はじめに
Tableauを勉強する上で避けて通れないデータの結合(一般的な意味で)ですが、正直めっちゃわかりづらい。
なぁなぁにしてしまうのもアレなので、自分なりにまとめてみることにします。
※ 前提知識としてデータベースのJOINだとかはある程度わかっている体で書きます
先に結論
なかなかに長いブログになってしまったので、結論を先に書くと、
データソースが1つなら関係を使う。データソースが別ならブレンドしたあとプライマリグループにする。後は気にしない
以上です!!
なんでそうなるのかは、以下をお読みいただければと思います。
たくさんある用語
なにが分かりづらいって、データ結合まわりの機能がたくさんあるんですよね、Tableauって。
しかもそれぞれがしっかりと別の役割があるので、うろ覚えのまま「このデータとデータを結合(機能的な意味で)しよう!」と思っても、あれ? データソース違うとできないぞ…? とかなるわけです。
そして、「結合」と言う機能があるので、
「結合機能のことを言ってる場合」 = 機能的な意味の「結合」
と
「データを組み合わせる機能の総称として結合と言ってる場合」 = 一般的な意味の「結合」
とがごっちゃになりがちなのがさらにややこしいのです。
(記事中では以後、後者の一般的な結合を「がっちゃんこ」と記載します)
というわけで、ひとまず思いつく限りその辺の単語を列挙します。
- 結合
- クロスデータベース結合
- ブレンド
- 関係
- リレーションシップ
- プライマリグループ
- 左結合、右結合(left/right join)
- 内部結合、外部結合(inner/outer join)
- ユニオン
多い。
もうね、あわあわもしますよこれは。
僕はただデータをがっちゃんこしたいだけなのに…!!
あわあわしないために、まずは簡単にこれらの単語を整理します。
- 結合
- ユニオン
- 左結合、右結合(left/right join)
- 内部結合、外部結合(inner/outer join)
- クロスデータベース結合
- ブレンド
- プライマリグループ
- 関係
- リレーションシップ
まず、ユニオンや左・右・内部・外部結合は結合の機能の一部です。
そしてクロスデータベース結合は、機能名ではなく概念的な言葉です。(後述しますが、データベースを跨いで結合機能を使うことを指します)
プライマリグループもブレンドに付随する機能ですし、リレーションシップに至っては関係を英語で言ってるだけです。
ほら、機能の種類で言うとたった3つになりました!
ずいぶん警戒度が下がりませんか?
データソース、接続、シート
結合まわりを整理するには、その前に、データソースの構造について整理する必要があります。
Tableauにおいてデータは大きい順に
- データソース
- 接続
- シート
という構造になっています。
データソースタブで言うと、こうです。
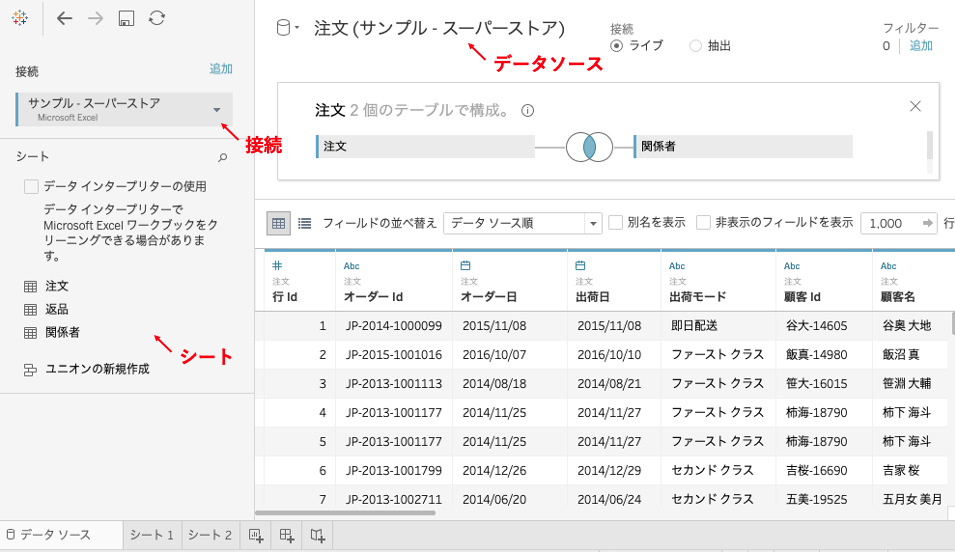
「データソース」というのはTableauでVizを作るにあたっての、データの1つのおおきな塊です。
Vizを作る時にイメージするデータのテーブルそのものですね。(伝われ)
で、そのデータソースがどこからデータを引っ張ってきているか、が「接続」です。
(データソースのデータソースとでも言いましょうか。いえ、ややこしいだけなのでやめときましょう)
例えばエクセルのファイルだったり、MySQLのデータベースだったりします。
そして「シート」が、各「接続」から取ってきたデータテーブルを指します。
なんで接続とシートが分かれてるかと言うと、1つのエクセルに複数シートでいろんなデータテーブルがあるケースが多いからですね。
これらの関係性を言葉にすると、
あるエクセル(接続)からとってきたデータ(シート)を組み合わせた1つのテーブル(データソース)
となるでしょうか。
で、実際にVizを作るときは「接続」や「シート」は気にせず、その完成品である「データソース」を見るわけですね。
で、データ結合の整理
データ結合の話に戻ります。
なんでデータソースの話をしたかというと、どの部分でデータをがっちゃんこしようとするかによって、使う機能が分かれているからです。
| 機能 | データソース | 接続 | シート |
|---|---|---|---|
| 結合、関係 | 同じ | 同じ | 異なる |
| 結合、関係 (クロスデータベース結合) | 同じ | 異なる | 異なる |
| ブレンド | 異なる | 異なる | 異なる |
いいじゃん、全部1つの機能でできるようにすれば!
と思うかもですが、そうも行かないのですね。
その理由は後述します。
結合( + ユニオン、◯◯結合、クロスデータベース結合)
結合は同じデータソース内で異なるシートをがっちゃんこする話です。
ユニオン、クロスデータベース結合も同じ結合の話なのでここで説明します。
結合、◯◯結合
結合は、いわゆるデータベースをSQLでJOINする、というあのイメージそのままでOKです。
注文データと、製品データが別々にあるので、注文データに含まれる製品idをキーにして1つのデータにしたい、とかそういうケースですね。
Tableauでの操作としては、まず1つ目のデータを読み込んだ状態から、そのデータの四角をダブルクリックします。

すると結合の画面に切り替わります。
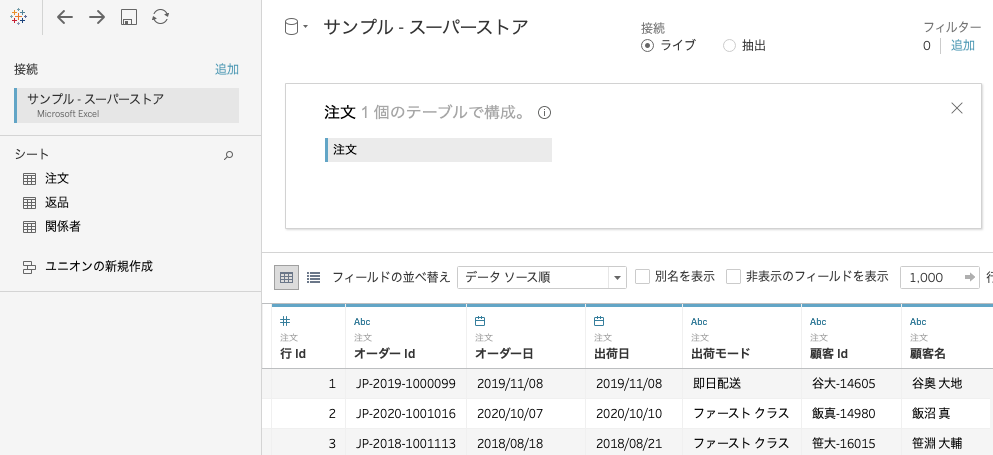
この枠に結合したいシートをドラッグアンドドロップすると…
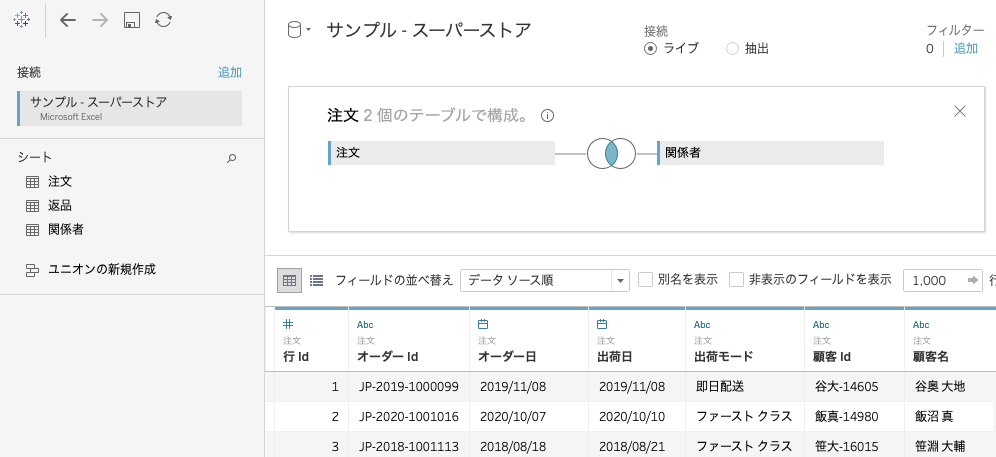
はい、これで結合完了です。
最後に、SQLわかる方なら説明の必要もないとは思いますが、左/右結合、内部/外部結合とか言ってるのは、この時にどうやって結合するかの種類のことを指します。

ユニオン
ユニオンは、やっぱりSQLでいうところのUNIONです。
注文データの1月分と2月分が別々のデータにあるので、1つにまとめたい、とかいうケースです。
先ほど同様、まず1つ目のデータを読み込んだ状態から、そのデータの四角を今度はクリックしてメニューを出すと「ユニオンに変換」があるのでこれをクリックします。
(先ほど同様、ダブルクリックしてからでもユニオンに変換できますし、結合と同様にドラッグアンドドロップで既存のデータに上に落としてもできます)

するとユニオンのダイアログが開くので、ここにユニオン結合したいデータをドラッグアンドドロップすれば完了です。

クロスデータベース結合
上記のように結合とユニオンができるわけですが、この時、がっちゃんこするのが別々の接続のシートだった場合は特にクロスデータベース結合と言います。
データベースを跨いでる、のでクロスデータベース、ですね。
ただ、別に「クロスデータベース結合」という機能があるのではなく、ただ接続を跨いで結合/ユニオン機能を使うことをそう言っているだけです。
なんとなく機能名っぽい雰囲気出してるのでややこしいですけどね。
※ただし、パフォーマンスの面で見ると、結合がDBレイヤーで行われるのに対して、クロスデータベース結合の場合はローカルメモリ上で行われるなどの違いがあります。
関係(リレーションシップ)
(この、関係という概念が、個人的にはまだすっきり飲み込めていないので、正確さに欠けることを言うかもしれません…)
次に、関係についてです。
前述の通り、リレーションシップはただ関係をカタカナで読んでるだけですので、関係機能だけわかればOKです。
(厳密には、関係機能でがっちゃんこしたデータ間の結びつきのことをリレーションシップと呼ぶようですが、あんまり意識しなくていい気がします)
関係とはなにか?とざっくりいうなら、「Tableauがいい感じにしてくれる結合機能」 だと思います。
いい感じってなんじゃい、となると思いますが、実際、この「いい感じ」をちゃんと理解するハードルが高いので、結合と関係機能がごっちゃになるんだと思ってます。
UI操作
まずはUIの説明から。
結合のときは、この「注文」をダブルクリックしましたが、関係の場合は、このフィールドに直接シートをドラッグ&ドロップします。

すると、こんな感じの画面になります。(このオレンジの線こそが、リレーションシップなんだそうです)

ダイアログには「注文」側のフィールドと「関係者」側のフィールドを選ぶUIが表示されています。
「ここで、片方のデータと、もう片方のデータのこのフィールドが、同じものを指してるんだよ!」と指定するわけです。
で、結合と違うのはこれでおしまい、ということです。
外部結合とか左結合とかは選びません。
なぜなら、そこはTableauが「いい感じに」やっといてくれるからです。
結局、結合と何が違うのか
Tableauとしては、結合ではなく関係が推奨とのこと。
これは、結合がガチガチのユーザー定義でTableauが手を加える余地がないのに対して、関係は緩い定義なので利用用途に応じてTableauがパフォーマンスチューニング等を行えるからです。
結合はDBですでに結合されているのに対して、関係はそのデータがVizでどう使われてるのかを見て最適化しているわけですね。
普段DBをいじってる人間からすると、ついつい「あ、これはOuter joinだな」とか思って結合したくなるのですが、Tableauを使うのであれば、ちょっと「いい感じ」を信じてみて関係を使ってみるのが良いわけです。
ちなみに、接続を跨いで関係を使う時もクロスデータベース結合っていうのかしら?
ブレンド( + プライマリグループ)
ここまでの説明で、結合と関係は、割と似た機能だということがわかると思います。
それに対して、異なるデータソースに存在するデータ同士を結合するには、ブレンド機能を使います。
なので、ざっくり言ってしまえば、
データソースが同じなら関係(結合より推奨)、データソースが別ならブレンド
です。
「いやいや、1つのデータソースに全部取り込んじゃえば関連だけで済むじゃん」
と思うかもしれません。
僕もそう思います!
が、データソース単位でパッケージングされているデータを持ってきて使う場合、そのデータソースを変更することはできません。
そうするとどうしても複数のデータソースを扱う必要が出てきます。
データのコラボレーションをするために必要な機能な訳です。
なので逆に、1人でデータ収集してTableauを使って、とやっているとお世話になる機会が少ないかもしれませんね。
ブレンド
ブレンドとプライマリグループの2つがありますが、まずはブレンドから。
UI操作を見ればイメージが掴めるかと思います。
UI操作
前述の通り、データソースを複数読み込む必要があるので、データソース名の横の▼をクリックし、「新しいデータソース」からデータソースを追加します。

そして、ブレンドはシート画面の方で行います。
データタブに2つのデータソースが表示されてますね。

ここで大事な概念として、「プライマリデータソース」と「セカンダリデータソース」があります。
要するに、どっちのデータをメインにする? ってことです。
例えば、1つのデータソースに対して複数のデータソースを紐づけるなら、その1つ目のデータソースがプライマリで、他がセカンダリであるべきです。
(ちなみに、2番目3番目と複数のデータソースでも全部「セカンダリ」とのこと)
いったん、「注文」データソースをプライマリデータベースにする、と心に決めます。
次に、プライマリデータベースから何か1つディメンションを追加します。(今回は「カテゴリ」)
すると、データソースに青いチェックマークがつきます。これがプライマリデータベースの印です。
最初に使った方がプライマリデータベースなのですね

次に、セカンダリデータベースに選んだデータソースを見てみると、製品IDに鎖マークが出ています。

これは、プライマリデータベースに対して、同じ名前のフィールドがあるので、「これでブレンドできるよ!」とTableauさんが言ってくれている状態です。
鎖をクリックすると、鎖が赤くなります。
今度はデータソースにオレンジのチェックマークがつきます。これがセカンダリデータベースの印です。

これでブレンドの設定が完了です。
ぱっと見はなんの変化もありませんが、2つのデータソースが製品IDをキーにがっちゃんこされている状態です。
その証拠に、プライマリデータベースの「カテゴリ」ディメンションに対して、セカンダリデータベースの「メーカー」ディメンションをぶら下げると、ちゃんとメーカーとカテゴリが紐づいていることがわかります。
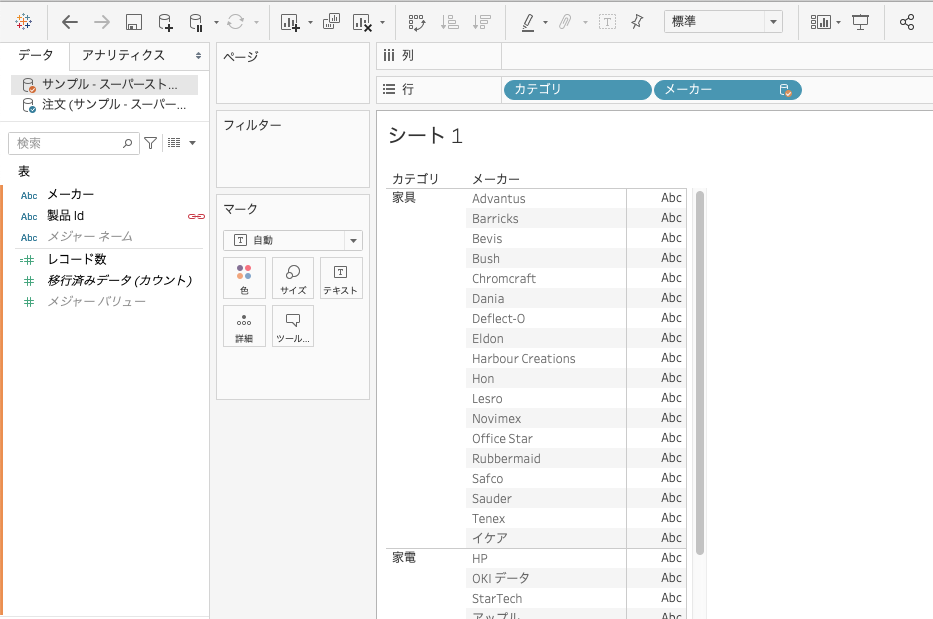
僕の場合、このUIになると何が起こってるのかいまいち掴めなくなってしまったことがありました。
「なんで製品IDをくっつけただけでカテゴリとメーカーが紐づくんだ!?」と。
まぁ実は深く考えなくても良くて、プライマリデータベースに対してセカンダリデータベースが製品IDをキーにがっちゃんこしているだけです。
製品IDでjoinされてるテーブル同士なら、そりゃカテゴリとメーカーはレコードで紐づいてるよね、と。
ちなみに、このケースではたまたま「製品ID」で同じ名前だったのでTableauさんが提示してくれましたが、異なる名前のキーを使うときは、ツールバーのデータから「ブレンド リレーションシップ の編集」を選びます。
※ここの「リレーションシップ」は「関係」機能とは関係ありません。(あるのかな?)

すると、ダイアログが表示されます。
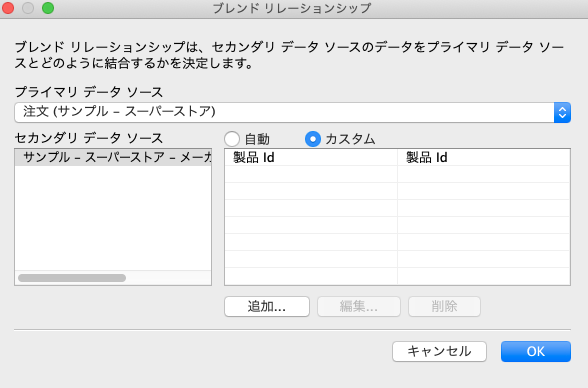
プライマリグループを選び、セカンダリデータソースを選ぶと、デフォルトでは「自動」にチェックがついています。
自動の場合、プライマリとセカンダリとで同じフィールド名を勝手に紐づけてくれていますが、カスタムから紐付きを自分で定義することができます。
ブレンドの問題点
ご覧の通り、お手軽なブレンドではあるのですが、欠点が2つあります。
1つ目は、紐付きが簡単に外れてしまうこと。
先ほど設定した製品IDでのブレンドは、ディメンションから「カテゴリ」と「メーカー」を外すと、ブレンドも解除されてしまいます。
使われていないブレンドは消えてしまうのですね。
またブレンドを設定するには、同じ手順を踏む必要があります。
そして2つ目は、シートを跨いで使えないことです。
これは結構な問題なのですが、ブレンドはシートごとの設定なので、あるシートをブレンドを使って作っても、別のシートにはそのブレンド情報がありません。
これらの課題を解決するのが、次に説明するプライマリグループです。
プライマリグループ
ブレンドの問題点は、前述の通りその脆さにあるのですが、プライマリグループを使えば永続化・シートを跨いでの活用ができます。
厳密にはプライマリグループはがっちゃんこの手法ではなく、ブレンドしたものをグループ化して保存する手法です。
UI操作
先ほどと同じく、ブレンドを設定します。
プライマリグループから製品IDを、セカンダリグループからメーカーを指定しています。
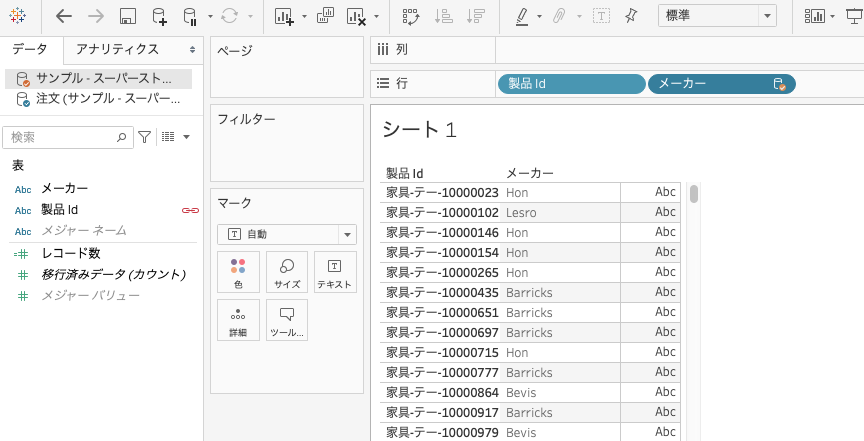
そして、「メーカー」ピルのメニューから、「プライマリグループの作成」を選びます
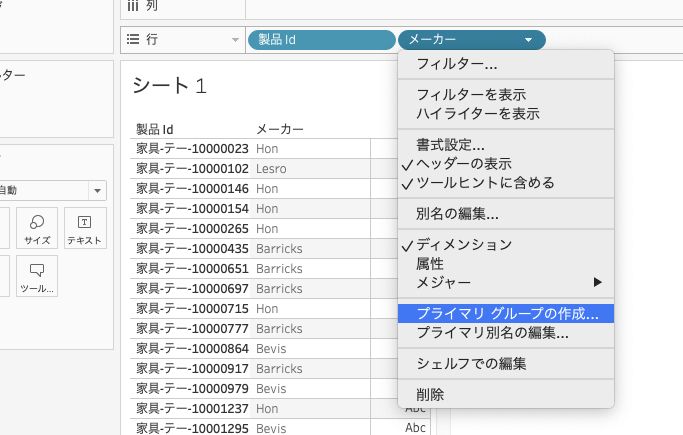
すると、グループの作成画面になります。

1つ1つのメーカー名を開いてみると、中には製品IDが含まれていることがわかります。
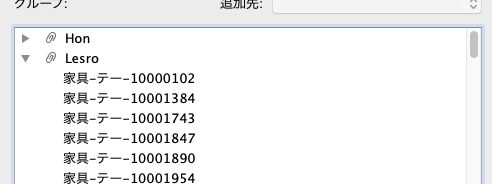
これで、OKを押すと、プライマリグループの作成完了です。
プライマリデータソースを見てみると、今作ったグループができています。
そして、プライマリデータソースの「カテゴリ」と、今作ったグループをディメンションに追加してみると、ちゃんと家具とメーカーの紐付けができていることがわかります。

こプライマリグループは、プライマリデータソースに完全に取り込まれているので、セカンダリデータソースを削除しても残りますし、別のシートでも使うことができます。
なので、ブレンドを使うときは、基本的にはプライマリグループにするところまでセットでやるのが良いかと思います。
プライマリグループでハマったところ
最初、このプライマリグループがよくわからず、うまく使えませんでした。
何かというと、まず、カテゴリとメーカーのブレンドを作りますよね。

この状態でプライマリグループを作ると…なんじゃこりゃ? となります。

なんでこうなるかというと、プライマリグループは**「右のフィールドをグループの単位にして、左のフィールドがどこに含まれるか」**でグループを作るからです
なので、この場合だと「メーカー」1つ1つを1グループとして、そこにどの「カテゴリ」が含まれるか、のグループを作ろうとします。
でもカテゴリは3つしかない & 重複して他のグループには存在できないので、家具と家電と事務用品が1つずつどこかのメーカーに属している、変なグループが出来上がったというわけですね。
なので、左をメーカーにして、右をカテゴリにしたこれ↓ならうまく動くわけです。
ただ、プライマリグループをカテゴリで作るには、プライマリデータソースとセカンダリデータソースを逆にしなければいけませんので、結果的にはうまくいきません。

ではどうするかというと、カテゴリとメーカーではなく、前述の通り製品IDとメーカーに変更するのです
これなら、メーカーをグループの単位として、製品IDをメーカーに割り振ることができます。
そして、このグループが定義されていれば、製品IDとカテゴリは元から紐づいているので、カテゴリとメーカーも紐づけることができる、というわけですね。
この辺の挙動がよくわかっていなかったので、かなり苦労しました…
まとめ
思ったよりずっと長い記事になってしまいました…。
それほどまでにややこしいところなわけですが、結論でまとめてしまうと、
データソースが1つなら関係を使う。データソースが別ならブレンドしたあとプライマリグループにする
以上!!
なんのことはない、これだけでした。
もちろん、パフォーマンスだなんだと細かいことを考えだすようになると、じゃあ結合を使って…とかになるわけですが、超基本の考え方はこれだけだったわけです。
いやぁ、苦労した…。