はじめに
今更ながらですが、ビットコインの価格をディープラーニングを用いて予測しようと思います。また、対象にビットコインを選択したのは以下の理由です。
- マーケットデータが安価に手に入ること(例えば、株価を予測しようとすると、株価だけではなく他の情報も必要となります。その情報はBloombergなどの情報ベンダから買う必要があります)
- ファンダメンタルズ等の価格以外の情報が少ないこと(センチメントなどの情報は必要だと思いますが、一応今回の予測では対象に含めない予定です)
- 話題性があること(いい意味でも、悪い意味でも)
この投稿ではまずはデータの取得から始めたいと思います。
目次
- ティックデータの取得
- ティックデータの1分毎の終値への変換
1.ティックデータの取得
JPYBTCのヒストリカルデータ(1分毎)は簡単に手に入るだろうと思っていましたが、そう簡単にはいきませんでした。そもそも過去の情報を提供していなかったり、過去の情報が取得できるAPIを提供している取引所でも、実際に取得できるのは日次などの間隔が大きい場合がほとんどです。
また、cryptowatchは1分毎のデータが実際に取得できるのですが、チャートに見えている以上過去のデータは取得できないらしく、1週間前のものは取得できません。
データが1週間もないとなるとかなり問題で、オーバーフィッティングしてしまう可能性もありますし、そもそものデータの信頼性の問題もあります。
そこで、以下のサイトで過去からの膨大なティックデータを発見したので、それを処理して1分毎のデータに変換することを考えます。
2. ティックデータの1分毎の終値への変換
以下のコードによりティックデータから1分毎の終値のデータを生成します。期間を2月からとしているのは、2月以前はかなり不安定な動きをしていたので、とりあえずは省いています。
import pandas as pd
from datetime import datetime, timedelta
filename = 'bitflyerJPY.csv'
header = ['timestamp', 'price', 'volume']
df = pd.read_csv(filename, names = header)
df = df.drop(['volume'], axis=1)
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s')
df_2 = pd.DataFrame()
start_date = datetime(2018, 2, 1)
n_date = 30
for i in (start_date + timedelta(minutes = x) for x in range(60 * 24 * n_date)):
df_2 = df_2.append(df.loc[(df['timestamp'] > i).idxmax()], ignore_index=True)
df_2.iat[-1, 1] = i
df_2 = df_2.set_index('timestamp')
df_2.to_csv('bitflyerJPY_2.csv', index=True)
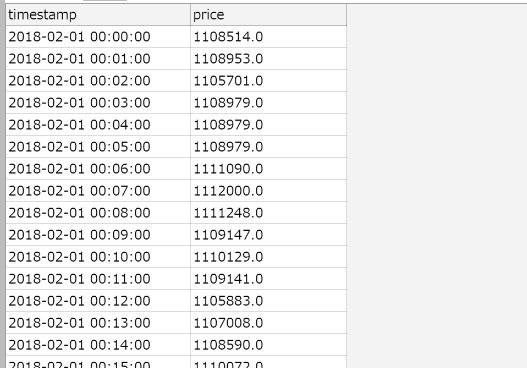
上記のプログラムを実行後、4時間くらいで(もっと効率の良い書き方があれば教えてください)
以下のように1分ごとの終値を取得することができました。
以上です。