この記事は Kubernetes2 Advent Calendar 2020 の 2 日目です。
本記事は、全く CRD を知らないところからスタートし、ざっくり CRD を理解して少し好きになることを目的にしています。
(ITNEXT投稿記事を翻訳/改変したものです)
CRD ってなんだか難しそう
CRD... Custom Resource Definition は Kubernetes 内で作れる特殊なオブジェクト (リソース) です。
Kubernetes の普通の使い方、例えばコンテナを起動するというだけであれば、ユーザは CRD のような特殊なリソースを使う必要はありません。したがって、CRDとは、ほとんどの人にとっては重要ではないものです。
しかし、たまに最近の技術ブログなどでは CRD を目にすることがあります。また、kubernetes.ioやKubernetes界隈の議論スレッドでも見ることがあります。こういう場面に出くわすと、CRD を知らなかった場合は理解に少し時間をかけなくてはいけません。私もそういう一人でした。
CRD とは何なのでしょうか。どうやって使うのでしょうか。もし必要になったら、どうやって作ればいいのでしょうか。
心配はありません。実はさほど難しいものではありません。今回は、CRD とそれに関連する CR の概念について、できる限りかんたんに説明したいと思います。
CRD は端的に言うと
CRD とは、単なるデータベースのテーブルです。この記事で説明したいことは実はそれだけです。
例えば、データベースの世界のことを考えてみます。まず、以下のようなテーブルを作ることを考えましょう。
- "Fruit" という名のデータベースのテーブルを作るとします。
- テーブルには "apple", "banana", "orange"という3つのフルーツを表すレコード3行を登録します。
- これらのレコードは、 "name", "sweetness", "weight"という3つの列を持つとします。この3つの列は、フルーツの「名前」「甘さ」「重さ」という特徴を表しています。
すでに、データベースに馴染みがある方は、CREATE TABLE 文がぱっと頭をよぎったのではないでしょうか。上記テーブルは非常にかんたんなテーブル実装の例です。
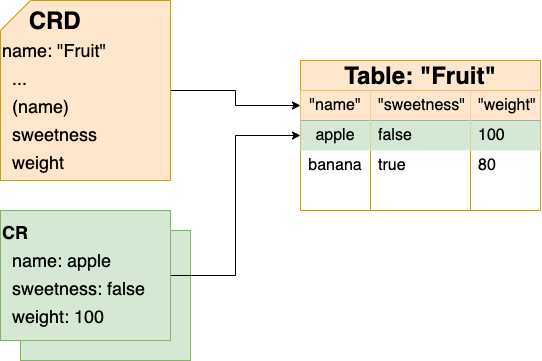
ここからが本題ですが、CRD はまさにこれと同じテーブル定義を含んだ情報です。CRD のかんたんな模式図を以下に示します。

次に、CR (Custom Resource) とは、"apple"などのそれぞれのレコードです。CRD がテーブルなら、その中のレコードが CR というわけです。CR のかんたんな模式図を以下に示します。

どうやって CRD を作るの?
すでに説明したとおり、 CRD はテーブルです。テーブルを作るとき、列名や列の型などのテーブルのフォーマットの情報を入力する必要があります。フォーマットの情報は CRD の定義ファイル (YAMLやJSONデータ)の中に書き込まれます。
また、レコードごとの情報は、CR 定義ファイルのYAMLやJSONデータで定義されます。
CRD, CR のそれぞれの定義ファイルとそれが指すテーブルの対応関係は以下のようになります。
では、 CRD の定義ファイルの中身を見ていきましょう。

CRD の定義ファイルはは大きく以下の3つのパートに別れます。
- 一般的な情報のパート
- Kubernetes内の他のリソースと同じように、CRD リソースの名前などの共通的なメタデータを書く部分です。
- 例:
name: "fruit"など。
- テーブルレベルの情報を書くパート
- テーブルの名称やその複数形など、Kubernetesでテーブルを扱うために必要な情報を書く部分です。
- 例:
kind: Fruit,simpler: fruit,plural: fruitsなど。
- 列レベルの情報を書くパート
- 列名 (
"sweetness"など)や列の型 ("boolean","string","integer","object"), ネストされたオブジェクトの定義など (props: <子要素の名前や列>) - これらの定義は、Open API Specification の version 3の記法で定義されます。
- 列名 (
より詳細な情報は公式ドキュメントを参照ください。
CRD の機能を試してみる
CRD は本当にテーブルとして操作できるのでしょうか。確かめてみましょう。
実際の確認結果の説明の前に少しだけ前置きさせてください。通常はCRD の定義ファイルを手動で作成するのが普通だと思いますが、今回はCRDの定義ファイルをよりかんたんなYAMLから自動生成する方法を使います。詳細は後で紹介します。その点をご了承いただければ幸いです。
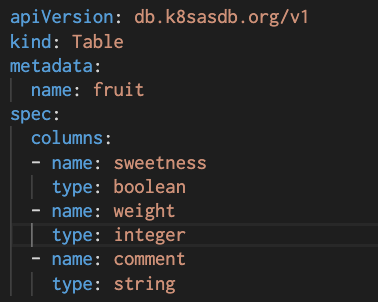
今回作るテーブルは単純です。先に少し例で説明した「フルーツ」用のCRDを作りたいと思います。"Fruit"というCRDは以下の3つの列を持ちます。
| 列名 | 列の方 |
|---|---|
sweetness |
boolean (甘いか甘くないか) |
weight |
integer (何グラムかを数字で表す) |
comment |
string (参考情報を文字列で記載する) |
これを端的なYAMLで記載すると以下のようになります (これはまだ正式な CRD 定義ファイルではありません)。列名や型がそれぞれ定義されています。
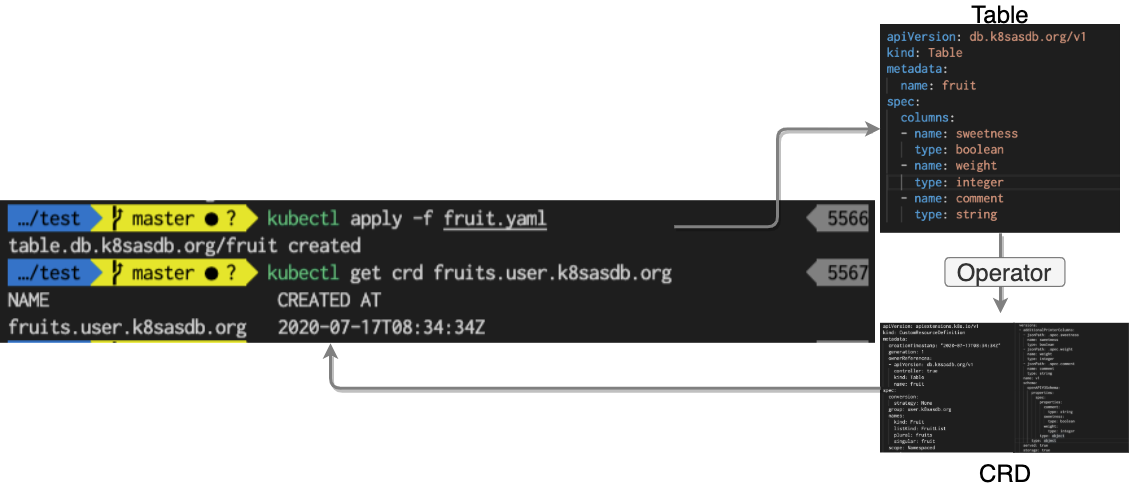
ここから CRD の定義ファイルを作ります。先の端的なYAMLをKubernetesに導入する際にある変換処理としてOperatorを用いて CRD の定義ファイルを自動生成します。生成した CRD 定義ファイルは以下のようになります。直接手動でCRDを作成する場合には、不要なownerReferencesやcreationTimestampを外しコピーし、kubectl apply -f <ファイル名>を実行すれば問題ありません。
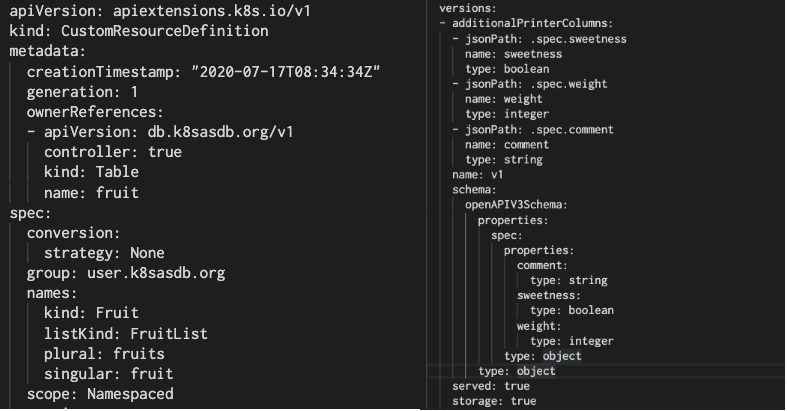
実際に生成された CRD の定義ファイルはここを開いて参照ください (Operatorを使わない場合はこれを直接ファイルに保存して`kubectl apply -f <ファイル名>`してください。)
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: fruits.user.k8sasdb.org
spec:
conversion:
strategy: None
group: user.k8sasdb.org
names:
kind: Fruit
listKind: FruitList
plural: fruits
singular: fruit
scope: Namespaced
versions:
- additionalPrinterColumns:
- jsonPath: .spec.sweetness
name: sweetness
type: boolean
- jsonPath: .spec.weight
name: weight
type: integer
- jsonPath: .spec.comment
name: comment
type: string
name: v1
schema:
openAPIV3Schema:
properties:
spec:
properties:
comment:
type: string
sweetness:
type: boolean
weight:
type: integer
type: object
type: object
served: true
storage: true
この CRD こそが Kubernetes における自作テーブル定義方法です。この中には、先ほど定義した「"sweetness"という列がbooleanである、、」といった情報が埋め込まれていることがわかります。
これを入力されたタイミングから、Kubernetes は「あ、フルーツというリソースがあるんだな」と理解し、これに対応する「レコード追加」や「削除」などのAPIを稼働させます。Swaggerドキュメントも自動生成し公開します。
これは、データベースにおいて "CREATE TABLE"をしたあとにそのテーブルの処理ができるようになるのと同じです。
さて、本当にデータベースと同じように振る舞うのか、試します。
レコードを追加してみる
Kubernetesにおけるレコードは、さきに説明したとおり CR でした。CRを追加するには、まずCRの定義ファイルを以下のように記載します。
apiVersion: user.k8sasdb.org/v1
kind: Fruit
metadata:
name: apple
spec:
sweetness: false
weight: 100
comment: little bit rotten
この CR には、appleというフルーツがあり、甘さはそれほど甘くなく、重さが100グラムで、コメントとしては「ちょっと腐っている」ということが書いてあります。
どのテーブルに追加するレコードかということを、上のkind: Fruitで指定しています。これを見て、 Kubernetes は「あ、Fruitというテーブルに追加するレコードね」と理解します。
では実際に CR を追加してみます。
kubectl create -f apple.yaml

エラーが出ずに実行完了したことを表示しています。
このコマンドはまさにデータベースのクエリで言うところの以下と同じと言えます。
INSERT INTO fruits values('apple', ...);
レコードのリストを取得する
CR のリストを取得するには以下のコマンドが使えます。
kubectl get fruits
Kubernetes を使っている方なら、この馴染みのある kubectl getコマンドで自作のCRDの操作ができることが楽しいと感じられると思います。このコマンドにより、以下の結果を得られます。

この結果は、私が"apple"と"banana"という2つのレコードを追加した際の状態を示しています。
これは、データベースにおける以下のクエリと同じです。
SELECT * FROM fruits;
単一レコードを取得する
一つだけ CR を取得するには以下のコマンドが使えます。
kubectl get fruit apple
単に、前のコマンドの後ろにappleという名前をつけただけになっています。Kubernetes で Pod などを取得するときと同じです。このコマンドにより、以下の結果を得られます。

私がすでに "apple"と"banana"という2つのCRを追加したにもかかわらず、コマンドは単一のレコードのみを取得していることがわかります。
これは、データベースにおける以下のクエリと同じです。
SELECT * FROM fruits WHERE name = 'apple';
レコードを削除する
kubectl delete fruit apple
上記のコマンドで、レコードを削除できます。

この結果、Fruitの全レコードの中にはすでにappleというレコードは削除され、bananaしか残っていないこがわかります。

これは、データベースにおける以下のクエリと同じです。
DELETE FROM fruits WHERE name = 'banana';
なぜ CRD が必要なのか
なぜ CRD が必要とされるようになったのでしょうか。私は、この理由をこう考えています。
Kubernetes は近年さまざまなユーザが幅広い用途に使うようになりました。APIやコマンドも非常に使いやすく便利です。そうなると、ユーザはもっと自分が便利になるよう、いろんなデータをKubernetesに登録したくなります。そのデータに応じて Kubernetes の振る舞いを変えさせたい、とも考えるようになります。
ここから、ユーザごとに違うフォーマットのデータを登録したい、列名やデータ型が異なるデータを登録したい、というニーズが生まれます。しかし、Kubernetes にはそのようなユーザごとのデータを事前に登録しておくということはできません。ニーズを実現するには、Kubernetes 構築後の事後でもユーザごとのデータを登録できるように、柔軟なスキーマ定義をさせる必要があります。
このインターフェースが CRD という形で実現されたのだと考えます。
CRD を使う一例として、会社の部署ごとの予算、といった情報を CRD で Kubernetes に登録しておき、予算消化状況に合わせて起動できる Pod 数の上限をコントロールするといった使い方が考えられます。
まとめ
本記事では、 CRD がデータベースのテーブルと同じであることを説明しました。
- CRD を作成することで、Kubernetes内にテーブルを作成できます。
- CR を作成することで、テーブル内にレコードを追加できます。
- テーブルの定義に必要な情報 (列名や型)はCRDの定義ファイルの中に書きます。
- CRD や CR を Kubernetes に登録するには、
kubectlコマンドを使用します。 -
kubectl apply -f <定義ファイル>でレコードを追加し、kubectl getにてレコードを表示し、kubectl deleteでレコードを削除できます。
最後に補足 (かんたんなYAMLからの CRD の自動生成)
今回 Fruit という CRD を作成した際に使用した自動生成ツールは以下のレポジトリに公開しています。
最初に定義した端的な YAML ファイル自体も Table という独自の CRD です。以下のように Table を登録することで CRD が生成されます。Table から正式な CRD を自動生成するために Operator という仕掛けを使います。この手法を適用するには、事前にこの Operator を Kubrnetes クラスタに導入しておく必要があります。導入方法などは先のレポジトリのREADMEをごらんいただき、フィードバックをいただければ幸いです。