はじめに
Colaboratoryで画像認識をやる上で、Colaboratory上で立ち上がったVM環境に毎回ローカルPCからファイルをUploadするのはシンドイ
また、動画を〇Frame単位に画像として分解した画像データをVM上に放置しておくとColaboratoryの仕様によってVMが強制遮断されてしまうので、処理した画像はどこかに置いておかなければならない
そこで、GoogleDriveをマウントしてColaboratoryで処理したものを永続的に保管しておくことにする
PyDriveというモジュールを使えばGoogleDriveのAPIを直接触らなくても良いらしい。
えぇやん
しかし
PyDriveでやってみることしたのは良いのだけれど....
えっ....
なんか.....
だいぶ...........
使いづらい.......
何なん???いや、マジで
ということで、どうせまたColaboratory使う時に色々忘れちゃうからここに書くことにする
1. ColaboratoryでGoogleDriveをマウントする
PyDriveを使ってGoogleDriveをマウントする方法は、Qiitaにも色々記事が上がっているし、Colaboratoryのデフォルトのスニペットにもあるので、下のコードをとりあえず写経しとけば良いはず
GoogleColaboratory で使う画像をGoogleドライブからコピー
google Colaboratoryでファイルを読み込む方法
# Install the PyDrive wrapper & import libraries.
# This only needs to be done once per notebook.
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Authenticate and create the PyDrive client.
# This only needs to be done once per notebook.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
これを実行すればどのGoogleアカウントでマウントするかを指定して、Colaboratory上で認証コードを打ち込む作業が発生
無事認証が通れば、ColaboratoryにGoogleDriveがマウントされている
Colaboratory上でPyDriveを用いずにGoogleDriveにアクセスしたい場合
マジックコマンド使ってshellライクにアクセスしたい場合には下のようにやれば良いらしい
from google import colab
colab.drive.mount('/content/gdrive')
!ls 'gdrive/My Drive'
みたいにアクセスすることも可能
ここら辺の話は
This notebook provides recipes for loading and saving data from external sources.
を読めばだいたいわかる
2. GoogleDriveの中身を確認する
まず今、GoogleDriveの中にはroot部分に3つのフォルダーと
- dat
- tmp
- ColabNotebooks
とSample file.txtのテキストファイルがある前提で進める
自分のルートのGoogleDriveの中に何が入っているかを確認する場合には、
# GoogleDriveのインスタンスをリストで取得する
file_list = drive.ListFile({'q': "'root' in parents and trashed=False"}).GetList()
# インスタンスの中に辞書で色々情報が入っているから指定して取り出す。この場合は、ファイル(フォルダ)名取得
[file['title'] for file in file_list]
>> ['Sample file.txt', 'tmp', 'dat', 'Colab Notebooks']
こんな感じで、ListFileでアクセスすると中身を確認できる。
でもこのListFileで指定するクエリが結構わかりにくい
なので、もうちょっと使い方をちゃんと確認する
2.1 フォルダを確認する
上の例では、rootにあるファイルもしくはフォルダー全てを取得して一覧を出しているだけなので、対象がファイルなのかフォルダなのかわからない。拡張子でなんとなくわかるけど。。。
folder_list = drive.ListFile({'q': "'root' in parents and trashed=False and \
mimeType = 'application/vnd.google-apps.folder'"}).GetList()
[file['title'] for file in folder_list]
>> ['tmp', 'dat', 'Colab Notebooks']
paramatorの中にandでmimeType = 'application/vnd.google-apps.folder'を指定するとフォルダのみを取り出せる
2.2 ファイルを確認する
ファイルだけを検索したい場合も同じ感じで出来る。。と思いきや出来ない!!!!!!![]()
自然な発想からするとmimeType = 'application/vnd.google-apps.file'で取り出せそうだし、それで取り出せるものもあるのだけれど、Sample file.txtはこれでは取り出せない
file_list = drive.ListFile({'q': "'root' in parents and trashed=False and \
mimeType = 'application/vnd.google-apps.file'"}).GetList()
[file['title'] for file in file_list]
>> []
# textファイルのmimeTypeは'text/plain'
text_list = drive.ListFile({'q': "'root' in parents and trashed=False and \
mimeType = 'text/plain'"}).GetList()
[file['title'] for file in text_list]
>> ['Sample file.txt']
結構細かくmimeTypeを指定しなければいけないっぽいので、ちゃんと取り出そうとすると公式のリファレンスを見るのが近道
一応抜粋しておく
| MIME Type | Description |
|---|---|
| application/vnd.google-apps.audio | |
| application/vnd.google-apps.document | Google Docs |
| application/vnd.google-apps.drawing | Google Drawing |
| application/vnd.google-apps.file | Google Drive file |
| application/vnd.google-apps.folder | Google Drive folder |
| application/vnd.google-apps.form | Google Forms |
| application/vnd.google-apps.fusiontable | Google Fusion Tables |
| application/vnd.google-apps.map | Google My Maps |
| application/vnd.google-apps.photo | |
| application/vnd.google-apps.presentation | Google Slides |
| application/vnd.google-apps.script | Google Apps Scripts |
| application/vnd.google-apps.site | Google Sites |
| application/vnd.google-apps.spreadsheet | Google Sheets |
| application/vnd.google-apps.unknown | |
| application/vnd.google-apps.video | |
| application/vnd.google-apps.drive-sdk | 3rd party shortcut |
すげーいっぱいあるじゃん。。。めんどくせ
しかもpngを保存する場合には/image/pngみたいな感じで指定するらしい。よくわからん
なので、普段はフォルダでないものを検索してファイルを検索したことにしている
obj_list = drive.ListFile({'q': "'root' in parents and trashed=False and \
mimeType != 'application/vnd.google-apps.folder'"}).GetList()
[file['title'] for file in obj_list]
>> ['Sample file.txt']
多分これがファイルの一覧を確認する場合には一番良いのでは??
2.3 指定フォルダ内のファイル一覧を確認する
ここまで、言及してなかったけれどGoogleDriveは1つ1つのオブジェクトに対してidが付与されている
そして、このIDを使ってファイルアクセスする処理が頻繁に発生する
特定のフォルダ内のファイルを確認したい場合もフォルダのIDを指定する必要がある
tmpフォルダー内のファイル一覧を取得する場合、まずはtmpフォルダーのIDが何かを特定してからファイル一覧を取得する
# tmpフォルダーのIDを取得する
tmp_folder_id = drive.ListFile(\
{'q': "'root' in parents and title= 'tmp' and trashed=False and mimeType = \
'application/vnd.google-apps.folder' "}).GetList()[0]['id']
# tmpフォルダーのIDを親フォルダーに指定して中身を確認する
file_list = drive.ListFile(
{'q': """'{folder_id}' in parents and trashed=False""".format(folder_id=tmp_folder_id)}).GetList()
[ (file['title'],file['id'] ) for file in file_list]
# 出力結果
>>[('display.png', '1L0ydU7oXcdWZzoWR5CJpighLV-YzZtQW'),
('Sample upload.txt', '1yyxy_xd592Cj2JV_PWSj54f922Rp4iGH')]
'ID' in parentsで指定したフォルダ内のファイルだけを対象に検索が可能。rootにしておけば、自分のrootフォルダーにあるものだけが検索対象になる。逆に'ID' in parents`を記載しなければ、root配下全てのファイルから検索することになる
3.GoogleDriveにファイルをUploadする
次に、ファイルのUploadについて考える
Colaboratoryで作業したファイルをGoogleDriveに保存したい場面はよくあるので、ここはちょっと詳しめに調べる
PyDriveではCreateFile()で色々やり取りすることになる
3.1 文字列をUploadする
単純な文字列をUploadする方法はColaboratoryのスニペットにもあるので、写経すると
# Create & upload a text file.
uploaded = drive.CreateFile({'title': 'Sample file.txt'})
uploaded.SetContentString('Sample upload file content')
uploaded.Upload()
print('Uploaded file with ID {}'.format(uploaded.get('id')))
- CreateFileで保存先に格納するファイル名を渡す
- SetContentStringで中身を渡す
- Uploadで実際にUploadする
という3つの工程に分かれている
基本は、この3つの工程なのだけれど、文字列を直接渡すケースはそれほど多くないので、使い道は限定的
3.2 既存のファイルをGoogleDriveにUploadする
既存のファイルをUploadする場合、こんな感じでコンテンツをセットすれば良い
# 適当にファイルを作成する
df_sample = pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c'])
file_name = 'df_sample.csv'
df_sample .to_csv(file_name)
# 作成したCSVファイルの名称を指定
upload_df = drive.CreateFile({'title':'df_sample.csv'})
# ローカルファイルPathを指定
upload_df.SetContentFile(file_name)
upload_df.Upload()
実際にGoogleDriveを確認すると確かにrootフォルダにファイルがUploadされている
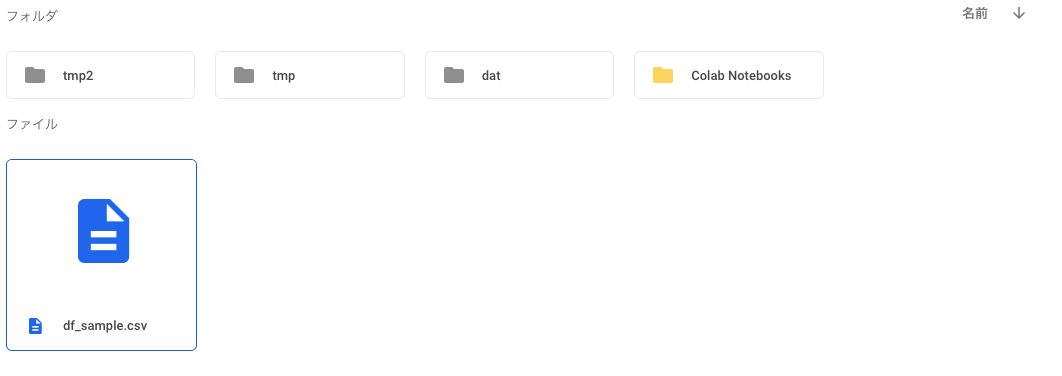
SetContentFileで既存のファイルを指定すれば大丈夫
3.3 指定フォルダにファイルをUploadする
ここで、一つ問題が発生。。。
基本的にファイルはrootフォルダに格納されるのだけれど、rootばかりに保存するわけにもいかない
指定したフォルダに保存したいが、その方法がわからない。。
公式のリファレンスもあまりそこらへんは詳しく書かれていないので、困り果てる
しかし、stackoverflowにそれっぽい記載が。。
pydrive-cannot-write-file-to-specific-gdrive-folder
なるほど。。。
試しにtmpフォルダに先ほどのファイルをUploadしてみる
# tmpフォルダのIDを取得
tmp_folder_id = drive.ListFile(
{'q': "'root' in parents and title = 'tmp' and trashed=False and \
mimeType = 'application/vnd.google-apps.folder' "}).GetList()[0]['id']
# メタデータを作成。ここでファイル名、格納先の指定を行う
_meta = {
'title':'df_sample.csv',
'parents': [{'kind': 'drive#fileLink','id': tmp_folder_id}]
}
# metaデータを渡して諸々の設定を指定
upload_df2 = drive.CreateFile(_meta)
upload_df2.SetContentFile(file_name)
upload_df2.Upload()
parentsを指定すると指定したフォルダに保存できる
ただ、注意点としてはparentsにidだけ渡してもうまくUploadされず、kindにfileLinkを一緒に渡す必要がある
3.4 メタデータに詳細な設定を指定してデータをUploadする
CreateFileにメタデータを渡すことで詳細な設定を反映できることがなんとなくわかった
PyDriveにはメタデータに関する詳細な説明はないので、更に遡ってGoogle Drive APIのリファレンスを見にいく
特に重要そうなプロパティを詰め込んでUploadしてみる
Googleのバナー画像を取ってきてtmpフォルダに格納する
! pip install requests
import requests
# googleのアイコンバナーを取得してきてGoogleDriveに保存する
url_png = 'http://www.google.co.jp/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png'
file_name_g = 'google_banner.png'
req = requests.get(url_png)
with open(file_name, 'wb') as f:
f.write(req.content)
# メタデータ作成
_meta = {
'title': 'google_banner.png', # GoogleDriveに格納するファイルの名称を指定
'parents': [{'kind': 'drive#fileLink','id': tmp_folder_id}], # 格納フォルダを指定
'mimeType' : 'application/vnd.google.drive.ext-type.png', # ファイルタイプを指定
'kind' : 'drive#file', # ファイルの種類を指定 *デフォルトはfileなので基本は記載不要
'description':'Google banner', # ファイルのディスクリプションを設定したい場合はここに記載
'editable':False # 編集可否を指定
}
# メタデータを指定して画像ファイルを格納
upload_g = drive.CreateFile(_meta)
upload_g.SetContentFile(file_name_g)
upload_g.Upload()
3.5 PyDrive以外の方法でファイルをUploadする
ここまでPyDriveの説明をしてきたけれどもPyDriveを使わない方法もあるので、一応紹介しておく
↓の記事を参考にしました
Google Colaboratoryでファイルを読み込む
import google.colab
import googleapiclient.discovery
import googleapiclient
google.colab.auth.authenticate_user()
drive2 = googleapiclient.discovery.build('drive', 'v3')
media = googleapiclient.http.MediaFileUpload(
"google_banner.png",mimetype='application/vnd.google.drive.ext-type.png')
file_metadata = {
'name': "goolge_banner2.png",
'mimeType': 'application/vnd.google.drive.ext-type.png',
'parents': [tmp_folder_id]
}
drive2.files().create(body=file_metadata,
media_body=media,
fields='id').execute()
csvでもMediaFileUploadでいける
# csvファイルを指定
media_csv = googleapiclient.http.MediaFileUpload("df_sample.csv",mimetype='text/csv')
file_metadata_csv = {
'name': "df_dample2.csv",
'mimeType': 'text/csv',
'parents': [tmp_folder_id]
}
drive2.files().create(body=file_metadata_csv,
media_body=media_csv,
fields='id').execute()
この場合、parentsは単純にIDを渡すだけで良い。何故?
4 GoogleDriveからファイルをDownloadする
Uploadはこれくらいにして次はDownloadの方法をまとめておく
ColoaboratoryにGoogleDriveにあるデータを持ってくるのは、IDを指定するだけで良いので簡単
IDを取得するのがめんどくさいけど。。。
4.1 ファイルをDownloadする
先ほどGoogleDriveにUploadしたdf_sample.csvをdf_sample_download.csvとしてColaboratoryに持ってくる
# rootにあるdf_sample.csvを取得する
# まずはdf_sample.csvのGoogleDrive上のIDを取得する
_id = drive.ListFile({'q': "'root' in parents and title= 'df_sample.csv' and trashed=False and mimeType='text/csv' "}).GetList()[0]['id']
# ColaboratoryにDownloadした時の名前を決める
file_name_download = 'df_sample_download.csv'
# IDを指定してダウンロードする
downloaded = drive.CreateFile({'id': _id})
downloaded.GetContentFile(file_name_download)
CreateFileでメタデータを渡してGetContentFileでDownloadできる
DownloadもUploadもどっちもCreateFileなのは違和感あるけど、まぁこれでいけるっぽい
4.2 フォルダーごとDownloadする
結論から言えば、おそらくフォルダーの中身をそのままColaboratoryにDownloadすることはできない(はず)
フォルダーに含まれるファイルをフェッチしてきて一つづつDownloadすることになる(はず)
しかも、(調べた限り)DownloadはColaboratoryのrootディレクトリにしか出来ないので、ファイルは都度移動させておく必要がある
結構不便なので、そのうち改修されるのではと思っている(ただの願望)
なので、まずColabaoratory側に格納したいディレクトリを事前に作っておいて、Downloadする度に移動させる
import os
import shutil
# Colaboratory側に格納用ディレクトリを事前に作成しておく
local_folder_name = 'tmp_local'
os.mkdir(local_folder_name)
# tmpにあるdf_sample.csvとgoogle_banner.pngをDownloadする
# 親フォルダーのtmpのIDを取得する
tmp_folder_name = 'tmp'
tmp_id = drive.ListFile({'q': "'root' in parents and title= '{folder_id}' and trashed=False and mimeType='application/vnd.google-apps.folder' ".format(folder_id=tmp_folder_name)}).GetList()[0]['id']
# GoogleDrive上のtmpフォルダー内にあるファイルの一覧を取得してくる
list_files = drive.ListFile({'q': "'{folder_id}' in parents and trashed=False and mimeType !='application/vnd.google-apps.folder' ".format(folder_id=tmp_id)}).GetList()
# ローカルのrootにダウンロードしてきて、指定したファイルに移動させる
for file_obj in list_files:
_title = file_obj['title']
_id = file_obj['id']
_download = drive.CreateFile({'id': _id})
_download.GetContentFile(_title)
# GoogleDriveのファイル名をそのまま移動する
shutil.move(_title, local_folder_name)
マジックコマンドでちゃんとColaboratoryに格納されているか確認
# マジックコマンドで確認
!ls tmp_local
> df_sample.csv google_banner.png
ちゃんと入っている!!
5 その他操作
最後にそれほど利用頻度は高くないが、覚えておくと便利な基本機能をまとめておく
5.1 ファイル削除
ファイルの削除は、ゴミ箱に移動させるTrashと完全に削除するDeleteが存在
通常はTrashを用いるので良さそう
# df_sampleをTrashする
# 親フォルダーのtmpのIDを取得する
tmp_folder_name = 'tmp'
tmp_id = drive.ListFile({'q': "'root' in parents and title= '{folder_id}' and trashed=False and mimeType='application/vnd.google-apps.folder' ".format(folder_id=tmp_folder_name)}).GetList()[0]['id']
# GoogleDrive上のtmpフォルダー内にあるdf_sample.csvを取得してくる
_file_name = 'df_sample.csv'
id_df_sample = drive.ListFile({'q': "'{folder_id}' in parents and trashed=False and title = '{file_name}' and mimeType !='application/vnd.google-apps.folder' ".format(folder_id=tmp_id,file_name=_file_name)}).GetList()[0]['id']
_trash= drive.CreateFile({'id': id_df_sample})
_trash.Trash()
# google_banner.pngは完全にDeleteする
# GoogleDrive上のtmpフォルダー内にあるgoogle_banner.pngを取得してくる
_file_name = 'google_banner.png'
id_ggl_banner = drive.ListFile({'q': "'{folder_id}' in parents and trashed=False and title = '{file_name}' and mimeType !='application/vnd.google-apps.folder' ".format(folder_id=tmp_id,file_name=_file_name)}).GetList()[0]['id']
_delete= drive.CreateFile({'id': id_ggl_banner})
_delete.Delete()
5.2 フォルダー作成
GoogleDriveにフォルダーを新規で作成したい場合もUploadを用いれば良いのだが、mimeTypeをフォルダーに指定しておかないとデフォルトだとファイルが作成されてしまうので注意
# フォルダーを新規で作る場合は、mimeTypeをfolderに指定しておけばOK
new_folder_name = 'NewFolder'
new_folder= drive.CreateFile({'title': new_folder_name, 'mimeType':'application/vnd.google-apps.folder' })
new_folder.Upload()
おわりに
使用頻度の高そうな処理についてはフォローしたつもり
ただ、書いていて思ったけど毎回ListFileからIDを指定してファイルオブジェクトを取ってくるのがすごく面倒くさいのでGoogleDriveのIDを指定したらダイレクトにファイルオブジェクトを取ってこれるAPIを提供して欲しい。。。![]()
おしまい