この記事について
Pythonデータ分析試験に合格したので、要点をまとめてみました。
1. データ分析エンジニアの役割
教師あり学習と教師なし学習
教師あり学習は正解となるラベルが存在する学習方式です。
正解ラベルである目的のデータを目的変数と呼びます。
目的変数以外のデータを説明変数と呼びます。
教師あり学習は説明変数を用いて、目的変数を予測する学習方式ということになります。
一方、教師なし学習は正解ラベルを用いない学習方式です。
正解ラベルがないので、目的変数がない学習方式ということです。
分類とクラスタリング
教師あり学習の分類は、事前にいくつのグループに分けるのか、明確に定義します。
例えば、イヌとネコに分類したい場合は2グループに分けることになります。
一方、クラスタリングは教師なし学習に分類され、グループ数がいくつになるのか明確ではありません。
ひょっとしたら、3グループかもしれないですし、5グループになるかもしれません。
機械学習の処理手順
機械学習はこのような手順で処理していきます。
データ入手 -> データ加工 -> データ可視化 -> アルゴリズム選択 -> 学習プロセス -> 精度評価 -> 試験運用 -> 結果利用(サービス運用)
機械学習はとにもかくにもデータが必要です。
データ分析のパッケージ
データ分析での主なパッケージは以下の通りです。
- Jupyter Notebook
- NumPy
- pandas
- Matplotlib
- scikit-learn
- SciPy
間違ってもdjangoなんてものは使っていないです。
参考書籍ではSciPyは存在感が薄いですが、データ分析で利用されるパッケージです。
※djangoに興味がある方はググってみてください。Flaskの親戚です。
2. Pythonと環境
pipコマンド
pipコマンドは-Uオプションをつけることでインストールするライブラリが最新版に更新されます。
明示的に最新版をインストールするには、このようになります。
$ pip install -U numpy pandas
空白文字列の削除
左右の空白文字を削除する場合はstripメソッドを利用します。
bird = ' Condor Penguin Duck '
print("befor strip: {}".format(bird))
print("after strip: {}".format(bird.strip()))
befor strip: Condor Penguin Duck
after strip: Condor Penguin Duck
pickleモジュール
pickleモジュールはPythonオブジェクトを直列化して、ファイルで読み書きできるようにします。
pathlibモジュール
Pythonでパスを利用する場合は、pathlibモジュールを使います。
マジックコマンド
Jupyter Notebookにはマジックコマンドというコマンドがあります。
例えば、%%timeitと%timeitがあります。
どちらも、プログラムを複数回実行して、実行時間を計測するコマンドです。
%timeitは1行のプログラムに対して時間を計測します。
一方、%%timeitはセル全体の処理時間を測定します。
%%timeit
x = np.arange(10000)
fig, ax = plt.subplots()
ax.pie(x, shadow=True)
ax.axis('equal')
plt.show()
# 図形の出力は省略
12 s ± 418 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
3. 数式を読むための基礎知識
数学はQiitaで書くと時間がかかるので、ざっくりと紹介していきます。
どんな傾向があるかグラフ等をよく見ておくと良いと思います。
対数関数
以下のような数式で表される関数を対数関数と呼びます。
f\left( x\right) =\log _{2}x
ユークリッド距離
ベクトルの大きさをスカラーを求める方法、つまりノムルを求める方法として、ユークリッド距離があります。
\left\| x\right\| _{1}=\left| x_{1}\right| +\left| x_{2}\right| +\ldots +\left| x_{n}\right|
簡単に言えば、ベクトルの各要素の絶対値を足し合わせています。
行列の掛け算
m × sの行列とs × nの行列をかけると、m × nの行列になります。
m × sの行列とx × nの行列のように、行列の数が合わないとかけることはできません。
また、数学の掛け算と違い行列の掛け算は順番が変わると結果が変わります。
自然対数の微分
$f\left( x\right) =e^{x}$は微分しても数値は変わりません。
f'\left( x\right) =e^{x}
4.1 NumPy
dtype属性
NumPyの配列ndarrayの要素のデータ型はdtype属性で確認できます。
ちなみに、Pythonのtypeメソッドは配列自体の型(ndarray)を確認できます。
a = np.array([1, 2, 3])
print("ndarray dtype: {}".format(a.dtype))
print("ndarray type: {}".format(type(a)))
ndarray dtype: int32
ndarray type: <class 'numpy.ndarray'>
コピーと参照
ndarrayではb = aという操作は参照となります。(bの値を変更するとaの値も変更される)
b = a.copy()と操作するとコピーとして扱われます。(bの値を変更してもaの値は変更されない)
Python標準のリストをスライスした場合はコピーが渡されますが、Numpyでのスライスの結果は参照が渡されます。
色々な組み合わせを試してみると、より理解が深まると思います。
nan
NumPyで数値ではないことを宣言するにはnp.nanを使用します。
a = np.array([1, np.nan, 3])
print(a)
[ 1. nan 3.]
行列の分割
vpslit関数では行方向、hsplit関数では列方向に行列を分解します。
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
first1, second1 = np.vsplit(a, [2])
first2, second2 = np.hsplit(second1, [2])
print(second2)
[[9]]
平均値
行列の平均値を求めるにはmeanメソッドを用います。
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
a.mean()
5.0
論理値
ndarrayは演算子で比較するとTrue / Falseで表示されます。
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
a > 4
array([[False, False, False],
[False, True, True],
[ True, True, True]])
4.2 Pandas
インデックス / カラム名の指定
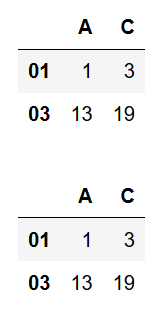
DataFrameからインデックスやカラムを指定して、データを抽出するにはlocメソッド / ilocメソッドを使用します。
locメソッドはインデックスとカラム名をインデックス名やカラム名を指定します。
ilocメソッドはインデックスとカラムを位置や範囲で指定します。
df = pd.DataFrame([[1, 2, 3], [5, 7, 11], [13, 17, 19]])
df.index = ["01", "02", "03"]
df.columns = ["A", "B", "C"]
display(df.loc[["01", "03"], ["A", "C"]])
display(df.iloc[[0, 2], [0, 2]])
データの書き込み / 読み込み
データの書き込みはto_xxx、読み込みはto_xxxで行います。
excelやcsv、pickle等が対応しています。
df.to_excel("FileName.xlsx")
df = pd.read_excel("FineName.xlsx")
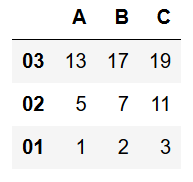
データの並べ替え
データはsort_valuesメソッドで並べ替えます。
デフォルトでは昇順で並べ替えが行われます。
降順に並べ替えるにはascending=Falseを引数に設定します。
df = pd.DataFrame([[1, 2, 3], [5, 7, 11], [13, 17, 19]])
df.index = ["01", "02", "03"]
df.columns = ["A", "B", "C"]
df.sort_values(by="C", ascending=False)
One-hotエンコーディング
get_dummiesメソッドを使うとOne-hotエンコーディングに変換できます。
One-hotエンコーディングではカテゴリ変数の種類だけ列を追加します。
日付配列
日付配列を取得するにはdata_rangeメソッドを使用します。
引数のstartとendに日付を設定することができます。
dates = pd.date_range(start="2020-01-01", end="2020-12-31")
print(dates)
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10',
...
'2020-12-22', '2020-12-23', '2020-12-24', '2020-12-25',
'2020-12-26', '2020-12-27', '2020-12-28', '2020-12-29',
'2020-12-30', '2020-12-31'],
dtype='datetime64[ns]', length=366, freq='D')
4.3 Matplotlib
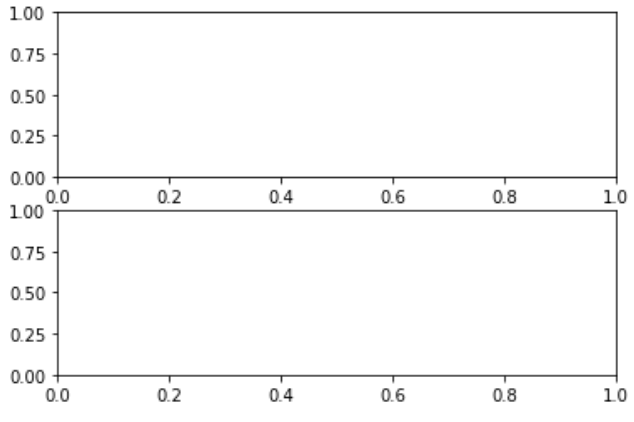
サブプロット
subplotsメソッドの引数で配置するサブプロット数を指定します。
数値一つの場合は2行のサブプロット、ncolsを指定すると2列のサブプロットが配置されます。
fig, axes = plt.subplots(2)
display(plt.show())
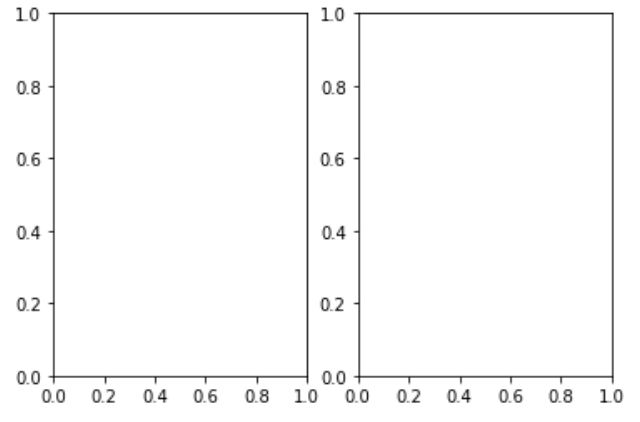
fig, axes = plt.subplots(ncols=2)
display(plt.show())
散布図
散布図はscatterメソッドで描画することができます。
ヒストグラム
ヒストグラムはhistメソッドで描画することができます。
bins引数でビン数を指定することができます。
円グラフ
円グラフはpiメソッドで描画することができます。
デフォルトでは、右から反時計回りに描画されます。
スタイル
色はHTMLやX11、CSS4で定義された色名を指定することができます。
フォントスタイルは辞書で定義してまとめて適用した李、個々に適用することもできます。
4.4 scikit-learn
分類モデル
分類モデルのデータセットは学習データとテストデータに分割します。
これはモデルの汎化能力を評価する必要がある為です。
決定木
決定木はモデルが可視化でき、内容が理解しやすい特徴があります。
パラメータはユーザーが設定する必要があります。
決定木の目的は情報利得の最大化もしくは不純度の最小化です。
(どちらも同じ意味を指します)
次元削減
次元削減とは、データをなるべく損ねることなく次元を削減するタスクです。
例えば、XとYの二次元データのうち、重要でないYのデータを削除して、Xのみの一次元データにすることができます。
ROC曲線とAUC
ROC曲線は確率の高い順にデータを並べたとき、各データの確率以上のデータはすべて正例であると予測することです。
AUCの値が1に近づくほど確率が相対的に高いサンプルが正例、相対的に低いサンプルが負例となる傾向が高まります。
つまり、AUCはモデル間の良さを比較することが可能です。