はじめに
この記事は、Apache Sparkのpartitionの概念について例題を添えてまとめてみようと試みた記事です。
Apache Sparkの概要についてはApache Spark で分散処理入門をどうぞ。
例題で見るパーティションのイメージ
以下は、Apache Sparkの分散処理のイメージを例題とともに図解しているものです。
まず、使う関数の説明、次にその処理のイメージ、最後にソースコードの順番で紹介しています。
パーティションの使い方が異なる三例を紹介します。
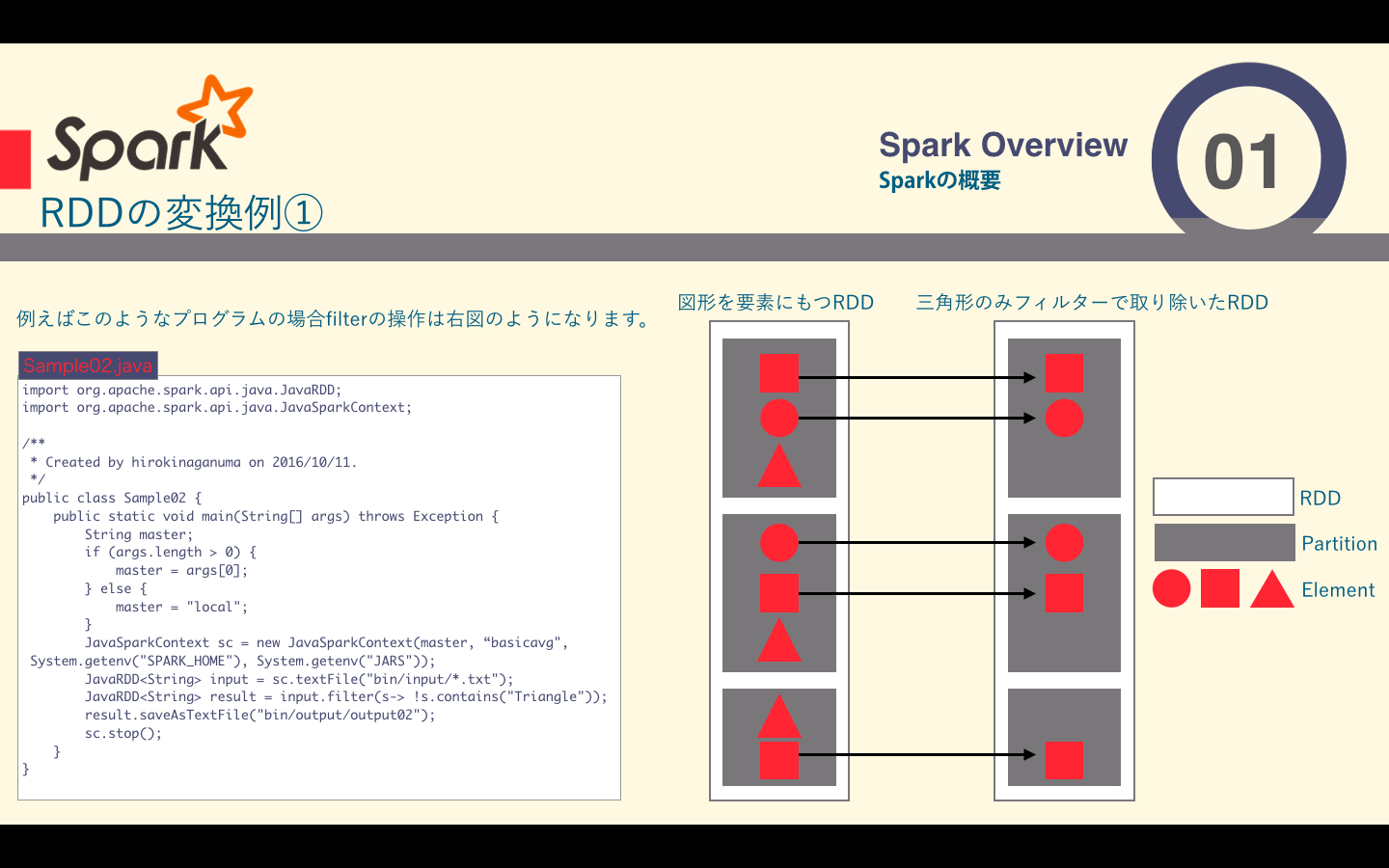
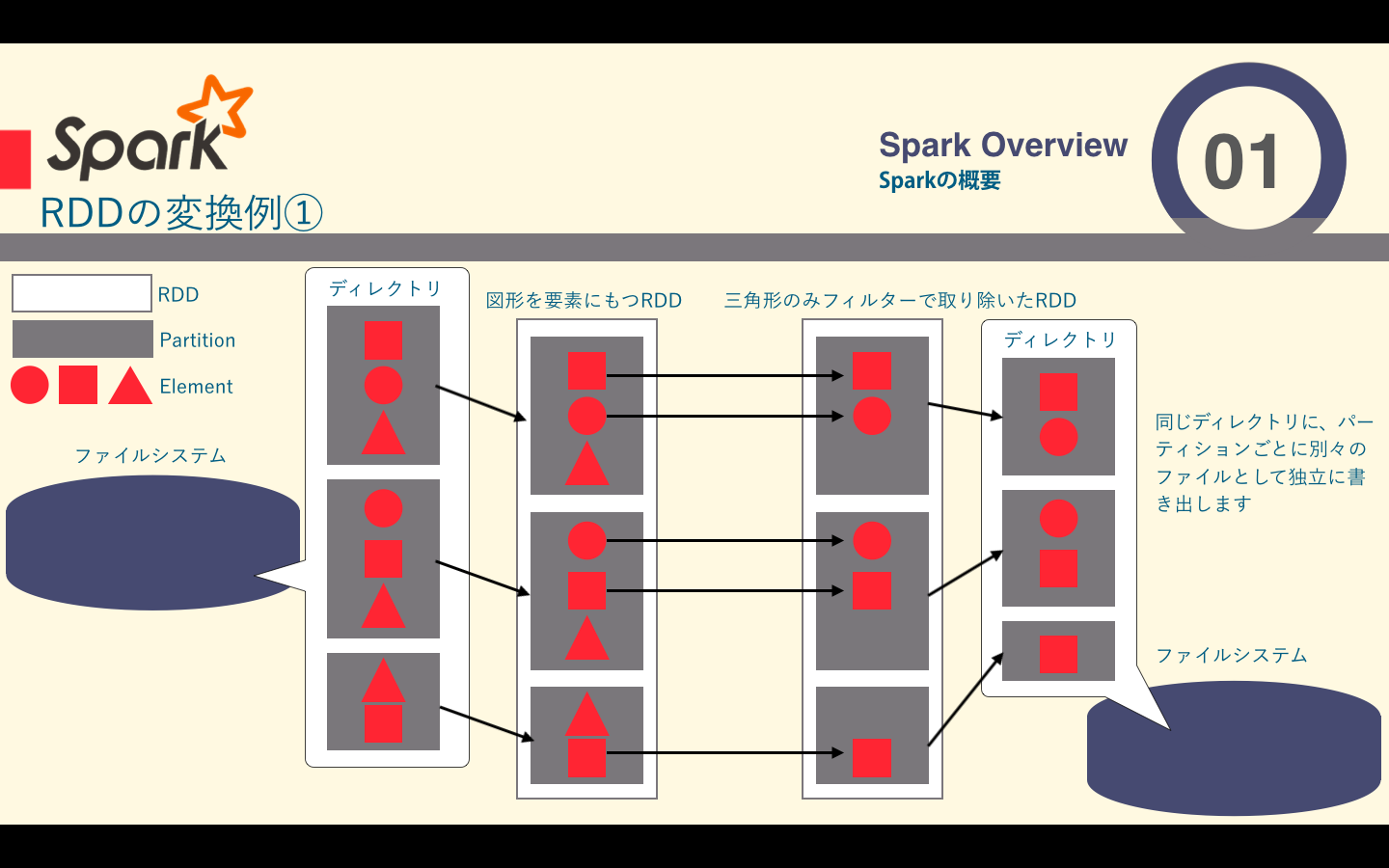
- filter関数の例
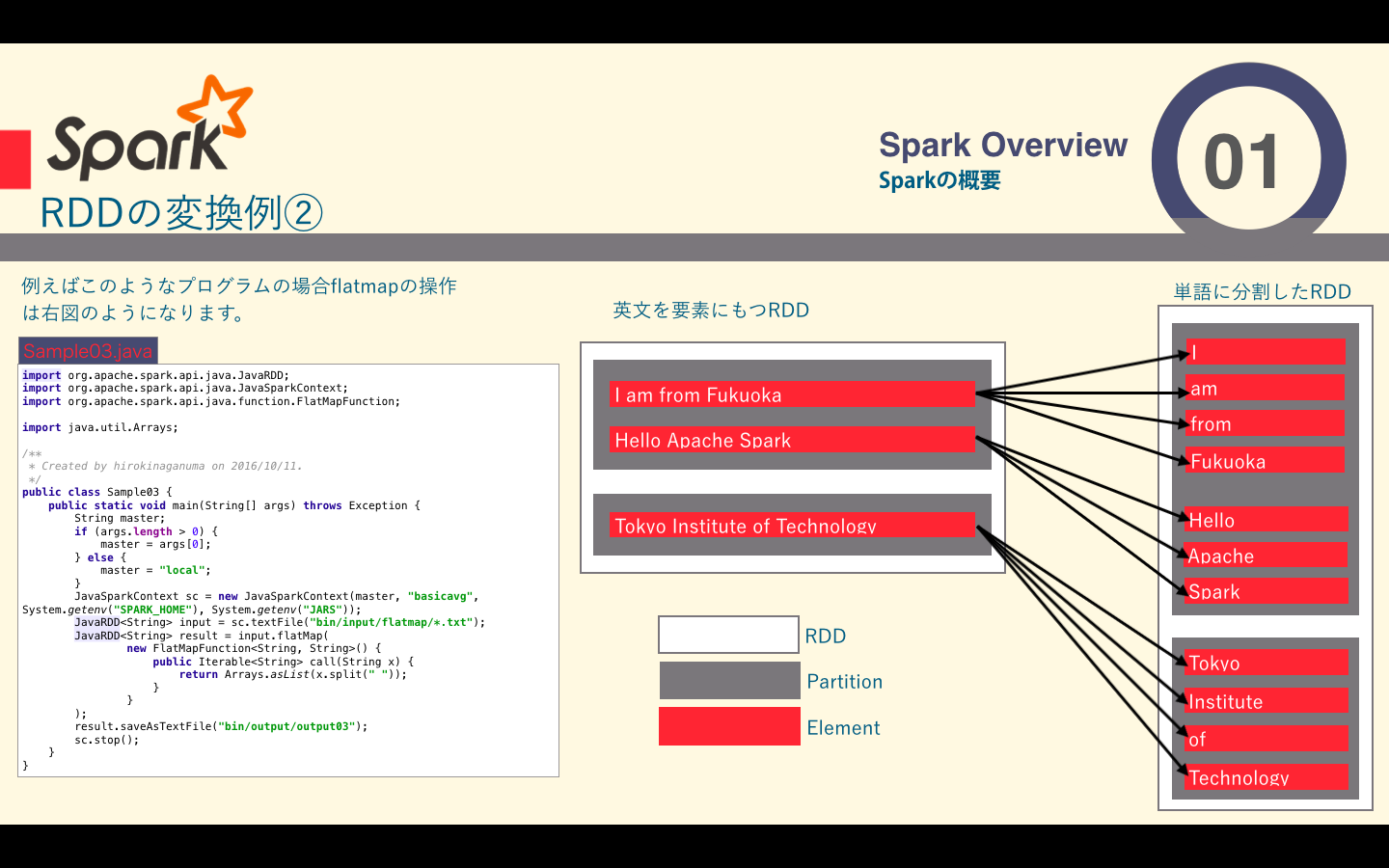
- flatmap関数の例
- reduceByKey関数の例
filter関数の例
要素単位の変換としてはmap()やfilterなどがあります。
| 関数 | 説明 |
|---|---|
| map() | 引数に関数を一つ取り、その関数をRDD内の各要素に適応し、その結果を新しい値とするRDDを返す |
| filter() | 引数に関数を一つ取り、そのフィルタ関数が真になる要素だけを含むRDDを返す |
ソースコードはこちら
package other;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* Created by hirokinaganuma on 2016/10/11.
*/
public class Sample02 {
public static void main(String[] args) throws Exception {
String master;
if (args.length > 0) {
master = args[0];
} else {
master = "local";
}
JavaSparkContext sc = new JavaSparkContext(master, "basicavg", System.getenv("SPARK_HOME"), System.getenv("JARS"));
JavaRDD<String> input = sc.textFile("bin/input/*.txt");
JavaRDD<String> result = input.filter(s-> !s.contains("Triangle"));
result.saveAsTextFile("bin/output/output02");
sc.stop();
}
}
Rectangle
Circle
Triangle
Circle
Rectangle
Triangle
Triangle
Rectangle
RDDは大量のデータを要素として保持する分散コレクションです。RDDは複数のマシンから構成されるクラスタ上での分散処理を前提として設計されており、内部的には__partition__という塊に分割されています。Sparkではこのpartitionが分散処理の単位となっています。RDDをpartitionごとに複数のマシンで処理することによって、単一のマシンでは処理できないデータを扱うことができます。
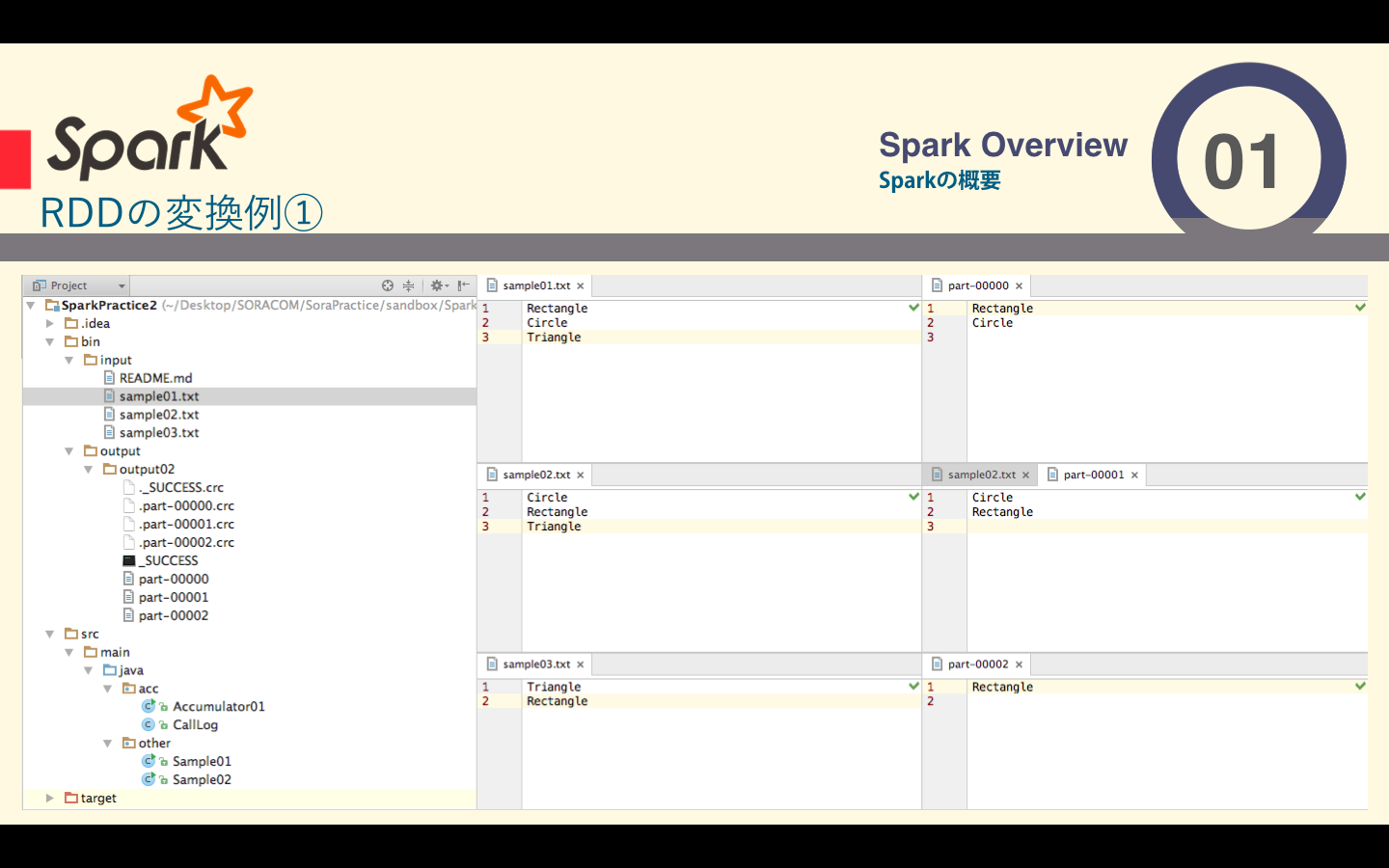
このように分割されたファイルを一つのRDDとして扱い、input.filter(s-> !s.contains("Triangle"))と記述するだけで、分散を意識せずプログラミングできるようになってます。
flatmap関数の例
filterやmap関数が1:1の関係だったのに対し、この関数は、一つの要素から複数の要素を生成する1:Nの関係の変換です。
| 関数 | 説明 |
|---|---|
| flatMap() | 引数に関数を一つ取り、その関数をRDD内の各要素に適応して呼ばれるが、この関数はその結果を返すIteratorを返します。それらのIterator全てから返された要素を値とするRDDを最優的に返します |
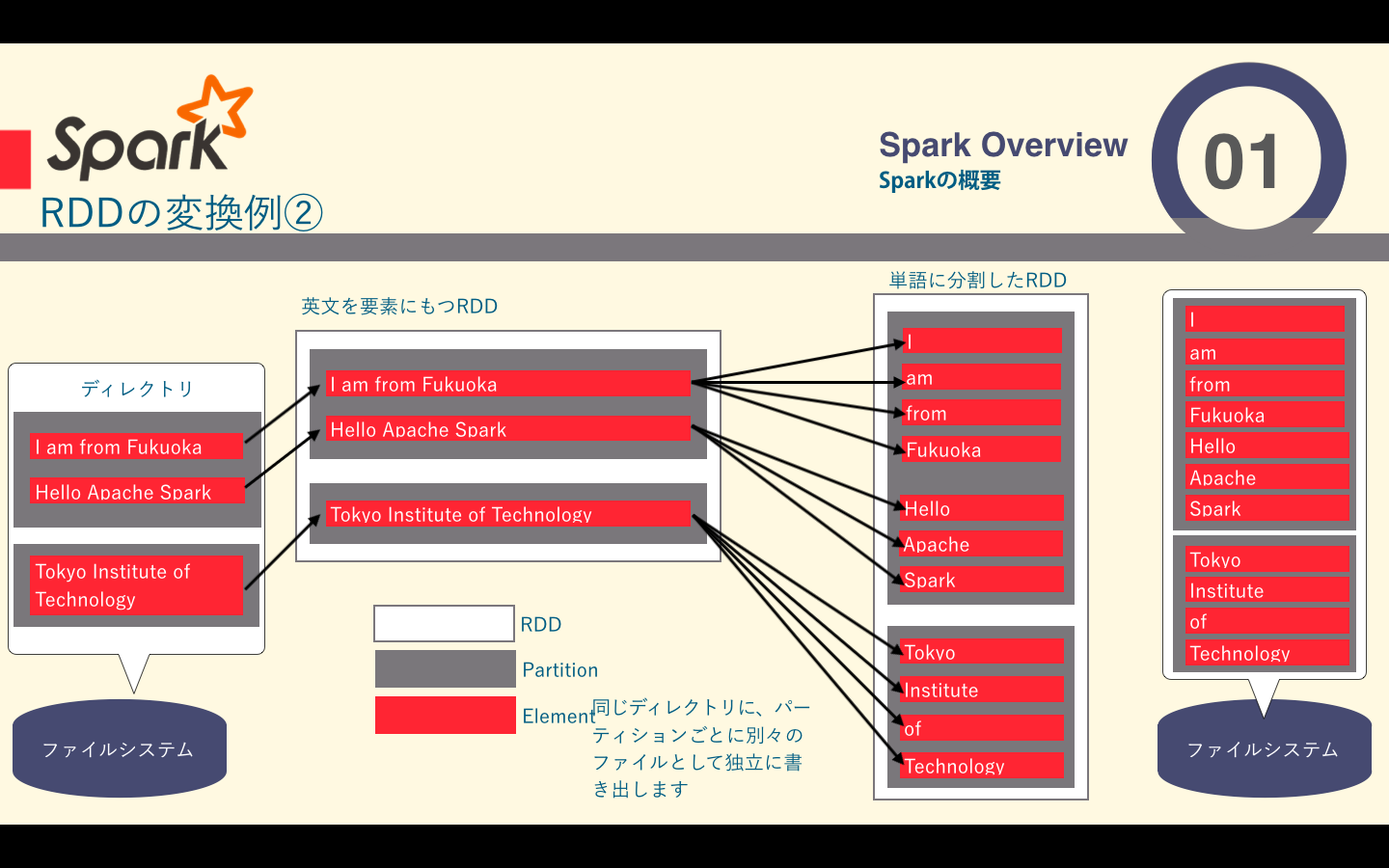
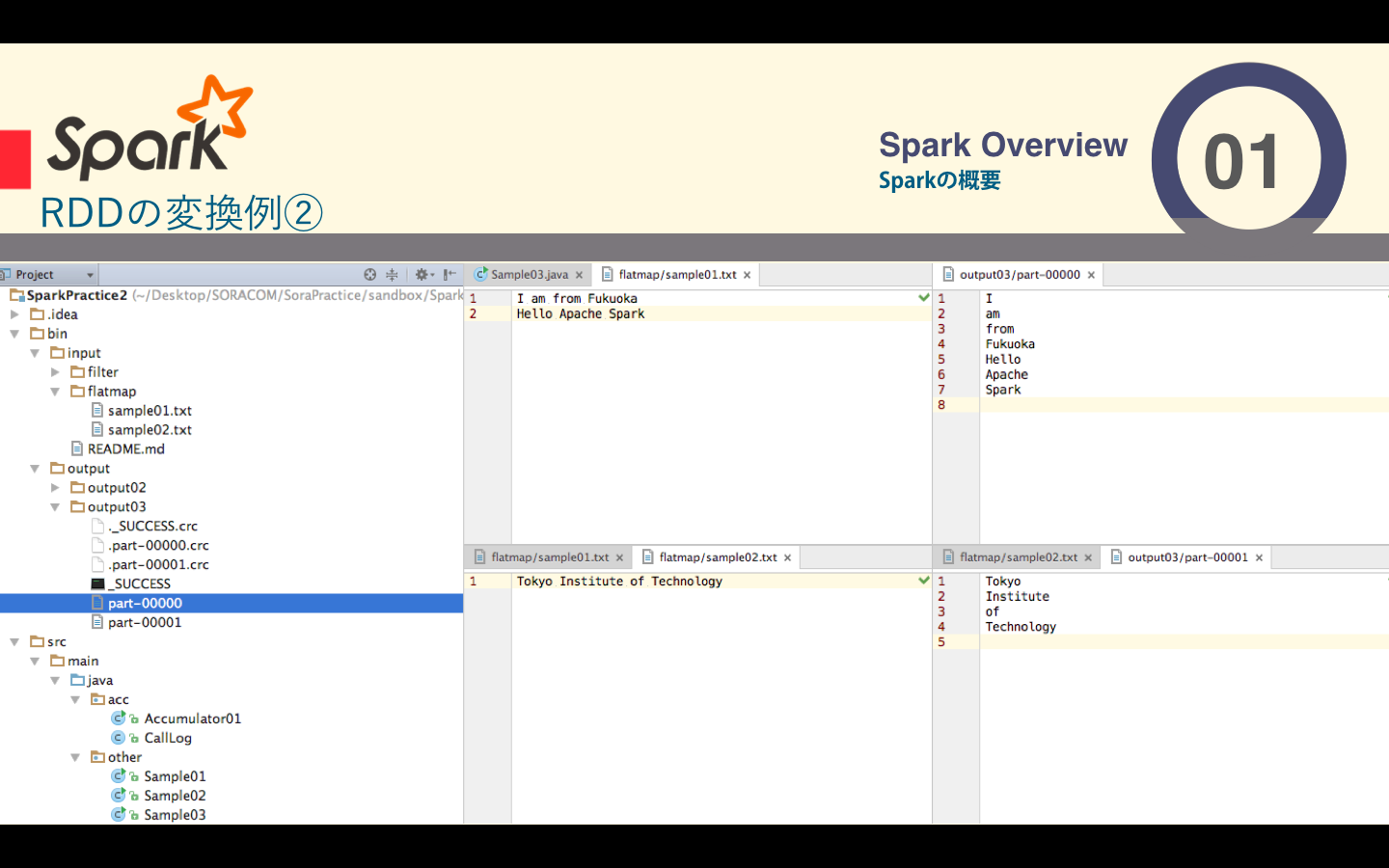
ソースコードはこちら
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import java.util.Arrays;
/**
* Created by hirokinaganuma on 2016/10/11.
*/
public class Sample03 {
public static void main(String[] args) throws Exception {
String master;
if (args.length > 0) {
master = args[0];
} else {
master = "local";
}
JavaSparkContext sc = new JavaSparkContext(master, "basicavg", System.getenv("SPARK_HOME"), System.getenv("JARS"));
JavaRDD<String> input = sc.textFile("bin/input/flatmap/*.txt");
JavaRDD<String> result = input.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String x) {
return Arrays.asList(x.split(" "));
}
}
);
result.saveAsTextFile("bin/output/output03");
sc.stop();
}
}
I am from Fukuoka
Hello Apache Spark
Tokyo Institute of Technology
reduceByKey関数の例
reduceByKeyは返還前のRDDに含まれる要素を、同じRDDに含まれるほかのpartitionの要素とまとめて処理する必要のあるものです。この変換はkey・valueペアを要素とするRDDを対象にしており、同じkeyを持つ要素をまとめて処理します。Sparkはpartitionごとに独立して分散処理を行うため同じkeyを持つ要素はすべて同じpartitionに含まれている必要があります。そのためreduce処理の前に配置換え(shuffle)が行われます。shuffleは、返還前のRDDの要素を、keyに基づいて変換後のRDDのpartitionに振り分けるように行われます。そのため、shuffleによって同じkeyを持つ要素が同じpartitionに含まれることが保証されます。
下の図では表しきれませんでしたが、shuffleの前にそのpartitionないでreduce`処理が行われ、通信コストを減らしているようです。
https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html
| 関数 | 説明 |
|---|---|
| reduceByKey() | 引数に関数を一つ取り、その関数は同じキーの値を結合する際のreduce処理である |
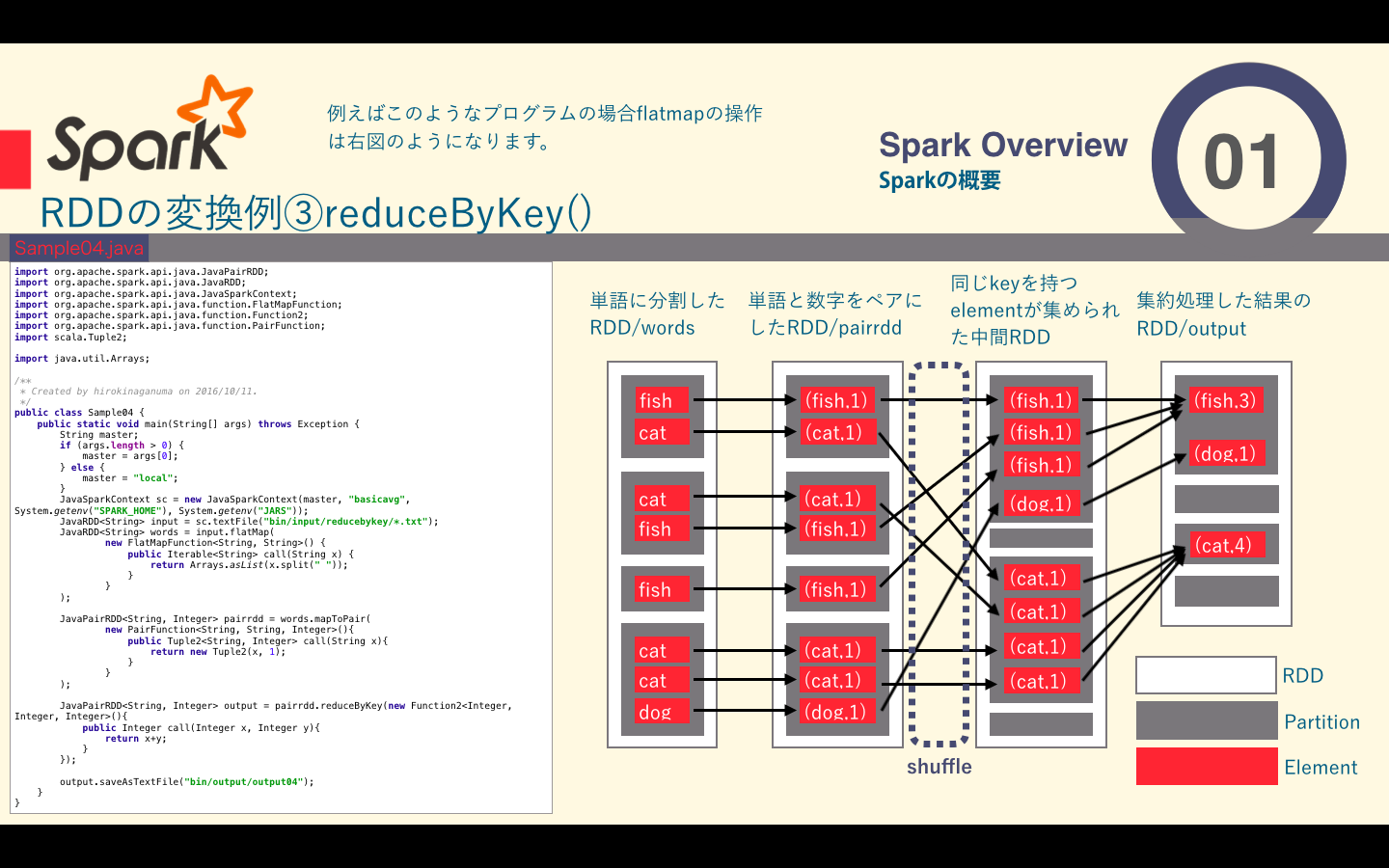
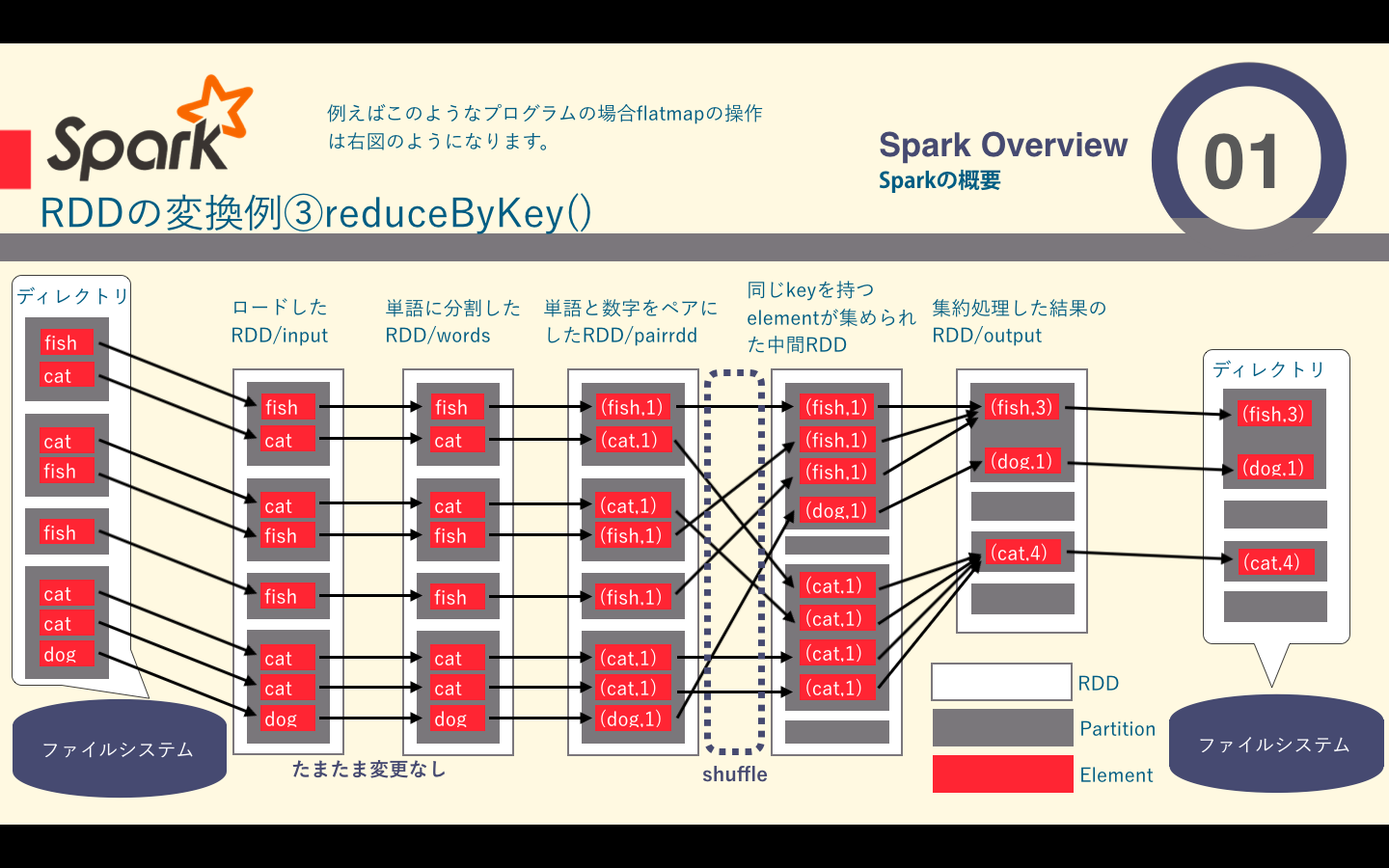
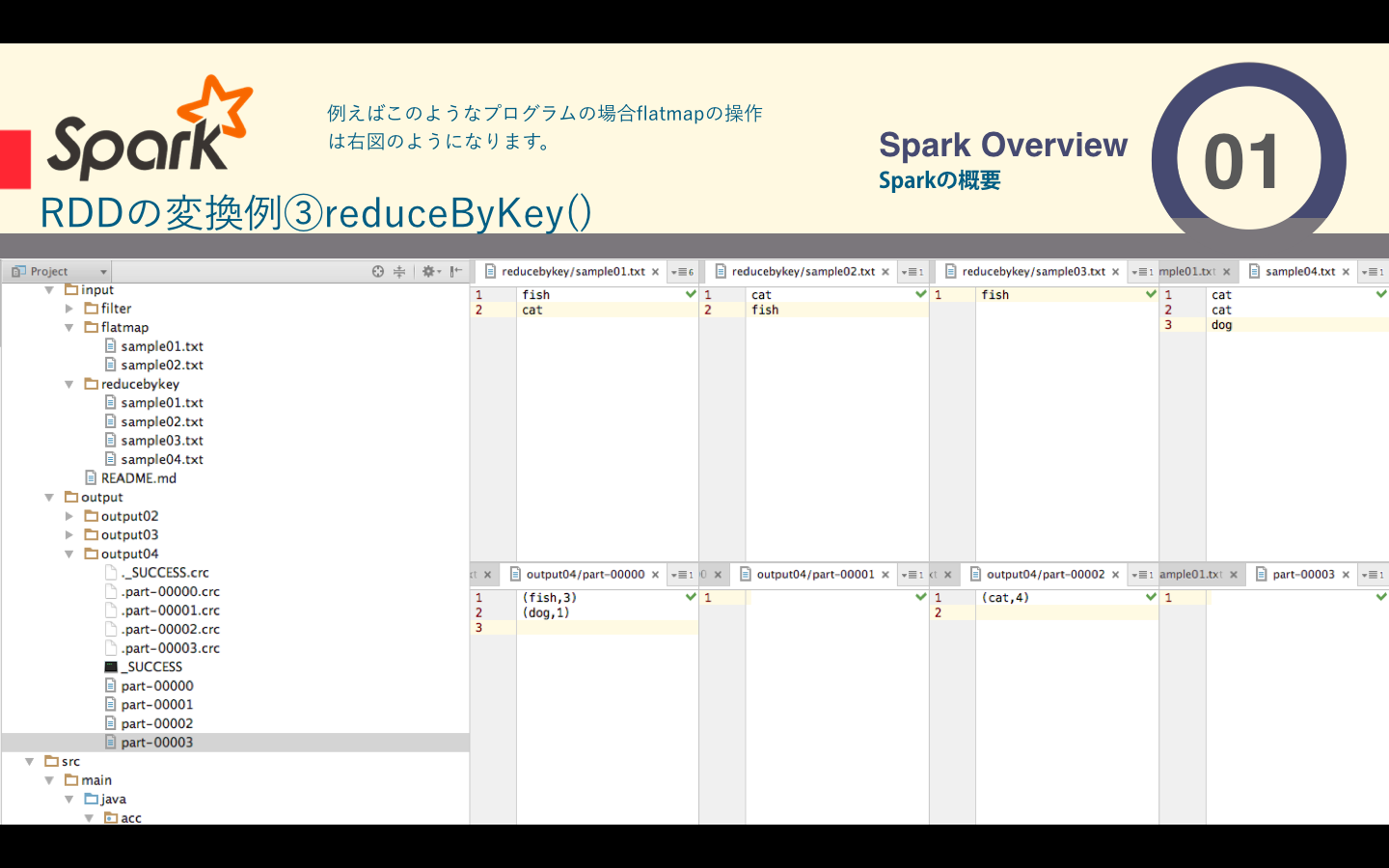
ソースコードはこちら
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by hirokinaganuma on 2016/10/11.
*/
public class Sample04 {
public static void main(String[] args) throws Exception {
String master;
if (args.length > 0) {
master = args[0];
} else {
master = "local";
}
JavaSparkContext sc = new JavaSparkContext(master, "basicavg", System.getenv("SPARK_HOME"), System.getenv("JARS"));
JavaRDD<String> input = sc.textFile("bin/input/reducebykey/*.txt");
JavaRDD<String> words = input.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String x) {
return Arrays.asList(x.split(" "));
}
}
);
JavaPairRDD<String, Integer> pairrdd = words.mapToPair(
new PairFunction<String, String, Integer>(){
public Tuple2<String, Integer> call(String x){
return new Tuple2(x, 1);
}
}
);
JavaPairRDD<String, Integer> output = pairrdd.reduceByKey(new Function2<Integer, Integer, Integer>(){
public Integer call(Integer x, Integer y){
return x+y;
}
});
output.saveAsTextFile("bin/output/output04");
}
}
fish
cat
cat
fish
fish
cat
cat
dog
Apache Sparkのpartitionとは何なのか
RDDは大量のデータを要素として保持する分散コレクションです。RDDは複数のマシンから構成されるクラスタ上での分散処理を前提として設計されており、内部的には__partition__という塊に分割されています。Sparkではこのpartitionが分散処理の単位となっています。RDDをpartitionごとに複数のマシンで処理することによって、単一のマシンでは処理できないデータを扱うことができます。
モチベーション
分散プログラムでは通信は非常にコストが高く、ネットワークのトラフィックを最低限に抑えることはパフォーマンスの大幅な改善につながります。
SparkのプログラムはRDDのパーティショニングを制御して通信を削減していく必要があります。
例えばSparkはkeyの集合がまとまってあるノードに現れることをプログラムで保証することができます(reduceByKey()で紹介しました)。特にパーティショニングが役立つのはデータセットが結合のようなキー操作を複数回再利用される場合に限ります。というのもSparkの操作の多くはネットワーク越しにキーに基づくシャッフルを起こします。それらはすべてパーティショニングの恩恵を受けることができます。
データのパーティショニング
JavaやScalaではpartitionerプロパティを用いてRDDのパーティショニングの方法を指定できます。ここでspark.Partitionerオブジェクトの値として、RDDに対してそれぞれのキーの行き先のパーティションを知らせるものをセットします。 reduceByKey()のように単一のRDDに対して働く操作をパーティション化されたRDD上で動作させると、各keyのすべての値は、単一マシン上でローカルに計算され、ローカルにreduce()された最終の値だけが、各ワーカーノードからマスターに戻されます(先ほど紹介しました)。 より細かく説明すると、シャッフル時に同じkeyを持つ要素を同じpartitionに振り分けるのはpartitionerの仕事で、partitionerは変換後のRDDのpartition数と振り分け対象の要素のkeyの内容をもとに、要素を振り分ける先のpartitionを決定します。Sparkではデフォルトでkeyのハッシュ値を変換後のRDDのpartition数で割ったあまりをもとに、振り分け先のpartition`を決定します。
また、二つのRDDに対して操作する場合は、事前にパーティショニングが行われていると、最低でも二つのRDDのうちの片方はシャッフルされません。
さらに、Sparkはそれぞれの操作がパーティショニングに及ぼす内部的な影響を知っているので、データパーテショニングを行う操作によって生成されるRDDに、自動的にpartitionerを設定します。
永続化
補足ですがRDDに対してパーティショニングを行い、それによって生成されたRDDを変換の対象とするのであればpersist()で永続化すべきです。理由としては、それ以降のRDDのアクションはパーティショニングで生成したRDDの系統全体を評価し直すことになるので、パーティショニング前のRDDに何度もハッシュパーティショニングが行われてしまい意味がなくなってしまいます。