この記事の目的
機械学習を学ぶためのリソースを探していました。その中で評判の良いコースがあったので、受講しています。
受講記録を残すことで、講義を理解できているか改めて確認します。
また、私と同じように機械学習を学ぶリソースを探している方の参考となれば幸いです。
fast.aiコースとは
fast.aiコースという、機械学習を学べる無料のコースをご存知でしょうか?
fast.aiコース
- 誰が作ったもの?
ジェレミーハワードさんという方のクイーンズランド大学での講義を基に作成されたものです。この方は国際的な機械学習コンペで世界一になったり、様々な機械学習のプロジェクトを実施してきたすごい方らしいです。 - 内容は?
コースの内容は機械学習のモデル構築、デプロイ、精度改善等を実装しながら学んでいくというものです。実際の問題に活用することがイメージしやすいと思われます。 - 受講前提は?
受講の前提はPythonのコーディング方法を知っていること、高校レベルの数学知識があることのみであり、受講のハードルが低いです。 - どうやって受講する?
コースは無料で読める本とYoutubeの動画の両方で受けることができ、個人の好みに合わせて進めることができます。登録などは不要です。
このコースを受講した人が、一流企業にオファーを受けた、論文を発表した、機械学習を用いたサービスを開発したといった実績もあるようで、受講のモチベーションを高めるようなことが書いてあります。
ディープラーニングは実装しながら学ぶべき
数学はどのように学ぶでしょうか。一般的には基礎的な内容を学び続けた先で、応用を学ぶという順序だと思います。これは、サッカーで例えるとインサイドキックのやり方からオフサイドトラップのかけ方等一通りの技術を習得するまで、試合を行わないようなものです。
ディープラーニングも通常は数学の基礎から学びます。しかし、このコースでは最初にディープラーニングを実装することから始めます。
実装したモデルを修正し、精度を向上させていくことを目的として、理論を学習するという流れです。
例えば、モデルの実装にデータ量が十分なのか、データの形式は正しいものか等は実装経験から学んでいくものです。できるだけ早く経験できるように、ディープラーニングを自分で実装することを優先します。
最初のモデルを実装する
早速、最初のモデルを実装します。モデル実装に使うライブラリ、ソフトウェアを定義したうえで、実装例に移ります。
使用するライブラリ・ソフトウェア
Pytorch
ディープラーニングのライブラリ。トップカンファレンスの研究論文のほとんどで使用されています。
fastai
Pytorchを低レイヤーのライブラリとして使い、高レイヤーの機能追加に使います。深く階層化されたソフトウェアアーキテクチャを提供するものです。
Jupyter
フォーマットされたテキスト、コード、画像、ビデオ等すべてを一つのドキュメントに含めることができるソフトウェアです。
ただし、どのライブラリ、ソフトウェアを使用するかは大きな問題ではありません。一つのライブラリ、ソフトウェアの使い方を習得すれば、同様のライブラリに切り替えることは簡単にできるためです。
実装
ライブラリ、ソフトウェアを定義したので、モデルの実装に移ります。ここでは渡された画像を猫か犬かを判断する画像認識モデルを実装します。
①まずはfastaiに関連するライブラリをインストールします。
! pip install fastbook
from fastbook import *
②続けて、モデル実装に使うデータを取得します。
#猫と犬を検索対象とする
searches = 'cat', 'dog'
path = Path('cat_or_not')
#猫と犬の画像を検索し、画像を保存する
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True,parents=True)
results = search_images_ddg(f'{o} photo')
download_images(dest, urls=results[:200])
resize_images(dest, max_size=400, dest=dest)
#うまくダウロードできていない画像は削除する
failed = verify_images(get_image_files(path))
failed.map(Path.unlink);
len(failed)
③ダウンロードしたデータをモデル実装で使用できる形式に整えます。
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')],
).dataloaders(path)
dls.show_batch(max_n=6)

④事前トレーニング済のモデルをダウンロードします。そのうえで、今回ダウンロードした猫と犬の画像を基に微調整させます。
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
100%|██████████| 44.7M/44.7M [00:00<00:00, 177MB/s]
epoch train_loss valid_loss error_rate time
0 0.855996 0.086447 0.056338 00:03
epoch train_loss valid_loss error_rate time
0 0.208480 0.062657 0.014085 00:02
1 0.140033 0.101857 0.056338 00:01
2 0.106803 0.103447 0.056338 00:01
これでモデルの実装は完了です。試しに画像をアップロードして、猫かどうかを判定してもらいます。
できるだけ犬っぽい猫を探してみました。
uploader = widgets.FileUpload()
uploader
PILImage.create(uploader.data[0])

is_cat,_,probs = learn.predict(PILImage.create(uploader.data[0]))
print(f"This is a cat ?:{is_cat}.")
print(f"Probability it's a cat: {probs[0]:.4f}")
This is a cat ?:cat.
Probability it's a cat: 0.9832
98%で猫と判断しました。モデルの実装は成功しているようです。
ここまでわずか4ステップで画像認識機能を持つモデルを実装できました。大まかな実装方法が分かったところで、このモデルの裏側で何が起こっているのかを確認していきます。
この4ステップの詳細についても後ほど解説があります。
実装したモデルの裏側にある理論を整理する
モデルの実装を行ったので、いったん一歩引いて、機械学習の全体を見渡します。
先ほど実装したモデルはディープラーニングのモデルです。そのディープラーニングは機械学習の一分野であるといえます。ディープラーニングのモデルの本質を知るためには、機械学習を知る必要があります。
機械学習とは何か
機械学習は平たく言うと、コンピュータに特定のタスクを実行させる方法です。
この言葉だけですと、通常のプログラムと変わらないように思えますが、違いはどこにあるのでしょうか。
通常のプログラムは、特定のタスクを実行するための手順を全て定義します。例えば、何らかの会計処理であれば、処理手順は決まったものがあります。インプットとなるデータを受け取り、会計処理を実行できるようにプログラムで定義します。

一方、処理手順を定義することが難しいタスクもあります。ある画像が猫の画像かを判断する手順を定義することは不可能に近いのではないでしょうか。
このような処理手順を定義することが難しいタスクを実行させる方法が機械学習です。
アーサーサミュエルという方が、機械学習をもう少し一般化した定義を作っています。
解くべき問題の例を見つけ出し、コンピュータ自身に解決方法を理解させる。
さらに具体的な実装をこのように定義しています。
- 現在の重みづけの有効性を自動でテストする手段を用意する。
- 有効性は実際のパフォーマンスを基準にテストする。
- テストのパフォーマンスを最大化するように重みづけを変更する手段を用意する。

重みづけとは、プログラムに入力されたデータに対して割り当てるものです。どのデータにどの数値を割り当てることで、モデルの精度が変わります。
実際のパフォーマンスというのは、モデルの精度の良しあしです。パフォーマンスを基準として、重みづけを更新していくという考え方です。
ニューラルネットワークとは何か
機械学習の概要を整理したので、その中のディープラーニングで使用する理論の概要です。
ディープラーニングではニューラルネットワークという理論が使われます。詳細は今後のコースで言及するようです。
現時点では、ニューラルネットワークは非常に柔軟な関数のようなものであり、様々な場面に応用がききやすいということを認識しておきます。
ディープラーニング固有の用語
ディープラーニングで使われる固有の用語がいくつかあります。ここで一度整理します。
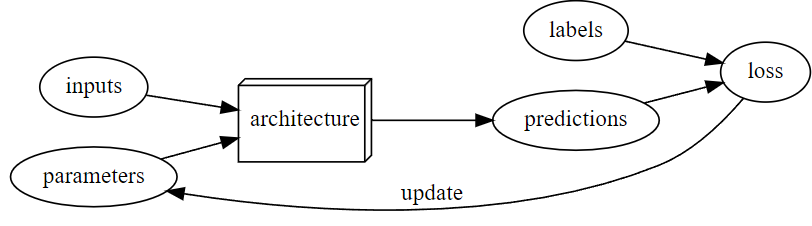
- モデル=アーキテクチャ
- 重みづけ=パラメータ
- モデルの出力=予測
- パフォーマンスの尺度=損失
予測はラベル以外のデータを使って計算されます。
損失は予測とラベルを合わせて計算されます。
機械学習固有の限界
機械学習の仕組みを改めて見ることで、機械学習の限界が見えてきます。
1.データがないとモデルのトレーニングができない
→モデルのトレーニングはデータをインプットすることから始まります。そのデータがなければどうにもなりません。
2.トレーニングに使用したデータだけがモデルに反映される
→インプットされていないデータはモデルには影響しません。
3.予測しかできない
→予測しかできないため、実装の目的と結果が乖離することがある
4.データ+データのラベルが必要
→トレーニングのためにはデータのラベルが必要。現実世界ではデータのラベルがないことが多い
これらの限界があることを理解することが重要です。
実装したモデルが何をしているのか整理する
機械学習の仕組みを一通り見たので、改めて実装したモデルが何をしているのか詳細に見ていきます。
画像認識モデルの仕組み
ここではモデル実装の部分に絞って実装したコードの解説をします。
まずは、モデル実装に使用するデータに関する情報を定義している箇所です。
dls = DataBlock(
#入力データの種類(ここでは画像)と出力データの種類(ここでは分類)を定義
blocks=(ImageBlock, CategoryBlock),
#データの格納先を定義。get_image_filesは渡されたパス内全ての画像ファイルを返す関数
get_items=get_image_files,
#検証用データの割り当て方法
splitter=RandomSplitter(valid_pct=0.2, seed=42),
#ラベルの取得方法。ここでは親ディレクトリの名前を使用する
get_y=parent_label,
#各データに何らかの処理を行う。ここでは画像のサイズ変換
item_tfms=[Resize(192, method='squish')],
#画像フォルダが格納されているパスを渡す
).dataloaders(path)
続けてモデル実装の箇所です。
#モデル実装に使うデータ、モデルのアーキテクチャ、モデルの品質を測るメトリックを指定する
#pretrainedというパラメータもあり、これはデフォルトでTrueとなっている。
#これにより事前に一般的な画像でトレーニング済のモデルを使うことができる
learn = cnn_learner(dls, resnet18, metrics=error_rate)
#事前トレーニング済のモデルを、今回使うデータで微調整する
learn.fine_tune(3)
まとめ
Introductionでは、簡単ですが精度はある程度高いモデルの実装を行いました。また、その背景にある機械学習の仕組みの概要を学びました。
講義2以降も受講次第、内容を整理していきます。