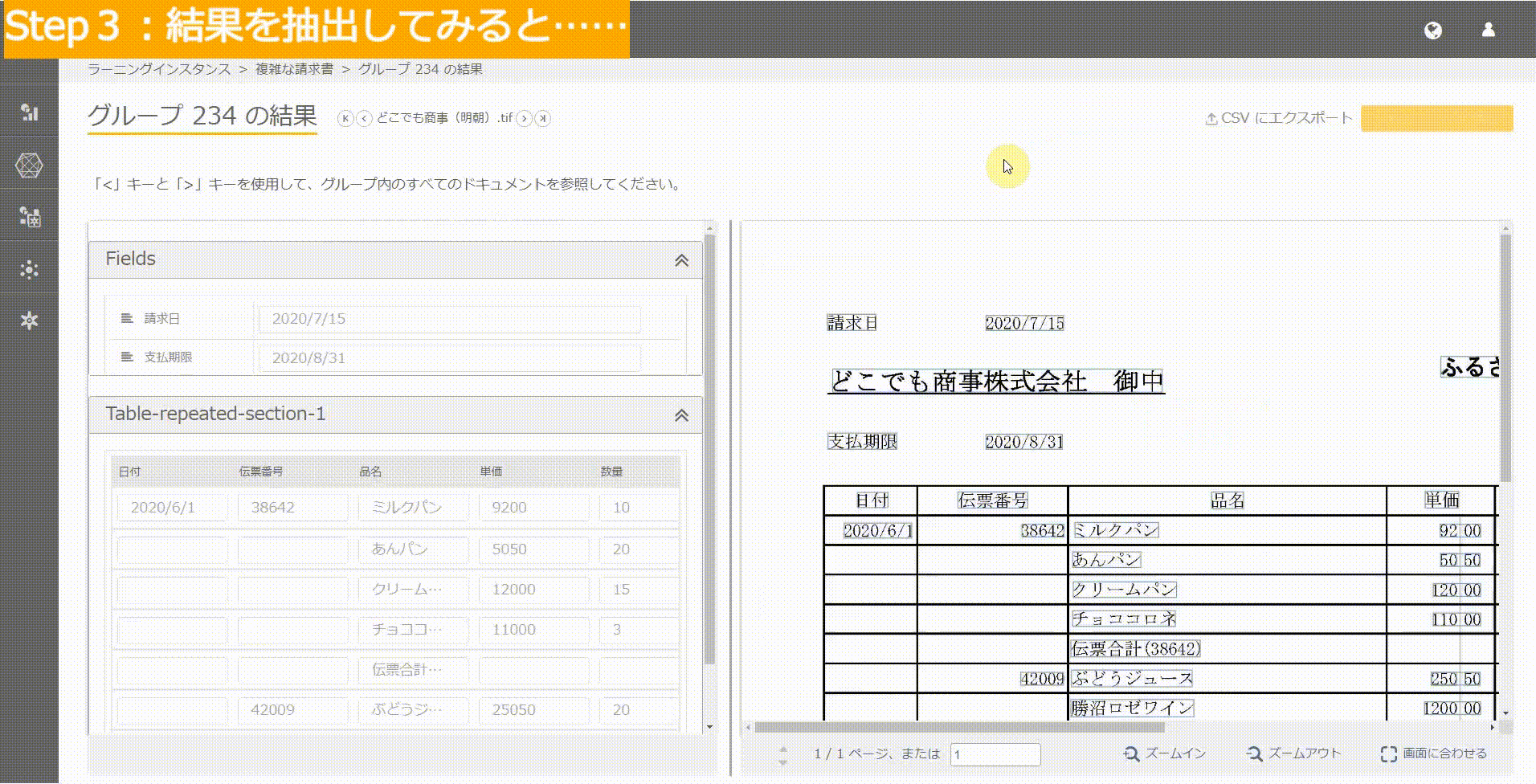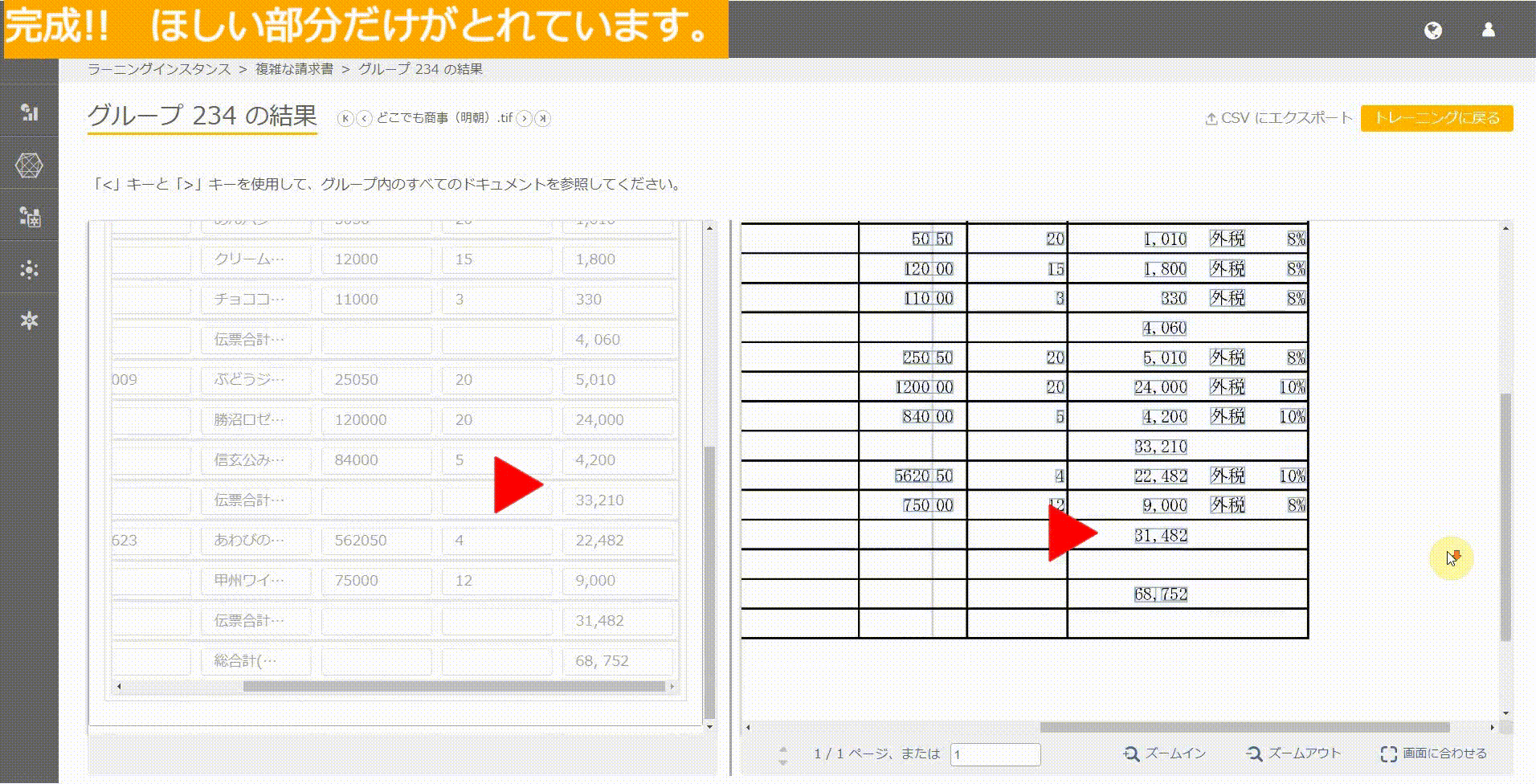
Easyモード:青い枠がきっちり分かれている場合
この場合の対応は簡単。
列値を選択する際に、以下の動画のイメージどおり、ほしい部分の値の幅だけを選択すればOKです。
Hardモード:青い枠がくっついている場合
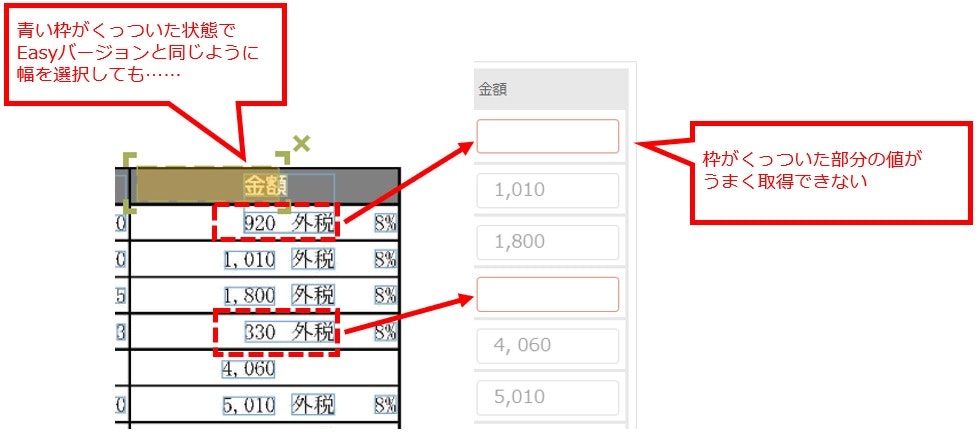
青い枠がくっついてしまっていると、上記のようにはいきません。
IQ Botは値を青枠のかたまりごとに取得しようとするので、部分的に取得しようとしてもうまくいかないはずです。
Hardモードへの対応方法
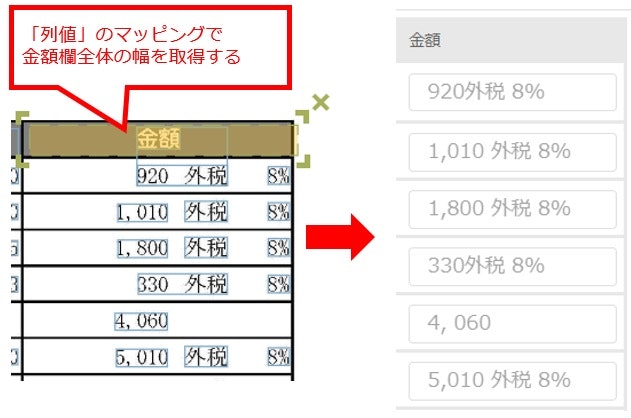
Hardモードに対応する場合は、①マッピングでは列全体を取得しつつ、②カスタムロジックで必要な部分だけを取り出すと良いです。
①マッピングのとりかた
②カスタムロジックで必要な部分だけを取り出す
マッピングができたら、カスタムロジックで必要な部分だけを取り出します。
この「必要な部分」がどういう条件で決まるかは帳票によって千差万別なので、一概にパターン化できないのですが、例えば今回の帳票でいえば以下のような分割のしかたが可能です。
方法1:決まった文字列を根拠に分割する
考え方
今回の帳票では、金額は税区分(外税)の前に書いてあるか(パターン①)、単独で書いてあるか(パターン②)のどちらかです。
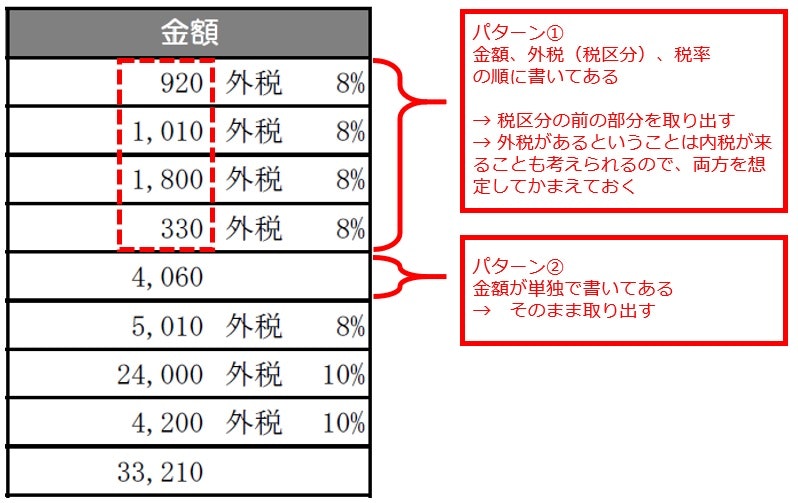
この考え方に基づいてカスタムロジックを作る場合、実装例は以下のようになります。
実装例
# 値を保存する変数: table_values
# 表の操作をするときに必ず入れるコード(最初)
import pandas as pd
df = pd.DataFrame(table_values)
#############################################
# ↓↓↓ ここからが今回の処理 ↓↓↓
#############################################
# 金額欄を分割する処理
def bunkatsu(x):
result = ""
splitter = ("外税","内税") #Point1:分割の根拠となる文字列
for i in splitter:
if i in x:
result = x.split(i)[0] #Point2:↑を根拠に分割した上で、分割したどの部分を取り出すかの指定
if result == "":
result = x
return result
df['金額'] = df['金額'].apply(bunkatsu)
#############################################
# ↑↑↑ ここまでが今回の処理 ↑↑↑
#############################################
# 表の操作をするときに必ず入れるコード(最後)
table_values = df.to_dict()
方法1の応用方法
例えば税区分で「外税」「内税」以外に「非課税」が考えられる場合は、上記のsplitter = ("外税","内税")をsplitter = ("外税","内税","非課税")のように変更します。
上記は税区分よりも前の部分を取り出していますが、税区分よりも後の部分(税率)を取り出したい場合は、上記のresult = x.split(i)[0]の[0]を[1]に変えます。
[0]を[1]に変えると、なぜ税区分より後の部分が取り出せるのかわからない&知りたい人は、文系初心者でもわかるsplitの説明を読んでみてください。
方法2:「数値以外の文字」を根拠に分割する
上記の処理をさらに一般化して、「数値以外の文字(1~複数)があれば、それを根拠に分割する」という組み方もできます。
注意:この方法は正規表現を使うので、pythonの正規表現ライブラリ(re)を使います。このライブラリは、V11系統では使用できますが、A2019系統の.14以前のバージョンでは使用できません。
# 値を保存する変数: table_values
# 表の操作をするときに必ず入れるコード(最初)
import pandas as pd
df = pd.DataFrame(table_values)
#############################################
# ↓↓↓ ここからが今回の処理 ↓↓↓
#############################################
import re #正規表現ライブラリのインポート
# 金額欄を分割する処理(関数)
def bunkatsu(x):
#結果の初期化
result = ""
#分割の根拠にしたくない文字列を除外
x = x.replace(" ","")
x = x.replace(",","")
#対象の文字列に含まれる数字を取り除く → 数字以外の部分だけが残る (”\d"は正規表現で数字を表す)
letterX = re.sub("\d","",x)
if letterX != "": #数字以外の文字列が含まれていたら...(★)
result = re.split("\D+", x)[0] #数字以外の文字列で分割した最初のかたまりを取り出してresultに入れる
#"\D+" は正規表現で「数字以外の文字列の任意の数の繰り返し」を表す
else: #★以外(=数字のみ)なら...
result = x #もとの値をそのままresultに入れる
return result #resultの中身を返す
# ↑ここまでが関数の定義
# 金額欄に定義した関数を適用する
df['金額'] = df['金額'].apply(bunkatsu)
#############################################
# ↑↑↑ ここまでが今回の処理 ↑↑↑
#############################################
# 表の操作をするときに必ず入れるコード(最後)
table_values = df.to_dict()
いかがでしたか?
今回はIQ Botで使うカスタムロジックにしては、そこそこ長め&中級編の内容が入ってきました。
わからない部分があった場合は、質問を投稿していただければ回答しますのでお気軽にどうぞ!
それでは!