前提
2020年の12月にDeepmindからAlphaZeroの後継であるMuZeroが発表されました。DeepmindからMuZeroの概要を説明した記事があったので、翻訳してみました。ただ、自分が強化学習詳しくないので(opengymでちょっと遊んだぐらい)、わかりづらいところもあると思います。ここはこういうことだよとか、間違いとかありましたら、気軽にコメントしてください。詳しくは、元論文を読んでください。
序文
2016年には、囲碁で人間を倒す最初の人工知能プログラムであるAlphaGoを導入しました。 2年後、後継者であるAlphaZeroは、囲碁、チェス、将棋を一から習得しました。 今回は、汎用アルゴリズムの追求における重要な前進であるMuZeroについて説明します。 MuZeroは、未知の環境で勝つための戦略を計画する能力のおかげで、ルールを知らされることなく、囲碁、チェス、将棋、Atariをマスターします。
長年にわたり、研究者は、環境を説明するモデルを学習し、そのモデルを使用して最善の行動方針を計画できる方法を模索してきました。 これまで、ほとんどのアプローチは、ルールやダイナミクスが通常未知で複雑なAtariなどのドメインで効果的に計画するのに苦労していました。
2019年の予備論文で最初に紹介されたMuZeroは、計画のために環境の最も重要な側面のみに焦点を当てたモデルを学習することにより、この問題を解決します。 このモデルをAlphaZeroの強力な先読みツリー検索と組み合わせることで、MuZeroはAtariベンチマークでSOTAを達成すると同時に、Go、チェス、将棋におけるAlphaZeroのパフォーマンスと一致します。
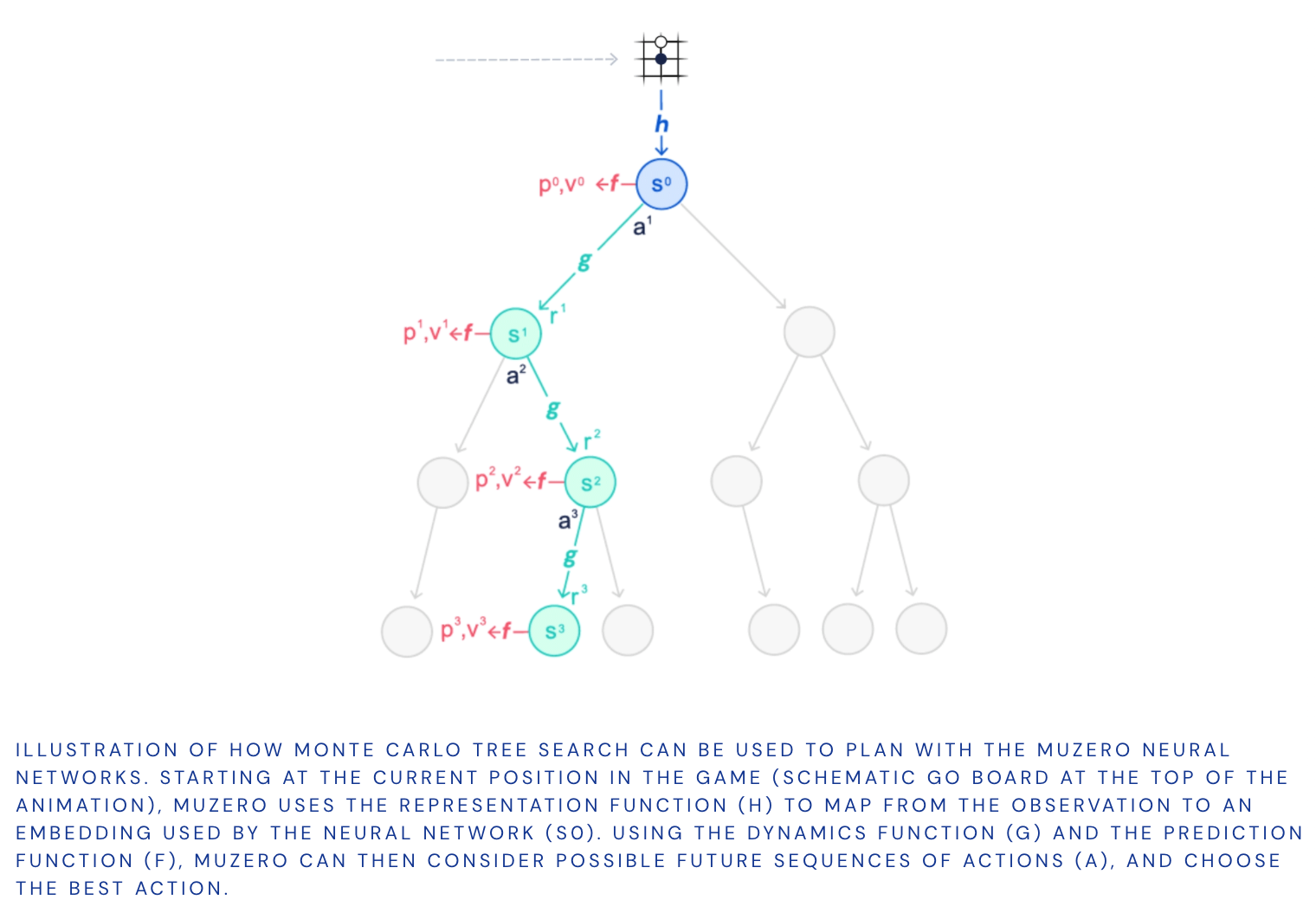
Generalising to unknown models
計画する能力は人間の知性の重要な部分であり、問題を解決し、将来について決定を下すことができます。 たとえば、暗い雲を見ると、雨が降ると予測して、出かける前に傘を持って行きます。 人間はこの能力をすばやく習得し、新しいシナリオに一般化することができます。これは、アルゴリズムにも持たせたい特性です。
研究者は、先読み検索またはモデルベースの計画という2つの主要なアプローチを使用して、AIにおけるこの主要な課題に取り組んでいます。
AlphaZeroなどの先読み検索を使用するシステムは、チェッカー、チェス、ポーカーなどの古典的なゲームで目覚ましい成功を収めていますが、ゲームのルールや正確なシミュレーターなど、環境のダイナミクスに関する知識が与えられていることに依存しています。 これにより、通常は複雑で単純なルールにまとめるのが難しい現実世界の問題にそれらを適用することが困難になります。
モデルベースのシステムは、環境のダイナミクスの正確なモデルを学習し、それを使用して計画を立てることにより、この問題に対処することを目的としています。 ただし、環境のあらゆる側面をモデル化することは複雑であるため、これらのアルゴリズムはAtariなどの視覚的に豊富なドメインで競合することができません。 これまで、Atariでの最良の結果は、DQN、R2D2、Agent57などのモデルフリーシステムからのものです。 名前が示すように、モデルフリーアルゴリズムは学習したモデルを使用せず、代わりに次に実行する最善のアクションを推定します。
MuZeroは、以前のアプローチの制限を克服するために異なるアプローチを使用します。 MuZeroは、環境全体をモデル化するのではなく、エージェントの意思決定プロセスにとって重要な側面をモデル化するだけです。 結局のところ、あなたが傘を乾いた状態に保つための方法を知ることは、空中の雨滴のパターンをモデル化するよリも役立ちます。
具体的には、MuZeroは、計画に不可欠な環境の3つの要素をモデル化します。
- value(値) 現在の位置はどれくらい良いですか?
- policy(方策) どのアクションを実行するのが最適ですか?
- reward(報酬) 最後のアクションはどれくらい良かったですか?
これらはすべてディープニューラルネットワークを使用して学習され、MuZeroが特定のアクションを実行したときに何が起こるかを理解し、それに応じて計画するために必要なすべてです。
このアプローチには、もう1つの大きな利点があります。MuZeroは、環境から新しいデータを収集するのではなく、学習したモデルを繰り返し使用して計画を改善できます。 たとえば、Atariスイートでのテストでは、このバリアント(MuZero Reanalyzeとして知られています)は、学習したモデルを90%の時間使用して、過去のエピソードで何をすべきかを再計画しました。
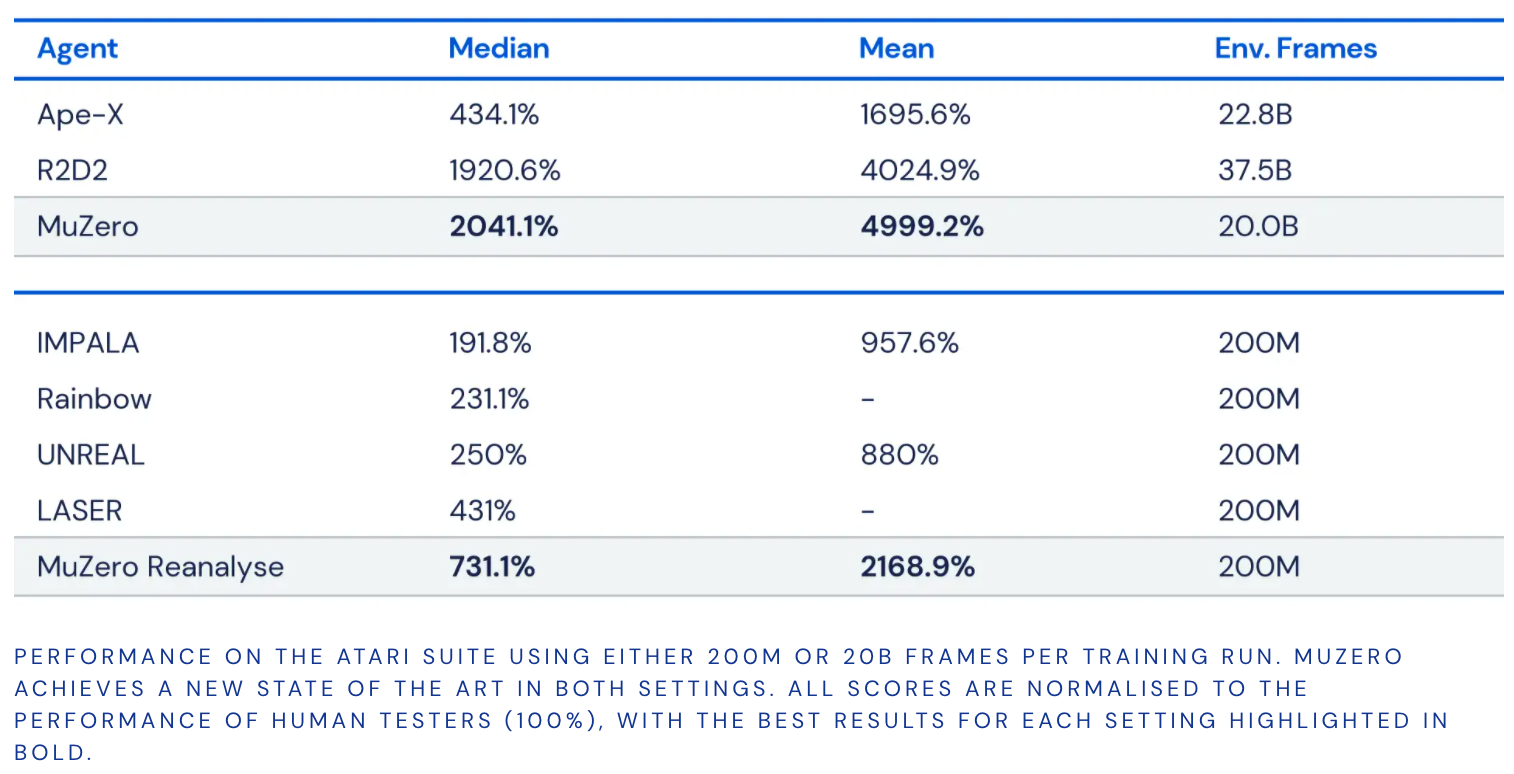
MuZero performance
MuZerosの機能をテストするために、4つの異なるドメインを選択しました。 囲碁、チェス、将棋を使用して、困難な計画の問題に対するパフォーマンスを評価しました。一方、より視覚的に複雑な問題のベンチマークとしてAtariスイートを使用しました。 すべての場合において、MuZeroは強化学習アルゴリズムのSOTAを達成し、Atariスイートの以前のすべてのアルゴリズムを上回り、囲碁、チェス、将棋でのAlphaZeroの超人的なパフォーマンスに匹敵します。
また、MuZeroが学習したモデルを使用してどれだけうまく計画できるかをテストしました。 囲碁での古典的な精密計画の課題から始めました。ここでは、1回の動きで、勝ち負けの違いを意味します。 より多くの計画を立てることでより良い結果が得られるという直感を確認するために、それぞれの動きの計画に時間をかけると、完全にトレーニングされたバージョンのMuZeroがどれだけ強くなるかを測定しました(下の左側のグラフを参照)。
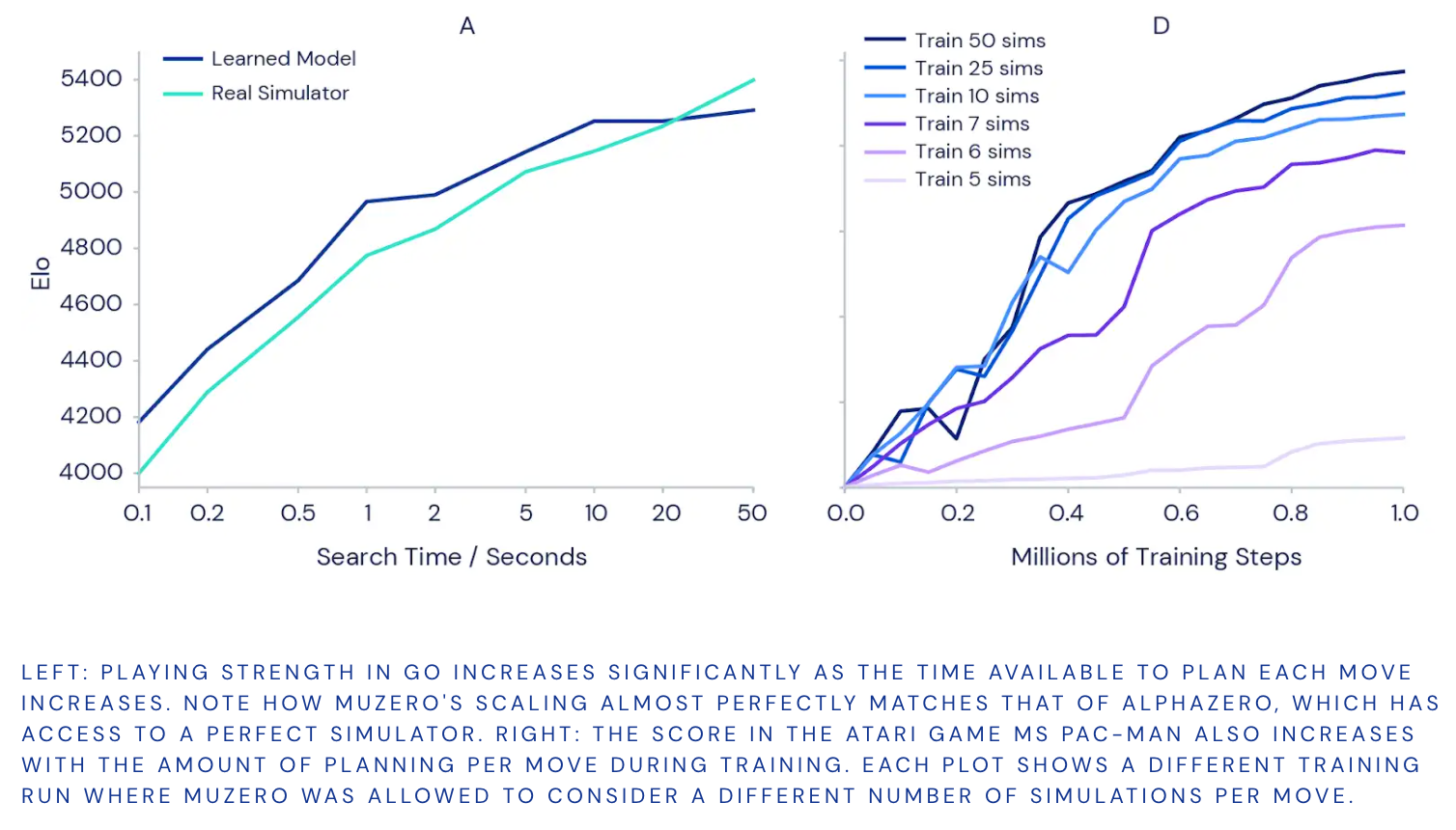
その結果、1回の移動にかかる時間を10分の1秒から50秒に増やすと、プレイの強さが1000 Elo(プレーヤーの相対的なスキルの尺度)以上増加することがわかりました。 これは、強いアマチュアプレーヤーと最強のプロプレーヤーの違いに似ています。
計画がトレーニング全体にメリットをもたらすかどうかをテストするために、MuZeroの個別のトレーニング済みインスタンスを使用して、AtariゲームのMs Pac-Man(上の右側のグラフ)で一連の実験を実行しました。 それぞれが、5から50の範囲で、移動ごとに異なる数の計画シミュレーションを検討することを許可されています。結果は、各移動の計画の量を増やすことで、MuZeroがより速く学習し、より良い最終パフォーマンスを達成できることを確認しました。
興味深いことに、MuZeroが1回の移動で6〜7回のシミュレーションしか考慮できなかった場合(ミズパックマンで利用可能なすべてのアクションをカバーするには小さすぎる数)、それでも良好なパフォーマンスを達成しました。 これは、MuZeroがアクションと状況の間で一般化できることを示唆しており、効果的に学習するためにすべての可能性を徹底的に検索する必要はありません。
New horizons
環境のモデルを学習し、それを使用して計画を成功させるMuZeroの能力は、強化学習と汎用アルゴリズムへの追求が大幅に進歩したことを示しています。 その前身であるAlphaZeroは、化学、量子物理学などのさまざまな複雑な問題にすでに適用されています。 MuZeroの強力な学習および計画アルゴリズムの背後にあるアイデアは、「ゲームのルール」が知られていないロボット工学、産業システム、およびその他の厄介な現実世界の環境における新しい課題に取り組むための道を開くかもしれません。
感想
強化学習は汎化が難しそうというイメージでしたが、少しづつ進歩していることがわかりました。MuZeroはyoutubeの動画の圧縮とかにも使われ始めているそうですね。2021年は強化学習とTransformerをちゃんと理解しようと思います。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。