はじめに
この記事では,XilinxのVivado HLSの一式で提供されている行列乗算関数matrix_multiplyについてご紹介しようと思います.HLS初心者なので変な情報が含まれている可能性があります.ご注意ください.
本記事ではニューラルネットワークで多用される積和演算をHLSで作製する際,matrix_multiplyを活用してみます.(MLPなどのニューラルネットワークを作るところまではいきません.あくまで積和演算だけです)
バージョン
Vivado HLS 2018.3 for Linux (CentOS 7)
線形代数ライブラリ
Vivado HLSには線形代数ライブラリなるものが存在し,以下の関数が利用できます.
- cholesky
- cholesky_inverse
- matrix_multiply <--今回のお題
- qrf
- qr_inverse
- svd
本記事では行列乗算を行うmatrix_multiplyを紹介します.
なお,詳細についてはXilinxのユーザーガイドUG9021を参照してください.
作ってみる
つくるもの
ニューラルネットワークを念頭にmatrix_multiplyを活用して積和演算をVivado HLSで実装してみます.
ニューラルネットワークの基本的な構造を図示すると以下のようになります.

入力層のノードが次の層のノード全てに結合を有する全結合型のものです.
入力を$\boldsymbol{x}$,結合荷重を$W$,2層目のバイアスを$\boldsymbol{b}$,$f$を活性化関数とすると,このときの出力$\boldsymbol{y}$は次のように計算されます.ただし,$\boldsymbol{x}, \boldsymbol{b}$はそれぞれ縦ベクトルで,要素数はそれぞれの層のノード数です.
\boldsymbol{y} = f(W\boldsymbol{x} + \boldsymbol{b})
この数式で活性化関数の引数に当たる部分をHLSで書いてみます.
コード
実際にはprop_one_cycleと命名した関数にまとめています.
matrix_multiplyを試してみるのが目的なので,最適化については一切考慮していません.
C++のテンプレートに慣れていない方はごちゃごちゃして見にくいかと思いますが,それぞれの引数の意味がわかれば難しくはありません.
# include "hls_linear_algebra.h"
# include "my_mat_func.hpp"
# define NEURON_NUM_V 10 //入力層のニューロン数
# define NEURON_NUM_H 5 //次層のニューロン数
void prop_one_cycle(float w[NEURON_NUM_H][NEURON_NUM_V],float vlayer[NEURON_NUM_V][1], float hlayer[NEURON_NUM_H][1], float hbias[NEURON_NUM_H][1]){
// h = w * v
// 計算させるための行列は2次元配列である必要がある.
// たとえベクトルであっても,1xnの行列として2次元配列で表現する.
// テンプレート引数は頭から:
// wを転置するか,vを転置するか,
// wの行数と列数,vの行数と列数,
// wvの結果の行数と列数,
// wとvの型
hls::matrix_multiply<hls::NoTranspose, hls::NoTranspose, NEURON_NUM_H, NEURON_NUM_V, NEURON_NUM_V, 1, NEURON_NUM_H, 1, float, float>(w, vlayer, hlayer);
// バイアスを足す計算(自作関数)
// y = h + b
my_mat_func::matrix_add<NEURON_NUM_H, 1, float>(hlayer, hbias, hlayer);
}
また,ベクトルの足し算が定義されていなかったので以下のように自作しました.各要素同士の足し算を行います.これで使いまわしができます.
# pragma once
namespace my_mat_func{
// Matrix add.
template<
int Rows,
int Cols,
typename T>
void matrix_add(const T A[Rows][Cols], const T B[Rows][Cols], T C[Rows][Cols]){
for(int row=0; row<Rows; row++){
for(int col=0; col<Cols; col++){
C[row][col] = A[row][col] + B[row][col];
}
}
}
}
使い方
matrix_multiplyを使うには,以下のようにして必要なヘッダファイルをincludeする必要があります.
# include "hls_linear_algebra.h"
行列乗算で,C=ABを計算したいときは,
matrix_multiply<(略)>(A, B, C);
とします.それぞれ引数は2次元配列です.ベクトルも1 x NもしくはN x 1の2次元配列で表現します.試しに1次元配列で与えたらエラーになってしまいました.
関数の戻り値は存在せず,計算結果は配列Cに格納されます.
テンプレート引数は第一引数から順に,以下のようになっています.
更に詳しい情報はXilinxユーザーガイドUG902を参照してください.
| 引数 | 意味 | 値 |
|---|---|---|
| TransposeFromA | 行列Aを転置するかどうか | hls::Transpose = 転置する hls::NoTranspose = 転置しない |
| TransposeFromB | 行列Bを転置するかどうか | hls::Transpose = 転置する hls::NoTranspose = 転置しない |
| RowsA | Aの行数 | 整数値 |
| ColsA | Aの列数 | 整数値 |
| RowsB | Bの行数 | 整数値 |
| ColsB | Bの列数 | 整数値 |
| RowsC | Cの行数 | 整数値 |
| ColsC | Cの列数 | 整数値 |
| InputType | 入力の型 | 型名 |
| OutptType | 出力の型 | 型名 |
テストベンチ
例によって,Eigenで計算させた結果と比較するテストベンチを作成しました.
各行列の値は一つ一つ決めるのが面倒くさいので,乱数を振っています.乱数を使うことについては,デバッグを困難にする可能性もありますので,注意してご利用ください.
このプログラムを回すと,Eigenで計算した結果とVivado HLSが計算した結果を比較して一致していれば正常終了,一致していなければエラー終了します.
Vivado HLSでのEigenの利用方法については過去に色々と試行錯誤したので,そちら2をお読みください.
なお,今回はC simulationのみで,RTL cosimulationは実施していません.
# include <iostream>
# include "Eigen/Core"
# include "Eigen/Geometry"
# include "hls/linear_algebra/utils/x_hls_matrix_utils.h"
# include "hls/linear_algebra/utils/x_hls_matrix_tb_utils.h"
# define NEURON_NUM_V 10
# define NEURON_NUM_H 5
void prop_one_cycle(float w[NEURON_NUM_H][NEURON_NUM_V],float vlayer[NEURON_NUM_V][1], float hlayer[NEURON_NUM_H][1], float hbias[NEURON_NUM_H][1]);
int main(){
// Prepare arguments for the function.
float w[NEURON_NUM_H][NEURON_NUM_V];
float vlayer[NEURON_NUM_V][1];
float hlayer[NEURON_NUM_H][1];
float hbias[NEURON_NUM_H][1];
// Initialize Eigen objects by random number.
Eigen::MatrixXf ew = Eigen::MatrixXf::Random(NEURON_NUM_H, NEURON_NUM_V);
Eigen::MatrixXf evlayer = Eigen::MatrixXf::Random(NEURON_NUM_V, 1);
Eigen::MatrixXf ehbias = Eigen::MatrixXf::Random(NEURON_NUM_H, 1);
// Copy values of the eigen objects to the raw arrays.
Eigen::Map<Eigen::Matrix<float, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>>(&(w[0][0]), NEURON_NUM_H, NEURON_NUM_V) = ew;
Eigen::Map<Eigen::Matrix<float, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>>(&(vlayer[0][0]), NEURON_NUM_V, 1) = evlayer;
Eigen::Map<Eigen::Matrix<float, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>>(&(hbias[0][0]), NEURON_NUM_H, 1) = ehbias;
// Calculate!!
prop_one_cycle(w, vlayer, hlayer, hbias);
// For debug by Eigen
Eigen::MatrixXf ehlayer = ew * evlayer + ehbias;
Eigen::MatrixXf result = Eigen::Map<Eigen::MatrixXf>(&(hlayer[0][0]), NEURON_NUM_H, 1);
// Display
std::cout << "---- ew -----" << std::endl;
std::cout << ew << std::endl;
std::cout << "---- evlayer ----" << std::endl;
std::cout << evlayer << std::endl;
std::cout << "---- ehbias ----" << std::endl;
std::cout << ehbias << std::endl;
std::cout << "===== RESULTS ======" << std::endl;
std::cout << "ehlayer = " << std::endl;
std::cout << ehlayer << std::endl;
std::cout << "hlayer = " << std::endl;
hls::print_matrix<NEURON_NUM_H, 1, float, hls::NoTranspose>(hlayer, " ", 10, 0);
// Evaluate the result
if((ehlayer.array() == result.array()).all()) return 0;
else return -1;
}
デバッグ用関数(hls::print_matrix)
デバッグ用に,多次元配列の行列をきれいに整形して出力・表示してくれるprint_matrix関数が提供されています.これを使うことで配列の中身を一つずつforで回して表示する必要がありません.
以下のヘッダファイルをテストベンチのコード内で読み込むと関数が使えるようになります.
当たり前ですが,これはテストベンチでのデバッグ用で,論理合成の対象外です.
# include "hls/linear_algebra/utils/x_hls_matrix_utils.h"
# include "hls/linear_algebra/utils/x_hls_matrix_tb_utils.h"
x_hls_matrix_utils.hによるとprint_matrixは以下のように宣言されています.
template <unsigned ROWS, unsigned COLS, typename T, class TransposeForm> void print_matrix(T a[ROWS][COLS], std::string prefix = "", unsigned prec=10, unsigned matlab_format=0)
それぞれの引数の説明は以下のとおりです.テンプレートの引数と関数の引数全部まとめて列挙します.
| 引数 | 意味 |
|---|---|
| ROWS | 表示する行列の行数 |
| COLS | 表示する行列の列数 |
| T | 表示する行列の型 |
| TransposeForm | 転置するか否か, hls::Transpose/hls::NoTranspose |
| a | 表示する行列 |
| prefix | 表示するときに書く行頭に入れる文字,空白などを入れると見やすい |
| prec | 表示する桁数 |
| matlab_format | 表示形式,MATLAB風になる? |
MATLABを殆ど使わないので,よくわかりませんが,以下のように表示が変わります.
趣味の問題ですね,多分.
matlab_formatを0にすると,
hlayer =
|(-0.1987174749) |
|(-0.2068132162) |
|(-1.4512076378) |
| (2.4631514549) |
|(-2.8751215935) |
matlab_formatを1にすると,
hlayer =
[-0.1987174749 ;
-0.2068132162 ;
-1.4512076378 ;
2.4631514549 ;
-2.8751215935 ];
となります.なれている表示の仕方に合わせるのが良いでしょう.
合成結果
Vivado HLSの"C Synthesis"ボタンを押して作成した関数を論理合成してみました.
コードには一切最適化するためのpragmaは書いていません.結果は以下のようになりました.
BRAMが一切使われていないようですね.規模が小さいからなのでしょうか?
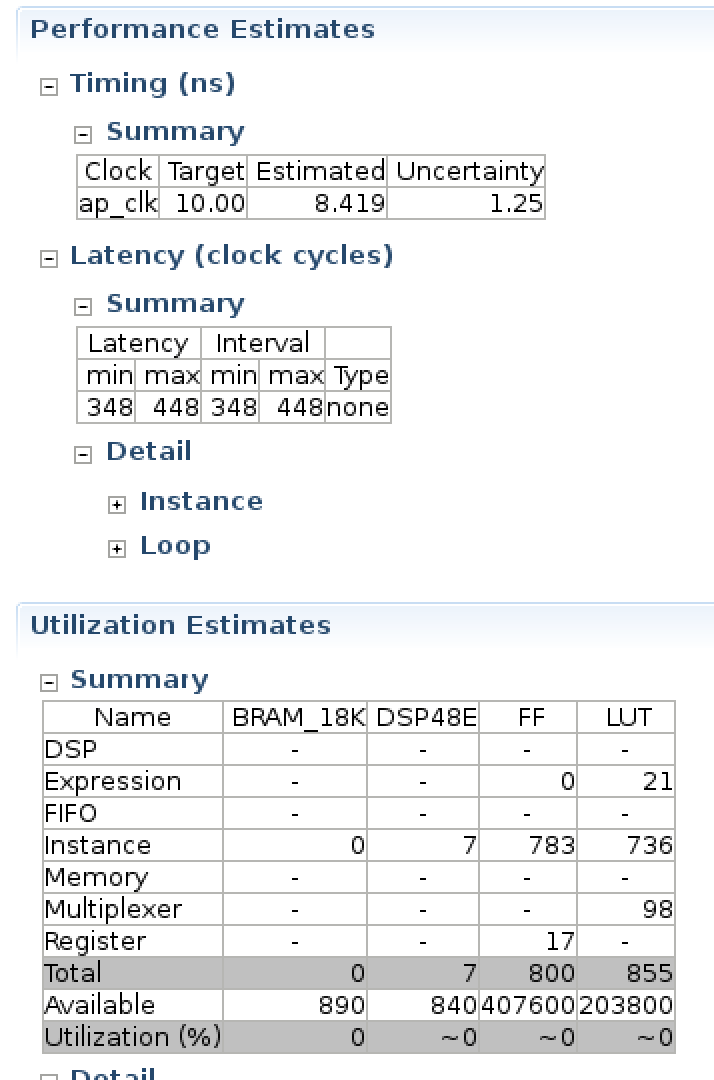
サイズは入力層が10,隠れ層が5のサイズです.ただし今回は積和演算だけですので,実際にニューラルネットワークとして実装する場合はこれより増えるでしょう.
おわりに
Xilinxの提供する行列乗算関数の使い方をまとめてみました.forループを手書きしても良いですが,何かとバグを生むことにもなりかねませんので,あるものは使ってしまおうというスタンスです.
今回は試していませんが,線形代数関数は別途設定を適切にすることで,消費リソースを優先するか速度を優先するか,といったことの指定もできるようです.
今後,ニューラルネットワークへ発展させるためには,活性化関数の実装なども必要になります.また,固定小数点化することでよりハードウェア向けに作れると思います.今回は何も考えずにintやfloatを使っていますが,非常に無駄が多い点にはご注意ください.
-
[Vivado Design Suite ユーザー ガイド UG902 高位合成](Vivado Design Suite ユーザー ガイド) ↩