何の記事?
PrometheusのHA構成について調べる機会があり、
その際にCortexというツールを見つけたので、仕組みを簡単に紹介します。
PrometheusのHA構成
Prometheusを複数台用意すればOKじゃん!!
というほどPrometheusの冗長化は簡単ではないようです。
Timescale(Postgresを時系列DBにする拡張機能)のブログでは、Prometheusを単純に複数台構成にした場合の問題点が記載されています。
これを基にどんな状態が想定されるか考えてみます。
仮に同じ設定のPrometheusが2台いるとします。
データの損失を防ぐ為、2台のPrometheusにはStorageを用意します。
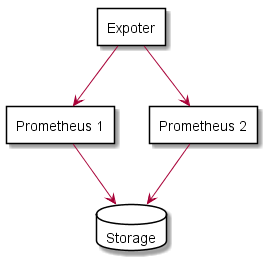
この場合、Prometheus 1とPrometheus 2のスクレイピングの間隔が微妙に異なる場合があります。よって、Storage内でデータの不整合が起きる可能性があります。
それでは、各PrometheusにStorageを用意した場合はどうでしょうか。
この場合は、どちらのStorageを正とするかのロードバランシングの問題が発生します。
まとめると、PrometheusのHA構成にはこのような問題が発生するようです。
- スクレイピングしたデータの重複/不整合
- ロードバランシング
Cortexって何?
Githubを見てみると、このようなキーワードが並んでいます。
- Horizontally scalable
- Highly available
- Multi-tenant
- Long term storage
要するに、
- Cortexは可用性が高くて、データも損失しにくいよ
- 複数のPrometheusからデータが収集できるよ
- 長期のデータ保存ができるよ
と言っているようです。
Cortexアーキテクチャ
Githubにはこのような構成図が掲載されています。
Cortexの肝である、赤で囲った部分にフォーカスして説明していきます。

今回説明する部分を簡略化すると、このような構成になっています。

Load Balancer
LBは残念ながらCortexコンポーネントには含まれないので、自分で構築する必要があります。
Distributor/Consul
CortexではPrometheusからのデータを受け取ると、まずはDistributorがデータを受け取ります。
Distributorの機能は
- ラベル名が重複したものは最大値を採用する
- Ingesterにデータを配布する
となります。
Hash Ring
Ingesterへのデータ配布はHash Ringでデータを分割します。
(文章で表現すると難しいのですが、絵心もないので文章で頑張って表現します)
イメージとしては、
データは一つのドーナッツだと思って下さい。
このドーナッツをIngester達で分けることにします。
(今回はIngesterが3つとします)
この時、ドーナッツを3等分するのですが、
その前にドーナッツを千等分してしまいます。
ピース1はIngester1へ配り、ピース2はIngester2に配り・・・としていき、データは3等分されます。
この時、Ingester1が故障した時の保険として、ピース1はIngester2とIngester3にも配布します。
複雑ですが、まずはデータを切り刻んでIngesterに配布している事を理解できれば良いです。
Cortexの紹介ブログでもこのように表現されています。
It’s not like slicing a pie into five pieces. It’s more like slicing a pie into a thousand pieces, and then each ingester claiming every fifth piece
Ingester
実質、Prometheusのデータを保持している部分です。
Hash Ringでデータを分割しているので(かつ別のIngesterが同じデータを持っているので)、ここが故障してもデータの損失は起こりにくいです。
(Ingester1台の障害なら損失は起こりませんが、複数台だと問題が起きる可能性があるようです)
受信したデータはメモリに保存され、チャンク形式でストレージへpushされます。(デフォルトでは12時間)
ストレージの保存形式に関わってくることなのですが、
データの保存形式にはブロック形式もあります。
Chunk Data/Chunk Index
チャンクデータはIndexとデータの実態に分けて保存することができます。
(オプション機能)
データを分けない場合、Indexと実態データはともにChunk Indexに保存されます。
利用可能なストレージは以下の通りです。
- Chunk Index
- Amazon DynamoDB
- Google Bigtable
- Apache Cassandra
- Chunk Data(オプション)
- Amazon DynamoDB
- Google Bigtable
- Apache Cassandra
- Amazon S3
- Google Cloud Storage
- Microsoft Azure Storage
Cortexのメリット/デメリット
メリット
- データの損失が起こりにくく、可用性が高い
デメリット
- 構成が複雑でコンポーネント内の個々の構築が難しい
(Consul/memcached等) - 万一、Ingesterに障害が起きた場合、最大12時間分のデータが損失する
参考
https://medium.com/weaveworks/what-is-cortex-2c30bcbd247d
https://github.com/cortexproject/cortex