あ、どーも。東京理科大学大学院修士過程2年の秋田と言います。春から所属が変わる予定ですが、まあよろしくお願い致します__|\○_
完全に個人的な趣味ですが、どうしても Stable Diffusion を理解したくてこの記事を順に上げていく運びとなりました。
そもそも Stable Diffusion とは
2022年頃から出てきた超スーパーハイパーウルトラめちゃくちゃ優秀な画像生成AI君です。
どういうふうに使うかというと、基本的には生成したい画像のキャプションとなる文章を打ち込むことで、それに準ずる画像がしゅぽっと出てくるって感じですね。
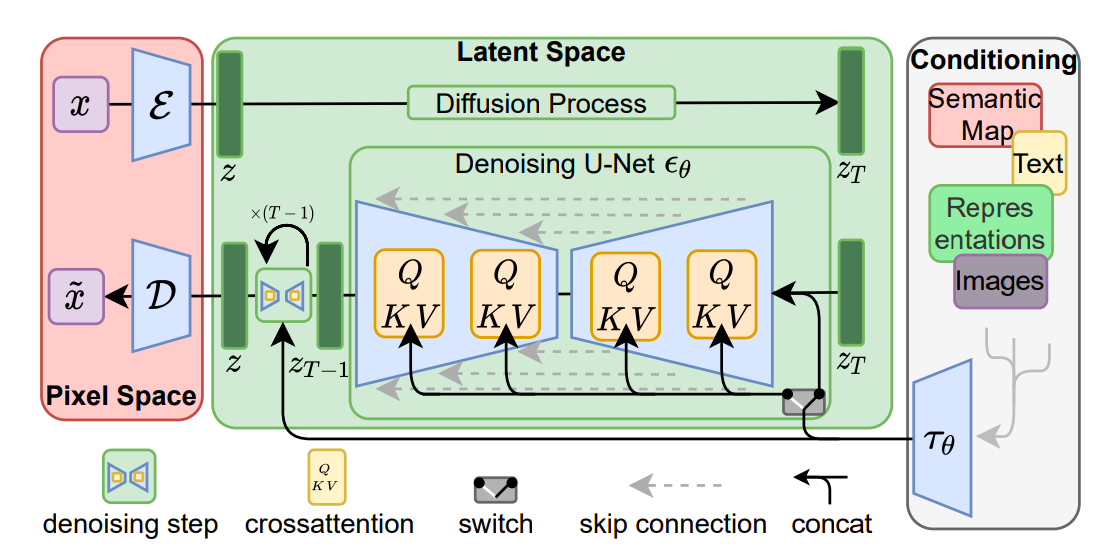
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models, arXiv:2112.10752 [cs.CV].
裏で何が行われているのか
ここからは少し難しい話をしましょう。
深層学習
さて、 Stable Diffusion を話す上で避けて通れないものとして、深層学習(Deep Learning)というものがあります。
ニューラルネットワーク(NN)という人間の神経構造(ニューロン)を模倣したネットワークを形成することで、ヒューリスティックな手法ながら多くの分野で採択されており、またその多くで従来の機械学習モデルより高性能であるとの報告が後を絶たないですね。
この NN は Python のライブラリで PyTorch や TensorFlow などでサポートされており、誰でも気軽に構築することができます(ん?)。
今回は、筆者自身が PyTorch 大好きマンなのでこちらを使って考えていきたいと思います(とは言っても全然使いこなせないのですが)。
拡散モデル(Diffusion Model)
拡散モデルは、 NN ベースの生成系のモデルになります。
元を辿ると2015年の Jascha Sohl-Dickstein と愉快な仲間たちが出した "Deep Unsupervised Learning using Nonequilibrium Thermodynamics" で提唱されたものだそうです。
出発点は非平衡熱力学の分野だったんですね!
どんなものかというのをざっくり説明すると、
- まず完璧な状態のデータを用意する
- T ステップに分けて徐々にノイズを加えていく
- T ステップ後から逆順にノイズを除去するように学習させ、生成する空間を見つける
といった流れです。

NVIDIA Developer. Improving Diffusion Models as an Alternative To GANs, Part 1.
Transformer
これは自然言語処理の分野から出てきて、文字通り世界を変えた革新的なモデルですね。
2017年、 Google 社のチームが発表した "Attention Is All You Need" という論文で提唱されたもので、これが出る前と出た後では自然言語処理の分野の発展が著しいのはもちろん、画像処理や時系列解析といった他分野でも活躍するという話も上がっています。
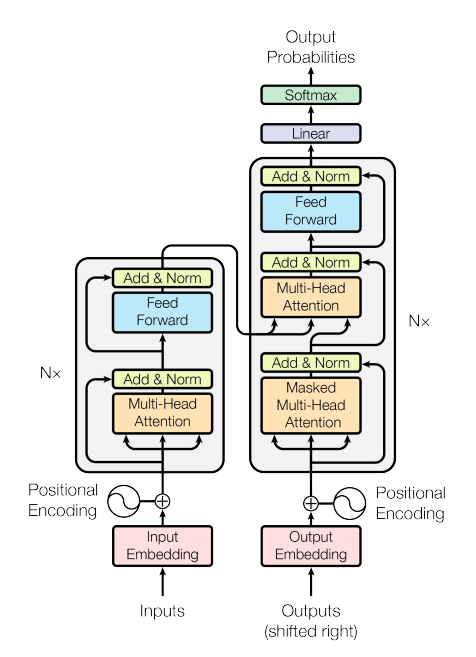
自己注意機構(Self-Attention Mechanism)と呼ばれる入力データの各々にその他の部分との関係を計算することでデータを文脈単位で機械が理解するということを可能にしています。これが Transformer の中核となる要素です!
また、位置エンコーディング(Positional Encoding)なるもので、各データのシークエンスの順序情報を理解します。
マルチヘッド自己注意(Multi-Head Self-Attention)によって複数の視点から文脈を理解し、偏った考え方をしなくなります。
位置単位順伝播ネットワーク(Position-Wise Feedforward Network)で、各データの表現を更新します。
そして、エンコーダ(Encoder)で入力の情報を処理し、デコーダ(Decoder)で出力の形に持っていくということをします。
これらの構成要素を持って学習させることで、今までにない革命的なモデルが誕生しました!
Stable Diffusion ではテキストから画像を生成するため、この Transformer の技術も取り入れています。
何がしたいん?
ここからの目標は、 Stable Diffusion のモデルのアーキテクチャを一つひとつ理解して、紛い物オリジナルモデルを作りたいなと思っています!
そのためにはまず、よく使われているモデルのアーキテクチャを調べなければいけないんですよね。で、どうするか。
Hugging Face のドキュメントにある Stability AI が公式で出している Stable Diffusion のモデルがあるので、こいつのアーキテクチャを覗いてみましょう!
UNet2DConditionModel(
(conv_in): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_proj): Timesteps()
(time_embedding): TimestepEmbedding(
(linear_1): LoRACompatibleLinear(in_features=320, out_features=1280, bias=True)
(act): SiLU()
(linear_2): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
)
(down_blocks): ModuleList(
(0): CrossAttnDownBlock2D(
(attentions): ModuleList(
(0-1): 2 x Transformer2DModel(
(norm): GroupNorm(32, 320, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_k): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_v): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=320, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=320, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=320, out_features=2560, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
)
)
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 320, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)
(norm2): GroupNorm(32, 320, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(1): CrossAttnDownBlock2D(
(attentions): ModuleList(
(0-1): 2 x Transformer2DModel(
(norm): GroupNorm(32, 640, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((640,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_k): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_v): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((640,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=640, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=640, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((640,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=640, out_features=5120, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=2560, out_features=640, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 320, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(320, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)
(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(320, 640, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 640, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)
(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(2): CrossAttnDownBlock2D(
(attentions): ModuleList(
(0-1): 2 x Transformer2DModel(
(norm): GroupNorm(32, 1280, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_k): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_v): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=1280, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=1280, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=1280, out_features=10240, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=5120, out_features=1280, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 640, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(640, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(640, 1280, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(3): DownBlock2D(
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
)
(up_blocks): ModuleList(
(0): UpBlock2D(
(resnets): ModuleList(
(0-2): 3 x ResnetBlock2D(
(norm1): GroupNorm(32, 2560, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(2560, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(2560, 1280, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(1): CrossAttnUpBlock2D(
(attentions): ModuleList(
(0-2): 3 x Transformer2DModel(
(norm): GroupNorm(32, 1280, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_k): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_v): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=1280, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=1280, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=1280, out_features=10240, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=5120, out_features=1280, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
)
)
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 2560, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(2560, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(2560, 1280, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 1920, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(1920, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(1920, 1280, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(2): CrossAttnUpBlock2D(
(attentions): ModuleList(
(0-2): 3 x Transformer2DModel(
(norm): GroupNorm(32, 640, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((640,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_k): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_v): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((640,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=640, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=640, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((640,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=640, out_features=5120, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=2560, out_features=640, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 1920, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(1920, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)
(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(1920, 640, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(1280, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)
(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(1280, 640, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 960, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(960, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)
(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(960, 640, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(3): CrossAttnUpBlock2D(
(attentions): ModuleList(
(0-2): 3 x Transformer2DModel(
(norm): GroupNorm(32, 320, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_k): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_v): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=320, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=320, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=320, out_features=2560, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 960, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(960, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)
(norm2): GroupNorm(32, 320, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(960, 320, kernel_size=(1, 1), stride=(1, 1))
)
(1-2): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 640, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(640, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)
(norm2): GroupNorm(32, 320, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): LoRACompatibleConv(640, 320, kernel_size=(1, 1), stride=(1, 1))
)
)
)
)
(mid_block): UNetMidBlock2DCrossAttn(
(attentions): ModuleList(
(0): Transformer2DModel(
(norm): GroupNorm(32, 1280, eps=1e-06, affine=True)
(proj_in): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_k): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_v): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(attn2): Attention(
(to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)
(to_k): LoRACompatibleLinear(in_features=1024, out_features=1280, bias=False)
(to_v): LoRACompatibleLinear(in_features=1024, out_features=1280, bias=False)
(to_out): ModuleList(
(0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GEGLU(
(proj): LoRACompatibleLinear(in_features=1280, out_features=10240, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): LoRACompatibleLinear(in_features=5120, out_features=1280, bias=True)
)
)
)
)
(proj_out): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
)
)
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)
(conv1): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)
(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
(conv_norm_out): GroupNorm(32, 320, eps=1e-05, affine=True)
(conv_act): SiLU()
(conv_out): Conv2d(320, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
長い。
次回
秋田 死す
デュエルスタンバイ!