
Amazon ECS(以下ECS)とFargateを用いて、今までEC2で運用されていたサービスをコンテナ化してECS上で稼働させるプロジェクトをしました。
特に、Fargateは2018年7月3日にTokyoリージョンで使えるようになったばかりなので、情報がまだまだ少なく手探りの状況でした。
Posted On: Jul 3, 2018
AWS Fargate is now available in Asia Pacific (Tokyo) region.
https://aws.amazon.com/about-aws/whats-new/2018/07/aws-fargate-now-available-in-tokyo-region/
ECS/Fargateで実現したアーキテクチャ・デプロイ方法の全容とその実装方法を記していきます。以下のスライドにもまとめているのでぜひご覧ください。
内定者バイトが1ヶ月ちょいでDSPをAmazonECSに乗っけた話
ECSとは
ECSは、AWSが提供するコンテナオーケストレーションサービスです。
Amazon Elastic Container Service (ECS)は、Dockerコンテナをサポートする拡張性とパフォーマンスに優れたコンテナオーケストレーションサービスです。これにより、コンテナ化されたアプリケーションをAWSで簡単に実行およびスケールできます。
ECSを理解するには、Task(TaskDefinition)/Service/Clusterという3つのレイヤーについての理解が必須なので、続けて解説をします。
Task/TaskDefinition
Taskはコンテナの集合体です。そして、TaskDefinitionはどのようなTaskを生成するか定義しているものです。
TaskDefinitionはdocker-composeのようなものと考えるとわかりやすいと思います。taskDefinitionにどのようなイメージを使ってどのようなコンテナを立てるのか、CPU/メモリの割り当てをどうするか、環境変数・ポートの設定などをしておくと、taskという形で定義されたコンテナの集合体を生成できます。
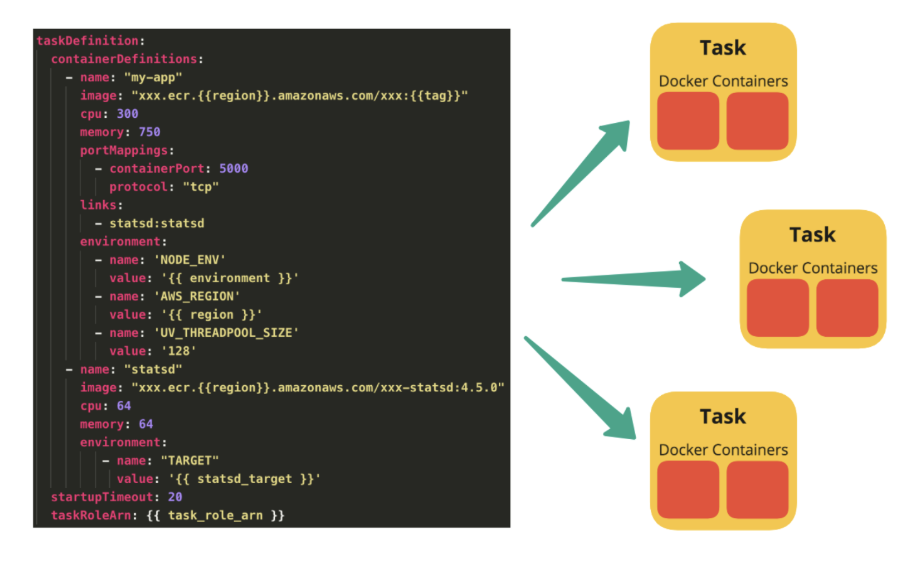
Service
Serviceの役目は、指定したtaskDefinitionからtaskを生成するという作業をいい感じにやることです。taskの希望台数・最大数・最低数、オートスケールのルールを設定することで、CPU/メモリの使用量やタスクのステータスを監視しながら自動でタスクの台数を調節してくれます。
まさに、下の絵のようなイメージです。TaskDefinitionから毎回手動でTaskを生成するわけにもいかないため、Serviceに「このようなルールでTaskを生成して管理してくださいね」と指示してあげることで、コンテナオーケストレーションを実現します。

Cluster
ClusterはTaskとServiceをグルーピングする概念です。アプリケーションごと、環境ごとに用意します。例えばHogeというサービスとFugaというサービスがあり、それぞれにstg環境・prd環境があるならば、clusterはHoge-prd/Hoge-stg/Fuga-prd/Fuga-stgの4つが用意されていると良いです。

Fargateとは
ECSで使うことができる、サーバレスでコンテナが実行できる技術であり、タスク(コンテナの実行単位)に割り当てたvCPUとメモリの量に応じて秒単位での課金でコンテナを実行できます。Fargateを用いればEC2インスタンスの管理が不要になり、オートスケールに柔軟に対応できます。
最初に述べた通り、今まではECSではコンテナ用のインスタンスとしてEC2しか用いることができませんでしたが、2018年7月よりFargateを選択することが可能になりました。このFargateがコンテナオーケストレーションの柔軟性を高くし、インスタンスの管理コストを大きく下げました。
ECSの構築
次に、ECSの構築についてです。全体像とそれぞれの設定方法を記していきます。
アーキテクチャ全体像
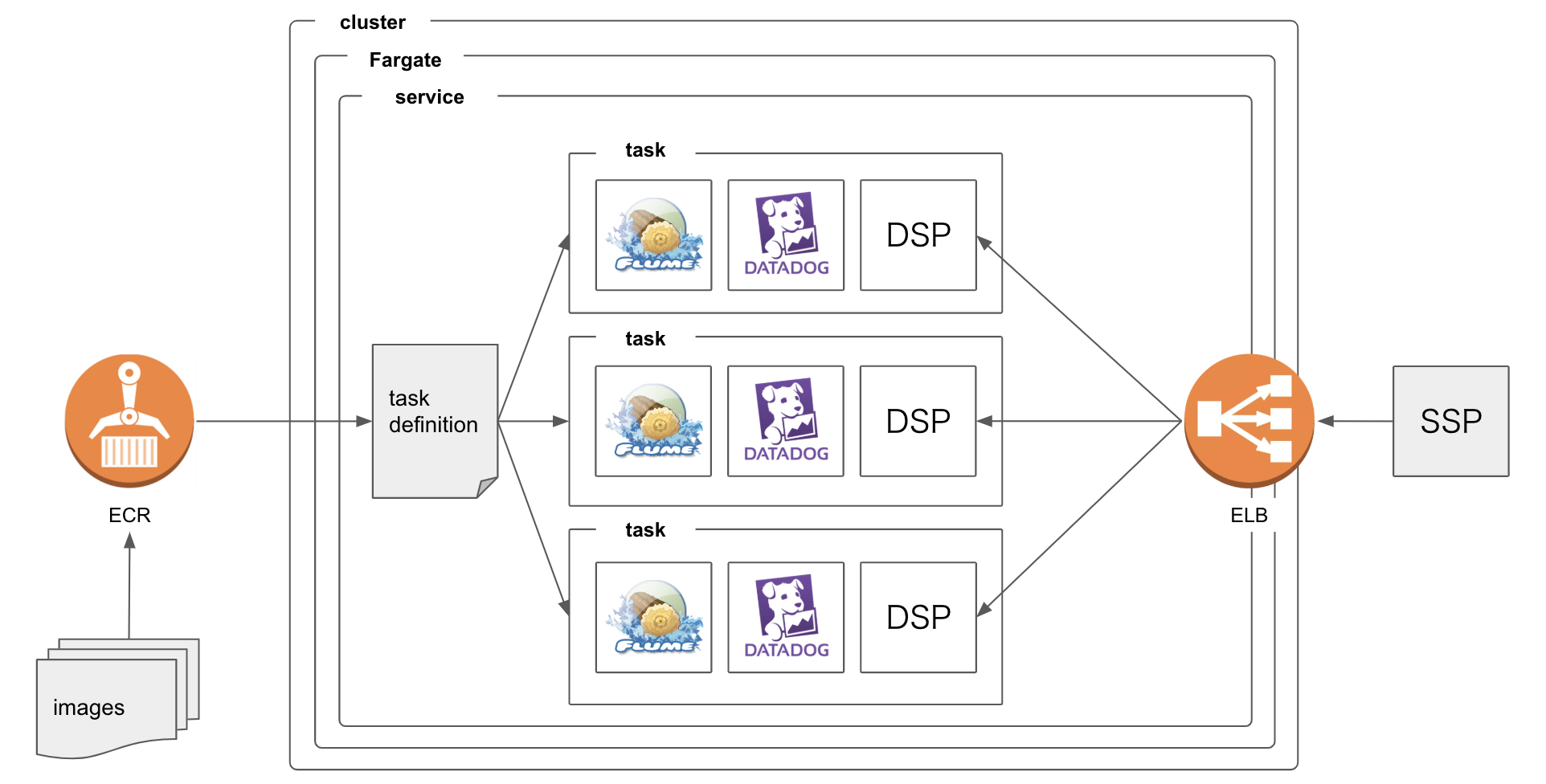
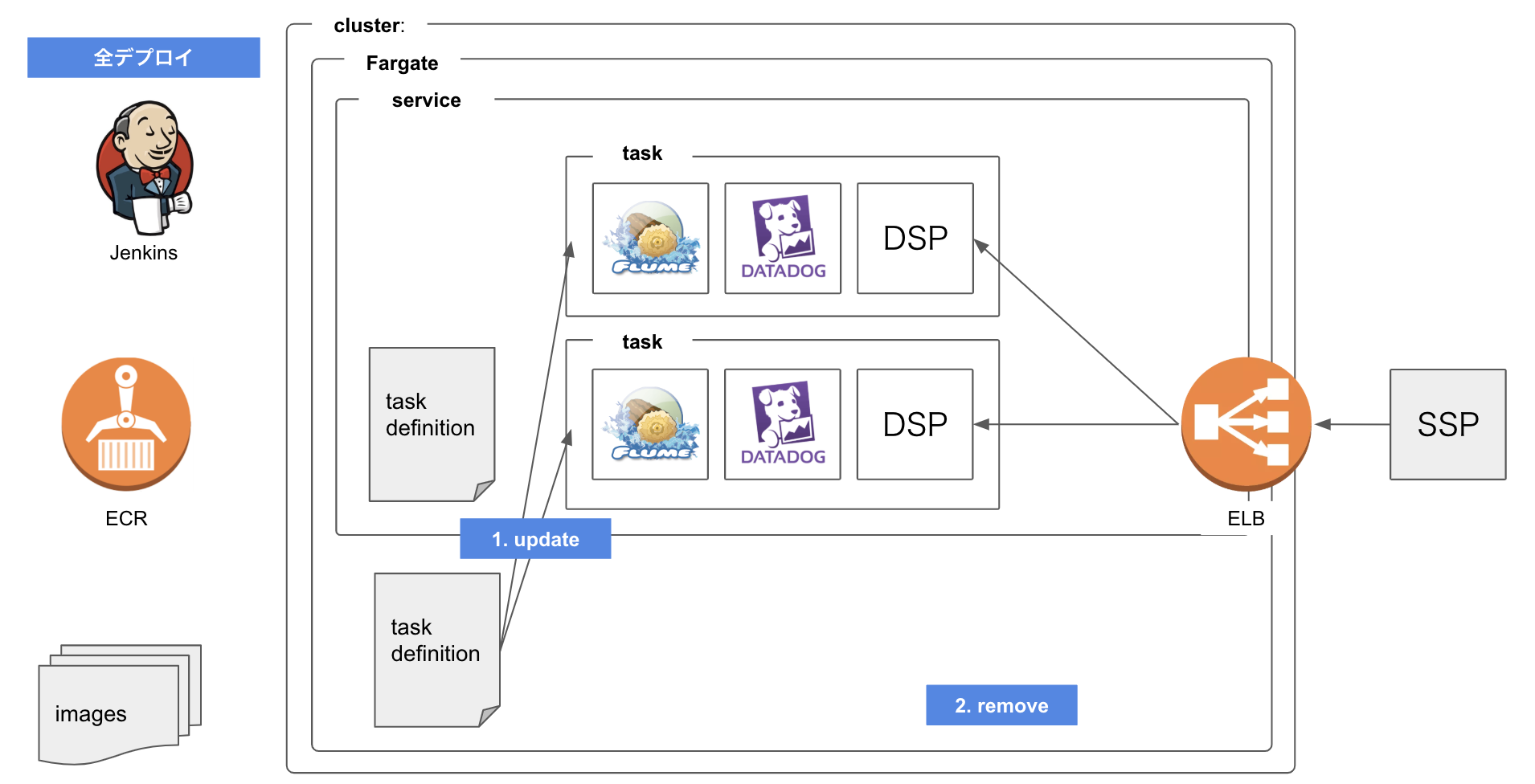
今回はDSPをECS上に構築しましたが、アドテクに詳しくない方はDSPをアプリケーション(例えばRails)、SSPをページをリクエストするユーザーに置き換えると把握しやすいと思います。
DSPはDatadogとFlumeをデータ転送のために周辺サービスとして持って動いているという設定です。もともとEC2では、同一サーバー上に3つのプロセスが動いていましたが、それぞれが独立したコンテナとして作成され、連携して動いています。その集合体がTaskだと思ってください。
Serviceは指定したTaskDefinitionからTaskを生成しています。上の図では3つのTaskをCPU/メモリ使用量などから必要と判断して動かしています。
1. Clusterの構築
SampleAppというアプリケーションのPrd環境を作成したいと思います。まずは、Clusterを作成します。Fargateを指定して、RepositoryNameはsaple_app_prdにします。

2. ECRにDockerImageをpush
次に、ECRにDockerイメージをpushします。以下のコマンドをDockerfileの置かれているディレクトリで順番に実行します。
$(aws ecr get-login --no-include-email --region ap-northeast-1) \
&& docker build -t sample_app . \
&& docker tag sample_app:latest <YOUR ECR URL>/sample_app:latest \
&& docker push <YOUR ECR URL>/sample_app:latest
すると、以下のようにlatestというタグがついたイメージがpushされているのが確認できます。

3. TaskDefinitionの構築
次にTaskDefinitionを構築します。まず、ローンチタイプでFargateを指定します。

次に、TaskDefinitionの名前、Roleの指定、Taskのサイズ(CPU/メモリの割り当て)、コンテナの定義をします。コンテナの定義では、コンテナ名と参照するイメージのURLを指定します。先ほどECRにpushしたので該当のURLをコピーしてきます。
最初の図のような構成にするためには、DSP/Datadog/Flumeそれぞれのイメージをpushした上で、3つのコンテナの定義を作成します。このGUIで設定した項目はJSONとして管理されます。JSONを直接構築してもいいのですが、GUIで項目ごとに指定するのが一番簡単です。

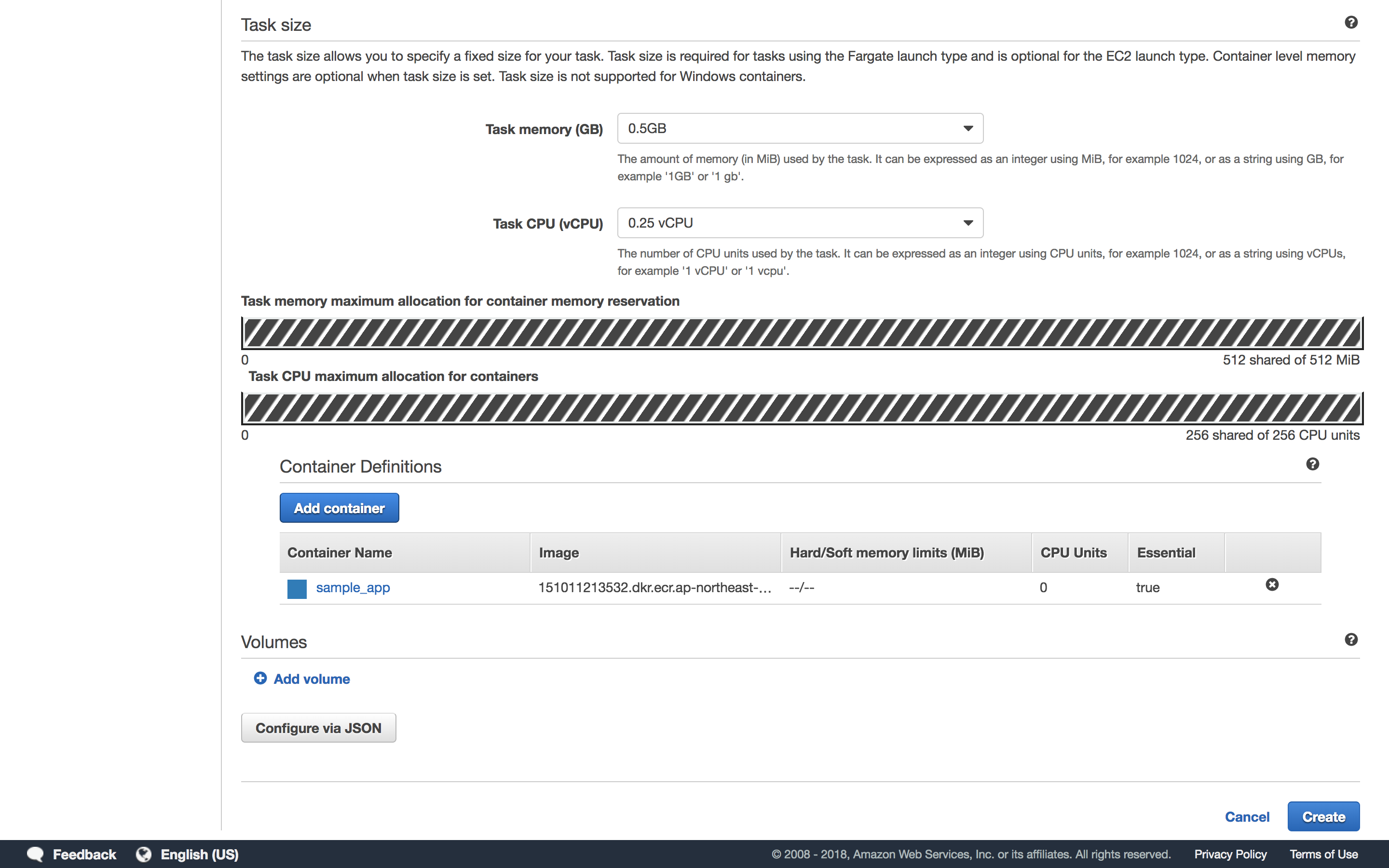
4. Serviceの構築と実行
最後に、serviceを作成します。ローンチタイプでFargeteを指定した上で、先ほど作成したTaskDefinition名とそのリビジョンを指定します。その上で、taskの数や最大数・最低数、ロードバランサの定義、オートスケーリングのルールなどを指定していきます。
指定の内容からわかる通り、serviceがTaskDefinitionを元にtaskを作成・管理します。ロードバランサの管理も行うため、serviceを作成しないことには本番運用ができないとても大切な作業です。

serviceの作成が完了すると、設定したルールに従ってtaskが作成されているのが確認できます。statusがRUNNINGになっていることを確認してください。
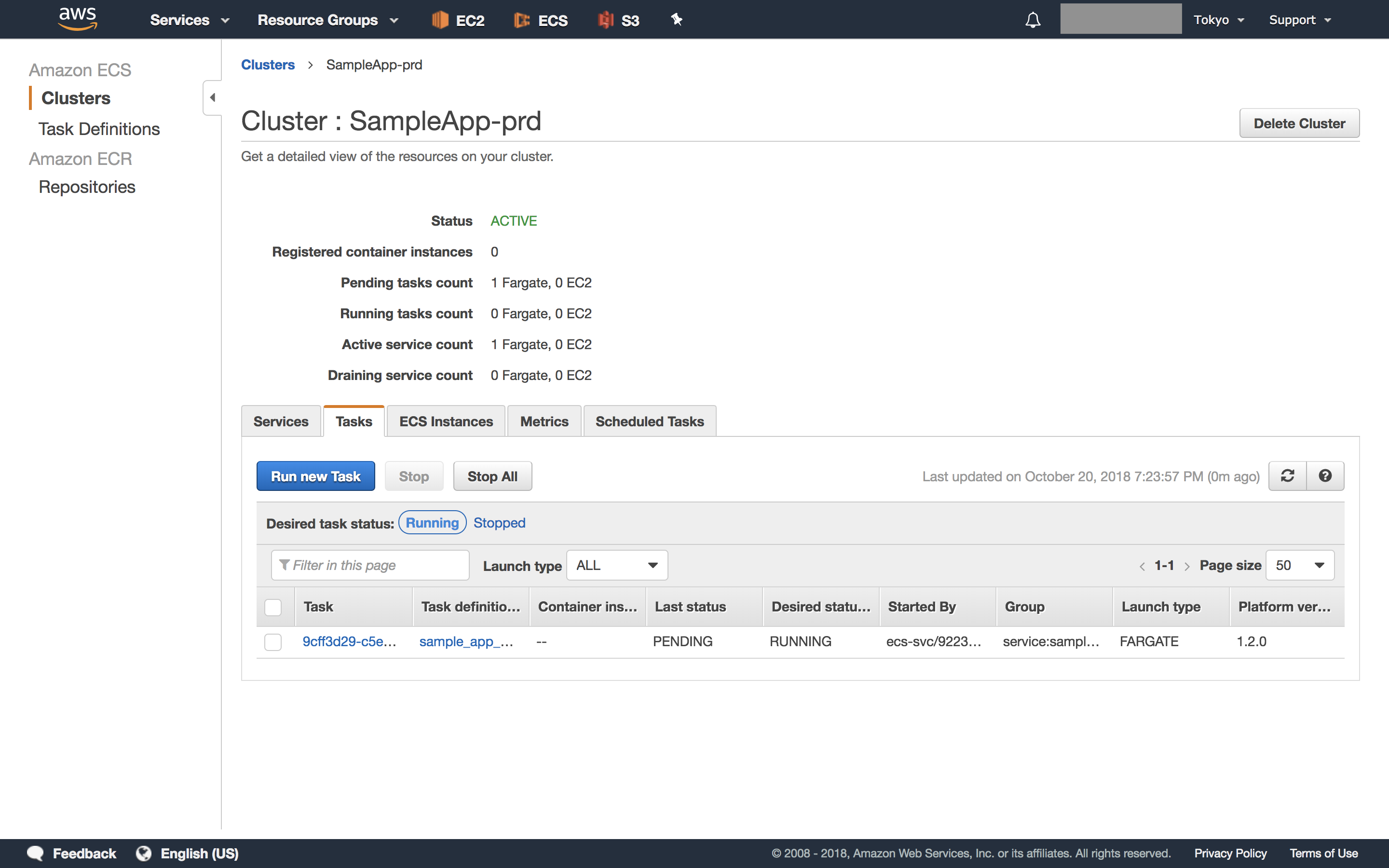
デプロイフローの構築
今までの作業で手動でTaskをデプロイすることが可能になりました。しかし、このままでは今後新しいバージョンのアプリケーションをデプロイしたい場合、イメージをpushしてTaskDefinitionの新しいRevisionを作成して、それを用いるためにServiceをUpdateしてとかなり煩雑な手順を踏む必要があります。
そうならないためにも、デプロイ用のスクリプトを構築してJenkinsを用いて自動でデプロイできるような設計を目指します。
また、今回はさらにカナリアデプロイを実現したため、それも合わせて紹介します。また、デプロイのためのスクリプトでカナリアデプロイを実現しているものがなかったため、自作・公開しています。
カナリアデプロイ:1台だけ最新バージョンのTaskをデプロイする
まずは、カナリアデプロイをします。
- 新しいバージョンのイメージをpushする。この時timestampをタグとして登録する。
- pushしたイメージを参照する新しいリビジョンのTaskDefinitionを作成する。
- 作成したTaskDefinitionを元に1台だけTaskを生成する。
- 生成したTaskのPrivateIPをロードバランサのターゲットグループに追加する。

この手順を踏むことで、複数台の旧バージョンのTaskが動きながらも1台だけ最新のバージョンのTaskが動いている状態になります。上の図であれば、33%配信ができている状態です。実際に一部だけデプロイをしてみることで、障害に対する被害を最小限にすることができます。
スクリプトは以下の通りです。今回デプロイしたTaskを識別するために、STARTED_BYというタグ情報にcanaryと指定しています。後々削除する時に、そのタグがついたTaskを削除すればいいため、処理がシンプルになります。
# ruby path/to/ecs-deploy.rb deploy --canary
def canary_deploy
puts "-----> START canary deploy"
image_name = push_latest_image
task_definition = update_task_definition(image_name)
new_task = run_task(task_definition, CANARY_STARTED_BY_TAG)
task_arn = new_task["tasks"][0]["taskArn"]
puts "-----> task ARN: #{task_arn}"
# take several seconds to get IP
while true
private_ip = get_task_private_ip(task_arn)
if !private_ip.nil?
puts "-----> private IP: #{private_ip}"
break
end
sleep(1)
end
add_task_to_target_group(private_ip)
puts "-----> END canary deploy"
end
カナリアロールバック:先ほどデプロイしたTaskを削除して元の状態に戻す
カナリアデプロイの結果、最新バージョンに問題があることが判明した場合はロールバックを行います。手順は以下の通りです。
- 最新バージョンのTaskを削除
- ロードバランサのターゲットグループから該当TaskのIPを削除
# ruby path/to/ecs-deploy.rb rollback --canary
def canary_rollback
puts "-----> START canary rollback"
task_definition_arn = remove_canary_task
deregister_task_definition(task_definition_arn)
puts "-----> END canary rollback"
end
全デプロイ:カナリアデプロイによって問題がないことが確認できたので100%配信をする
1台だけデプロイしたTaskに問題がない場合は、全Taskが最新のTaskDefinitionを参照している状態にします。手順は以下の通りです。
- 最新のTaskDefinitionを元にSarviceをUpdateする
- 1台だけデプロイしたTaskを削除
# ruby path/to/ecs-deploy.rb deploy
def deploy
puts "-----> START deploy"
task_arn = get_task_arn(CANARY_STARTED_BY_TAG)
task_definition_arn = get_task_definition_arn(task_arn)
update_service(task_definition_arn)
remove_canary_task
puts "-----> END deploy"
end
実装してみた感想
デプロイ・ロールバックがとても楽になった
これはFargateの目的そのままですが、サーバーのリソース管理や起動・停止などをブラックボックス化して裏でうまくやってくれるために、本当に何も考えずにサーバーの起動・台数調整などができます。素直に楽だなと感じました。
Fargateに関する最新情報を取ってくる必要がある
公式ドキュメントの英語版と日本語版の情報量が異なる。下の英語版で書かれているDocker volumes are only supported when using the EC2 launch type.という内容が日本語では書かれていません。私はこここで情報不足状態になり数日詰まったので、情報は英語で取ってくるのがベターだと感じました。

最後に
datadog-agent側にFargateを使うとエラーがでるバグがあったり、デプロイ用のスクリプトがFargate対応が間に合ってなかったりと、まだまだ不便な点も多いです。ただ、とにかく楽になるということと、このように本番環境で使えるようになったよという実例があるので、ぜひどんどん使い倒してもらいたいです。
また、Twitterでは常に技術系・筋トレ系のアウトプットをしているのでぜひフォローしてください!👉 https://twitter.com/hiromu_bdy