はじめに
SREという部署の責任者をしており、マネジメントがメインなので自分で手を動かす機会が少ないのですが、今回 アドベントカレンダー をやることになったので、自らやったことを記事にしてみたいと思います。
タイトルの通り、ユーザーがどんなOS、どんなブラウザからアクセスしているのか、またその割合はどれぐらいなのか、サポート体制の妥当性などを検討するためにデータを分析をしてほしいという依頼を受けました。
短期間で、あまりお金をかけずに、スポット作業で、S3のデータを分析するならAthenaが最適ですね
この記事で得られること
・ALBのログをAthenaで分析する
・Athenaのパーティションを使う
・S3のパスを検索条件として利用する
・AWSコンソールだけで、サラっとやってみる
前提
- 複数のユーザー環境があり、環境毎にALBが存在している。
- 環境は
tenantlandscape単位で存在している。 - ALBのログはS3の以下のパス配下に格納されている
s3://[ALBログのバケット名]/{tenant}/{landscape}/alb/AWSLogs/{year}/{month}/{day}/
調査方針
各環境毎に、どんなOSのどんなブラウザからアクセスされているのか把握するため、直近3ヶ月のALBログの user-agent を分析して結果を集計する。
それでは、実際にやってみましょう
やってみる
STEP.0 クエリ実行結果の格納場所指定
事前に、S3のバケットを作成しておいてください。
ここでは、 aws-athena-query-results というS3バケットがある前提とします。
※実際のバケット名はユニークにする必要があるので、アカウントIDやリージョン名などを含めたバケット名になると思います。
次に、AWSコンソールからAthenaのページを開き、下記メッセージの太文字部分をクリックします。
もしくは、上部にある Settings メニューを開いてください。
Before you run your first query, you need to set up a query result location in Amazon S3. Learn more
表示された画面に事前に用意したS3のBucketを指定します。
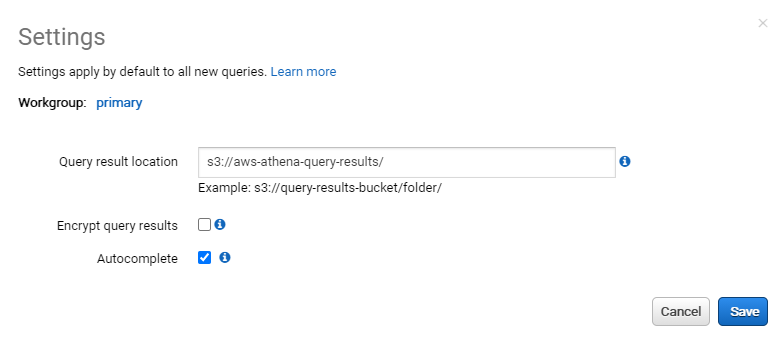
※これをやらないと query が実行できるようにならないのでご注意ください
STEP.1 データベース作成
まずは、テーブルを作成するためにデータベースの作成が必要になります。
今回は「alb_db」というデータベースを作成するために、AWSコンソール上で、以下のqueryを実行してみます。
CREATE DATABASE alb_db;
AthenaのQuery Editor の画面
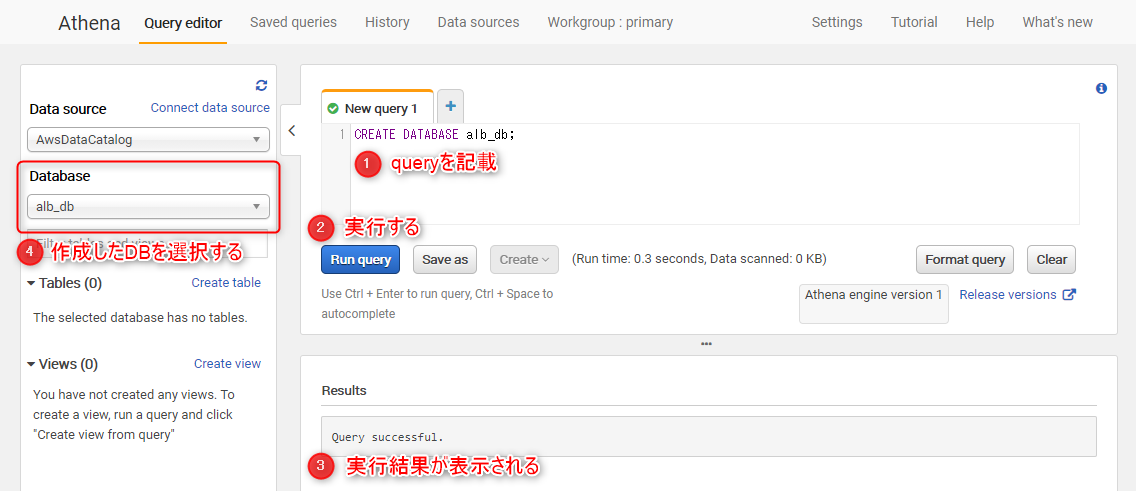
DBが作成されたら、左側のペインで、作成したDBを選択しておいてください。
STEP.2 テーブル作成
ALB ログのテーブルはAWSのユーザーガイド に記載されているので、これを参考にテーブルを作成してみます。
ただし、今回は、S3のパス( tenant landscape year month )を検索条件として使えるようにしたいので、少し手を加えてパーティションを利用できるようにします。
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
PARTITIONED BY (
tenant string,
landscape string,
year integer,
month integer
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"'
)
LOCATION 's3://[ALBログのバケット名]/';
パーティションに検索条件にしたい項目を指定します。(後ほど各項目毎のパーティションをALTER文で指定します。)
day まで指定すると細かくなりすぎるため、 month までにしておきます。
PARTITIONED BY (
tenant string,
landscape string,
year integer,
month integer
)
STEP.3 パーティション作成
ALTER文で、各パーティションのデータの場所を指定していきます。
例えば、下記のS3パス配下にあるログの場合
s3://[ALBログのバケット名]/A/production/alb/AWSLogs/2020/12/
- tenant: A
- landscape: production
- year: 2020
- month: 12
というパーティションキーとS3の場所を指定した、下記のALTER文になります。
ALTER TABLE alb_logs ADD PARTITION (tenant='A', landscape='production', year=2020, month=12) LOCATION 's3://[ALBログのバケット名]/A/production/alb/AWSLogs/2020/12/';
今回は、直近3ヶ月分のproductionのログを分析したいので、必要な分だけを対象にパーティションを作成します。
※ロードしたデータ量によって課金されるので、なるべく対象を絞ったほうが安くなります。
ALTER TABLE alb_logs ADD PARTITION (tenant='A', landscape='production', year=2020, month=12) LOCATION 's3://[ALBログのバケット名]/A/production/alb/AWSLogs/2020/12/';
ALTER TABLE alb_logs ADD PARTITION (tenant='A', landscape='production', year=2020, month=11) LOCATION 's3://[ALBログのバケット名]/A/production/alb/AWSLogs/2020/11/';
ALTER TABLE alb_logs ADD PARTITION (tenant='A', landscape='production', year=2020, month=10) LOCATION 's3://[ALBログのバケット名]/A/production/alb/AWSLogs/2020/10/';
ALTER TABLE alb_logs ADD PARTITION (tenant='B', landscape='production', year=2020, month=12) LOCATION 's3://[ALBログのバケット名]/B/production/alb/AWSLogs/2020/12/';
ALTER TABLE alb_logs ADD PARTITION (tenant='B', landscape='production', year=2020, month=11) LOCATION 's3://[ALBログのバケット名]/B/production/alb/AWSLogs/2020/11/';
ALTER TABLE alb_logs ADD PARTITION (tenant='B', landscape='production', year=2020, month=10) LOCATION 's3://[ALBログのバケット名]/B/production/alb/AWSLogs/2020/10/';
~ 省略 ~
AthenaのQuery Editor の画面からだと1query毎しか実行できません。
ALTER文の数が多くて大変な場合は、AWS CLIなどを利用して一括実行しましょう。
作成したパーティションは確認することができます。(実行結果がソートされないのは残念、、、)
SHOW PARTITIONS alb_logs;
これで、テーブル構造とデータの準備が整いました。
STEP.4 SELECTクエリで結果取得
各テナント毎に、user-agentをグルーピングしてその件数をカウントすることで分析します。
SELECT tenant, landscape, user_agent, count(user_agent) FROM alb_logs GROUP BY tenant, landscape, user_agent;
STEP.5 user-agent分析
様々なuser-agentの結果が取得できました。
例えば、以下のuser-agentは、Windows10 の Chrome からのアクセスです。
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36
また、分析してみてなるほどと思ったのは、iPhone の Safari からのアクセスですが末尾に Line 付与されているので、LineアプリからURLを開いたことがわかります。
Mozilla/5.0 (iPhone; CPU iPhone OS 13_5_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 Safari Line/10.18.0
このように千差万別のuser-agentを調べるのに役に立ったサイトが、User-Agent暗号プロトコル辞典でした。
こちらを見てもらうとわかるように、OSは99種類、ブラウザは167種類あります。
すべて識別してもあまり有益でないので以下に絞り、それ以外はUnknownとして集計しまとめました。
OS
- Windows
- Mac
- Linux
- Android
- iOS
- Unknown
ブラウザ
- IE
- Edge
- Chrome
- Safari
- Firefox
- Unknown
1件ずつuser-agentを調べたのでとても苦労しました。(もうやりたくない、、、涙)
おわりに
今回はuser-agentを分析することで、OSやブラウザの利用状況を調査しましたが、なんと、user-agentは廃止予定らしいです。
詳しくは以下の記事でわかりやすく説明されているのでご参考ください。
ChromeでUserAgentが凍結される日(User Agent Client Hintsの使い方)
あらためて、アウトプットの場があると、行動をするモチベーションが生まれるなと感じました。
今回アドベントカレンダーに参加し、どんな記事を書こうかなと思ってるところに、OSやブラウザの利用状況調査依頼が来たので、お!これは、自分でやって記事化すれば一石二鳥になるなと思い、夜な夜な少しづつ作業しました。
やっぱり、開発は楽しいですね。AWSサービスを触ったり、SQLを実行してみたり、よく知らなかったuser-agentを分析してみたり、最終的にピポットテーブルで集計結果を出してそれを眺めながらニヤニヤしちゃいました。
仕事だと思って開発をやると面白みは半減しますが、自分でやってみようと思ってやる開発は本当に楽しいですね。
開発にたずさわる人たちが開発をもっと楽しめるようになることを祈って Merry Christmas!