今回は知識を使った固有表現認識をやってみよう。
固有表現認識がどのようなタスクなのかというと、テキスト中に出現する人名や地名といった固有名詞を認識するタスクです。固有表現認識は自然言語処理の基礎技術であり、質問応答システム、対話システム、情報抽出といったアプリケーションの要素技術としても使われています。
通常、固有表現認識ではテキスト中の固有名詞を以下の8種類程度に分類します。この8種類の分類はIREXという固有表現認識を含むワークショップで定義されました。公開されているAPIでは、DocomoやGoogleのAPIがこれに近い分類を行っています。
| クラス | 例 |
|---|---|
| ART 固有物名 | ノーベル文学賞、Windows7 |
| LOC 地名 | アメリカ、千葉県 |
| ORG 組織 | 自民党、NHK |
| PSN 人名 | 安倍晋三、メルケル |
| DAT 日付 | 1月29日、2016/01/29 |
| TIM 時間 | 午後三時、10:30 |
| MNY 金額 | 241円、8ドル |
| PNT 割合 | 10%、3割 |
8種類の分類でも良いのですが、実際に固有表現認識を何かのアプリケーションに組み込んで使う際は、8種類では不十分なことがあります。それに対応するために、ドメインに特化した分類を行ったり、より汎用的な分類を行える分類器を構築したりします。
本記事ではテキスト中の固有名詞を150種類程度に分類する分類器を作ります。最近は機械学習を使うことが多いですが、今回は学習させる時間がなかったので、知識を使って150種類の固有表現を認識してみます。
手法の説明
手法の概要
今回は固有表現を認識するために、機械学習ではなく知識を用いて認識します。具体的には、固有表現の辞書を作り、文字レベルでパターンマッチングします。複数パターンにマッチした場合は、最長一致したパターンを採用します。イメージは以下の通りです。

なんだか昔の形態素解析器みたいですね。
では、辞書を作っていきましょう。
固有表現の辞書作り
固有表現の辞書作りには Wikipedia を使います。具体的には、Wikipediaの各ページを150種類の固有表現に分類してやります。この際、複数の固有表現クラスに当てはまる場合は、それらすべてをラベルとして付けてやります。このあたりは以下の論文と同じです。
私は自分でアノテーションしましたが、アノテーション済みのコーパスが売られているので、買うと手っ取り早いのではないかと思います。
分類する基準としては、関根の拡張固有表現階層を基に150種類程度を決めました。関根の拡張固有表現階層では、固有表現を200種類に分類しており、比較的汎用的に使うことができます。
辞書は以下の形式で作成しました。左から「記事名」「大分類」「小分類」「記事URL」です。
日本,location,country,http://ja.wikipedia.org/wiki/日本
ジンバブエ,location,country,http://ja.wikipedia.org/wiki/ジンバブエ
ボツワナ,location,country,http://ja.wikipedia.org/wiki/ボツワナ
ガンビア,location,country,http://ja.wikipedia.org/wiki/ガンビア
ベラルーシ,location,country,http://ja.wikipedia.org/wiki/ベラルーシ
...
今回は、手動でアノテーションした25万記事分を辞書として使うことにします。日本語Wikipediaのページ数は管理用ページを除くと100万程度で、ここから一般名詞を除くと、80万から90万程度と推測されます。したがって、固有名詞を表すページの3割程度にアノテーションしたことになります。
文字列マッチング
辞書の作成が終われば後は辞書中の固有名詞とパターンマッチングを行うだけです。パターンマッチでは辞書の規模が数十万語のため、単純に一単語ずつマッチさせると計算時間がえらいことになります。そこで、Aho-Corasickアルゴリズムを使って効率的にマッチングを行います。以下のPython実装を使いました。
最近、Aho-Corasickアルゴリズムを基にしたアルゴリズムのPython実装が公開されていたので、そちらを使ってもいいかもしれません。使い方が丁寧に解説されています。
認識してみた
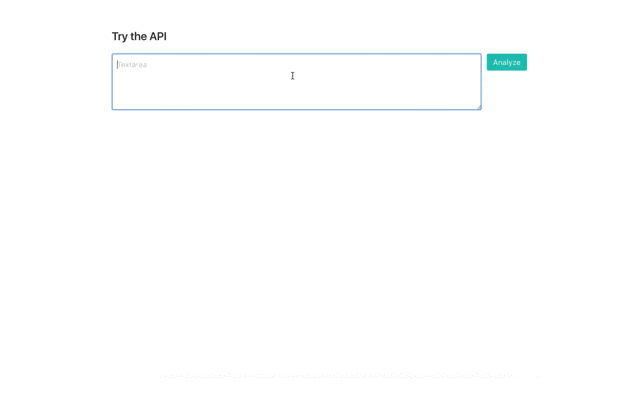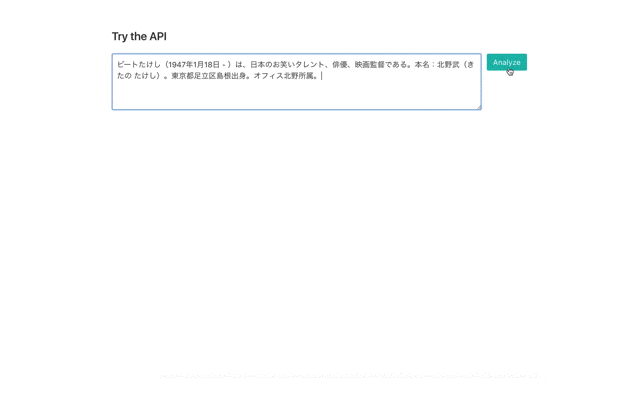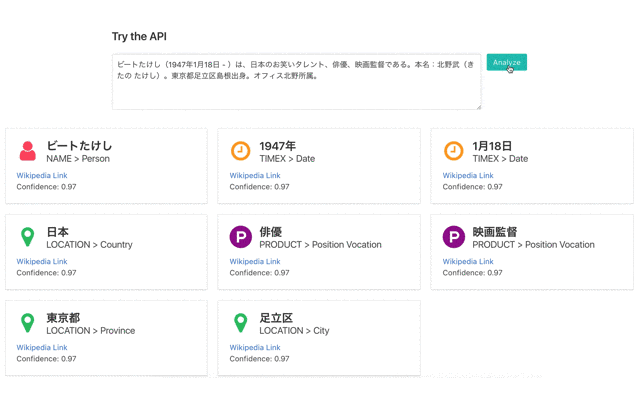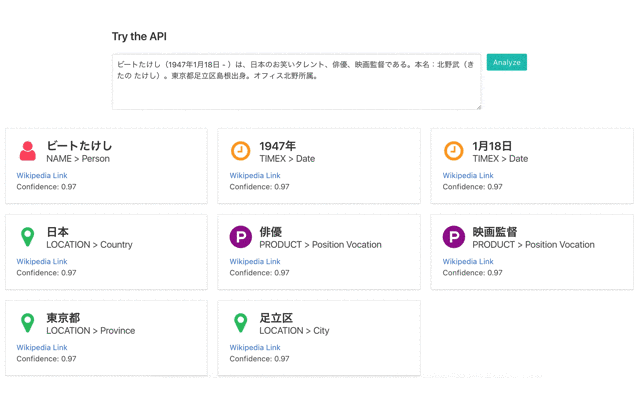
作成した辞書を使ってパターンマッチすることで、固有表現認識を行うことができます。以下のような結果を出力することができました。
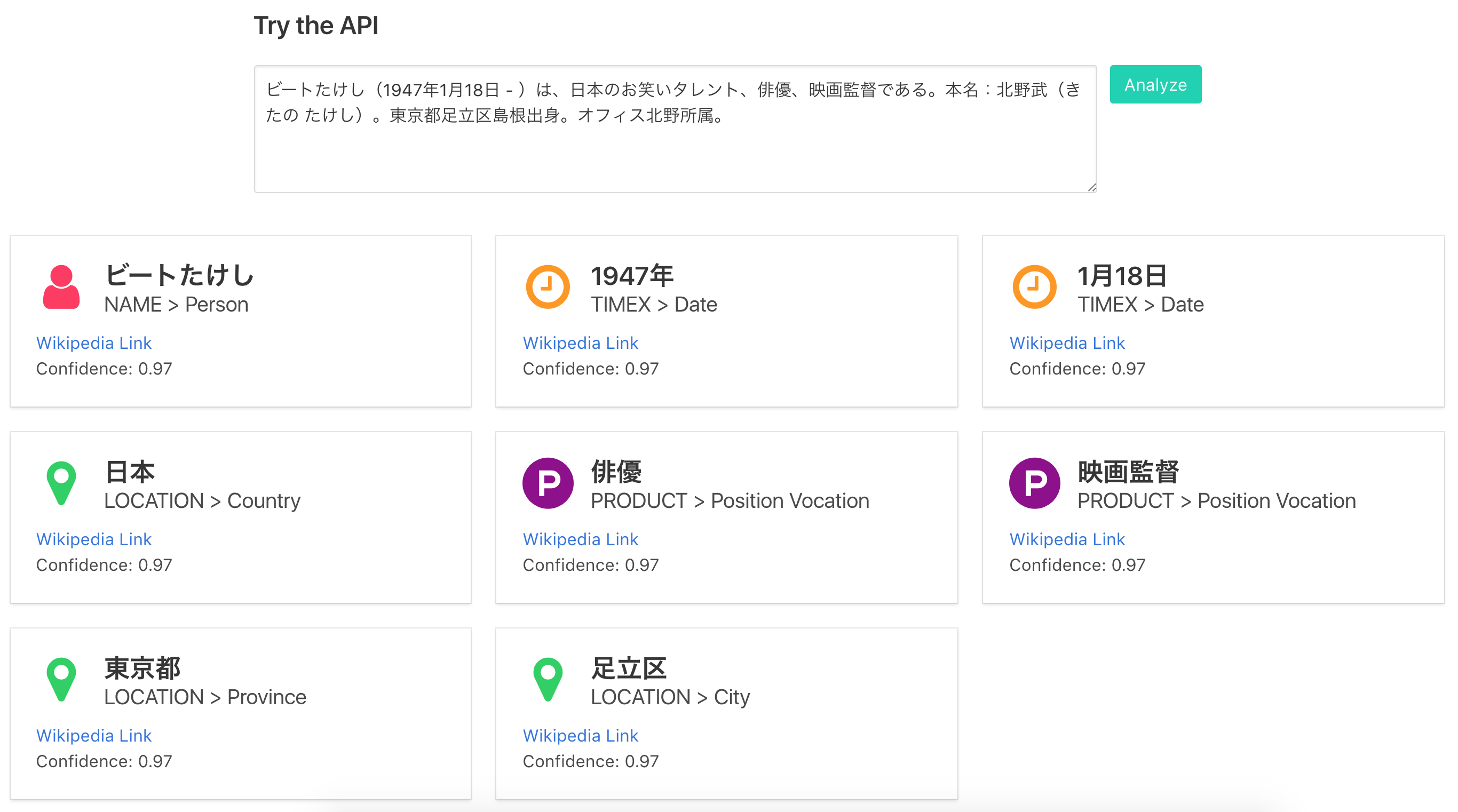
「ビートたけし」を例に認識結果を説明すると、「ビートたけし」は固有表現であり、その大分類は「NAME」、小分類は「Person」であることを示しています。また、「Wikipedia Link」はWikipediaの該当ページへのリンクであり、Confidenceは認識の確信度です。確信度は今回は固定値です。
結果を見ると、「お笑いタレント」「北野武」「島根」「オフィス北野」等が認識できていないことがわかります。このあたりは辞書のカバレッジが問題になってきます。
問題点
この手法には様々な問題点があるのですが、そのうち以下の2つを取り上げてみましょう。
- 辞書のカバレッジ
- 認識誤り
この手法で再現率を上げるには辞書のカバレッジが問題になります。今回は25万語程度を用いましたが、この程度では不十分なので、更に拡張する必要があります。手動で拡張するのは辛いので、少数のアノテーションデータを使って自動的に拡張する手法が提案されています。
また、単純な文字列マッチングで認識しているため、認識誤りが起きやすいです。特に、短い単語に対してはそれが顕著に現れます。たとえば、「〜を明らかにする」という文に対して、辞書中に国名として「明(昔の中国の国)」が登録されていると、誤って認識してしまいます。
以上のような問題点があるため、現在では機械学習ベースの認識が行われています。ただ、機械学習ベースの手法にも、認識しやすい固有表現タイプとしにくいタイプがあります。機械学習と知識を統合して認識することで、認識しにくいタイプも性能良く認識できるのではないかと思います。
おわりに
今回は、固有表現辞書とパターンマッチアルゴリズムを用いて固有表現認識器を作ってみました。タグ付けには拡張固有表現の定義に基づいて150種類の固有表現を付けました。NEologdと統合して認識してみても面白かったかもしれません。本記事が皆様のお役に立てば幸いです。
私のTwitterアカウントでも機械学習や自然言語処理に関する情報をつぶやいています。
@Hironsan
この分野にご興味のある方のフォローをお待ちしています。