Python入門編 その2
今回扱うプログラムはこちらにあるので、是非ダウンロードしてみてください!
中身はここにあるものと一緒です。
イントロダクション
こんにちは、東京理科大学所属の秋田と申します!
前回は、Pythonに関する基本的な文法事項をメインに紹介しました。
今回はPythonのライブラリを使ってもっと便利なことをやってみましょう!
Section 3. 「NumPyライブラリ」
キーワード :
- import
- エイリアス
NumPy(公式ドキュメント)は、Pythonでの計算処理を高速化するためのライブラリです。
Pythonは「インタプリタ言語」と言って、プログラムを1行ずつ機械が理解できる言語に変換し、実行するので処理が遅くなってしまいます。
インタプリタ言語と対になるのが「コンパイル言語」で、これはプログラム全体を機械が理解できる言語に変換した後、実行します。
コンパイル言語の代表例としては、
- C言語
- COBOL
などがあり、このNumPyはC言語で実装されているので数値計算をする上で効率化を図れます。
まずはライブラリのインポートの仕方から見てみましょう。
import numpy
pipi = numpy.pi
print(pipi)
このように 'import' と書き、その後に使用したいライブラリの名前を入れることでことでインポートができます。
また、よく使われるライブラリに関しては、別名(エイリアス)が一般的に定まっており、例えば
- numpy $→$ np
- matplotlib.pyplot $→$ plt
- seaborn $→$ sns
- pandas $→$ pd
などがあります。
これらは次のようにして扱えるようになります。
import numpy as np
pipi = np.pi
print(pipi)
エイリアスを使うことで、コードをより綺麗にし、冗長な表現を避けることができます。
続いて、上の二つのコードにある、 '.' 以降のものについて見てみましょう。
これは、NumPy上に存在するモジュール・クラス・関数などを表しており、それらのインスタンスを作る際にこのように書きます。
また、これらはimportの形でより簡単に書くこともできます。
from numpy import pi
pipi = pi
print(pipi)
NumPyでは、独自の多次元配列を扱います。
Pythonのデフォルトでは前回やったもので、リスト型という配列がありました。
NumPyの提供するndarray型により、行列の計算を高速に行うことができます。
py_list = [0, 1, 2, 3, 4]
print(f'Type list:\t\t {py_list}')
np_ndarray = np.array(py_list)
print(f'Type ndarray:\t {np_ndarray}')
出力結果に ',' が出てこなくなりましたね。
他にも色々やってみましょう。
# 配列の次元を変える 'reshape()' メソッド
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
print(arr) # 1次元配列を...
arr_reshaped = arr.reshape(3, 3)
print('\n ↓ ↓ ↓ \n')
print(arr_reshaped) # 3×3の2次元配列に変える
arr_re_reshaped = arr_reshaped.reshape(9)
print('\n ↓ ↓ ↓ \n')
print(arr_re_reshaped) # 1次元配列に戻す
# 転置の 'T' メソッド
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
arr_reshaped = arr.reshape(2, 5)
print(arr_reshaped) # 元の行列(ベクトル)を...
arr_T = arr_reshaped.T
print('\n ↓ ↓ ↓ \n')
print(arr_T) # 転置する
# 行列の積やベクトルの内積を計算する 'dot()' メソッド
matrix = np.array(
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
)
matrix_T = matrix.T
multi_1 = np.dot(matrix, matrix_T) # matrix × matrix_T
multi_2 = np.dot(matrix_T, matrix) # matrix_T × matrix
print(f'multiple 1:\n{multi_1}')
print(f'\nmultiple 2:\n{multi_2}')
その他様々な機能が揃っているので、興味があれば調べてみましょう!
Section 4. 「Matplotlibライブラリ」
キーワード :
- グラフの描画
- データ分析
Matplotlib(公式ドキュメント)はグラフを描画するためのライブラリです。
折れ線グラフや円グラフをはじめ、ヒストグラムや散布図なども表示・保存できます。
データ分析をする際に非常に重要になります。
Matplotlibでグラフを作る大まかな流れとしては
- X軸になるデータを用意
- Y軸になるデータを用意
- '
plot()' 関数でプロット - '
show()' 関数で表示
です。
import matplotlib.pyplot as plt # Matplotlib では基本的に .pyplot までを一緒にインポートする
x = [i for i in range(1, 31)]
y = [
16.0, 14.1, 12.8, 14.0, 16.1, 18.8,
18.5, 14.6, 11.8, 14.6, 18.2, 19.2,
16.1, 18.2, 14.3, 16.2, 15.1, 13.6,
18.0, 20.4, 21.6, 14.9, 14.2, 13.2,
14.1, 15.6, 17.2, 18.7, 19.4, 19.7
]
plt.plot(x, y)
plt.show()
表示ができましたね。
これは2023年4月の東京の日ごとの平均気温のデータです(ソース)。
しかし、これだけではデザインがあまり良くない上に、後々見返したときに何がなんだかわかりません。
ここに、もうちょっと工夫をしましょう。
# タイトルの付与
plt.title('Ave Temp, April. 2023, Tokyo', size=15, color='red')
# 軸のラベルの付与
plt.xlabel('Day')
plt.ylabel('Temparature')
# 各軸の範囲を指定
plt.xlim(1, 30)
plt.ylim(11.5, 22.0)
# グリッドを描画
plt.grid()
plt.plot(x, y)
plt.show()
先ほどに比べてだいぶ見やすくなったのではないでしょうか。
次は、気温に加えて湿度もプロットしてみましょう。
# 画像のサイズを指定
plt.figure(figsize=(18, 12))
plt.title('Ave Temp and Hum, April. 2023, Tokyo', size=15, color='red')
plt.xlabel('Day')
plt.xlim(1, 30)
y_hum = [
63, 67, 57, 54, 58, 67, 85, 70, 43, 47,
57, 66, 47, 59, 91, 89, 46, 61, 69, 72,
66, 45, 38, 38, 56, 87, 52, 64, 66, 90
]
plt.grid()
# 2種類のグラフをプロット
plt.plot(x, y, label='Temparature')
plt.plot(x, y_hum, label='Humidity')
# 2つのグラフの凡例を付与
plt.legend(bbox_to_anchor=(1.01, 1), loc='upper left', borderaxespad=0.)
plt.show()
グラフを分けて表示するには 'subplot()' メソッドを使います。
plt.figure(figsize=(16, 12), tight_layout=True)
# 1つ目
plt.subplot(211) # 引数は LMN の各1桁の整数、順に「縦の分割数」, 「横の分割数」, 「左上からの順番」
plt.title('Ave Temp, April. 2023, Tokyo', size=15, color='red')
plt.xlim(1, 30)
plt.ylim(11.5, 22.0)
plt.plot(x, y, label='Temparature')
plt.xlabel('Day')
plt.ylabel('Temparature')
plt.grid()
plt.legend(bbox_to_anchor=(1.01, 1), loc='upper left', borderaxespad=0.)
# 2つ目
plt.subplot(212)
plt.title('Ave Hum, April. 2023, Tokyo', size=15, color='green')
plt.xlim(1, 30)
plt.ylim(35, 93)
plt.plot(x, y_hum, label='Humidity', color='orange')
plt.xlabel('Day')
plt.ylabel('Humidity')
plt.grid()
plt.legend(bbox_to_anchor=(1.01, 1), loc='upper left', borderaxespad=0.)
plt.show()
だいぶ複雑なものになってきましたね。
今回は折れ線グラフを扱いましたが、他にも色々できるので挑戦してみてください。
Exercises
Exercise 4.
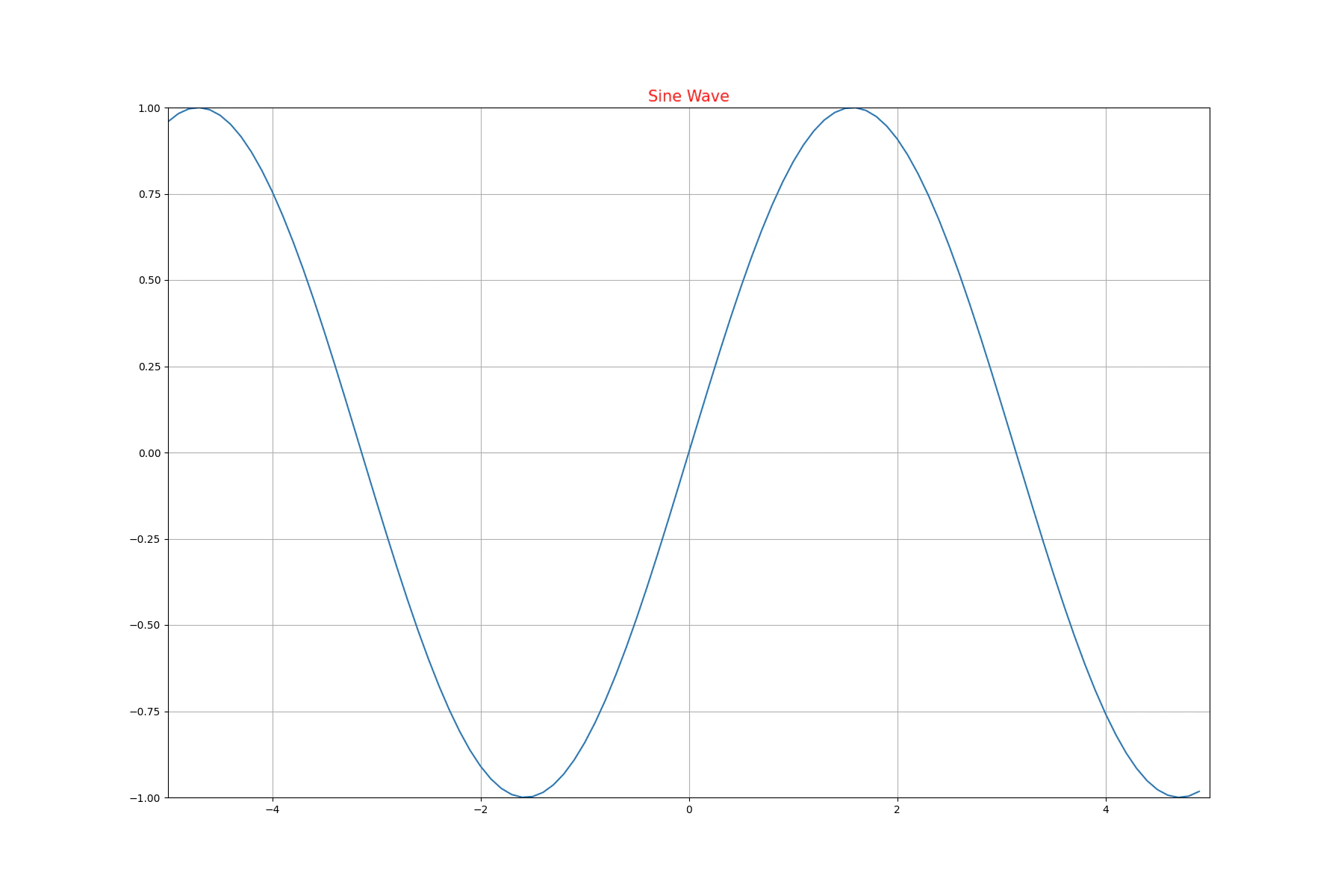
NumPyとMatplotlibを使って、正弦波(sin波)のグラフを書いてみましょう。
X軸の範囲を [-5, 5] とします(プロット間隔は指定しません)。
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(18, 12))
#コードを書いてください↓↓↓
#コードを書いてください↑↑↑
plt.show()
ヒント1.
NumPyの
.arange()メソッドは、第1, 2引数に入れた範囲内に第3引数の間隔があいた配列を作る
ヒント2.
NumPyの
.sin()メソッドは、引数の正弦の値を返す
Exercise 5.
$x, y\space(∈ [-1, 1])$ の平面上に、点を10000個乱数生成し、 $x^2 + y^2 ≤ 1$ を満たす点を赤色で、それ以外を青色でプロットし、次のような図を作成してみましょう。
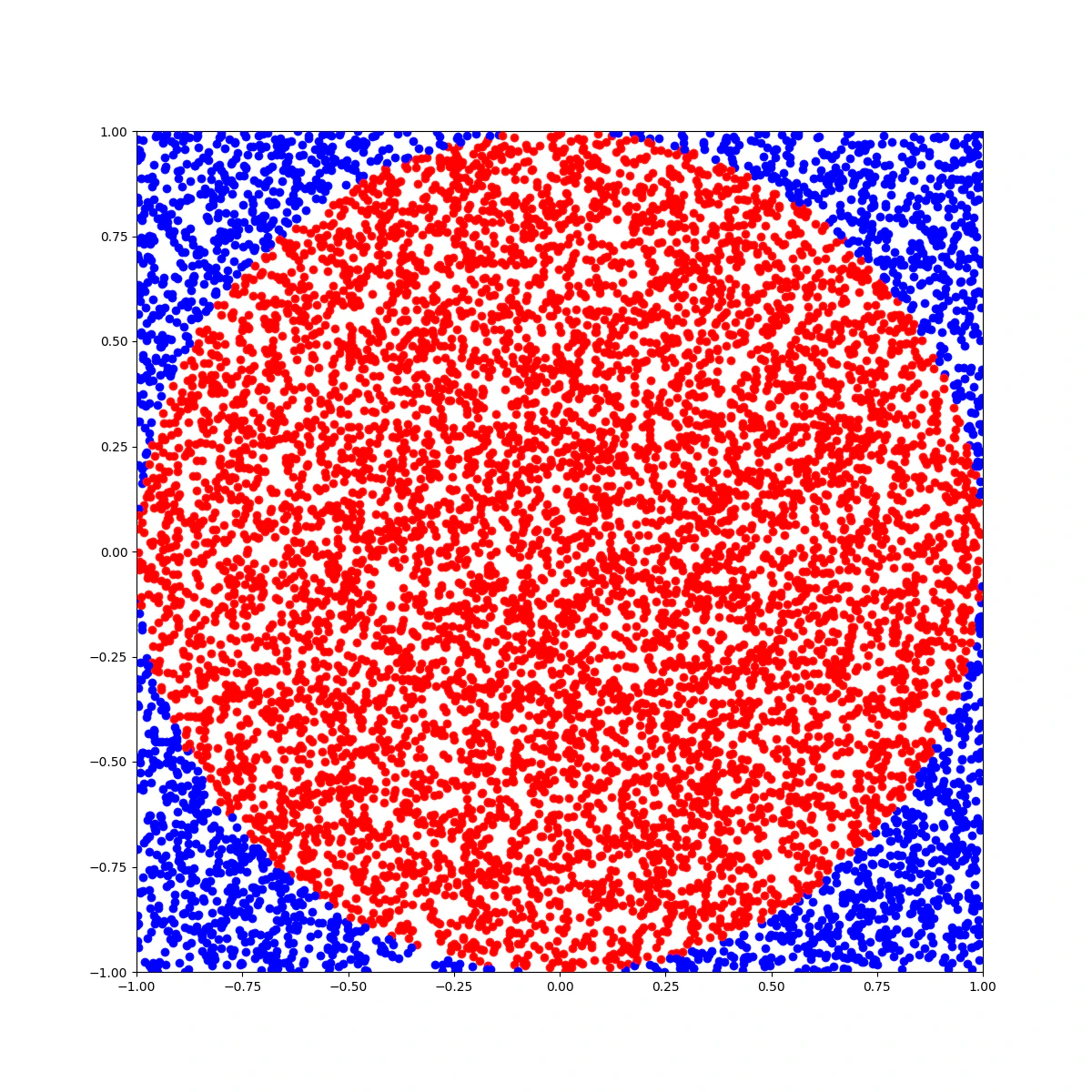
また、赤色の点をカウントして、 $2500\space(= 10000 ÷ 4)$ で割ってみましょう。
#コードを書いてください↓↓↓
#コードを書いてください↑↑↑
ヒント1.
乱数生成はrandomモジュールを使うとやりやすい
ヒント2.
点のプロットはMatplotlibの
.scatter()メソッドを使うと良い
Exercise 6.
Excelファイルをダウンロードして読み込んで、次のようなjsonファイルとして保存しましょう。
{
"時計じかけの摩天楼": {
"公開日": "1997/04/19",
"主題歌": "杏子 - Happy Birthday",
"上映時間": "95分",
"興行収入": "11億円",
"キャッチコピー": "真実はいつもひとつ!"
},
"14番目の標的": {
"公開日": "1998/04/18",
"主題歌": "ZARD - 少女の頃に戻ったみたいに",
"上映時間": "99分",
"興行収入": "18億5000万円",
"キャッチコピー": "次に狙われるのはだれだ!?"
},
"世紀末の魔術師": {
"公開日": "1999/04/17",
"主題歌": "B'z - ONE",
"上映時間": "100分",
"興行収入": "26億円",
"キャッチコピー": "世紀末最大の謎を解くのは誰だ!?"
}
}
上記はデータの一部であるため、全てのデータでまとめてください。
形式としては、
{
「タイトル」: {
"公開日": "XXXX/XX/XX",
"主題歌": "◯◯○◯ - Hoge Hoge",
"上映時間": "M分",
"興行収入": "〜円",
"キャッチコピー": "ホニャララ"
},
「タイトル」: {
"公開日": "XXXX/XX/XX",
"主題歌": "◯◯○◯ - Hoge Hoge",
"上映時間": "M分",
"興行収入": "〜円",
"キャッチコピー": "ホニャララ"
},...
}
というように構造化し、インデントを4にしてください。
#コードを書いてください↓↓↓
#コードを書いてください↑↑↑
ヒント1.
Excelデータの読み込みはpandasライブラリが使いやすい
ヒント2.
jsonファイルにするには辞書型(dict型)としてデータを扱う
終わりに
お疲れ様でした!
今回はここまでとなります。
次回は、Pythonで最適化問題を解けるように一緒に学んでいきましょう!