前回まではUltra96のPS部分(ARMプロセッサ)を使った推論を実行するまでの手順を紹介しました。いよいよ、ハードウェア推論回路を実装してみましょう。
…といきたいところなのですが、最近のFPGAは複雑になりすぎて(しかも今回はGoogle ColabとかPyTorchとか、機械学習までやらないといけないんです。。)初心者の参入敷居が高くなっていますので、まずは何をしないといけないのか解説して、次回から設計に取り掛かりましょう。
ハードウェアを使う意義
パレートの法則(2:8の法則ともいいます)によると、全体の大部分はごくわずかな部分が影響しているのですが、計算もほぼその法則が当てはまると言われています。つまり、今回の推論処理の大部分はわずかな部分、具体的に言えば畳み込み(Convolution)演算が9割以上を占めている、という事実です。
そこで、その部分だけを専用ハードウェアで処理することを目標にします。下図をイメージしてください。

もちろん、全てハードウェア化してもいいんですけど、たった1割未満のものを高速化するのに、10倍以上と言われている(今回の連載の回数がそれを端的に表していますね)ハードウェア設計に時間をかけるのはコストが悪いです。コンテストの締め切りもありますし。限られた設計時間で最大の性能を引き出すために、ハード・ソフト協調システムを採用することが多くなってきました。そこで、多くのFPGAもARMプロセッサを搭載、またはPCI接続しているんですよね。
もう少し上の図を眺めていると、ハードソフト協調実行するには、
- ホストPSがDDRメモリを読み出す
- PLにデータを転送する
- PLがデータを処理する
- PSにデータを戻す
という手順で処理が行われます。PSとPLで処理を分担するにはデータ通信という避けて通れない問題があって、多くのAIエッジコンピュータはこの問題を解決するために工夫されています。データ通信をなんとかしないと、ハードウェアを使う意義がないとも言えます。大変なんです。。
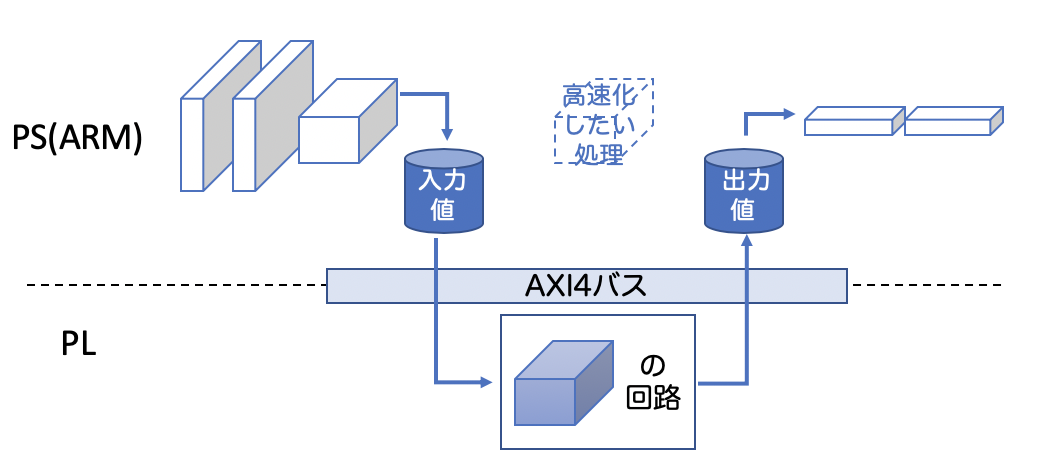
Ultra96での処理(主にデータ転送)
Ultra96での処理を上図に詳しく書いてみました。2:8の法則に従って重たい処理(=高速化したい処理)を見つけます。大抵の場合はプロファイル解析を行います。そして、PSとPLで行う処理を決めます。
そうすると、上図のように、ソフト(PS)側とハード(PL)側でやりとりするデータ(入力値、出力値)をそれを跨ぐ境界というデータの流れが出来上がります。今回コンテストで使うFPGAにはARMプロセッサで使われているAXIバスが搭載されており、PSとPLはAXIバスのプロトコルを使ってデータをやりとりします。Xilinx社のFPGAは3つのAXIバス通信プロトコルを使うことができます。
- AXI4 Lite
- AXI4 Streaming
- AXI4 Scatter Gather (今回は説明しません)

まずはAXI4 Liteプロトコルです。Liteというので、処理を記述するのは単純です。ただし非常に遅いです。。上図に示すように、たった一つのデータを送るために、PSがDRAMにデータを取りに行って(そのためにDRAMにコマンド発行して、それを待って、数サイクルかけて読み出して、途中でデータリフレッシュとか入って、バンクを切り替えて、、、)、それからAXIプロトコルの準備(これもコマンド発行とか待ちとか基準があってややこしい)をして、ようやくデータを送ります。データ読み出しも同様です。。
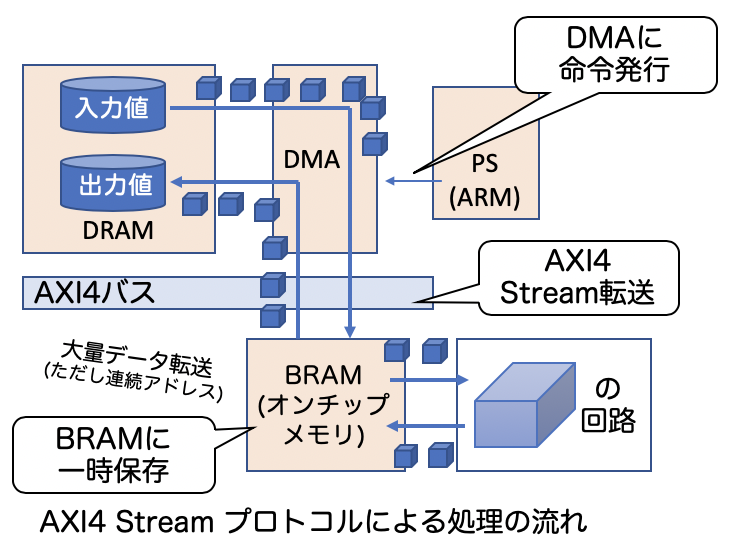
そこで、AXI4 Streamingプロトコルを使います。上図をみてください。AXI4 Streamingとは名前の通り、連続データ転送を行うプロトコルで、PSがDMAに転送発行すれば連続でデータがPLに送られます。通常はFPGAのオンチップメモリ(BRAM: Block RAM)に転送しておき、PL上に設計したハードウェアで処理を行い、再度ホストPSのDRAMに転送する仕組みです。連続アドレスへのアクセスであれば、性能を十分に発揮できます(連続アドレスでない場合はScatter Gatherもありますが、今回は触れません)。
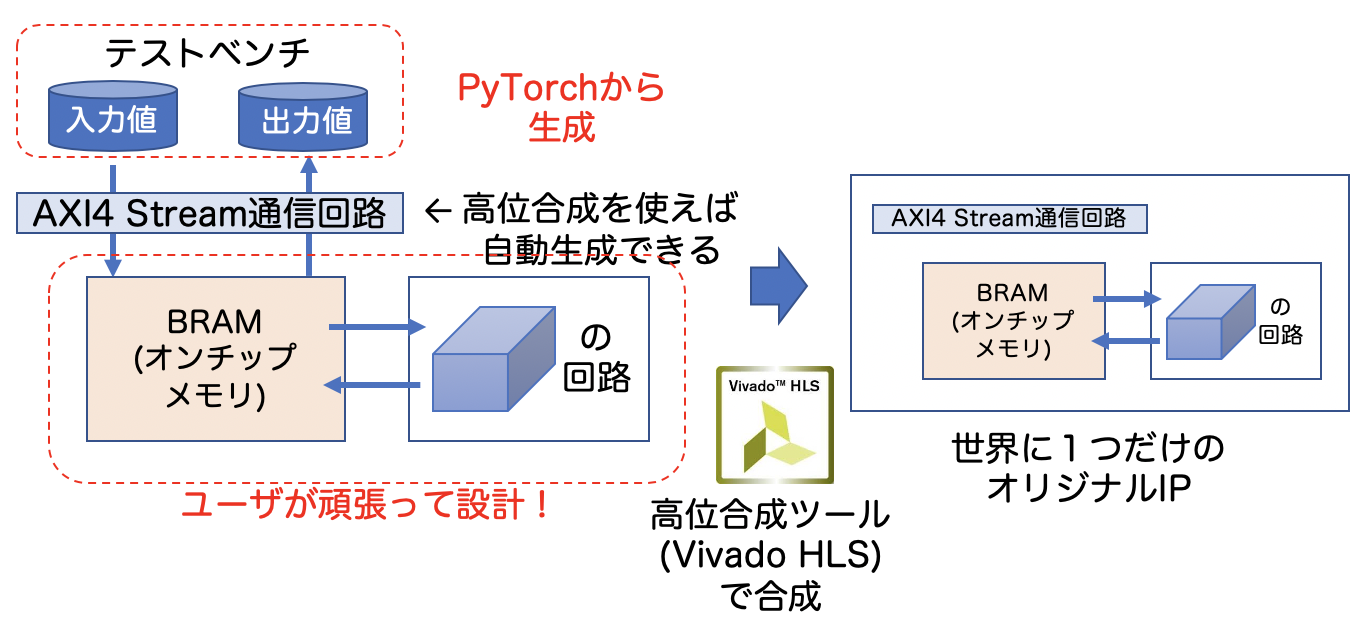
設計フロー
以上を踏まえて、今回解説する設計フローを上図に書きました。Xilinx社の高位合成ツールであるVivado HLSを使用して世界に1つだけのオリジナルIPコアを合成します。そのコアにはホストPSから転送されてきたデータをストアするオンチップメモリ、処理を行う回路、及び、AXI4 Streaming通信回路が必要ですが、Vivado HLSを使うことで自動生成できてしまします!高位合成を使うメリットの一つですね。
また、設計したIPコアが正しく動作するか検証するためのデータ(テストベンチと言います)、はGoogle Colabで学習したモデルから生成して使いましょう。

オリジナルIPを作った後、PS(ARMコア、DMA, DRAMなど)を含めてハードウェア全体を統合し、合成します。Xilinx社のVivadoというツール(Vivado HLSではありません!)を使います。その後、PYNQをインストールしたソフトウェアシステム上にオリジナルIPの制御を含めた処理前半をPythonで記述します。ここ直近のDeep Learningフレームワークはほぼ全てPythonベースなので、そのままシームレスに統合できるので、とても便利になりました。もちろん、PYNQはUbuntu18.04 LTSに組み込まれているフレームワークなので、Ubuntuの資産をそのまま使うことも可能です。例えば、apt-getで様々なソフトウェアを組み込むことも可能であり、scikit-learnとかOpenCVも簡単にインストールできます。
次回は
ハードウェア設計といいましたが、その事前準備である検証用のテストベンチを生成しましょう。PyTorchを直接ハックして内部のデータにアクセスします。テストベンチだけで1回分ですから、ハードウェア設計ってやっぱり手間と時間がかかるんですよねぇ。。。