Chapter 34. GPU Flow-Control Idioms
Flow-Control Challenges
平行结构中两个最常见的机制是单指令流多数据流(single instruction, multiple data, SIMD)和多指令流多数据流(multiple instruction, multiple data, MIMD)。SIMD结构中所有的处理器同时执行同一个指令流。MIMD结构中不同的处理器并行执行不同的指令流。
对于GPU有三种办法进行分支操作:MIMD分支,SIMD分支和状态码。
MIMD分支是理想的方案。GeForce6之后在顶点着色器中支持MIMD分支。
SIMD中因为处理器同时只能执行一个指令流,片元随机选取一个分支时,其他处理器必须等待其运行结束。SIMD在分支条件相当空间连续的情况下很有用,但是在非连续的情况下是非常昂贵的。
控制码被用于旧一点的结果来模拟分支。
基础流控制策略(Basic Flow-Control Strategies)
预测(Predication)
最简单的方法就是GPU快速预估分支然后抛弃其中一个。缺点就是如果分支里的函数是很庞大的话就会很耗时。所以预测适合小的分支。
移至流水线的上游
静态分支解析
尽量避免在循环内使用分支。尽量不要使用嵌套循环。使用独立的循环。
预计算
对于一个范围内值是固定的判断来说,提前将结果预存起来,只要预测结果不变直接就可以使用而不用计算。可以提供巨大的性能提升。
Z-Cull
可以使用另一项GPU的特性来利用预计算的结果,从而完全跳过不必要的开销。
Z-cull是一种比较输入的深度(depth z)和z缓冲(z-buffer)里的z值的技术(似乎就是Z-test)。如果测试失败,就会在被抛弃掉。
z-cull的伪代码,第一个Pass里进行z-test并踢出不需要的像素。第二个Pass里处理通过z-test的像素。

z-culling通常被GPU用来做粗略的解析而不是一个逐片元的操作。GPU只有在缓存中一小片连续区域里的片元全部测试失败的时候才会跳过渲染操作。所以,z-cull只有在分支有一定连贯性的情况下才能提供性能提升。

z-cull并不是分支选择的处理,只是他能够让着色器不去执行分支选择。z-cull是一个可以跳过很多无用工作的基于一个静态和预处理的强力的手段。
分支指令
现代GPU一般都支持。如果空间比较连续,效率更高。
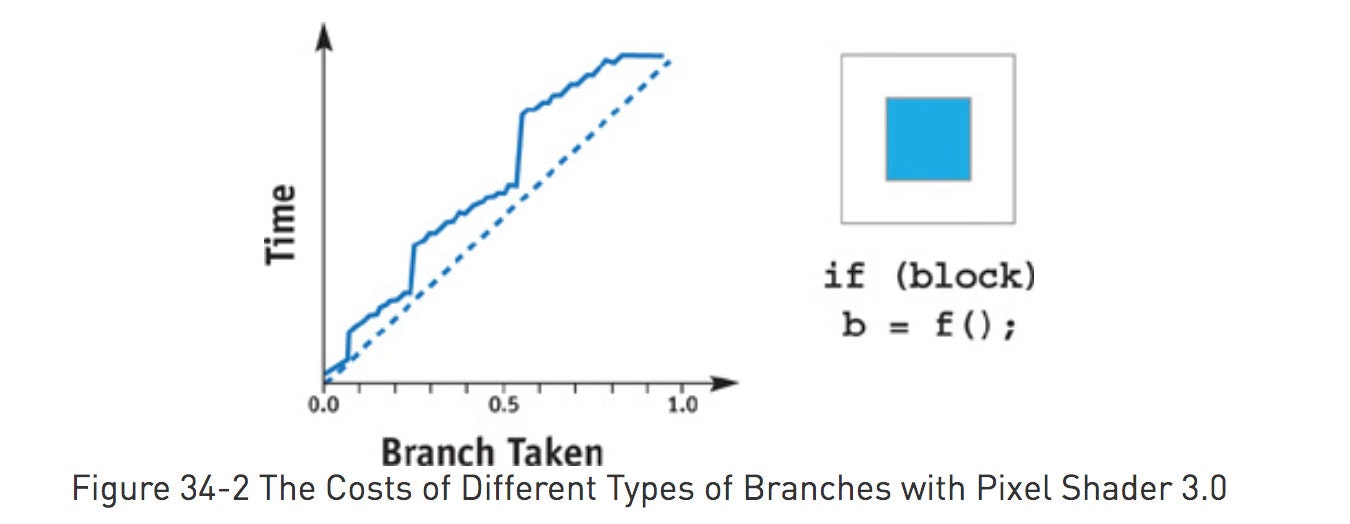
选择合适的分支功能
选择分支功能是基于分支里的代码量以及表现的状态数量。对于短分支(2-4个指令),推荐使用预测。对于嵌套在大程序里的分支,推荐使用分支指令而不是z-cull。使用z-cull需要保存所有的程序状态,在一个单独的Pass中处理分支。然而,如果能够高效地分离程序里的分支元素的话,z-cull能提供最好的效率。
自己查的资料
作为初学者,对静态和动态分支的概念不是很理解。稍微谷歌了一下。
找到一个很理想的概念解答。
静态分支(static branching):是同样的分支在整个draw call始终会被调用。比如基于Shader的属性和非per-vertex/per-pixel数据(常数之类的)。这种分支通常来说没有问题。虽然有些开销,但是GPU可以比较轻松的对所有的vertices/pixels中应用相同的代码。
动态分支(dynamic branching):是当你对每一个vertex/pixel进行处理的时候条件会不同。GPU处理器会把对顶点用同样的代码进行处理,然后如果其中有的数据是别的分支的话,那么GPU的处理器会再运行对顶点/像素等再用另外一个分支进行处理一边然后抛弃之前的。为了保证效率,最好数据是空间连续的。
一些旧的处理器和Shader Models(比如Unity默认的SM2.0)并不支持动态分支。Unity会内部进行处理。