やってることを3行で
- AutoML Visionを使えば自分が持つラベルつき画像を学習させて、個別の画像認識問題を解けるようになる
- ローカルPCの画像やGCSに溜めているFIFAのプレイ画像をAutoML Visionに食わせてラベルをつけた
- 極めて少ないサンプルでもインプレイ画像とハイライトや得点シーンなどのアウトオブプレイ画像をちゃんと識別してくれている(勿論、問題設定によってはサンプルが重要なこともある)
AutoML Visionとは
公式リファレンスによると
Cloud AutoML は機械学習プロダクトのスイートです。AutoML を利用すると、機械学習の専門知識があまりない開発者でも Google の最先端の転移学習とニューラル アーキテクチャ検索技術を利用して、ビジネスニーズに合った高品質のモデルをトレーニングできます。
機械学習プロダクトのスイートってなんや?![]()
要はこういうことかと。。
- Cloud AutoML Visionが機械学習モデルをトレーニングして、自分の定義したラベルに従って画像を分類可能
- 自分で画像認用のモデルをゴリゴリ作成する必要がないので、統計や深層学習の知識は不要(しかし、2値・多値分類の評価方法ぐらいは知っておく必要がある)
- ただし本格的に導入しようとしたらそれなりにお金が掛かるので資金はあるが技術がない人には最適
AutoMLでFIFAの画像を分類する
以前に単純な機械学習のアルゴリズムでFIFAのプレイ動画のシーンを識別してプレイ部分だけを再編集した動画を生成できるか検証したが、今回はAutoML Visionを使って同じようにシチュエーションの異なるシーンを識別できるか検証する
Qiita: 機械学習を使ってゲーム動画からプレイシーンだけを抽出出来るか検証する。ちなみにだいたい出来た。
1.GCSにプレイ画像のキャプチャをUploadする
自分のPCから直接画像ファイルをあげることもできるが、GCS(GoogleCloudStorage)からもUploadできるので、AutoMLのデータインポート画面で提示されているgs://{自分のPJのパス}の配下に画像ファイルを格納しておく
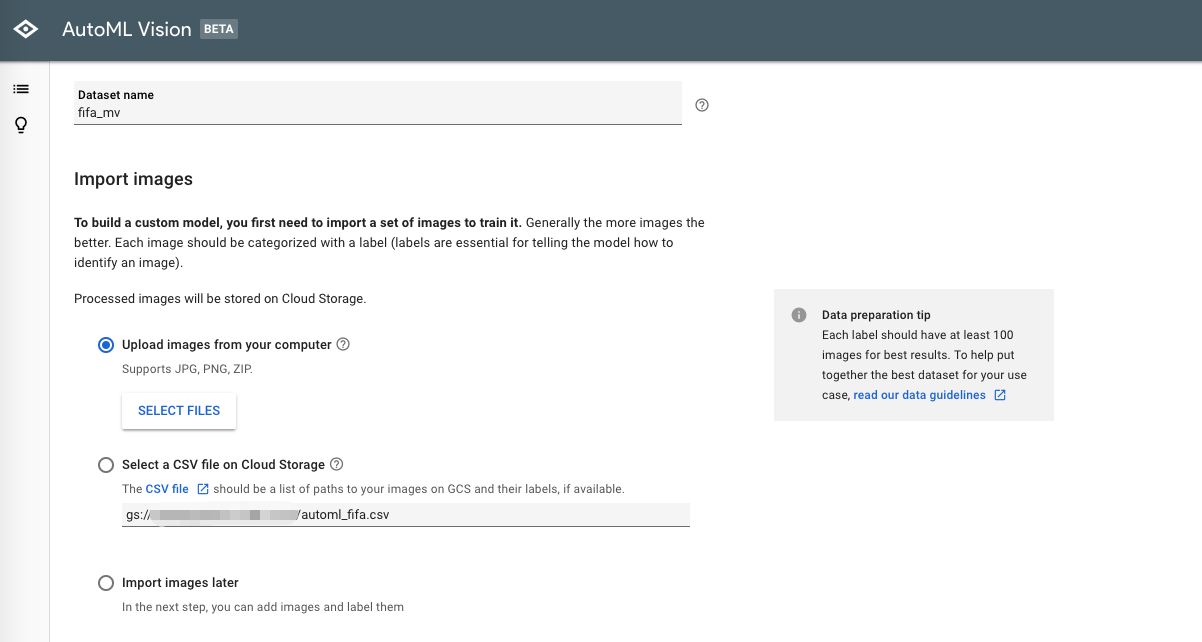
2.AutoMLにGCS(or ローカルPC)から画像をUploadする
AutoMLに対して画像をUploadする方法は、主に2つ
- 自身のPCにある画像を直接Uploadする
- Upload対象のGCSに格納してある画像ファイルを指定したCSVファイルを読み込ませてUploadする
パッと試したければ自身のPCから直接画像をあげるのでいいと思うが、APIの活用を視野に入れる場合は2の方法も検討した方が良い
しかも、2の場合には画像のPATHを指定したCSVファイルにラベルを事前につけておくことが出来るので、画面上でラベリングを後でしなくても良いため結局楽かも。。。
csvはこんな感じで用意する
# gcsのファイルパス,ラベル
gs://{sample.csvと同一バケット}/inplay/fifa_cap_0001.png,inplay
gs://{sample.csvと同一バケット}/inplay/fifa_cap_0002.png,inplay
gs://{sample.csvと同一バケット}/inplay/fifa_cap_0003.png,outplay
gs://{sample.csvと同一バケット}/inplay/fifa_cap_0004.png,setting
*画像のパスを記載したCSVファイルと同じバケットに画像ファイルを置いておく必要があるので注意
そしてGCSを利用する場合は、事前にAutoMLがGCSに対してアクセスできるようにAPIを有効にしておく必要がある
*詳しくはクイックスタートのページを参照
3.インプレイ画像とアウトオブプレイ画像をラベル付けする
画像をUploadし終えると、画面上でラベルを付与できる
ローカルPCからUploadする場合には、事前にラベルごとにフォルダーを分けておいて
全選択->ラベルの一括付与
でラベリングしていった方が手っ取り早い
勿論、GCSでCSVに事前にラベルを付与しておけばこの工程は完全に省ける
ラベルの付与を終えるとこんな感じになる
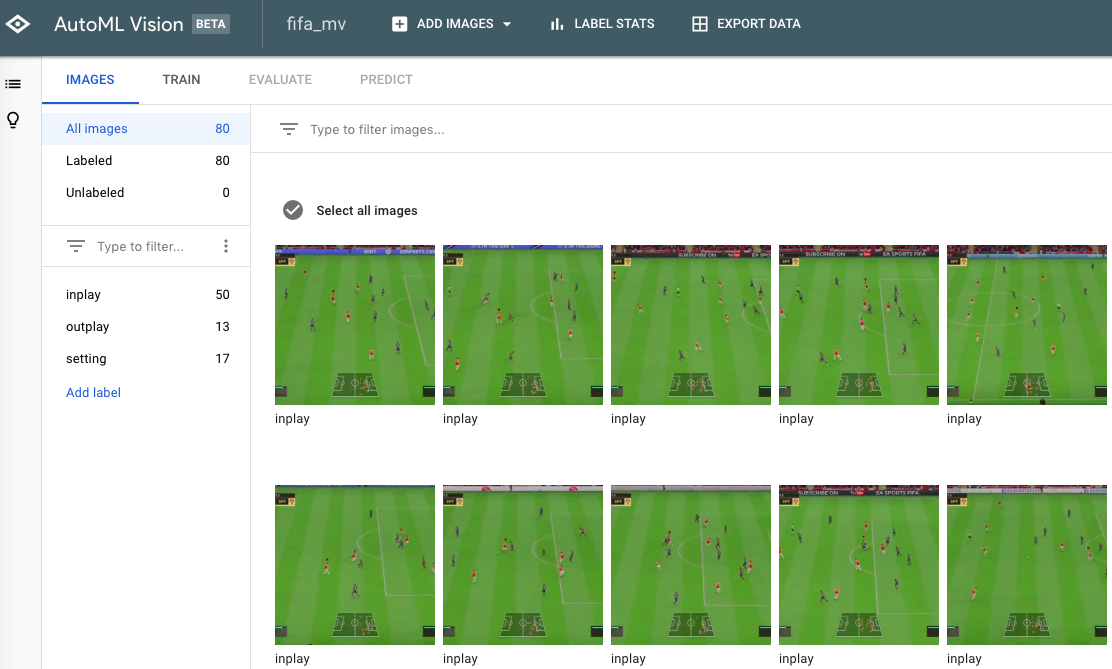
以前Qiitaに書いた記事で定義したシチュエーションを継承し、
- inplay -> 実際に操作している時の画像
- outplay -> 交代やハイライトのように操作してない時の画像
- setting -> 選手交代の設定やハーフタイム画面のような設定画面の画像
の3種類のラベルを付与
4.画像を学習させる
画面上から学習を実施するのは、極めて単純で[TRAIN]タブに移動して、Train、Validation、Testの設定をしてTrainボタンを押すだけ
今回はたった80サンプル程度しか用意してないため(推奨は1000枚、各ラベル最低10−50枚は必要)厳密な識別は難しいと思うが、inplayと他の2つは未知画像に対しても完全に識別して欲しいところ
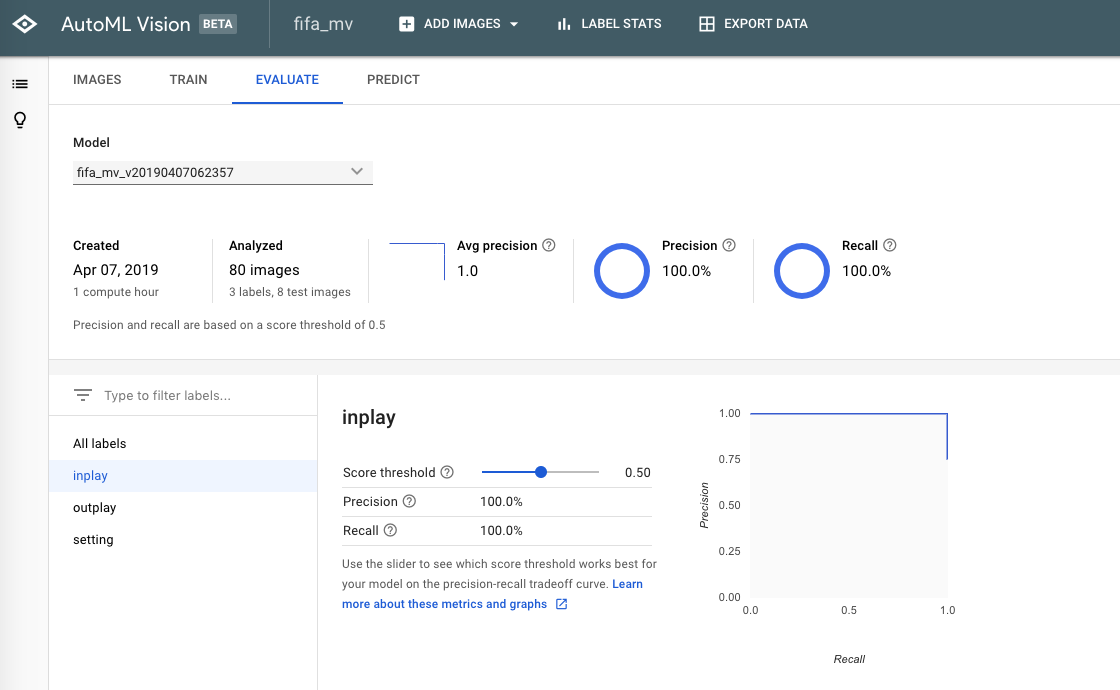
5.学習結果を確認する
学習ボタンを押してから10分ほどするとモデルが出来上がっていた。。。
が、80サンプルしかないので早いだけで恐らく1000枚程度用意したらもっと時間が掛かると思われる
こんな感じでそれぞれのラベルの識別精度を確認できるようになっている
サンプルが少なすぎて、Precision/Recallの数値があまり参考にならないが、1000件くらいデータを用意できれば十分意味のある考察が可能なはず
6.未知データに対して適用する
では作成された学習済みモデルに対してTrainにもValidationにも含まれない未知の画像を適用してどの程度精度が出るか確認していく
今回は、4つの画像を例にスコア結果を確認する
1. 別の試合のインプレイ画像
まずは、学習に使った試合とは別の試合のインプレイ画像を識別させた結果を見ると
↓
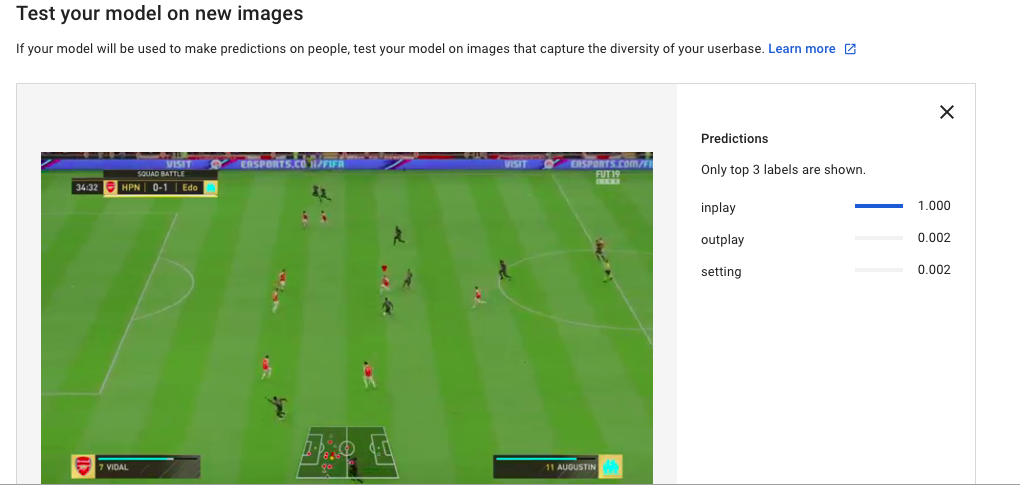
完全に正解ラベルに識別されてる!!
議論の余地がないぐらい完全に識別されてる。。。
まぁ、これくらいは楽勝と言うことか。。。
2.学習に含まれないGKのハイライトシーン
次に、学習には存在していないGKが点を入れられて悔しがっている様子がどのように識別されるか確認すると
↓
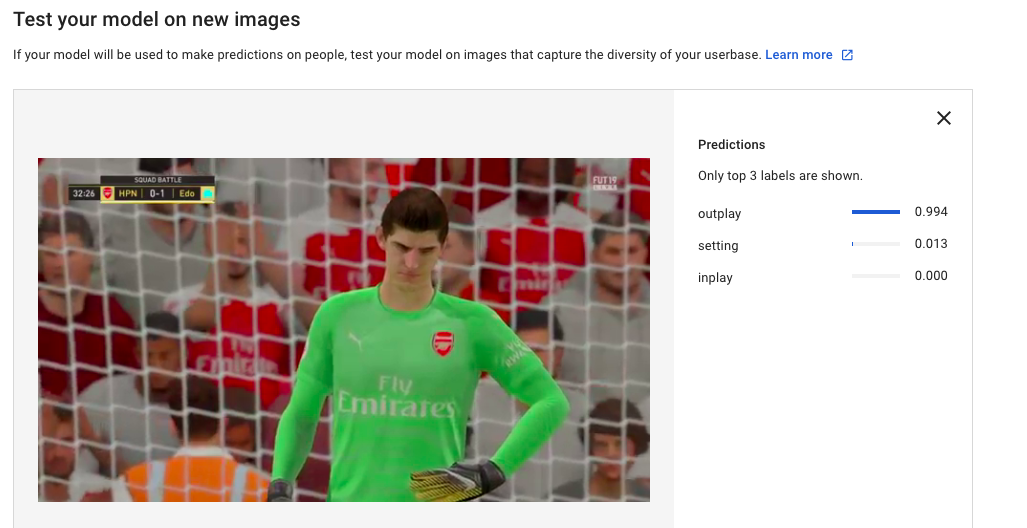
おぉーーー!!!
ちゃんとoutplayと識別してるじゃないのぉ!!
やるやん!!
10件くらいしかoutplay画像用意せんかったのに!!
3.試合後のスタッツ画面
試合終了後のsettingに該当する画像は、どの程度ちゃんと識別するかも確認
ちなみに下の画像と完全同じ場面に該当する画像は学習には含まれていないので、outplayと識別できない可能性もあるあが。。。
↓
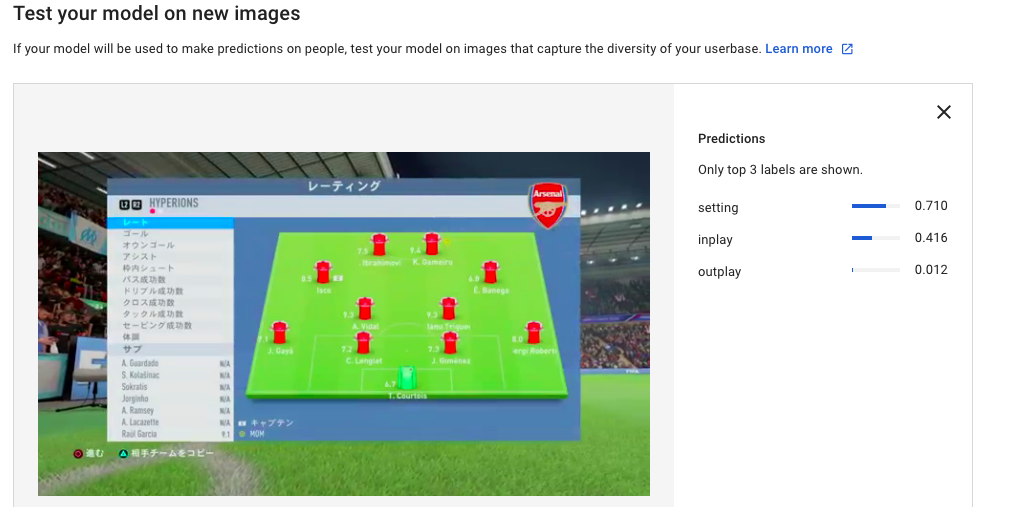
むしろ、inplayの方が可能性あると見てるんかい!!
まぁ、settingが一番スコア高いんでいいけど。。。
多分、画面に占める緑の割合(と位置)が重要視されてる気がする
4.ゴール後のセレブレーションシーン
inplayのように引きの絵ではないものの画面に占める緑の割合が比較的多い画像の結果を最後に適用してみる
↓
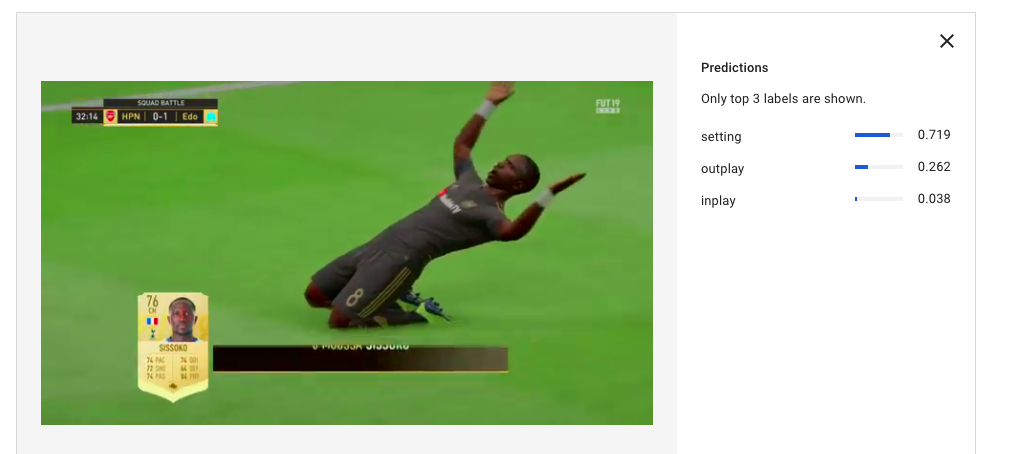
setting:0.719
残念。。
これはoutplayと認識して欲しかったんだよなぁ。。。
ほとんどセレブレーションシーンを学習に入れてないからかなぁ。。。
まとめ
確かにAutoML Visionを使うと前提知識なく画像を食わせてラベルをつけたら個別の画像認識問題を解けるようになることを確認した
しかも、画像を用意してから予測結果を得るまで1.5時間くらい(多分、画像のラベルづけに手間取らなければもっと早い)でできるのはすごく良い気がする
小さなデータセットでやったのでsettingとoutplayで一部ちゃんと識別できていなかったが、十分なデータ量を与えれば完全に識別してくれる気がする
本格的に導入するとなるとそれなりにお金がかかるので(月10モデルまで学習時間1時間は無料だけど)そこが問題なければ画像認識の課題解決のファーストチョイスになるかも。。。
おしまい