はじめに
皆さん,Slackにおいてこのような経験はないでしょうか?
- 記事の共有を行ったがあまり反応がなかった,かといって読みたくなるようなコメントをつけるのも面倒...
- 記事のスクリーンショットやイベントや学会でのスライドの写真を共有したが,画像データのみであとから検索することができなかった...
今回,この2つの問題を解決するSlackアプリを作成しました!!
作成したSlackアプリはGitHubのリポジトリに公開しているので,実際に使用したい方はどうぞ!
実装アプリ
本Slackアプリの機能は以下の2つです.
- URLから記事を要約し,どのようなユーザに適しているかの推薦文を作成

- 画像データからテキストを読み取り,5つのキーワードを抽出
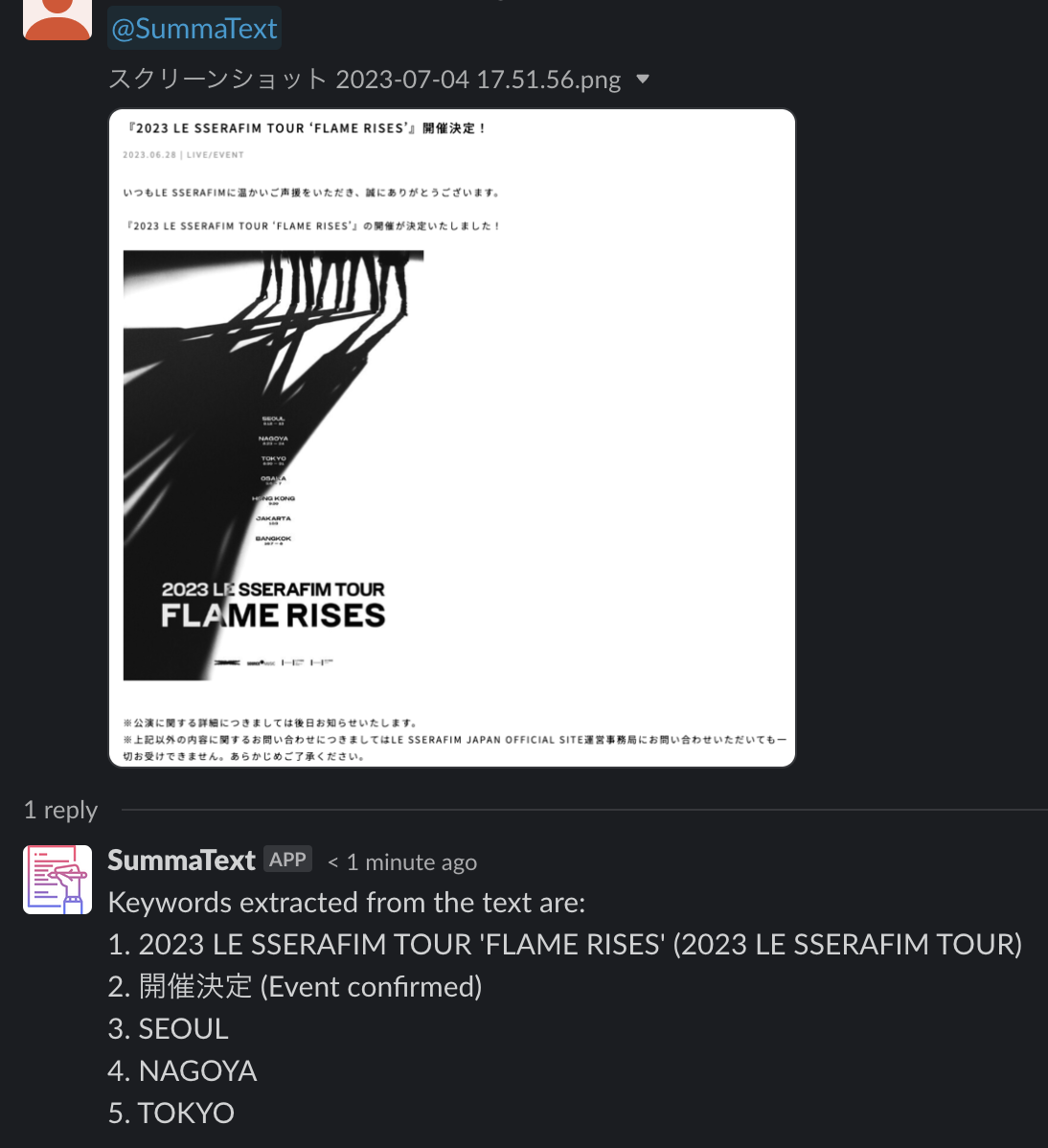
アプリをメンションし,記事のURLや画像データを送信することでこれらの機能を利用することができます.
使用技術
主に,以下の2つの技術を活用してアプリの実装を行いました.
ChatGPT
記事の要約やキーワードの抽出を行います.
以下に実装した関数を示します.
- 記事の要約を行う関数
def summarize_and_recommend_with_gpt3(text):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{
"role": "system",
"content": """
You are a talented writer with a knack for captivating summaries.
Imagine you are crafting a compelling headline to entice readers to dive into the article.
Summarize the content in three sentences, making it engaging and intriguing.
After the summary, also provide a recommendation on who would find this article most beneficial.
Write in Japanese.
""",
# あなたは魅力的な要約を書く才能のあるライターだ。
# 読者をその記事に飛び込ませるために、説得力のある見出しを考えているところを想像してみてください。
# 内容を3つのセンテンスで要約し、魅力的で興味をそそるものにする。
# 要約の後には、この記事が最も有益だと思う人についての推薦文も添えましょう。
# 日本語で書く。
},
{
"role": "user",
"content": f"Summarize this and recommend who would benefit: {text}",
},
],
max_tokens=1024,
)
return response.choices[0].message["content"]
- 画像から読み取られた文字列からキーワードを抽出する関数
# GPT-3.5を使用してOCRから読み取られた文字列からキーワードを抽出する関数
def extract_keywords_with_gpt3(text):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": """
You are a highly intelligent model capable of understanding and interpreting text, even when it contains inaccuracies due to OCR errors.
Your task is to identify and extract the five most relevant and specific keywords from the following text,
while intelligently completing any missing or erroneous characters.
These keywords should be the ones that most accurately depict the text.
The keywords should be in their original language, without any translation.
""",
# あなたは、OCRエラーによって不正確なテキストが含まれていても、それを理解し解釈することができる高度に知的なモデルです。
# あなたの仕事は、次のテキストから最も関連性の高い具体的な5つのキーワードを特定し、抽出することです、
# 同時に、欠落した文字や誤った文字をインテリジェントに補完することです。
# これらのキーワードは、テキストを最も正確に描写するものでなければなりません。
# キーワードは翻訳せずに原語のままにしてください。
},
{"role": "user", "content": f"Here is the text: {text}"},
],
max_tokens=200,
)
return response.choices[0].message["content"]
OCR(Optical Character Reader)
OCRは、Optical Character Reader(またはRecognition)の略で、画像データのテキスト部分を認識し、文字データに変換する光学文字認識機能のことを言います。具体的にいうと、紙文書をスキャナーで読み込み、書かれている文字を認識してデジタル化する技術です。RICOH
今回はSlackに投稿された画像データから文字列の抽出を行うために使用しました.
アプリ全体像
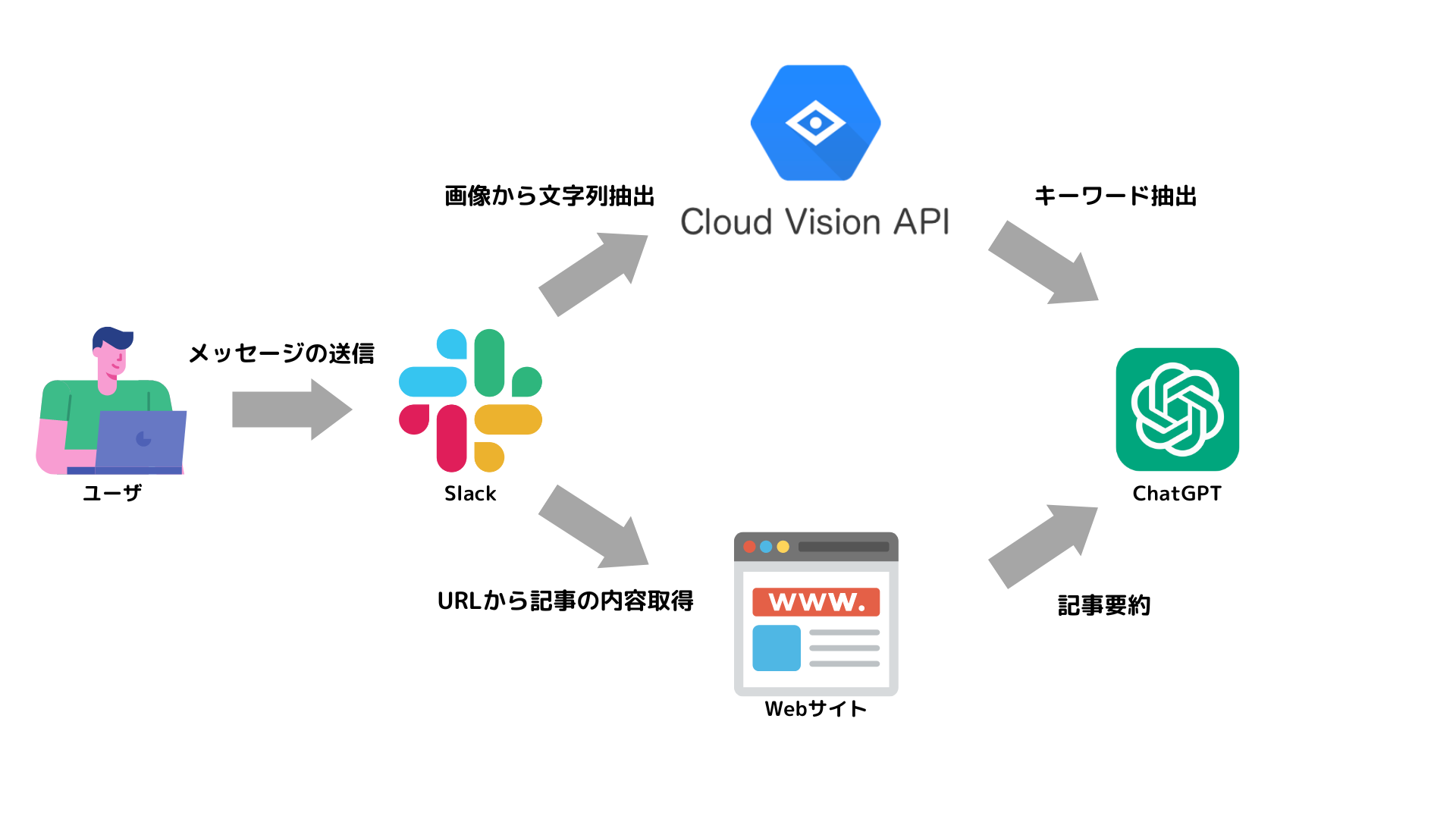
今回実装したアプリの全体像は以下の図のようになっています.
ユーザーがSlackでアプリにメッセージを送信すると,アプリはそのメッセージが画像データかURLを含んでいるかを判定します.
画像データならばCloud Vision APIに,URLならば記事の内容を取得し,それぞれChatGPTに適切なクエリを送信して結果をSlackに送信します.
おわりに
今回,簡単にですが,Slack上でURLから記事の要約や画像からキーワードの抽出を行うアプリの紹介を行いました.
こだわりポイントや実装の苦労など多く書きたかったのですが,プログラムからプロンプト,アプリ名に至るまで,ChatGPT4.0様の恩恵に預かっているため,さほど書くことがございませんでした...
この記事のタイトルも考えてもらいました笑
作成したアプリケーションを公開ではなく,レポジトリの共有とさせていただいたのはChatGPT APIの料金がかかるのを恐れたためです.
そのため,本アプリケーションをご利用の際はご自身のChatGPTのAPIキーを用いて,用法用量を守ってご利用いただければと思います.
また,具体的なアプリの実行方法に関しては本記事に記載していないため,README.mdを参照いただけますと幸いです.
利用に際し,問題が生じた場合はコメントいただけますとできる限り対応したいと思います!