GraphQLの特徴的な結合パターン "Union"
前前回記事でAppSyncを呼び出すアプリを作り、前回記事でAppSyncと既存のGraphQL APIを結合させ一つのAPIにできました。
もう一つGraphQLの結合のケースを発見しました!
(最後に説明しますが、発見とは言っても概念としてはさして新しいものではありません。)
それは同列の結合、名付けてUnion型です。(私が名付けました。意味は後述)
前記事の親子関係なAPIの結合とは異なり、このUnion型を使うと網羅的なデータ処理ができる嬉しさがあります。
今回もGithub API v4とAppSyncのAPIと結合させて、嬉しさを検証しました。
Union型のユースケース
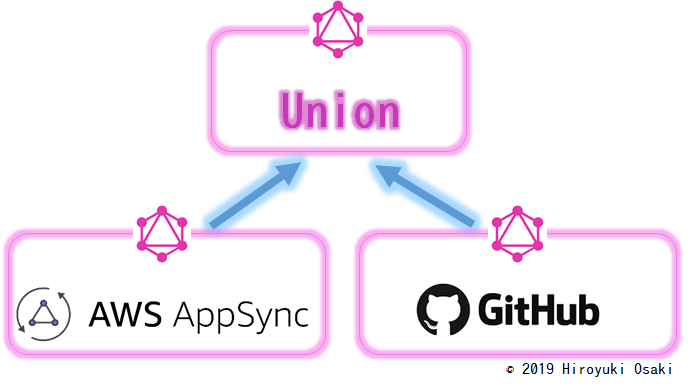
次の2つのGraphQL APIがあるとします。
- AppSync上のGraphQL API: 会社内のプライベートな組織名一覧が取得できるGraphQL API
- GithubのAPI: 一般に知られた組織名一覧が取得できるGraphQL API
たとえば、
「github」という会社、組織名は2.に入っていますが、
「●●株式会社総務部」という組織名は1.に入っており、同じ名前は2.には入っていません。
実際に、Github GraphQL APIの最上位(ルートフィールドという)には
organizationというクエリがあり、"github"とか"facebook"などの有名な組織名を指定すると組織情報を取得することができます。
今、(1)と(2)それぞれ違う組織名が保存されています。
(1)(2)は、対象範囲が違うというだけで「組織名」を保持するという本質は同じなので、同列のAPIと考えられます。
では、これらの同列なAPIをUnionで結合し、(1)(2)を網羅的に処理するような一つのAPIを作ります。
Unionのユースケースを2つ挙げてみます。
具体的ユースケース1. 2つのAPIの和集合を取得する
(1)と(2)の全組織名の一覧を返す、listUnionedOrganizationsというAPIを作ります。
つまり、リターン値は(1)の組織名一覧+(2)の組織名一覧の和ということになります。
具体的ユースケース2. 2つのAPIの中から一要素だけ検索する
(1)と(2)の全組織のうち1つだけを返すgetOneUnionedOrganizationというAPIを作ります。
何かのIDを使って1つの組織を同定してリターン値にしもいいですし、名前のようなもので検索してもいいです。
(1)か(2)のどちらの組織名を取ってくるかはその時次第です。
アーキテクチャ
同列のAPIを結合する場合のアーキテクチャは、だいたいこんな感じになります。
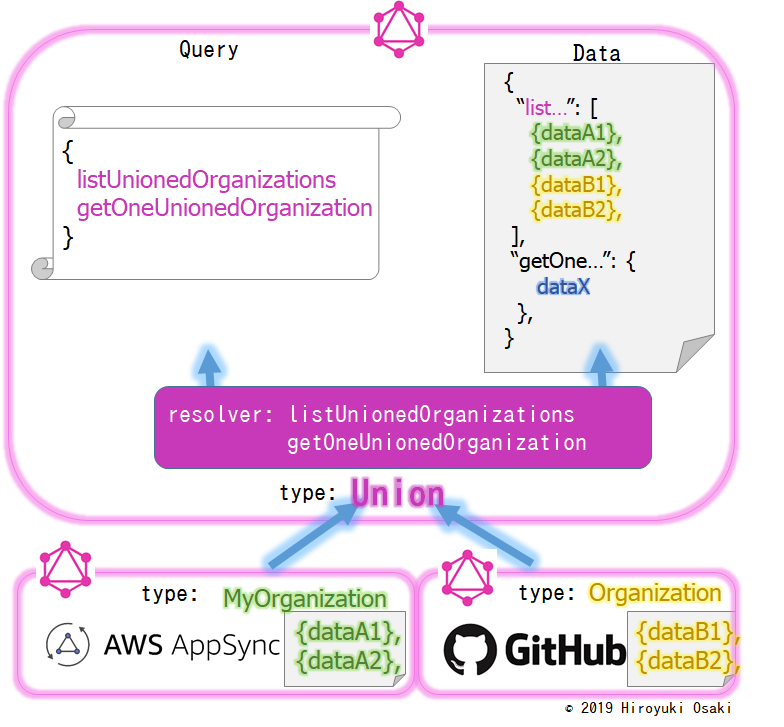
AppSyncとGithubから両者のAPIを取り込むサーバを起動し、両者を結合させ新たなGraphQL APIを作ります。(前回同様、結合させるGraphQLの仕組み「スキーマスティッチング」別記事を使用)。
今回は、スキーマスティッチングに加えて**unionという型定義方法(後述)を使います**。
同列のAPIを結合した型を作るUnion
GraphQLではデータの型を持っており、前述の同列な2つのAPIもそれぞれ型を持っています。
GraphQLが持つunionという型定義の仕方を使うと、複数の型を結合させることができます。
例えば、以下のような型があったとします。
union UnionedOrganization = MyOrganization | Organization
type Query {
getUnionedOrganization: UnionedOrganization
}
1行目はunionで型を定義していて、結合のもととなった複数の型のいずれのインスタンスでも格納することができます。
たとえば、1行目で定義されたUnionedOrganizationは、MyOrganizationとOrganizationいずれの値も格納できます。
2行目にそのUnionedOrganizationを返すgetUnionedOrganizationというフィールド(関数)が定義されていますが、実際に取得できる値はMyOrganiztionかもしれないし、Organizationかもしれません。
ということで、前置きが長くなりましたが、Union型の構成を見ていきます。
今回もAWS Lambdaに起動します。
各APIの構築
1. AppSync側のAPIの構築
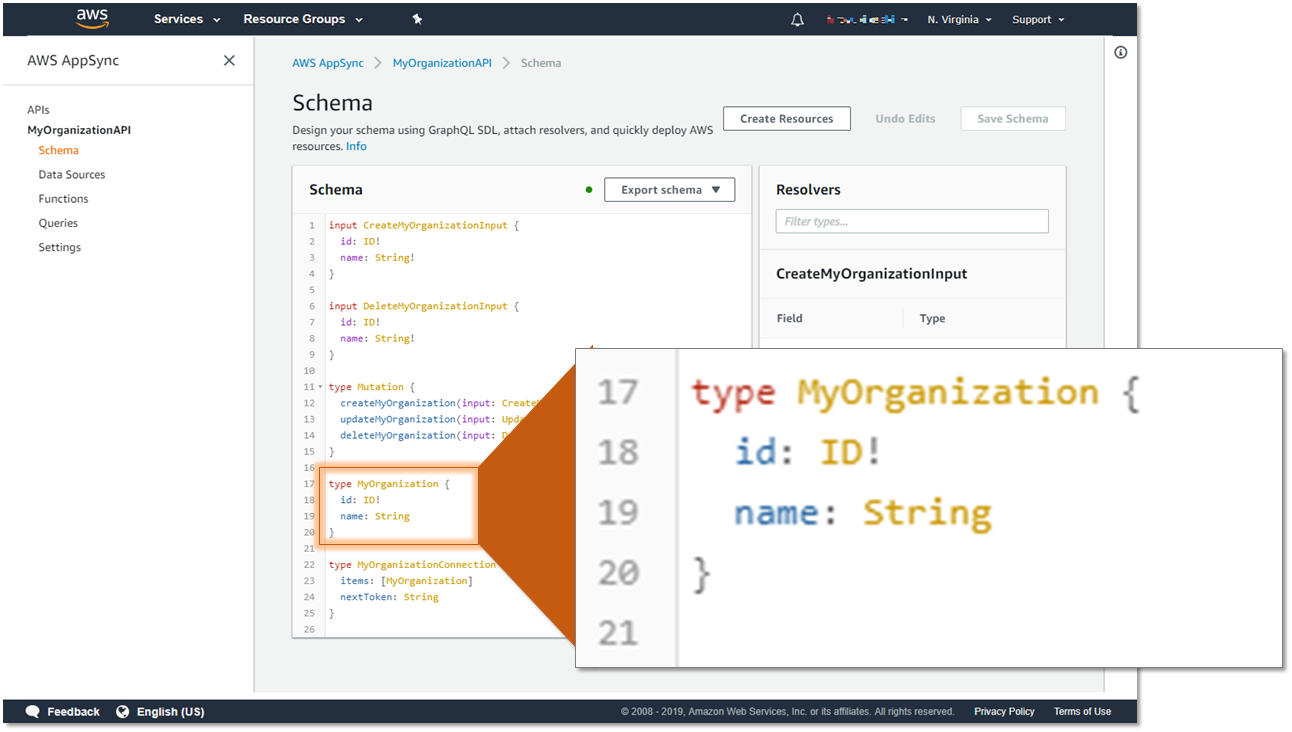
AppSync上に作成するAPI「プライベートな組織一覧」のモデルは以下とします。
type MyOrganizations {
id: ID!
name: String
}
type Query {
listMyOrganizations: MyOrganizationConnection
getMyOrganization: MyOrganization
}
特徴は以下です。
- データの型は
MyOrganizationで、idとnameの2つのフィールドしかない。 - クエリは、一覧を取得する
listMyOrganizationsと、単体を取得するgetMyOrganizationという2つのAPIを持つ。
以下のように、AppSyncのコンソールでモデルを構築します。
AppSyncのQueriesやDynamoDBの直接操作で、あらかじめいくつかのデータを登録しておきます。
私は以下のようにしました。
APIアクセスの準備
前回同様ですが、作成したAPIのサマリ画面からaws-exports.jsをダウンロードします。
2. GithubのAPI
これも前回同様ですが、Github API v4のモデルの一例に、以下のようなOrganizationがあります。
引数がloginという文字列で、返り値としてOrganizationを取得できます。
Organizationは次のように型定義されており、repositoriesというその組織のレポジトリを取得できるフィールドがあります。
type Organization {
id
location
name
repositories
}
type Query {
organization(login: String!): Organization
}
特徴は以下です。
- データの型は
Organizationで、idとname、location、repositoriesという4つのフィールドを持っていて、前述のMyOrganizationより多いフィールドを持つ。 - クエリは、一覧を取得するAPIはなく、単体を取得する
organizationという1つのAPIを持つ。
スキーマはGithub API Explorerで確認できます。
APIアクセスの準備
githubのsettings -> developers settings -> personal access tokenから、アクセストークンをあらかじめ取得します。
取得したトークンを、.envに記載します。
GITHUB_ACCESS_TOKEN=<token>
Union型APIの仕様とAWS Lambda上のNode.jsサーバの実装
準備として、後述のサーバ実装ファイルと同じフォルダに先ほどのAppSyncからダウンロードしたaws-exports.jsや.envファイルを格納しておきます。
サーバ実装内では、AppSync APIのMyOrganizationとGithub APIのorganizationの結果を結合します。
結合したAPIのリターン値やフィールド名は以下となります。
union UnionedOrganization = MyOrganization | Organization
type Query {
listUnionedOrganizations: [UnionedOrganization]
getUnionedOrganization: UnionedOrganization
}
特徴は
- リターン値
UnionedOrganizationは、2つの型のunion。 - クエリは、一覧を取得する
listUnionedOrganizationsと、単体を取得するgetUnionedOrganizationの2つのAPIを持つ。
APIの返り値は以下のように作ります。
-
- AppSyncから値をコピーする
-
- Github APIから値をコピーする。
-
-
organizationは1)と2)を合わせて(必要に応じてフィルターして)返す
-
さて、結合APIの実装であるNode.jsサーバは以下のように実装します。
import {makeRemoteExecutableSchema, mergeSchemas, introspectSchema, makeExecutableSchema } from 'graphql-tools';
import fetch from 'node-fetch';
import { HttpLink } from 'apollo-link-http';
import { ApolloServer, gql } from "apollo-server-express";
import serverless from "serverless-http";
import express from "express";
import { config } from 'dotenv';
import { graphql } from "graphql";
config()
const aws_exports = require('./aws-exports-2').default;
const github_url = 'https://api.github.com/graphql';
const createSchema = async () => {
const createRemoteSchema = async (uri, headers) => {
const link = new HttpLink({uri, fetch, headers});
return makeRemoteExecutableSchema({
schema: await introspectSchema(link),
link
});
};
const appsyncSchema = await createRemoteSchema(
aws_exports.aws_appsync_graphqlEndpoint,
{'X-Api-Key': aws_exports.aws_appsync_apiKey}
);
const githubSchema = await createRemoteSchema(
github_url,
{ Authorization: `bearer ${process.env.GITHUB_ACCESS_TOKEN}`}
);
const linkSchemaDefs = gql`
union UnionedOrganization = MyOrganization | Organization
extend type Query {
getOneUnionedOrganization(name: String, type: String): [UnionedOrganization]
listUnionedOrganizations: [UnionedOrganization]
}
`;
const schema = mergeSchemas({
schemas:[githubSchema, appsyncSchema, linkSchemaDefs],
resolvers: {
Query: {
getOneUnionedOrganization: {
async resolve(parent, args, context, info) {
const delegate = (schema, fieldName, args) => {
const operation = 'query'
const _paramsForDelegate = { schema, operation, fieldName, args, context, info }
return info.mergeInfo.delegateToSchema(_paramsForDelegate)
}
if(args.type === "github") {
return delegate(githubSchema, 'organization', {login: args.name})
}
return delegate(appsyncSchema, 'getMyOrganizationsByName', {name: args.name})
.then(a => (a.length > 0) ? a[0] : null); }
},
listUnionedOrganizations: {
async resolve(parent, args, context, info) {
const delegate = (schema, fieldName, args) => {
const operation = 'query'
const _paramsForDelegate = { schema, operation, fieldName, args, context, info }
return info.mergeInfo.delegateToSchema(_paramsForDelegate)
}
const githubResponse = delegate(githubSchema, 'organization', {login: 'serverless'})
.then(a => [a])
const appsyncResponse = graphql(appsyncSchema, `{ listMyOrganizations { items{__typename, id, name}}}`)
.then(a => a.data.listMyOrganizations.items)
return Promise.all([githubResponse, appsyncResponse]).then(arr => arr.flat())
}
}
},
}
});
return schema
}
const createServer = (schema) => {
const app = express();
const server = new ApolloServer({ schema });
server.applyMiddleware({ app });
return serverless(app);
};
let schema
let sls
exports.graphqlHandler = async (event, context) => {
if(sls == null) {
schema = await createSchema();
sls = createServer(schema);
} else {
console.log("Already initialized")
}
return await sls(event, context);
}
ステップバイステップの説明
GithubやAppSyncからデータを取ってくる処理を以下の関数でラップしています。
const delegate = (schema, fieldName, args) => {
const operation = 'query'
const _paramsForDelegate = { schema, operation, fieldName, args, context, info }
return info.mergeInfo.delegateToSchema(_paramsForDelegate)
}
listUnionedOrganizationsでは、Github側に一覧取得APIがないので、単体取得APIを代用しそれを配列に入れ(1個しか入っていない配列)、その結果とAppSyncの結果をつなげています。
const githubResponse = delegate(githubSchema, 'organization', {login: 'serverless'})
.then(a => [a])
const appsyncResponse = graphql(appsyncSchema, `{ listMyOrganizations { items{__typename, id, name}}}`)
.then(a => a.data.listMyOrganizations.items)
ここでポイントなのですが、AppSyncの特性としてリターン値が少し深い階層になっていますので、delegateではうまくクエリが発行できず結果も得られないことからそのままはマージできません。(正確には対処法があるようですがまだ理解していない)
したがって、delegateはそのまま使いづらいため、少しズルをして、graphql関数でクエリをそのまま書いてしまっています。
最後にそれらの結果を結合します。arrには[[<githubの結果>], [<AppSyncの結果>]]のような2次元配列が送られてくるので、それをflat()で1次元配列にすると結合ができます。
Promise.all([githubResponse, appsyncResponse]).then(arr => arr.flat())
デプロイ
serverlessを使ってAWS Lambdaにデプロイするために、serverless.ymlを以下のように準備します。
service: github-appsync
provider:
name: aws
runtime: nodejs8.10
functions:
graphql:
# this is formatted as <FILENAME>.<HANDLER>
handler: index.graphqlHandler
events:
- http:
path: graphql
method: post
cors: true
plugins:
- serverless-webpack
- serverless-offline
custom:
webpack:
webpackConfig: ./webpack.config.js
includeModules: true
webpackでビルドするためにwebpack.config.jsも準備しました。
const slsw = require("serverless-webpack");
const nodeExternals = require("webpack-node-externals");
module.exports = {
entry: slsw.lib.entries,
target: "node",
devtool: 'source-map',
externals: [nodeExternals()],
mode: slsw.lib.webpack.isLocal ? "development" : "production",
optimization: {
minimize: false
},
performance: {
hints: false
},
module: {
rules: [
{
test: /\.js$/,
loader: "babel-loader",
include: __dirname,
exclude: /node_modules/
}
]
}
};
以上の環境で、以下コマンドによりAWS Lambdaにデプロイします。
sls deploy
検証結果
検証方法として、以下の2つのクエリ(一覧取得と単体取得)を同時に実行します。
query simple($name: String = "HumanResourceDept", $type: String = "appsync") {
getOneUnionedOrganization(name: $name, type: $type) {
...any
}
listUnionedOrganizations {
...any
}
}
fragment any on UnionedOrganization {
__typename
... on Organization {
... git
}
... on MyOrganization {
id
name
}
}
fragment git on Organization {
id
location
name
repositories(first: 3) {
nodes {
name
stargazers {
totalCount
}
}
}
}
パラメータには、あらかじめAppSyncに登録しておいた組織名を入力します。
{
"name": "ProcurementDept",
"type": "appsync"
}
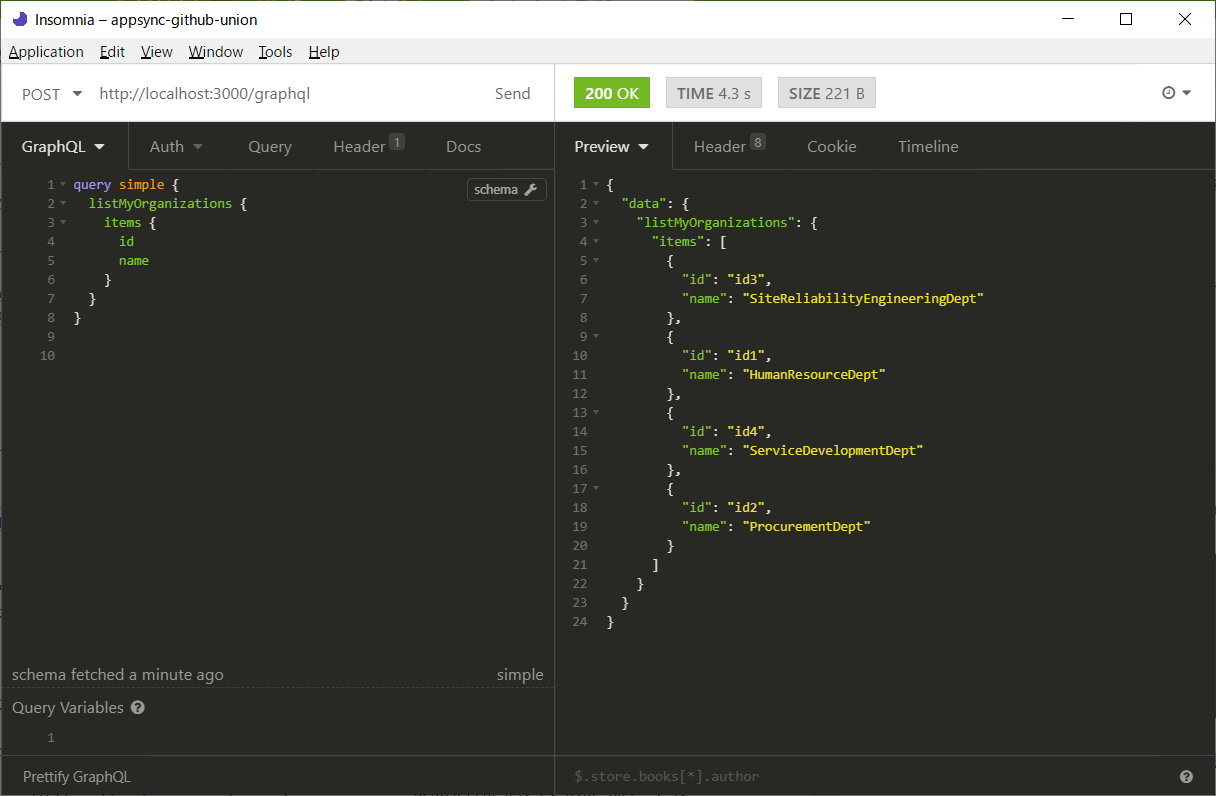
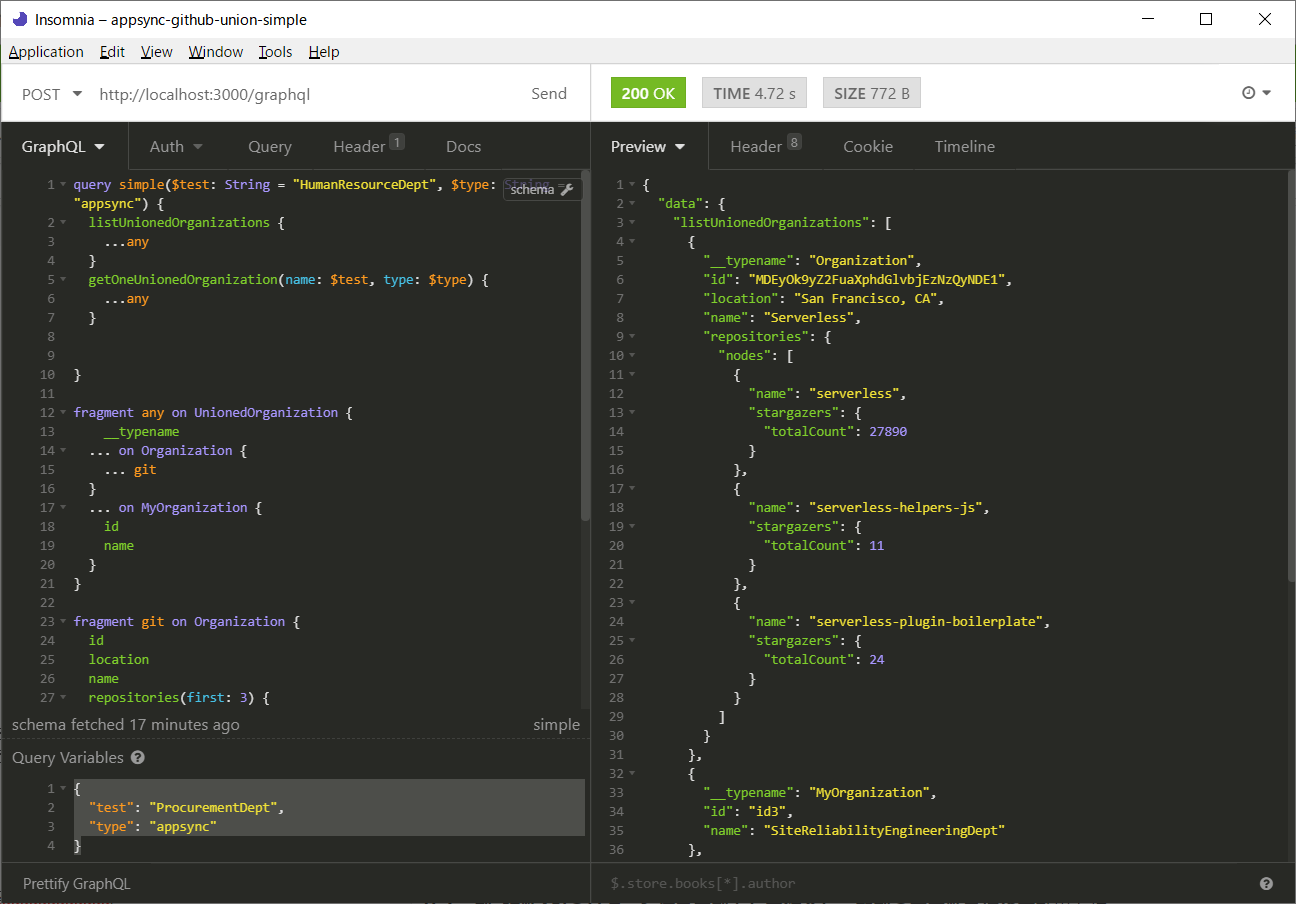
検証した結果、以下の通り。
まずlistUnionedOrganizationsにはGithub APIの結果1つとAppSyncの結果4つがマージされています。
また、getOneUnionedOrganizationでは、$nameで指定したProcurementDeptという値をもった組織が一つ取り出されています。
{
"data": {
"listUnionedOrganizations": [
{
"__typename": "Organization",
"id": "MDEyOk9yZ2FuaXphdGlvbjEzNzQyNDE1",
"location": "San Francisco, CA",
"name": "Serverless",
"repositories": {
"nodes": [
{
"name": "serverless",
"stargazers": {
"totalCount": 27890
}
},
{
"name": "serverless-helpers-js",
"stargazers": {
"totalCount": 11
}
},
{
"name": "serverless-plugin-boilerplate",
"stargazers": {
"totalCount": 24
}
}
]
}
},
{
"__typename": "MyOrganization",
"id": "id3",
"name": "SiteReliabilityEngineeringDept"
},
{
"__typename": "MyOrganization",
"id": "id1",
"name": "HumanResourceDept"
},
{
"__typename": "MyOrganization",
"id": "id4",
"name": "ServiceDevelopmentDept"
},
{
"__typename": "MyOrganization",
"id": "id2",
"name": "ProcurementDept"
}
],
"getOneUnionedOrganization": {
"__typename": "MyOrganization",
"id": "id2",
"name": "ProcurementDept"
}
}
}
オフラインでの実行結果
まとめ
既存APIであるGithub APIと自作のAppSync APIを結合させるシナリオとして、同列の結合をunionを使って実施しました。
結果、Lambda上で結合した結果のAPIを稼働できました。
リゾルバの書き方が少し工夫が必要でしたが、マージの処理をうまく作れば、1個のAPIで複数のデータソースの検索も可能ですね。
同列の結合と親子関係の結合
同列の結合の処理を少しかみ砕きます。
前回記事の結合と比べてみます。
前記事の親子関係で2つのAPIを結合するやり方をJoin型と名付け、今回の同列なAPIを結合するUnion型と名付けます。
Join型とUnion型が生成するデータの違いを図示したのが次の図です。
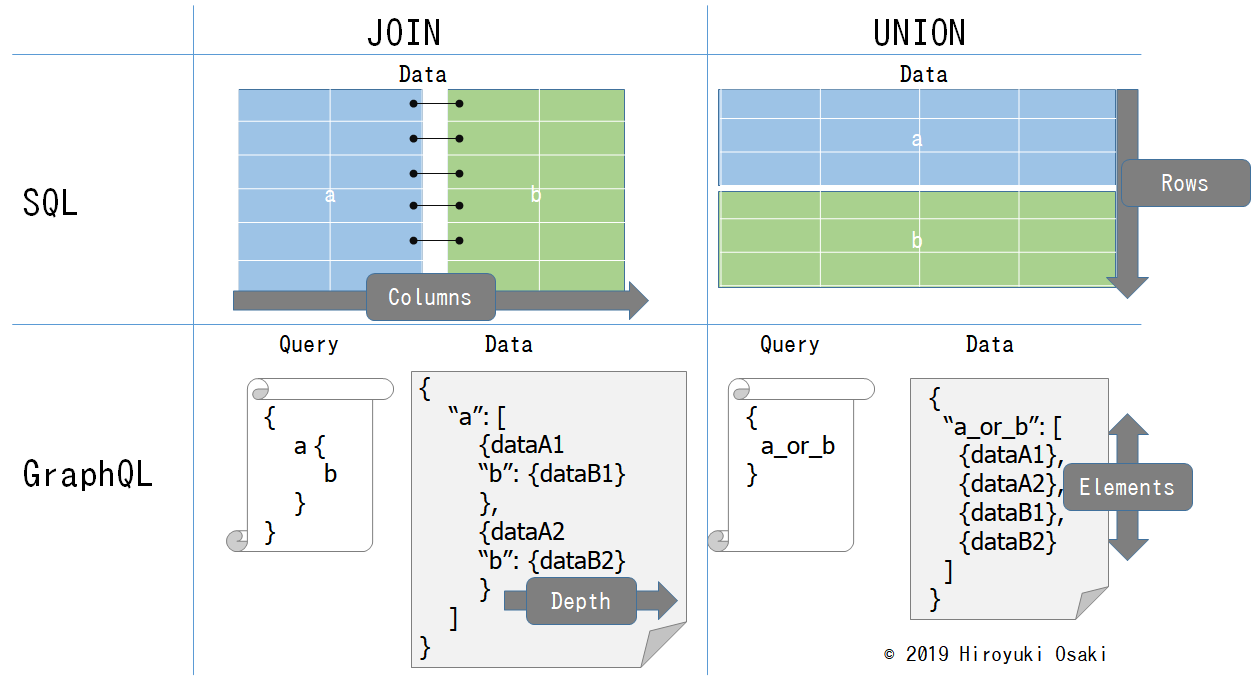
Join型とUnion型のふるまいの違いは、SQLのJOINとUNIONと似ています。
SQLで見ると、
JOIN: テーブルを横に結合し、列数を増やす効果を持つ
UNION: テーブルを縦に結合し、行数を増やす効果を持つ
GraphQLでも同じと考えることができます。
Join型: 複数APIのリターン値を親子関係に結合し、深さを増やす効果を持つ
Union型: 複数APIのリターン値を同列として結合し、配列の要素数を増やす効果を持つ
(網羅的な処理ができる)
Join型とUnion型を適宜組み合わせることで、データサイエンティストが必要とする整形データができていくのではないでしょうか。