しまねソフト研究開発センター(略称 ITOC)にいます、東です。
先日来、STマイクロエレクトロニクス製のマイコンボード、「Nucleo-F401RE」と、開発環境「STM32CubeIDE」を使って、mruby/c の移植などを行ってきました。
その活動の中で、Cコンパイラの最適化については触れてきませんでしたので、今回簡単なベンチマークテストを実施するとともに、結果を公開します。
使用機器・環境
STM32マイコン評価ボード STM32 Nucleo-F401RE
(https://www.st.com/ja/evaluation-tools/nucleo-f401re.html)
開発環境 STM32CubeIDE v1.15.1
(https://www.st.com/ja/development-tools/stm32cubeide.html)
Cコンパイラ
arm-none-eabi-gcc.exe (GNU Tools for STM32 12.3.rel1.20240306-1730) 12.3.1 20230626
マイコン STM32F401RET6
(https://www.stmcu.jp/stm32/stm32f4/stm32f401/12226/)
- ARM Cortex-M4
- 84MHz
- FLASH 512KB
- RAM 96KB

ベンチマークプログラム
mruby/c でハノイの塔の解法プログラムを記述し、それを実行します。ただし結果の表示は、速度に影響してしまうのでコメントアウトしています。
意図的に、配列、ハッシュ、文字列など、まんべんなく使うように記述しています。
mruby/c VM は、2024/09/07現在の master を使います。
# hanoi tower benchmark
puts "Hanoi benchmark"
def make_hanoi_data( num )
data = { :A=>[], :B=>[], :C=>[] }
num.times {
data[:A] << num
num -= 1
}
return data
end
def solve_hanoi_recursive( n, data, ta, tb, tc )
if n == 1
data[tc] << data[ta].pop()
puts_hanoi_data( "move #{ta}:#{data[tc][-1]} >#{tc}", data )
else
solve_hanoi_recursive( n-1, data, ta, tc, tb )
solve_hanoi_recursive( 1, data, ta, tb, tc )
solve_hanoi_recursive( n-1, data, tb, ta, tc )
end
return data
end
def puts_hanoi_data( s, data )
n = data[:A].size + data[:B].size + data[:C].size
fmt = "%s=%-#{n*2}s "
s << " "
data.each {|k,v|
s << sprintf( fmt, k, v.join(",") )
}
# puts s
end
def hanoi( num )
data = make_hanoi_data( num )
puts_hanoi_data( "start ", data )
result = solve_hanoi_recursive( num, data, :A, :B, :C )
end
t1 = VM.tick
10.times do
hanoi(8)
end
t2 = VM.tick
p [t1, t2, t2-t1]
実行結果
Release モードで、NDEBUG プリプロセッサ定数を定義した状態でコンパイルしています。
-O0 -DNDEBUG
5785ms
text data bss dec hex filename
111324 1832 34784 147940 241e4 mrubyc-tuto-stm32.elf
-O1 -DNDEBUG
2392ms
text data bss dec hex filename
86532 924 34788 122244 1dd84 mrubyc-tuto-stm32.elf
-O2 -DNDEBUG
2303ms
text data bss dec hex filename
85972 924 34792 121688 1db58 mrubyc-tuto-stm32.elf
-O3 -DNDEBUG
2277ms
text data bss dec hex filename
94604 924 34792 130320 1fd10 mrubyc-tuto-stm32.elf
-Os -DNDEBUG
2770ms
text data bss dec hex filename
74284 924 34788 109996 1adac mrubyc-tuto-stm32.elf
-Ofast -DNDEBUG
2276ms
text data bss dec hex filename
94356 924 34792 130072 1fc18 mrubyc-tuto-stm32.elf
実行速度比較
| 最適化 | 実行時間(ms) | -O0比 (倍) |
|---|---|---|
| -O0 | 5785 | 1.00 |
| -O1 | 2392 | 2.42 |
| -O2 | 2303 | 2.51 |
| -O3 | 2277 | 2.54 |
| -Os | 2770 | 2.09 |
| -Ofast | 2276 | 2.54 |
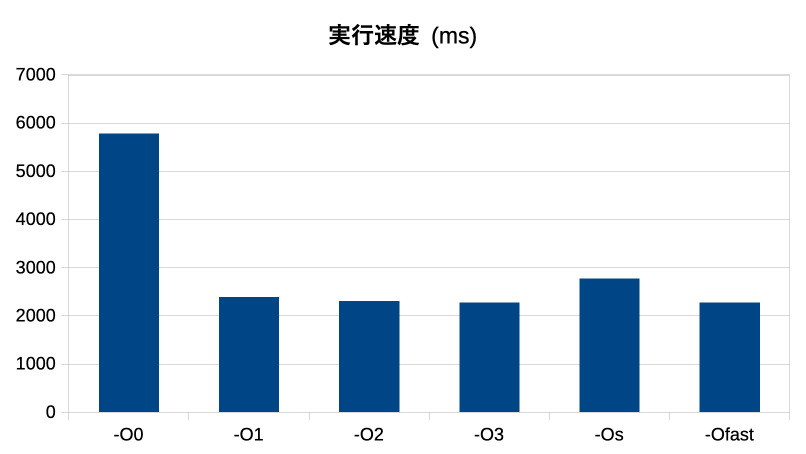
- 実行速度は、最適化をかければ、(-O0でなければ)、どのレベルでも2倍以上の速度に向上する
- -O3と-Ofast がほぼ同スコアで最速だが、その他の最適化オプションの場合と大差は無い
オブジェクトサイズ (.text) 比較
| 最適化 | サイズ(KB) | -O0比 (%) |
|---|---|---|
| -O0 | 108.7 | 100.0 |
| -O1 | 84.5 | 77.7 |
| -O2 | 84.0 | 77.2 |
| -O3 | 92.4 | 85.0 |
| -Os | 72.5 | 66.7 |
| -Ofast | 92.1 | 84.8 |

- サイズは、-Osが最小になり、3割以上縮小する
- 実行速度ベンチマークの場合ほどの大差は無い
考察
コンパイラの最適化の結果は、速度に関してはめざましい効果がありました。一方、サイズに関しては2〜3割の縮小にとどまりましたが、それでも十分といえるものでした。
速度とサイズのバランスを考えると、-O2 か -Os あたりが最もバランスが良いように思われます。
なお、コンパイラは、Thumb命令セットを生成しています。
-Os は、挙動から想像するに、かなり深い最適化をするようなので、volatile 修飾子などを丁寧に書いておかないと、動かなくなる場合がありそうです。
おまけ
PIC32MX170 (MIPS32) でも、同じベンチマークをうごかしてみました。
| MPU | Core | clock(MHz) | 最適化 | 実行時間(ms) |
|---|---|---|---|---|
| PIC32MX170F256B | MIPS | 40 | -O2 | 4437 |
| STM32F401RET6 | ARM Cortex M4 | 84 | -O2 | 2303 |
コアの種類は違いますが、ほぼクロック周波数の違いが実行速度の違いで、クロックあたりの速度はMIPSの方が少し優秀といった結果でした。
おわりに
今回は、Cコンパイラの最適化オプションを変えて、ベンチマークテストをやってみました。
プログラムは、mruby/c の VMを使って、mrubyプログラムを動かすものでしたが、測定結果は、C言語プログラムを作る時の汎用的な結果として参考になるものだと思います。