はじめに
「本日の格言」とは
大川総裁の格言が毎朝8時に配信されるサービスです。スマホアプリ版とメール版の2種類があります。
以下に格言の例を示します。
【人間と動物を分けるもの】信仰の本能とは、「目に見えないものを信じ、理解し、それに基づいて行動することができる」という性質のことです。何を信ずるのかといえば、伝統的には、「仏」や「神」という言葉で表わされるもの、すなわち「仏神」です。「仏神... https://t.co/SFBlxqkCLY #大川隆法
— 大川隆法【公式】本日の格言 (@hs_word) 2018年8月16日
「本日の格言」予想コンペ
夏休みが暇すぎたので前日までの情報をもとに翌日の格言の出典を予想する遊びを考えました。例えば2018年8月16日の格言であれば、前日に『繁栄の法』を正しく予測できていれば正解とします。今のところ参加者は世界で僕一人です。
分析
モチベーション
大川総裁の多作ぶりをご存じの方は分かると思いますが、膨大な著作の中からピンポイントで翌日の格言の出典を当てるのは困難をきわめます。2018年8月現在大川総裁の著作は2,300冊を超えるということで、もしこの中から一様にランダムな選定がなされるとすれば正解する確率は一試行あたり0.04%程度です。実際は格言の出典には『Are you happy?』などの雑誌も含まれるので確率はさらに下がります。そこで今回の記事では過去の格言のデータを集計して、少しでも格言として採用されやすい著作を見つけることを目的とします。
データの取得
上に引用したツイッターのリンクから、格言が公開されているURLは以下のような構成をしていることが分かります。
https://ryuho-okawa.org/quotes/20180817/
この流れでいけば、例えば2016年7月1日の格言であれば、最後の数字の部分のみを変更してhttps://ryuho-okawa.org/quotes/20160701/のように指定すればよさそうです。
データの取得にはPythonのBeautifulSoupモジュールを使います。
from urllib import request
from bs4 import BeautifulSoup
import re
import time
base_url = "https://ryuho-okawa.org/quotes/"
def extractBook(url):
try:
html = request.urlopen(url)
except:
return 'failed'
soup = BeautifulSoup(html, "html.parser")
book_tag = soup.find("p", class_="book").find('span')
book = re.sub(r'<[^>]*?>', '', str(book_tag))
time.sleep(1)
return book
books = []
start = time.time()
for year in range(2014, 2019):
for month in range(1,13):
for day in range(1,32):
sub_url = str(year) + str(month).zfill(2) + str(day).zfill(2)
url = base_url + sub_url
book = extractBook(url)
books.append([year, month, day, book])
if(len(books) % 100 == 0):
print('#', end='')
elapsed_time = time.time() - start
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
手動でURLを打ち込んで調べたところ、格言が始まったのは2014年の1月2日からということが判明したので、2014年から始めてforループで総当りで日付の部分を生成しています。この方法だと2月31日のような存在しない日付も生成されてしまいますが、そのような場合は単に404エラーが返ってくるだけなのでプログラムが止まることはありません。
また今回スクレイピングをする上で非常に助かったのは出典を表す文字列が書かれている箇所に独自クラスのbookクラスが指定されていたことです。このクラスは出典以外では使われていなかったので、htmlソースの中からbookクラスが書かれている箇所をサーチすれば書籍名が簡単に取得できました。
幸福の科学のサーバーの負荷を考慮して1件ごとにインターバルを1秒取るようにすると、過去の格言を全件取得するのに45分かかりました。
データの整形
取得したデータはこのままだと分析に適した形式にはなっていません。今回はPythonついでにpandasモジュールを使ってデータを整えていきましょう。
import pandas as pd
books = pd.DataFrame(books, columns=['year', 'month', 'day', 'title'])
books = books[books.title != 'failed']
books.head(10)
取得したデータは以下のような表形式で表されます。
| year | month | day | title | |
|---|---|---|---|---|
| 1 | 2014 | 1 | 2 | 『忍耐の法』 |
| 2 | 2014 | 1 | 3 | 『忍耐の法』 |
| 3 | 2014 | 1 | 4 | 『生涯現役人生』 |
| 4 | 2014 | 1 | 5 | 『新しき大学の理念』 |
| 5 | 2014 | 1 | 6 | 『忍耐の法』 |
| 6 | 2014 | 1 | 7 | 『創造の法』 |
可視化
ヒストグラム
まず、タイトルごとに回数をカウントして、ヒストグラムを作ってみました。
books_count = books.title.value_counts()
ax = books_count.hist(figsize=(8,6))
ax.set_xlabel('frequency (times)', fontsize=18)
ax.set_ylabel('count (books)', fontsize=18)
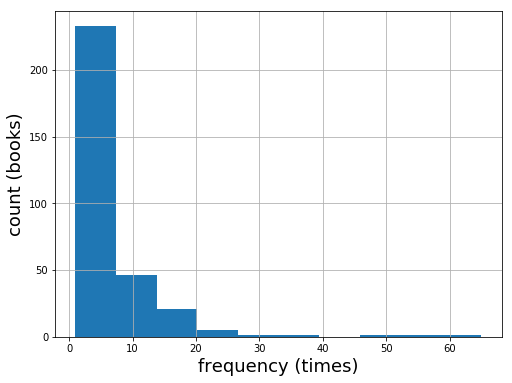
このグラフから、そもそも格言に選ばれやすい著作が存在するのかどうかが分かります。もしどの著作も均等に格言に選ばれているのだとしたら、棒グラフは一箇所にかたまるはずです。一見グラフはそのような期待を裏付けているように思えますが、注目するべきなのは、少数ではあるものの大多数の著作よりも格言への登場頻度が格段に高い著作が存在することです。例えば右端の著作は50〜60回近く格言に登場したものです。
多少私の主観も入りますが、このような形状の分布は一般にべき乗分布と呼ばれるもので、自然や社会に広くみられるポピュラーな分布です。年収の分布などもこの形状の分布で表されることが多いですが、一部のサンプルが並外れて大きな値をとることが特徴です。この分布はサンプル間の格差が大きいことを表しているとも言えるので、あまり好きではない人もいるかもしれませんが、今回のように著作を予測する場合には好都合です。なぜなら大多数の著作に比べて並外れて高い頻度で格言に登場する著作があるので、その著作を予想すれば正解する可能性も高まると考えられるからです。
頻繁に登場する著作をみつける
それではヒストグラムの右端に位置する著作はどのようなものなのでしょうか。出現頻度上位10件を取り出してみます。集計はヒストグラムの作成のところのvalue_countメソッドで済んでいるので、あとは表示するだけです。
| title | frequency |
|---|---|
| 『忍耐の法』 | 65 |
| 『生涯現役人生』 | 53 |
| 『智慧の法』 | 49 |
| 『幸福の法』 | 33 |
| 『成功の法』 | 28 |
| 『勇気の法』 | 25 |
| 『光ある時を生きよ』 | 24 |
| 『未来の法』 | 21 |
| 『人生の王道を語る』 | 21 |
| 『繁栄思考』 | 21 |
5年間を通して出現回数栄えある第一位に輝いたのは『忍耐の法』でした。また全体的に法シリーズが多いのも特徴的です。それではこれからは『忍耐の法』を予想するようにすれば成功する可能性が最大となるのでしょうか? ただ、どうもそうではないようなのです。
トレンドを捉える
今回の分析の目的は、明日の格言の予想です。ということは単に回数の多い著作ではなくて、現在そしてこれから登場する見込みが高い著作を予想するべきです。実際に、先ほどのカウントを年ごとに集計しなおしてみると、例えばこんな結果が出ます。
| year | 2014 | 2015 | 2016 | 2017 | 2018 |
|---|---|---|---|---|---|
| 『忍耐の法』 | 57 | 8 | 0 | 0 | 0 |
これを見ると『忍耐の法』が多く出現していたのは2014年で2016年以降は全く出現していません。このように回数は多くてもトレンドがない(/負)の著作を予想するのはナンセンスだと思われます。
それではトレンドのある著作を見つけ出すにはどのようにすれば良いでしょうか? この問に答えるには**何をもってトレンドとするか?**という問いに答える必要があり、これが意外と難しい質問です。直線をあてはめて傾きをみたり、成長率の対数を足しあわせたりと色々な方法があるみたいですが、どれも一長一短な印象があります。
今回は、2018年に6回以上出現した著作を抽出し、そのすべてについて実際にグラフを書いて定性的に判断することにしました。
# 5年間の総出現回数が10回以上の著作に限定しました
books_popular = books[books.title.str.contains('|'.join(books_count[books_count > 10].index))]
books_ts = pd.crosstab(books_popular.title, books_popular.year)
# この変換はちょっと怪しいですが、2018年の分は8月分までしかないので観測された値に1.6倍しています。
books_ts[2018] = (books_ts[2018] * (365/228)).round()
books_ts[books_ts[2018] > 5].T.plot(figsize=(12,6), fontsize=18, xticks=range(2014,2019))
plt.xlabel('year', fontsize=18)
plt.ylabel('frequency', fontsize=18)
plt.legend(loc='upper left', prop={'size':14}, bbox_to_anchor=(1,1))
plt.tight_layout(pad=7)
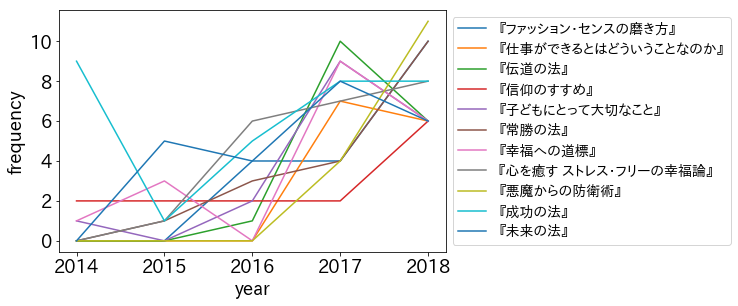
この結果をみると、『悪魔からの防衛術』『常勝の法』あたりがトレンドになっていそうです。ほかも概ね右肩あがりですが、『成功の法』だけはV字回復してトレンドになっています。
結論
今回の分析はモデリングなしの簡易的なものでしたが、それでも当てずっぽうに予想し続けるよりは正解する可能性が上がった気がします。せっかくなのでしばらくは上に挙げた11個の著作の中から色々試していこうと思います。今回の分析に使ったコードはここに掲載しています。至らない点も多々あると思いますが、暇な人は参考にしてみてください。