これは 日本情報クリエイト Engineer's Advent Calendar 2017 の1日目の記事です。
Merry Christmas! 🎅
はじめに
目的
複雑な話は無しにして、
Microsoft Azure Machine Learning Studio(以下、ML Studio)を一通り
- 学習・テストデータ作成
- 学習フローの作成
- 学習
- 予測
- 学習モデルの性能評価
- 予測データの利用
体験すること。
きっかけ
ML Studio を知ったのはつい最近のことです。
チュートリアルや他の方が書かれた記事を読み、こう感じました。
「なんだこれ、楽しそう!」
嗚呼、使ってみたい
ML系のサービスを試したいときに困るのが、大量の学習データの用意です。
Web上のどこからか引っ張ってきたり、予め用意されている サンプルデータ を使用したり。
いろいろ方法はありますが、やっぱり自分でデータを作って弄って試してみたい。と思うものです。
何をするのか①
そこで今回は、例えば株価のような時系列データを手元で生成し、
それを ML Studio に食べさせてみたいと思います。
言わずもがな、時系列データは、画像や文章に比べて圧倒的に生成しやすいです。
如何ようにもできちゃいます。
今回は手軽さを重視して、そんな時系列データを対象にしました。
何をするのか②
詳しく後述しますが、10000個の値を持つ時系列データを用意します。
10000日分の株価だと思ってもらえれば、想像に易いかと思います。
そして、**「今日を含む過去20日間の株価から、翌日の株価を予測する」**ことにします。
例えば、「1~20日目の株価を見て、21日目の株価を予測する」という感じです。
おことわり
ML Studio を一通り使ってみることに重きを置いた記事です。
そのため、データ生成や疑似トレードのソースコードは割愛しています。
やっていることは非常に簡単ですので、お好きなプログラム言語1で再現できるはずです。
本質的な部分は、文章で説明しています。
また、筆者は実際の株トレードなどに関してはズブの素人ですので、
言葉の使い方など誤りがあるかもしれません。
それぞれの単語に、深い意味や厳密性は持たせていませんので、ご了承ください。
イメージだけ伝わればOKです。
時系列データの準備
学習・テストに使用する時系列データは、
振幅と周期をランダムに変化させた正弦波に、ノイズを加えたものとします。
今回は実験なので確率的に異なるものを、手元でいくらでもサンプリングできるようにしておきます。
10000個の値からなる時系列データを、学習用・テスト用の2種類用意しました。
-
学習データ
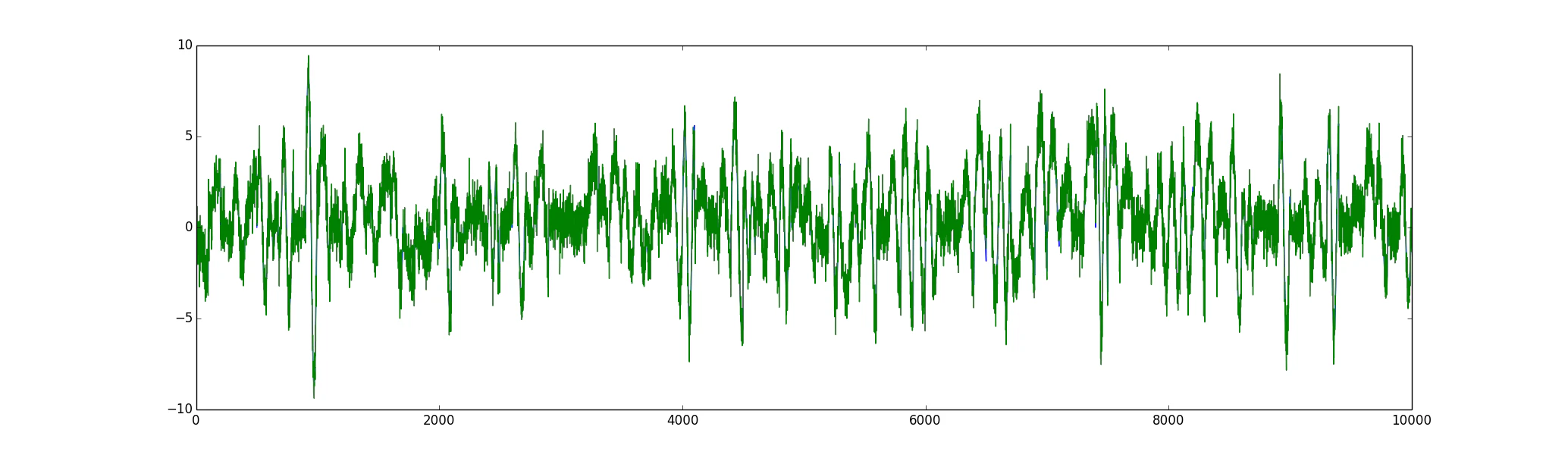
-
テストデータ
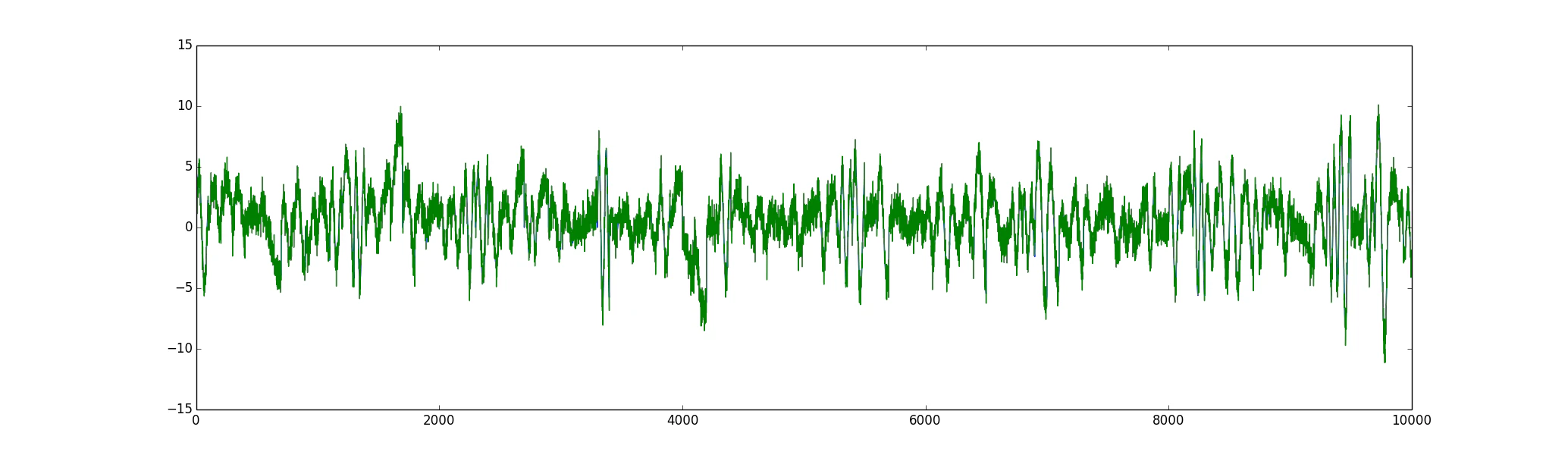
上の2種類のデータは、同じ生成モデルからサンプリングしているので、
値は違えど似たような特徴を有しているはずです。
ML Studio に渡す学習・テストデータは、このグラフのような値そのままでありません。
先述のとおり、
過去20日分+予測したい1日分 = 21個の値 を1行として、
1日目から9980日目まで1日ずつシフトして切り取った9980行のCSVデータ2を用います。
ML Studio を使用した時系列データの学習
では、前準備ができましたので、いよいよ ML Studio を触っていきましょう。
Azure のサブスクリプションは準備できている前提とします。
Machine Learning Studio ワークスペースの作成
素直に追加します。名前も一旦は適当で。
実験用なので、価格・プランも一番低廉なもので問題ありません。
プラン、ワークスペース、ストレージの3つが作成されています。
今回は、ワークスペースのみ使用します。

ML Studio の起動
作成したワークスペースを開くと、次のような画面が出てきます。
**「Machine Learning Studio の起動」**をクリックすると、文字通り、起動します。
分かりやすいですね。
今回は0から実験したいので、「Blank Experiment」を追加しましょう。
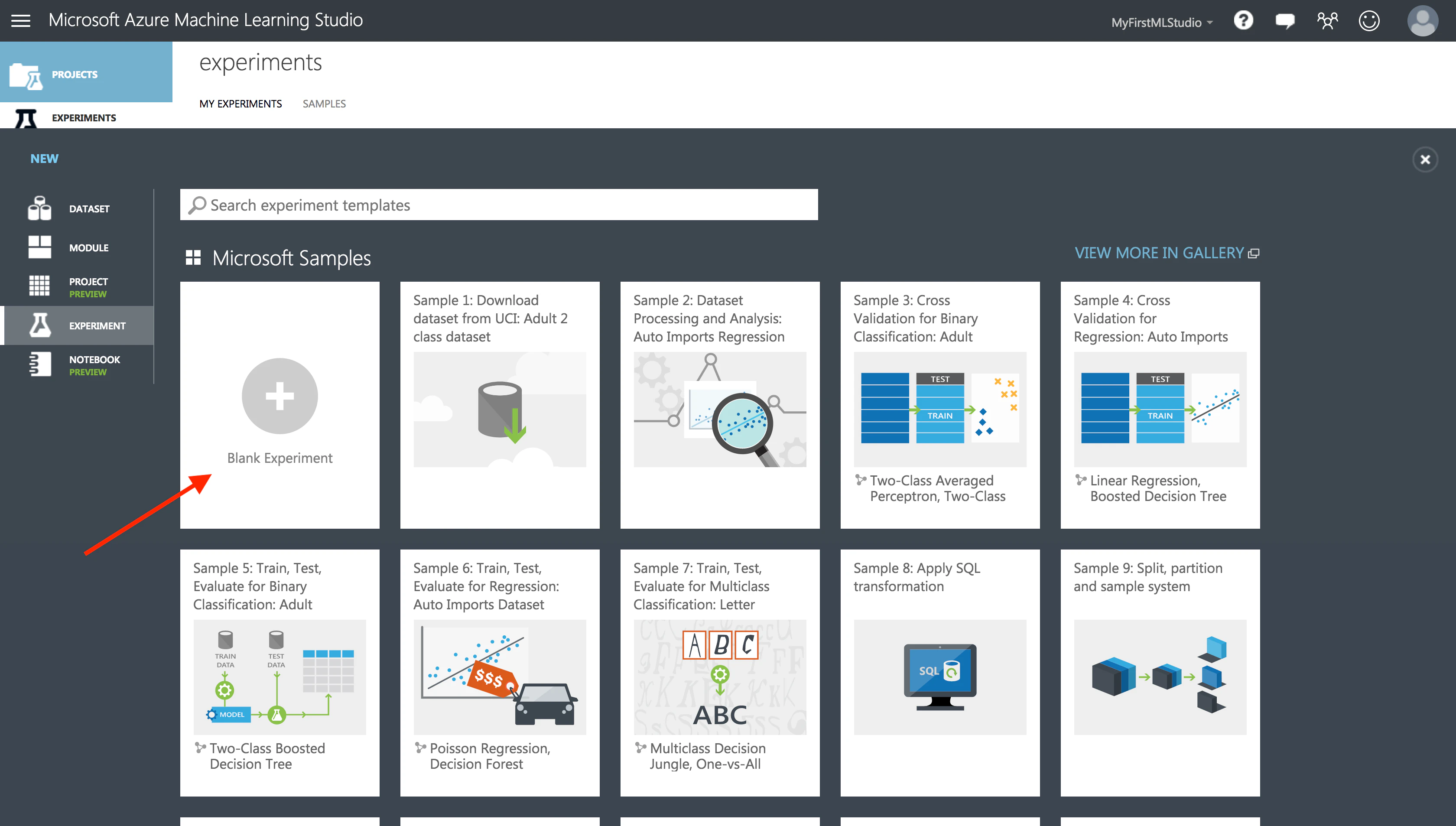
お、なんだか楽しそうな画面が出てきましたね!わくわくします。
データセットの追加
先ほど作成した時系列データを ML Studio 上では、データセットという概念として扱います。
データセットに、学習データ、テストデータを追加してみましょう。
CSVファイルをアップロードするだけです。簡単ですね。
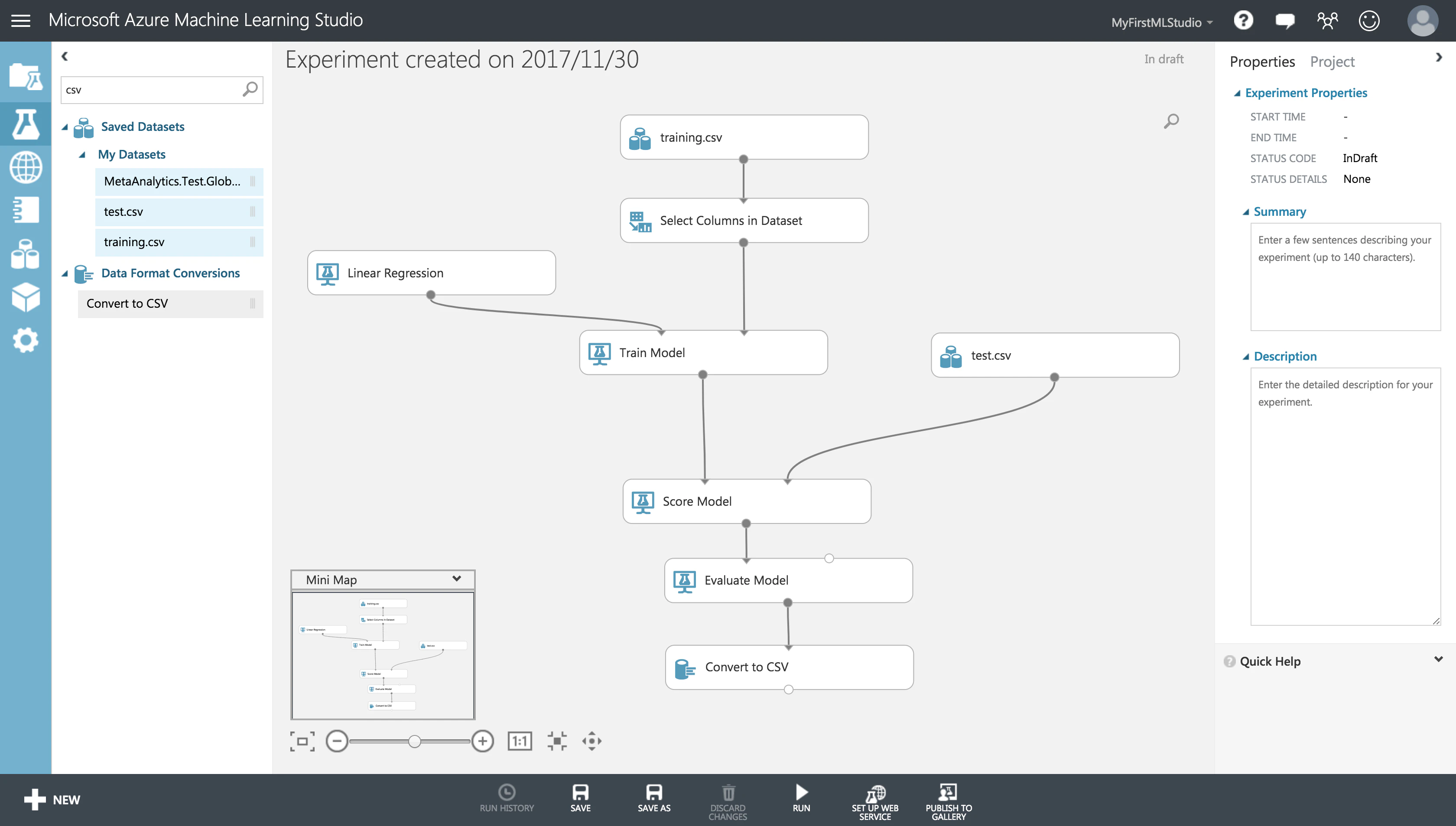
学習フローの定義
まずは、何より学習データをセット
先ほど追加したデータセットを、ドラッグ&ドロップで配置します。
GUIでできちゃうなんて素敵。
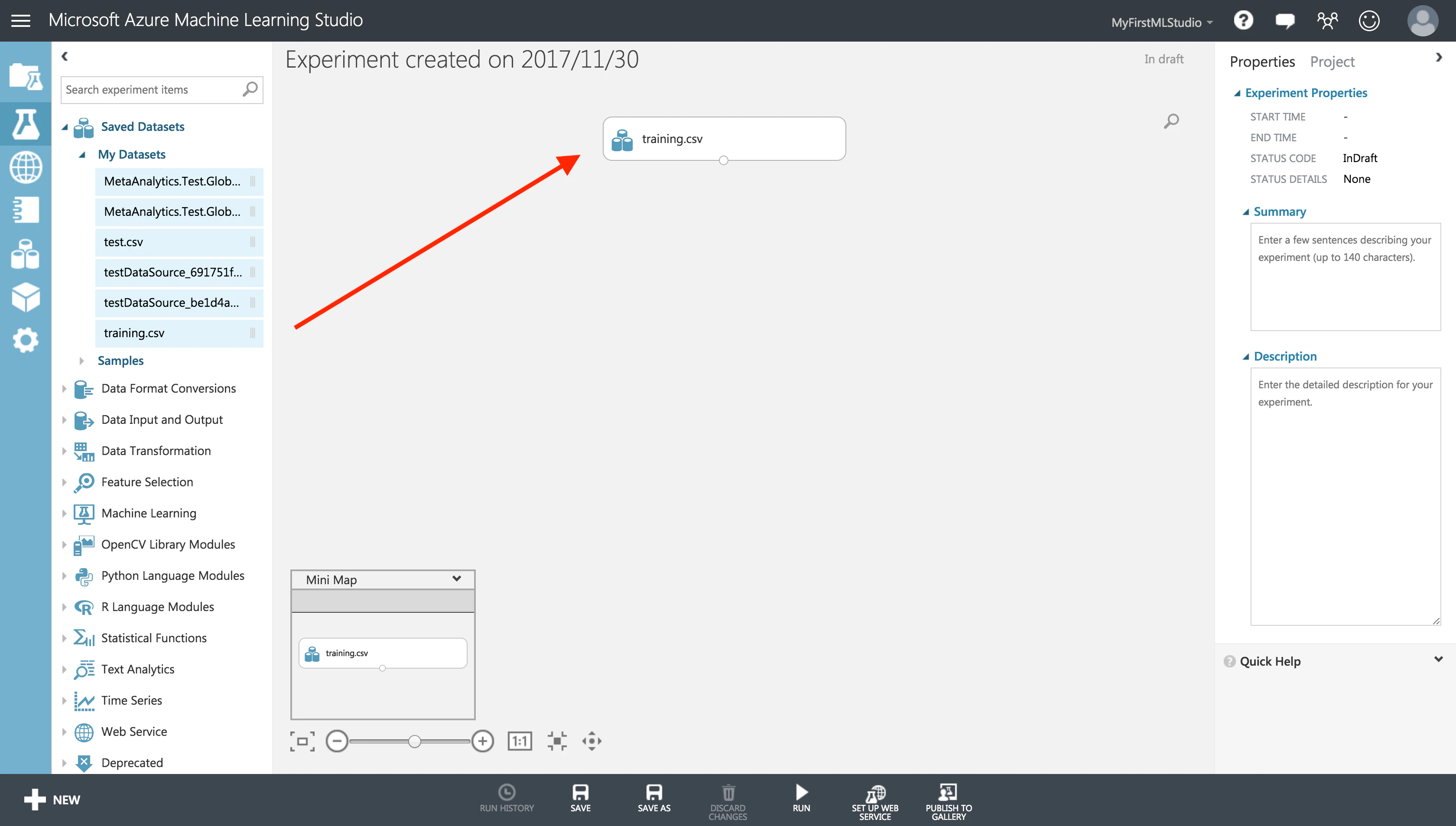
データセットの中身を確認することもできます。
ちゃんと、col0, col1, col2... のデータがあるようです。
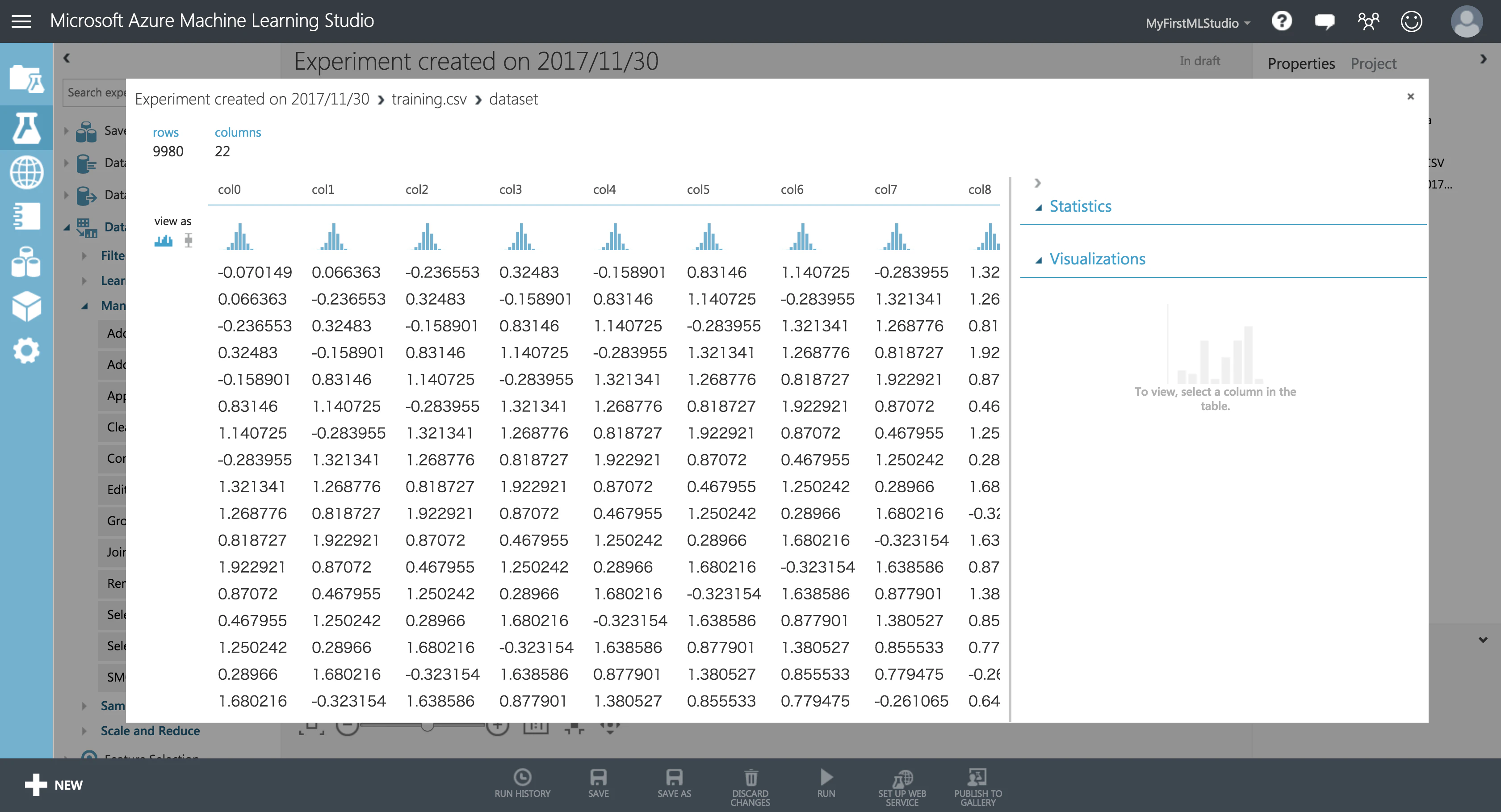
あれっ!!??
過去20日分のデータをもとに、翌日1日分の値を予測するので、
カラムは col0 ~ col20 までの21列になるはずが…。
プログラムのミスで、col21 という空カラムができてしまっているようです…!
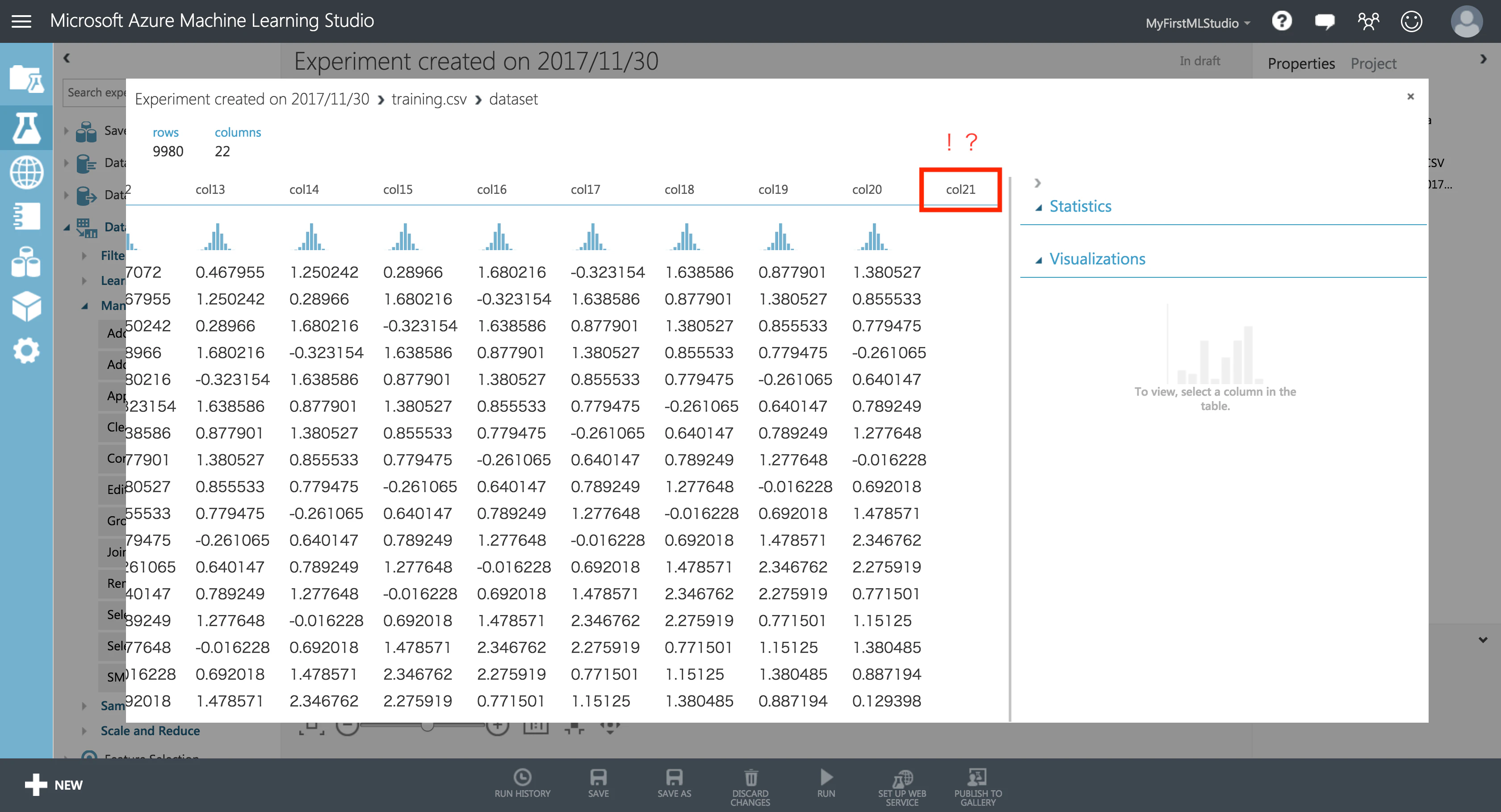
必要なデータを選ぶ
データセットの中に、不要なデータが混じるケースは往々にしてあります。
そんなときは慌てずに、モジュール**「Select Columns in Dataset」**を使いましょう。
データセット「training.csv」を「Select Columns in Dataset」に流し込みます。
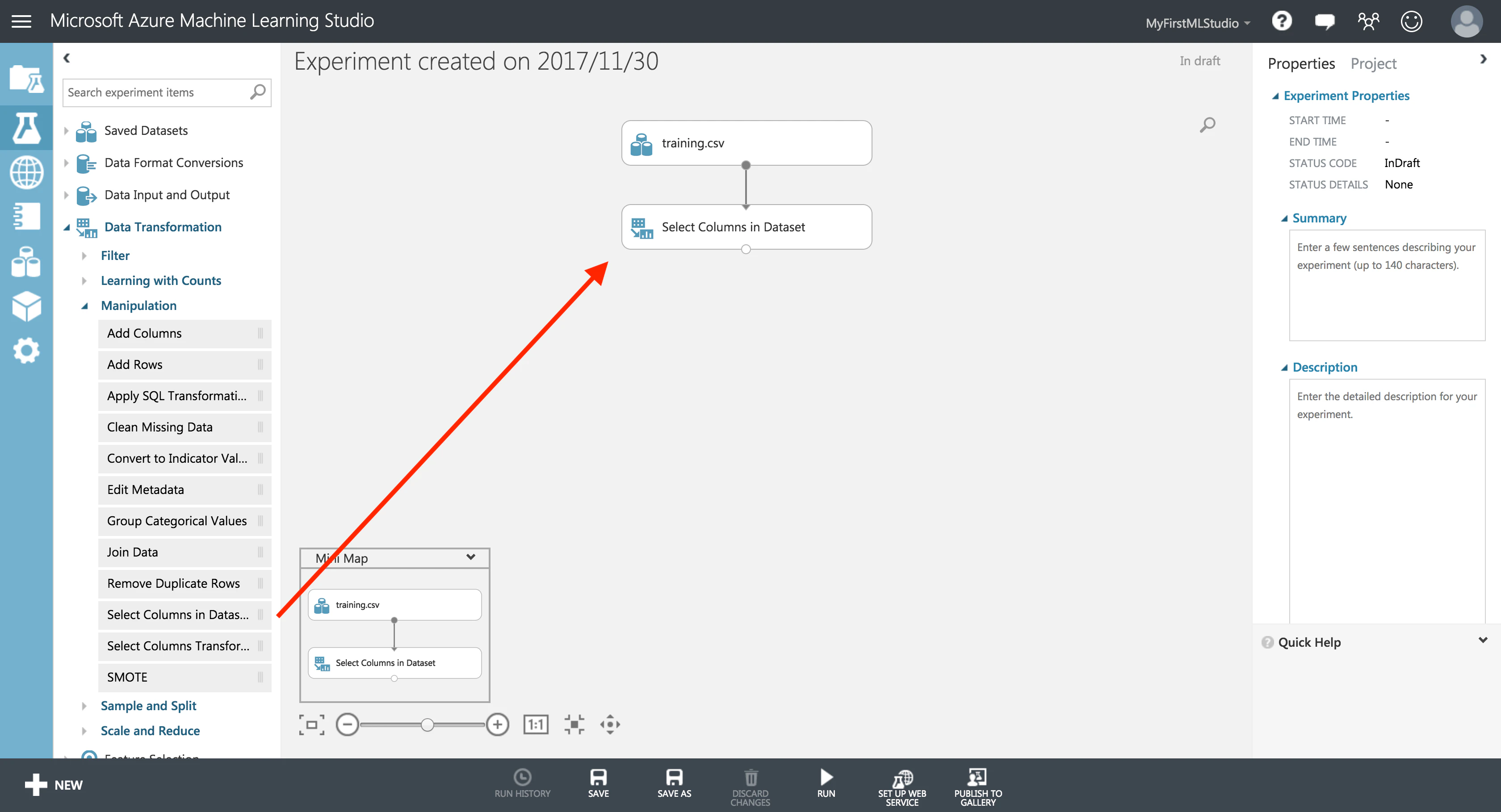
モジュールを選択すると、画面右部の Properties からそのモジュールの詳細を設定できます。
モジュール「Select Columns in Dataset」では、学習に使用するカラムを指定できます。
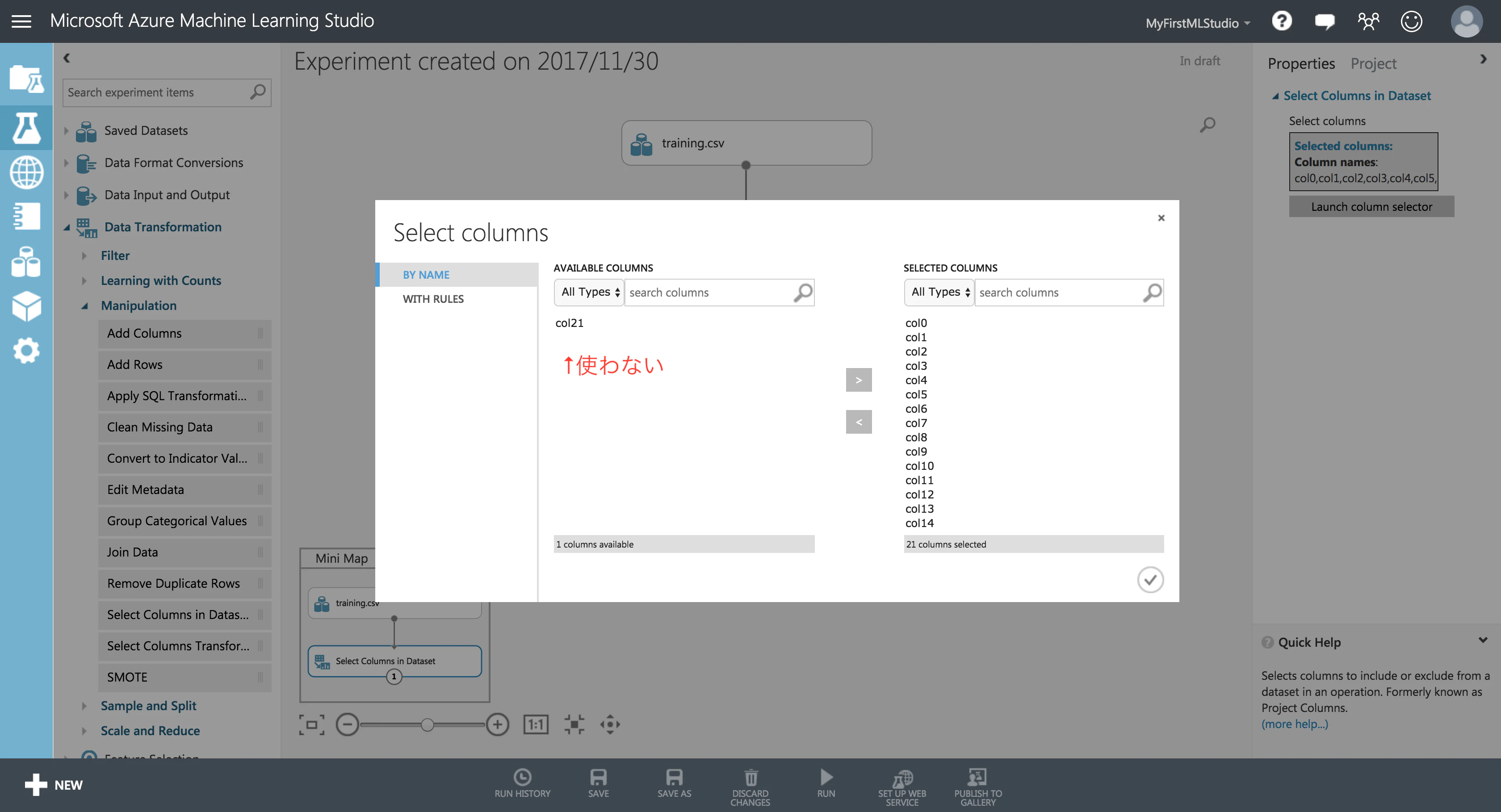
これで、学習に必要なデータの整備ができました。
学習フェーズの定義
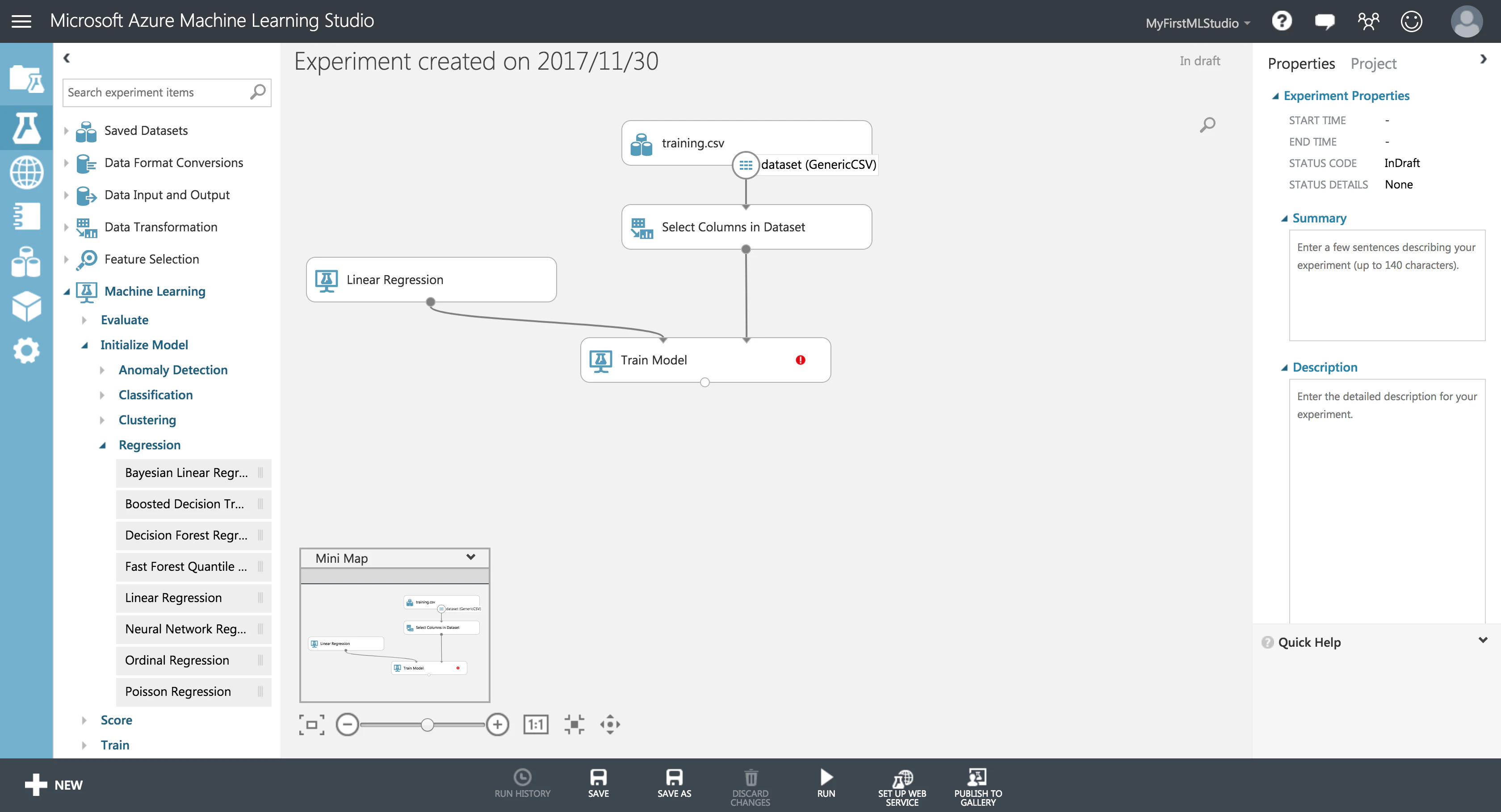
さて、いよいよ学習モジュールの追加です。といっても、呆気ないほど簡単です。
学習を行うモジュール**「Train Model」**を追加し、学習に使用するアルゴリズムを他モジュールから入力する形で指定します。
アルゴリズムも多数用意されていますが、今回は何も考えずに Linear Regression(線形回帰)を使ってみましょう。3
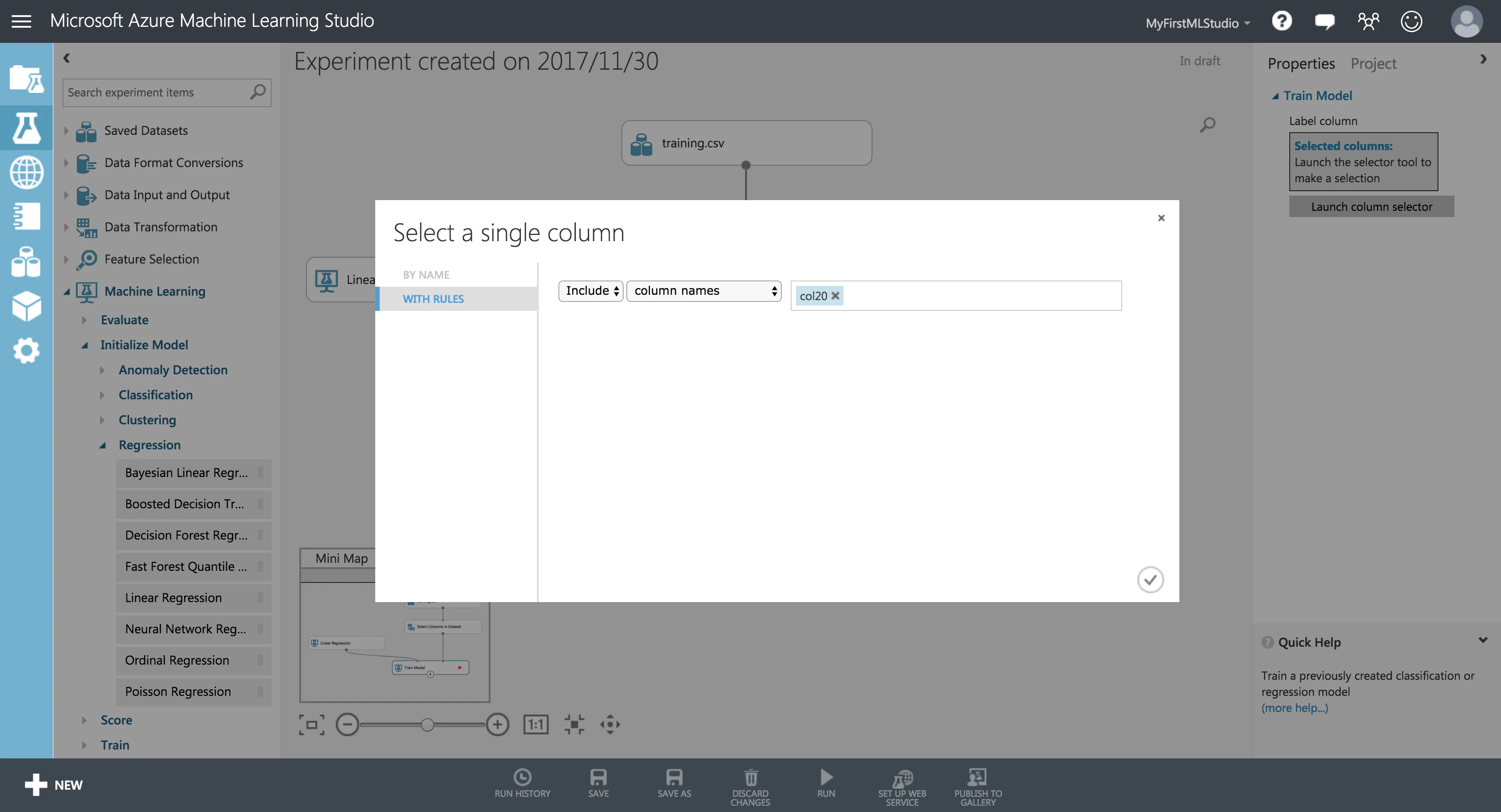
「Train Model」で、予測したい値(カラム)を指定します。
ここでは、21日目の値を予測したいので、21列目(col20)がこれに該当します。
予測フェーズの定義
モジュール「Train Model」で学習したモデルを使用して、未知のデータを予測してみましょう。
予測にはモジュール**「Score Model」**を使用します。
予測に使用するモデルを「Train Model」から入力し、
予測したい未知のデータをデータセット「test.csv」から入力します。
予測後、「どれくらい上手に予測できたのか」を評価したいので、
モジュール**「Evaluate Model」**に「Score Model」の出力を渡しておきます。
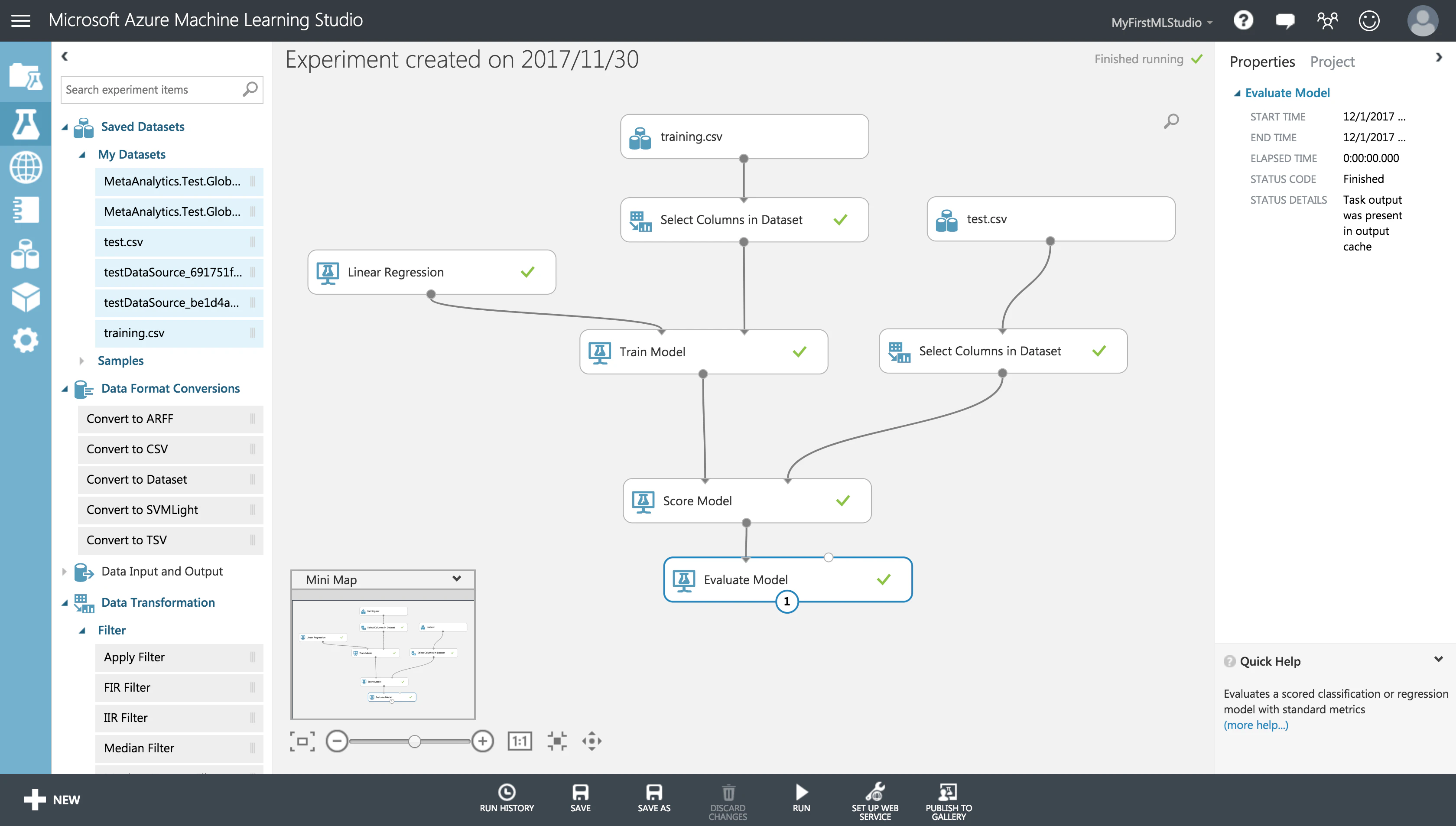
さあ、学習&予測を走らせよう!
画面下部の**「Run」**をクリックします。え?これだけ? …これだけです。
学習フローの上から順に実行されていきます。完了したモジュールに付くグリーンのチェックがかっこいい。
学習データのサイズは 9980行×21列 でしたが、数秒でフローが完了しました。速い。
実は、1つ前の画像が、処理を走らせた直後の様子でした。
予測がどれくらいうまくいったのか、**「Evaluate Model」**を可視化してみましょう。
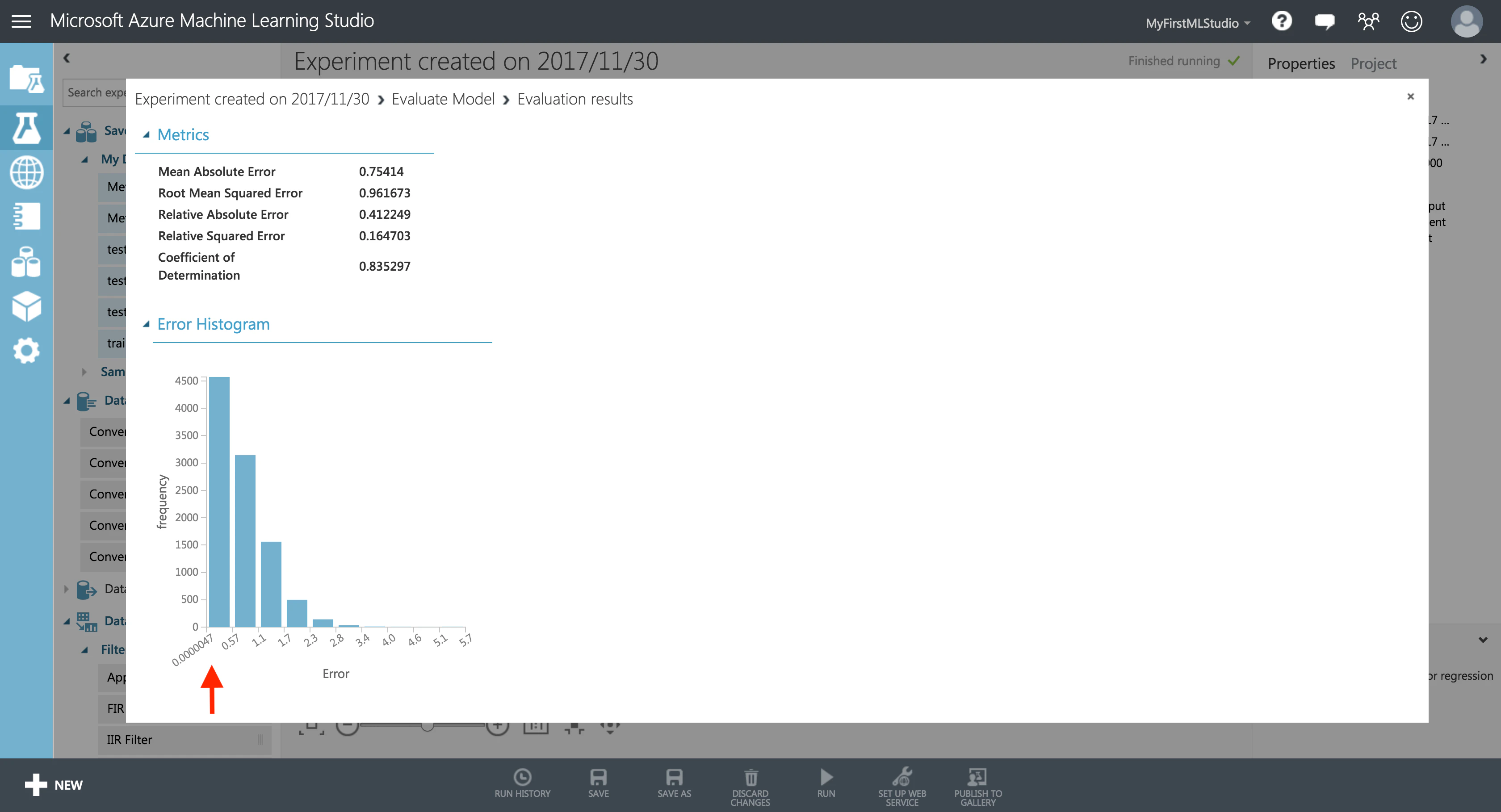
Error Histgram が視覚的に分かりやすいですね。
Error(誤差)が 0.0000047 以下のデータが再瀕ですね。
これは期待できます。
予測したデータを使用して、疑似トレード(シミュレーション)を行いたいので、
モジュール「Score Model」の結果をCSVファイルに出力してみましょう。
**「Convert to CSV」**という分かりやすい名前のモジュールがあるので、これに「Score Model」の結果をびよーんと流し込みます。
あとは、「Convert to CSV」を右クリック → Download でCSVファイルを取得できます。
AIトレーダー vs 無垢トレーダー
テストデータを対象に、トレードをシミュレートしてみましょう。
ルールは簡単です。
- 翌日の値が「上がる」と予測したら今日「買う」
- 儲け = 実際の翌日の値 - 買った時の値
- 儲けを最大化したい
2名のトレーダーに戦略を与えて、トレードしてもらいましょう。
9980回の長丁場です!がんばって!!
AIトレーダー

戦略
ML Studio で学習して得られた、予測データに従う。
予測データから、今日の値 < 翌日の値 と分かれば買う。
結果
- 勝率:71.91%
- 儲け:+2740.34
無垢トレーダー

戦略
翌日の値が上がるかどうかを $ \frac{1}{2} $ の確率でランダムに決める。神頼み戦法。
丁と出れば買うし、半と出れば買わない。
結果
- 勝率:49.50%
- 儲け:-0.69
まとめと感想
これまで、機械学習の数理的背景ばかりを追っていたので、
最新のMLサービスの使い勝手の簡単さには目からウロコでした。
まだ、GUIで操作する部分にしか触れていません。これだけでも十分に遊べると思いますが、
自分でコードを書いてより柔軟なモデルを作成することもできるようです。
ちょっとずつ掘ってみたいですね。
そして、言葉は悪いですが、すごく適当に何も考えずに構成した学習フローでしたが、
AIトレーダーの結果を見て分かる通り、予測データを用いると有意に高い勝率を叩き出しています。
現実世界のトレードでも、全く同じ手法が通用するかと問われれば、それは否です。
実際は、背後にさまざまな要因を隠した時系列データであるためです。
今回使用したデータは、ただ正弦波にノイズを加えた程度の簡単なデータであることをご留意ください。
ただ、MLは正弦波の上がり下がりのパターンや、ノイズの特徴を何かしら見つけたのだと考えます。
それが、勝率 71.91% という結果に現れています。
学習データさえ用意できれば、数分で学習と予測ができてしまいます。
この手軽さを少しでも感じていただけたなら、
Advent Calendar 1日目の記事としてお役目を果たせたと思います。
ぜひ皆さんも、遊んでみてください。ではでは。