ようやくハードウェアを合成する準備が整いました。FPGAで実現する回路を合成して実機動作の準備をしましょう。
FPGAとビットストリーム
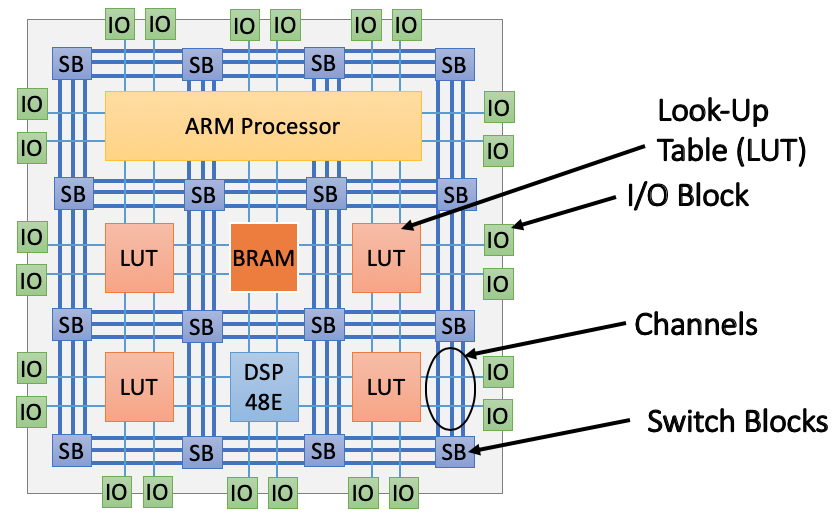
今回の実装ターゲットはZynq FPGAといい、ARMプロセッサが内蔵された特殊なFPGAです。FPGAの構成要素は上の図をみてください。基本素子であるLUT、BRAM,DSPブロック、そして柔軟な配線を実現するためのChannel,Switch Block, IO Blockで構成されています。
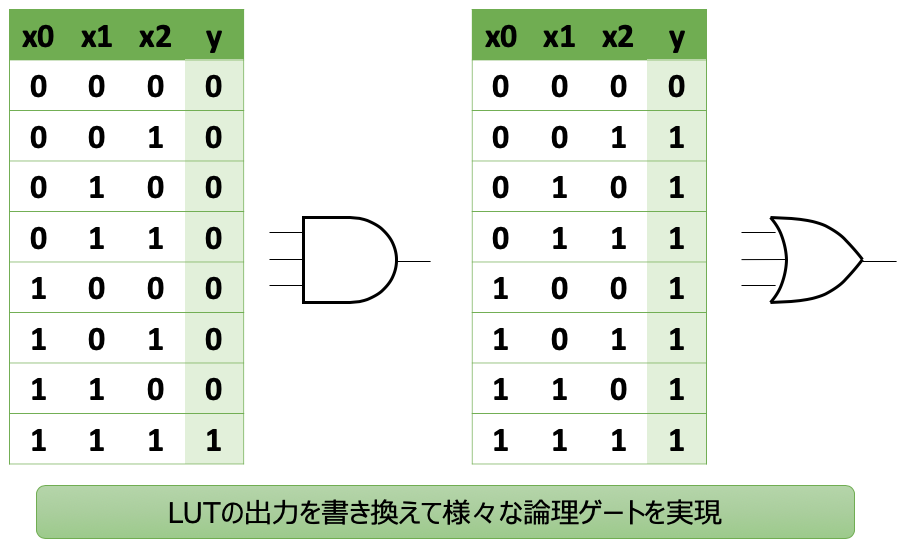
その中身ですが、LUTの出力値、すなわち小規模メモリの内容を書き換えることで任意の論理回路を実現できます。
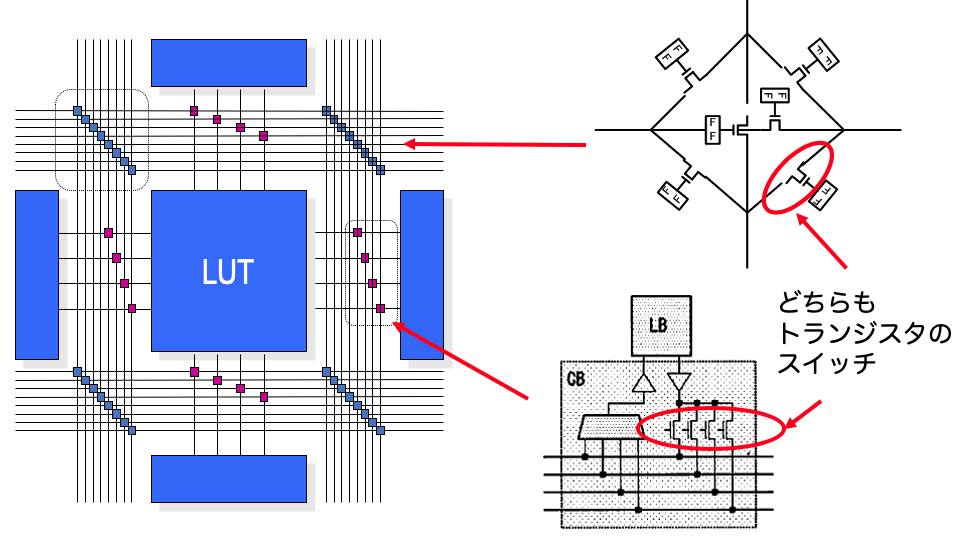
配線は交差する部分とLUTブロックなどの接続にトランジスタスイッチを使って実現しており、スイッチのON/OFFを1ビットの情報に入れておきて書き換えできるようにします。つまり、FPGAの構成要素は大小のメモリでできているため、その情報をストリームに流し込むビットの列=ビットストリームでユーザの回路情報を保持しているんですね。
FPGAの回路合成=ビットストリーム生成です。それでは、Vivadoツールを使ってHLSで合成した回路をビットストリームに合成しましょう。
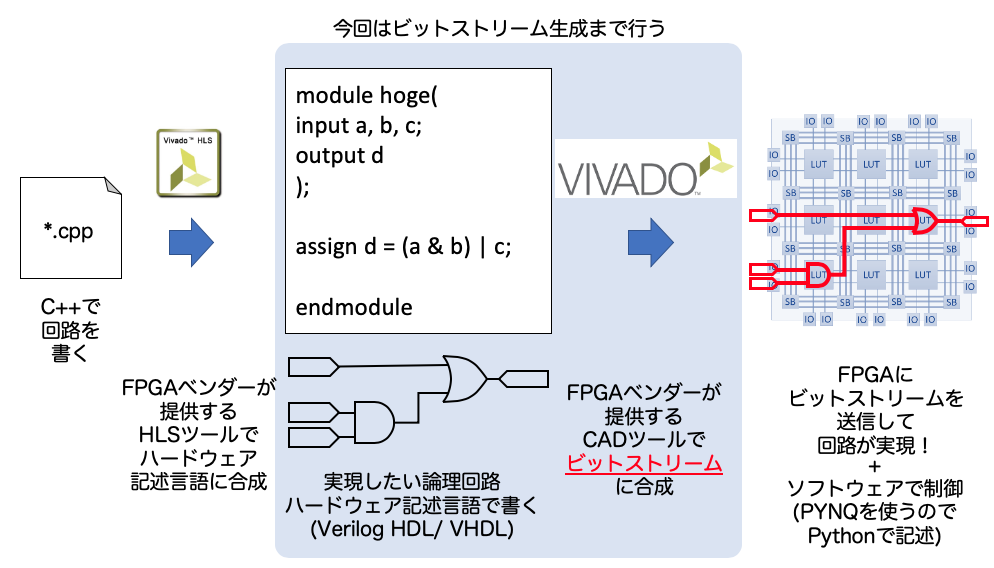
Vivadoを使ったビットストリームの生成、、の前に
Vivadoで合成する前に、もう一度流れを確認しましょう。実現したい回路(今回は畳み込み演算)のC++記述をHLSツールで合成して論理回路を合成します。論理回路はゲートレベルの記述になっており、通常はハードウェア記述言語(Verilog HDL/VHDL)で記述します。これを入力としてビットストリームに変換するツールが今から使うVivadoというツールです。
Vivadoを起動する前にVivado HLSを再度起動して、前回までのプロジェクトを開いてください。まず、HLSで合成したHDLファイルをインポートします。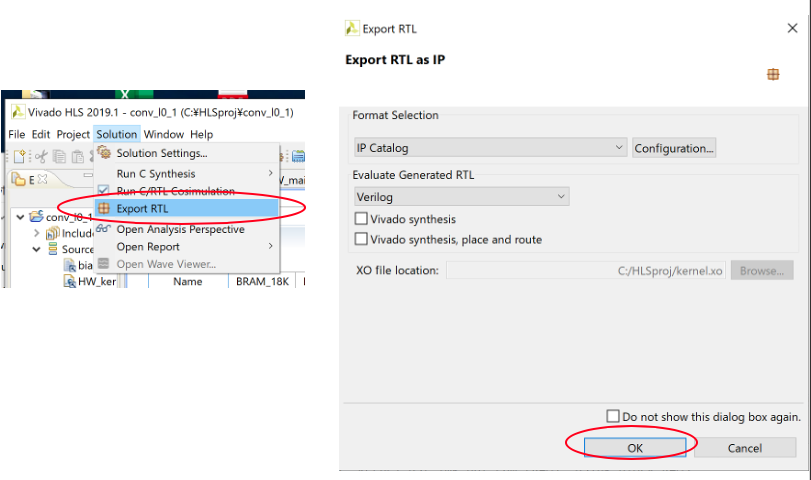
Solution -> Export RTL を選択しそのままOKをクリックします。しばらくするとexportが終わります。いよいよVivadoを起動しましょう。
Vivadoを使ったビットストリーム合成前の準備
起動したらプロジェクトを生成して設定します。Create a New Vivado Project -> Next, Project Name -> “pynq_ultra96_conv_l0_1”としNext,Project Type -> RTL Project をチェックしNext, Add Sources, Add Constraints は共に Nextを指定。
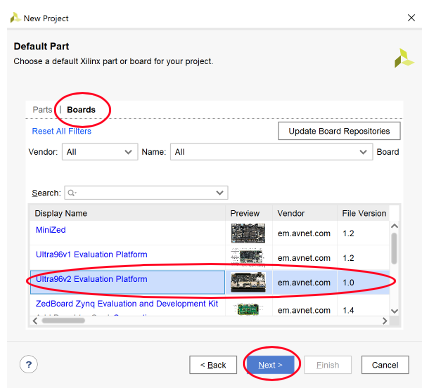
Default Part で上図のように、Ultra96V2ボードを選択し、Next, New Project Summary で Finishを選択.
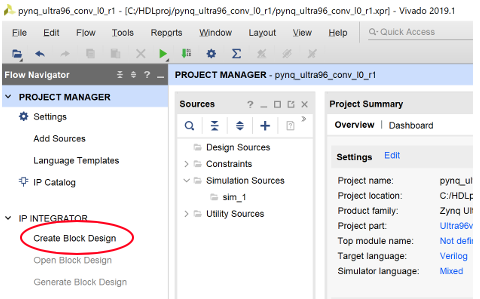
Create Block Design -> OK を行うと
Diagramが開いてIPコアベースの設計が可能となる。
そこで、右クリックしてAdd IP を選択
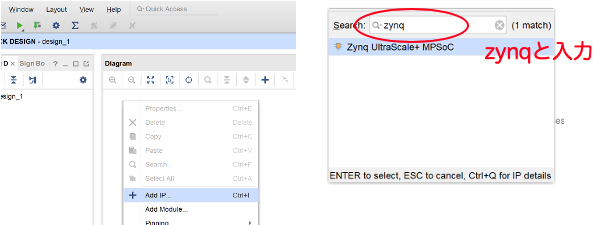
Searchでzynqと入力するとZynq UltraScale+ MPSoCが選べるのでダブルクリックすると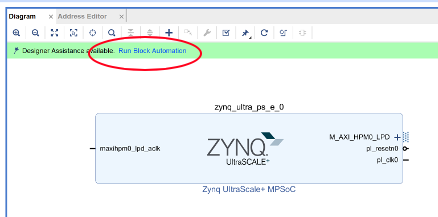
ZYNQのブロックが挿入されます。Ultra96V2用の設定を読み込みましょう。
Run Block Automation をクリックしてOK. これでUltra96V2ボードに搭載されているARMプロセッサのデフォルト設定が読み込まれて設定されます。
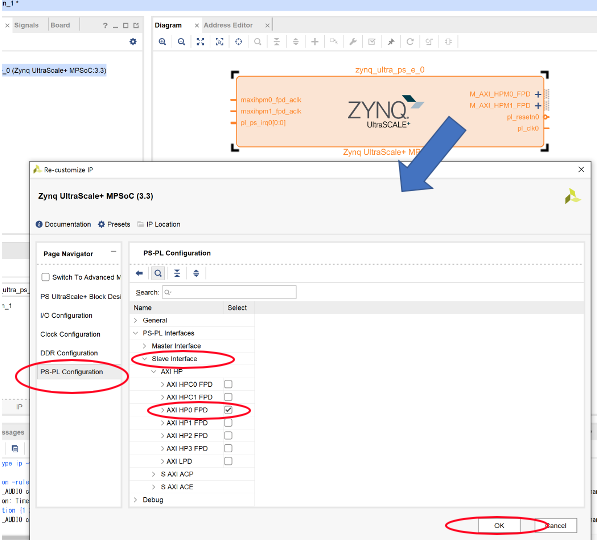
次にユーザが設計したIPコアをどのバスで接続するのかを指定します。
zynq_ultra_ps_e_0 をダブルクリックして, PS-PL Configuration -> Slave Interface
-> AXI HP -> AXI HP0 FPD にチェックを入れてOKをクリック。これでAXI HPポートを使う準備が整いました。次はユーザのIPをインポートしましょう。
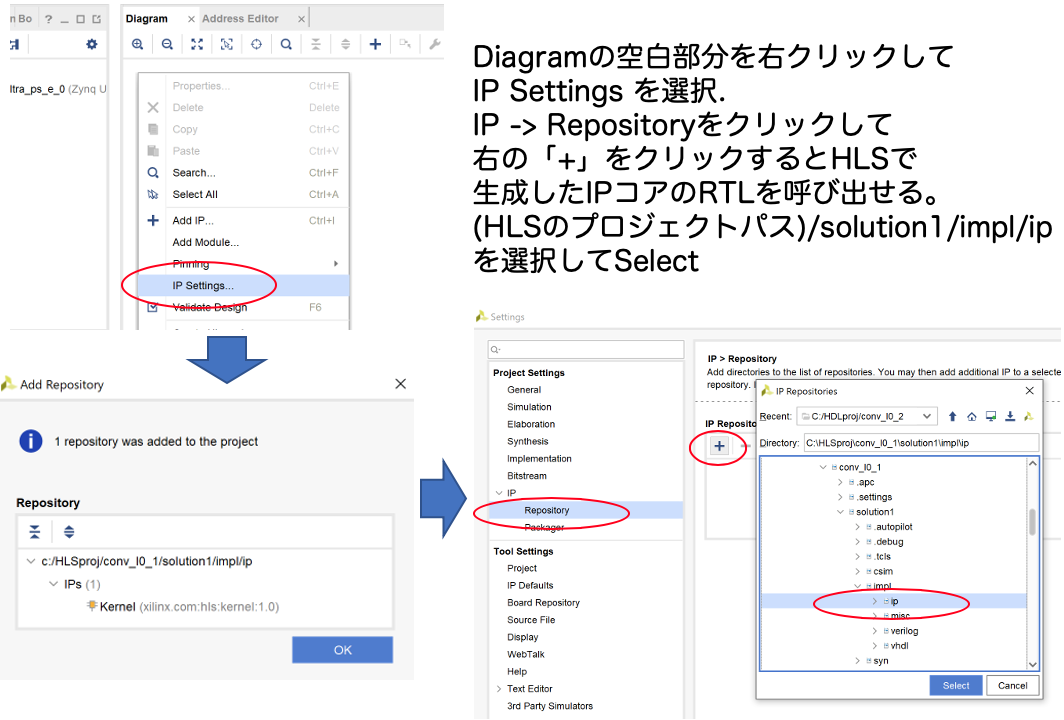
ちょっと面倒な操作が続くので図でまとめました。上図をみてその通りに設定してください。そうするとHLSで設計したトップ関数(今回はKernel)がIPコアとして読み込まれる。IP > Repositoryに戻るのでOKをクリック.
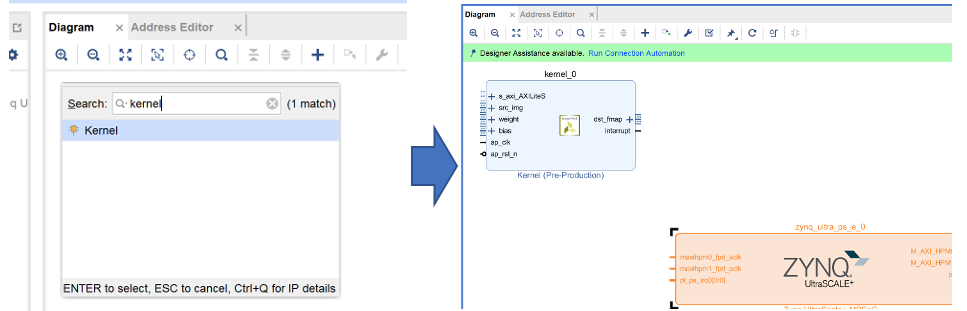
Diagramの空白部分を右クリックして Add IP -> Search にKernel と入力すると自作IPコアが現れるのでダブルクリック(上図左). 自作IPコアが取り込まれました!(上図右)
最後に、DMAコアを追加しましょう。
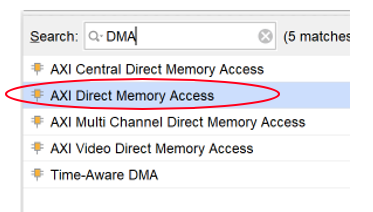
Diagramの空白部分を右クリックして Add IP -> Search にDMAと入力し、
AXI Direct Memory Access をダブルクリック.
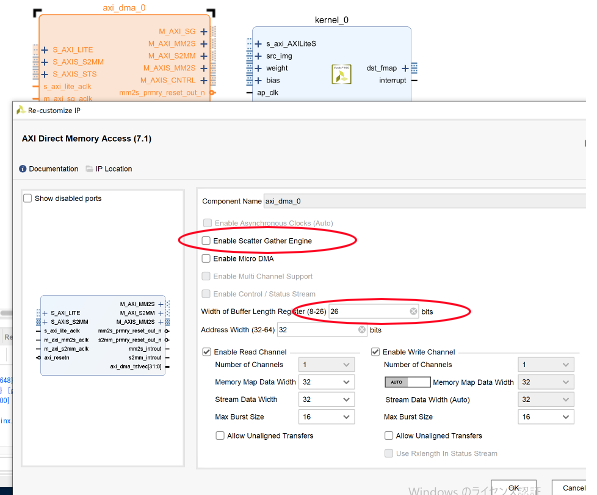
axi_dma_0をダブルクリックして Enable Scatter Gather Engineのチェックを外し Width of Buffer Length Register を 26bit に設定してOKをクリック.26ビットというのはDMAを使って転送するデータのサイズを指定するビット長です。つまり2の26乗個のデータを転送できるように設定しました。なぜデフォが14ビットなのか意味不明です。。。
IPコアを接続しましょう。
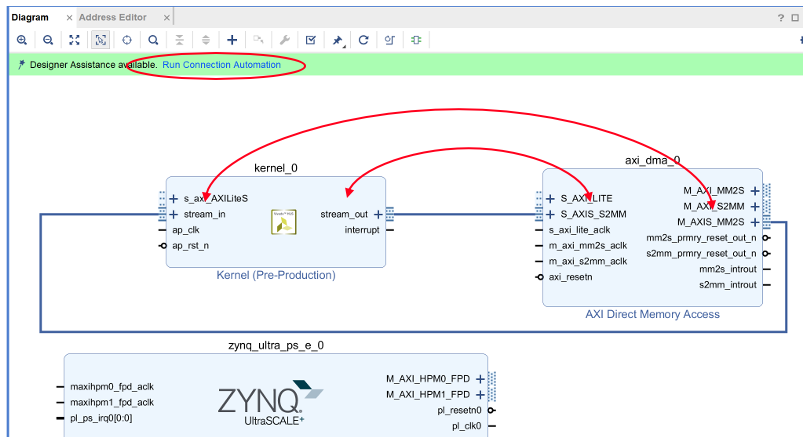
kernel_0 と axi_dma_0 の stream_in <-> M_AXIS_MM2S, stream_out <-> S_AXIS_S2MMをドラッグアンドドロップで接続し, Run Connection Automationをクリックしてください。
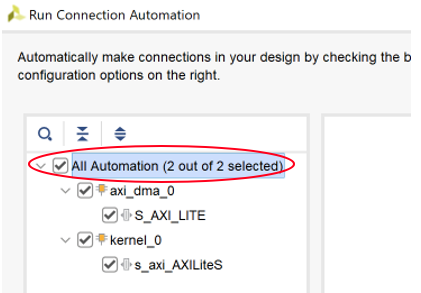
All AutomationをチェックしてOKをクリックすると接続用のIPコアが自動で設定され、配線が行われます。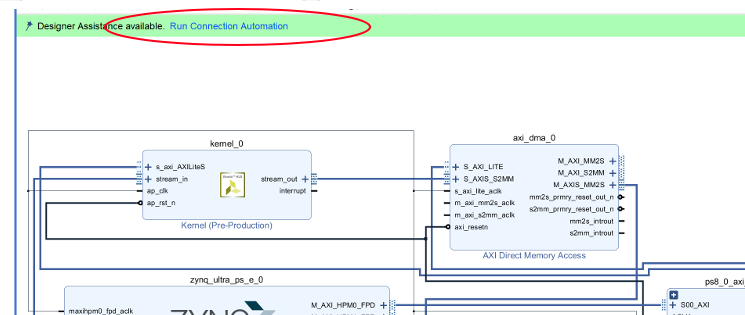
再度 Run Connection Automation をクリックしそのままOKをクリック.
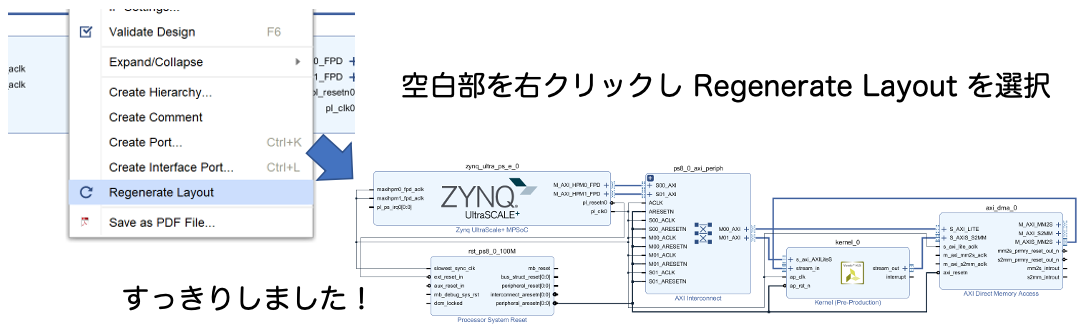
すると配線が自動で行われます。このままでも良いのですが、みやすいように再配置しましょう。
最後に、配線が正しく行われているかチェックをしましょう。DRC (Design Rule Check)といいます。
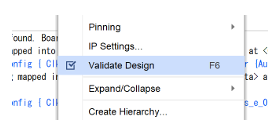
空白部を右クリックし Validate Design を選択して接続のチェックをしましょう。
(Warningが出るが気にしない。。)
ビットストリーム生成
この時点で回路構成ができていますが、肝心のHDLファイルはまだ生成されていません。そこで、各IPコアのHDLファイルを生成しましょう。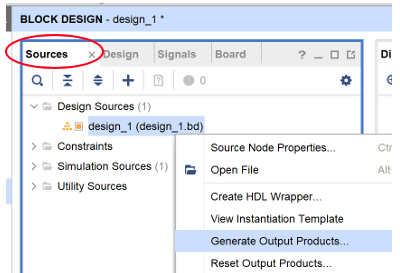
BLOCK DESIGNにあるSources タブに切り替えて design_1 を右クリックしてGenerate Output Productsを選択し, Generate をクリックしてしばらく待ちます。
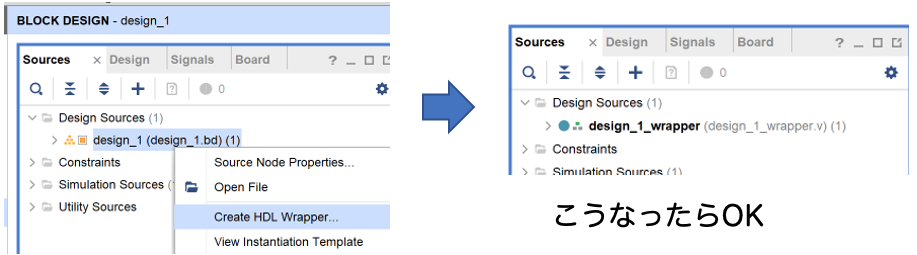
再度design_1 を右クリックしてCreate HDL Wrapperを選択し, OK をクリック.この作業はトップHDLファイルといって、回路全体を接続する記述が書かれたファイルを生成しています。
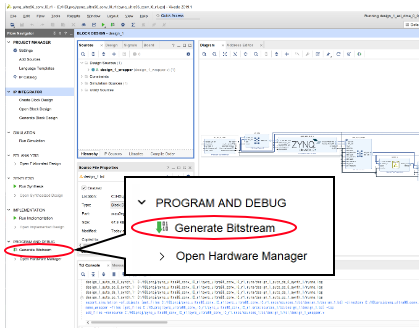
Flow Navigator -> Generate Bitstreamをクリックして適時 OK をクリックしましょう。いよいよビットストリームを生成する作業が始まります。論理合成→リソース配置・配線、が行われます。この作業は10〜20分かかるのでコーヒーでも飲んで待ちましょう。ソフトウェアだったらコンパイルすると一瞬ですよね。ハードウェア設計は時間がかかる理由はこの工程の長さと、検証の面倒さ、記述量の多さが原因です。
ビットストリームが生成されるとダイアログが表示されるのですが、Cancelをクリックしましょう。
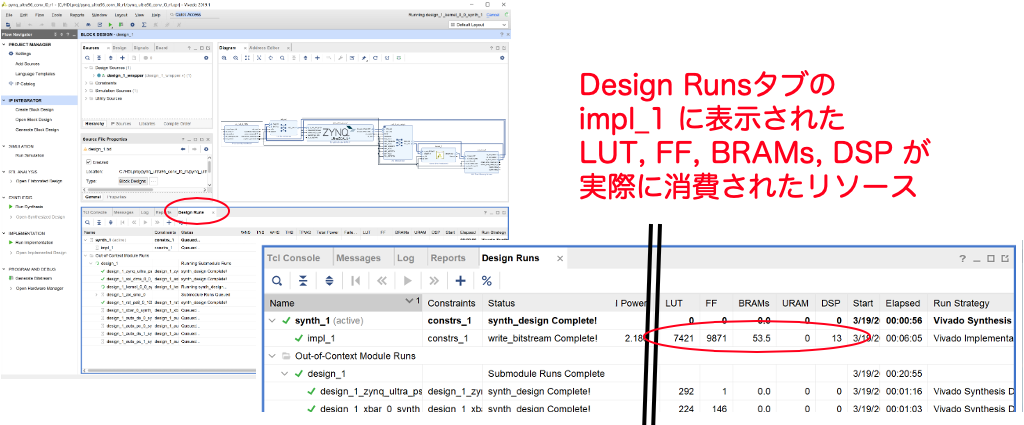
余談ですが、コンテストの提出には設計した回路のリソース量を報告するらしいので、Design Runsタブにその情報が表示されています。impl_1が配置配線までやった実際のリソース消費量です。他の情報は見積もり値なので、この値を報告しましょう。
ビットストリームが生成された後の処理
このままFPGAに書き込みかと思ったら、ファイルの準備が必要です。面倒ですがあと少し!
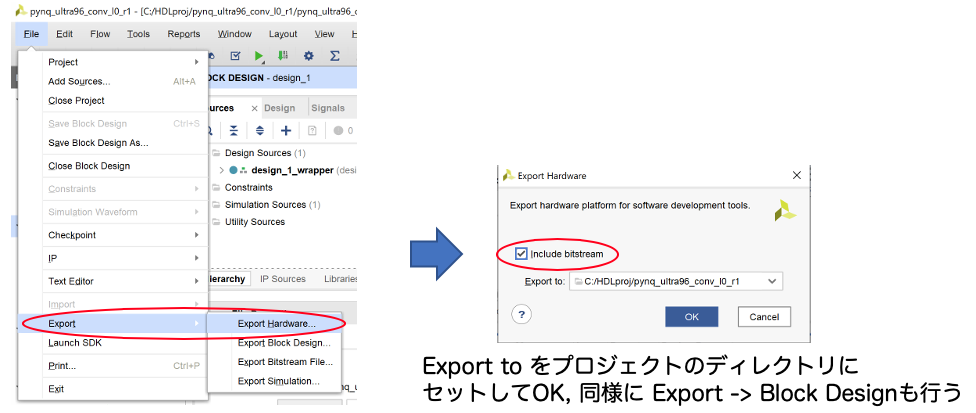
File -> Export を選択してHardware, Block Design, Bitstream Fileを出力します。Export Hardwareではinclude bitstreamにチェックを入れておきます。
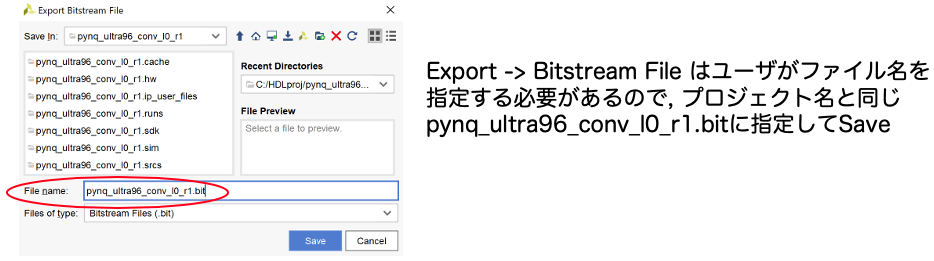
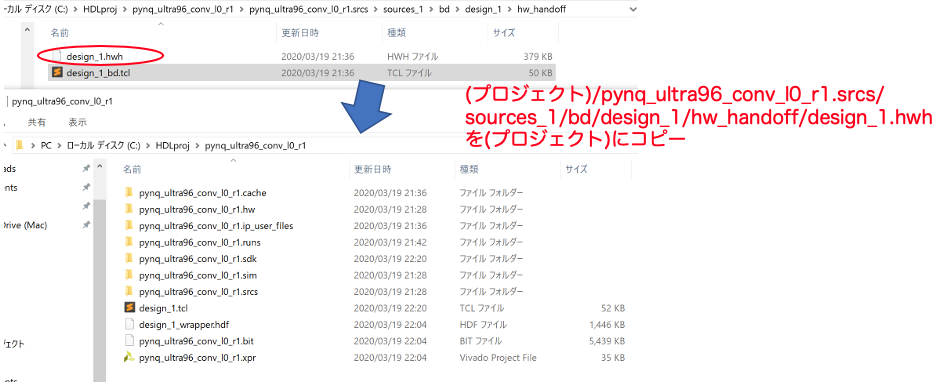
以上の作業を行えば、プロジェクトのディレクトリに4つのファイルが置かれるので、リネームして名前を合わせておきます。この名前を覚えておきましょう。
- pynq_ultra96_conv_l0_r1.bit (そのまま)
- design_1.tcl -> pynq_ultra96_conv_l0_r1.tcl
- design_1_wrapper.hdf -> pynq_ultra96_conv_l0_r1.hdf
- design_1.hwh -> pynq_ultra96_conv_l0_r1.hwh
ようやく作業終了です!!いよいよUltra96V2で(やたらと遅い)ハードウェアを動かしてみましょう!!