
近年、ビッグデータを活用する際にデータの匿名性が重要になってきました。これは匿名加工されたデータであれば、本人の同意なしに第3者にデータを提供して活用できることに関連しています。このあたりの話は情報処理学会誌の5月号にわかりやすい特集が組まれています。
今までは、データの匿名化は主に構造化データに対して行われてきました。構造化データというのは簡単に言うとRDBのテーブルに格納されているようなデータのことです。それらのデータに対して、個人を特定したり、レコードを紐付けられないように処理するのが匿名化です。
本記事では、非構造化データであるテキストに対して匿名化(というより医療情報でいうところのde-identification)を行ってみます。具体的には、自然言語処理の基礎技術である固有表現認識を使って、テキスト中の人名や組織名を認識し、黒塗りします。黒塗りの対象はニュースのテキストとします。
固有表現認識
固有表現認識とは、テキストに出現する人名や地名などの固有名詞や、日付や時間などの数値表現を認識する技術です。具体例を見てみましょう。以下の文から固有表現を抽出すると人名として太郎と花子、日付として5月18日、時間として朝9時が抽出できます。
太郎は5月18日の朝9時に花子に会いに行った。
固有表現認識で認識した固有表現を黒塗りすることで、匿名化っぽいことができると考えられます。というのも、機密文書で黒塗りされている部分は機密に関係している人名や組織名などが多いと考えられるからです。上文の固有表現部分を黒塗りすると以下のようになります。
■■は■■■■■の■■■に■■に会いに行った。
今回は固有表現を認識するためにディープラーニングを用いたモデルを構築します。具体的にはLampleらが提案したモデルを構築します。このモデルでは、単語とその単語を構成する文字を入力することで、固有表現の認識を行います。言語固有の特徴を定義する必要性もなく、ディープな固有表現認識のベースラインとしてよく使われているモデルです。
Lampleらのモデルは主に文字用BiLSTM、単語用BiLSTM、およびCRFを用いて構築されています。まず単語を構成する文字をBiLSTMに入力して、文字から単語表現を獲得します。それを単語分散表現と連結して、単語用BiLSTMに入力します。最後にCRFを入れることで、出力ラベル間の依存性を考慮しています。以下のようなイメージです。
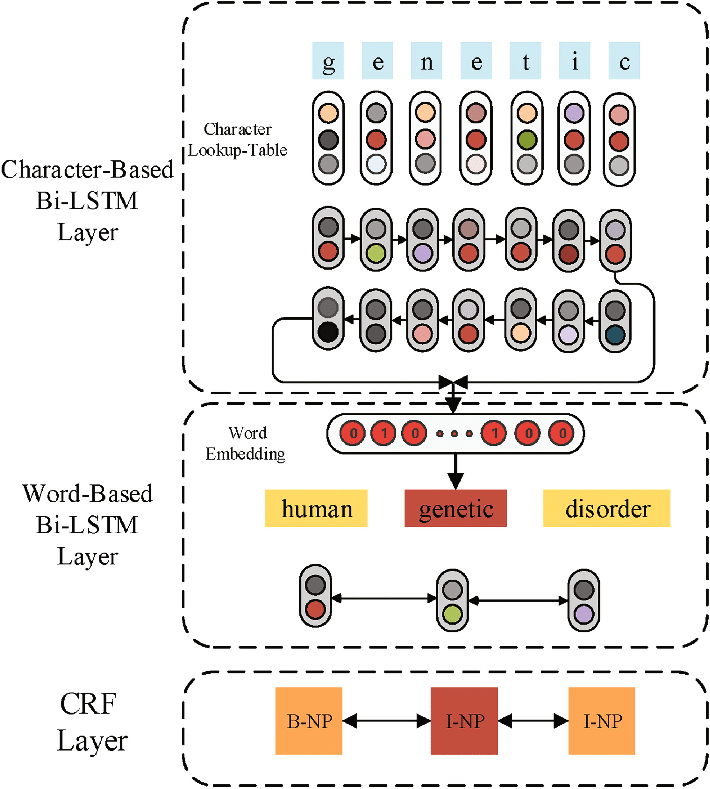 [A Bidirectional LSTM and Conditional Random Fields Approach to Medical Named Entity Recognition](https://www.researchgate.net/figure/The-overall-architecture-of-the-Bi-LSTM-CRF-Model-for-medical-NER-tasks_fig1_319404236)より
[A Bidirectional LSTM and Conditional Random Fields Approach to Medical Named Entity Recognition](https://www.researchgate.net/figure/The-overall-architecture-of-the-Bi-LSTM-CRF-Model-for-medical-NER-tasks_fig1_319404236)より
Lampleらのモデルの実装として、anaGoを使います。anaGoはLampleらのモデルをKerasで実装しており、固有表現認識や品詞タグ付けなどの系列ラベリングと呼ばれるタスクに使うことができます。ちなみに、わたしが実装しました。スターしていただくと、やる気がでますヾ(゚∀゚)ノ
黒塗りの準備
ここでは黒塗りする対象の文書を用意し、anaGoに固有表現を学習させます。最終的には、学習したanaGoを使って固有表現を認識し、文書を黒塗りします。
文書はウィキニュースから用意しました。以下の画像がそのテキストです。最初は森友文書を使っていたのですが、■■の■■が■■■■だったのでやめました。
 [ウィキニュース](https://ja.wikinews.org/wiki/%E3%83%88%E3%83%A9%E3%83%B3%E3%83%97%E5%A4%A7%E7%B5%B1%E9%A0%98%E3%80%81%E5%8C%97%E6%9C%9D%E9%AE%AE%E3%81%AE%E3%83%9F%E3%82%B5%E3%82%A4%E3%83%AB%E7%99%BA%E5%B0%84%E3%82%92%E5%8F%97%E3%81%91%E3%81%A6%E3%80%8C%E5%81%89%E5%A4%A7%E3%81%AA%E5%90%8C%E7%9B%9F%E5%9B%BD%E6%97%A5%E6%9C%AC%E3%82%92100%EF%BC%85%E6%94%AF%E6%8C%81%E3%81%99%E3%82%8B%E3%80%8D%E3%81%A8%E8%A8%98%E8%80%85%E4%BC%9A%E8%A6%8B%E3%81%A7%E6%98%8E%E8%A8%80)より
[ウィキニュース](https://ja.wikinews.org/wiki/%E3%83%88%E3%83%A9%E3%83%B3%E3%83%97%E5%A4%A7%E7%B5%B1%E9%A0%98%E3%80%81%E5%8C%97%E6%9C%9D%E9%AE%AE%E3%81%AE%E3%83%9F%E3%82%B5%E3%82%A4%E3%83%AB%E7%99%BA%E5%B0%84%E3%82%92%E5%8F%97%E3%81%91%E3%81%A6%E3%80%8C%E5%81%89%E5%A4%A7%E3%81%AA%E5%90%8C%E7%9B%9F%E5%9B%BD%E6%97%A5%E6%9C%AC%E3%82%92100%EF%BC%85%E6%94%AF%E6%8C%81%E3%81%99%E3%82%8B%E3%80%8D%E3%81%A8%E8%A8%98%E8%80%85%E4%BC%9A%E8%A6%8B%E3%81%A7%E6%98%8E%E8%A8%80)より
固有表現の学習には、anaGoを使います。認識する固有表現のタイプについてですが、「人名」「組織名」「施設名」「地名」「日付」「職業名」の6つとします。これらのタイプの固有表現を認識して黒塗りすると、良い感じに黒塗りできそうだからです。手元のテストセットで性能評価したところ、F1で92.39ポイントでした。これだけ出れば十分でしょう。
黒塗りの結果
準備が整ったので、黒塗りしてみましょう。黒塗りをするために、まず文書中の固有表現を認識します。そして、認識できた固有表現を使って文書を黒塗りします。まずは固有表現認識器で認識できた表現を確認してみましょう。以下のように表現を認識できました。
$ python tagger_example.py --sent トランプ大統領、北朝鮮のミサイル発射を受けて「偉大な同盟国日本を100%支持する」と記者会見で明言
{'entities': [{'beginOffset': 0,
'endOffset': 1,
'score': 1.0,
'text': 'トランプ',
'type': 'name'},
{'beginOffset': 1,
'endOffset': 2,
'score': 1.0,
'text': '大統領',
'type': 'artifact'},
{'beginOffset': 3,
'endOffset': 4,
'score': 1.0,
'text': '北朝鮮',
'type': 'location'},
{'beginOffset': 15,
'endOffset': 16,
'score': 1.0,
'text': '日本',
'type': 'location'}],
'words': ['トランプ',
'大統領',
'、',
'北朝鮮',
...
「トランプ」や「北朝鮮」といった人名や地名を認識できていることがわかります。バグでスコアがすべて1.0になっていますが、今回は使わないのでこれでいいでしょう。書き換え前の文書を入力することで、以下のような固有表現を認識することができました。認識は1行ずつ行いました。
トランプ,大統領,北朝鮮,日本
北朝鮮,アメリカ,ドナルド・トランプ,大統領,日本,安倍晋三,首相,フロリダ州,安倍,首相,記者,米国,北朝鮮,日本
土曜日,11日,フロリダ州,トランプ,大統領,安倍,首相,北朝鮮,トランプ,大統領
トランプ,大統領,日本,米国,日本
適合率は高めですが、認識漏れが少々あるので再現率が若干低そうです。
続いて認識した表現を元に文書を黒塗りします。画像に自動で塗るのはかなりたいへんなので、今回は該当部分を人手で黒塗りしました。結果は以下のようになりました。

認識漏れがあったために黒塗りできていない箇所がある点と周りのテキストや知識から推定できてしまう箇所があるのが不満点。この手の文書は黒塗りし過ぎる分には問題なさそうなので、適合率を下げて、再現率を上げた方が実践的だと考えられます。
また、今回は6つの固有表現タイプを認識して黒塗りしましたが、ニュースや議事録のような文書では、発言を黒塗りする必要があるので、発言も認識する必要がありそうです。加えて、6つの固有表現タイプに分類するのではなく、黒塗りするかしないかでラベリングしても良かったかもしれません。
おわりに
ビッグデータ活用時代において、データの匿名化は重要な技術です。今までは主に構造化データに対して匿名化が行われてきました。本記事では非構造化データであるテキストに対して固有表現認識を用いて匿名化のようなことをしてみました。本記事が皆様のお役に立てば幸いです。
私のTwitterアカウントでも機械学習や自然言語処理に関する情報をつぶやいています。
@Hironsan
この分野にご興味のある方のフォローをお待ちしています。