Text to Speechに日本語をPOSTするのに結構苦労したのですが、出来た後にまとめると内容って結構単純なんですよねw
この文書ではText to Speechの送信バリエーションとそこから分かったAPIリファレンスの読み解き方とハマりポイントなど紹介します。
私の実行環境はWindows7 64bitでコマンドプロンプトなのですが、コマンドプロンプトならではの苦労もありました。。。
Text to Speech の送信バリエーション
英語でHello Worldと喋るoggファイルを生成する。(GET)
curl -u "{username}:{password}" -o "en_get.ogg" "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?text=HelloWorld"
これはAIPリファレンスにあるサンプルのままです。動くサンプルが提供されている事は嬉しいですね。?text=で喋らせたい文字をURLエンコードした状態で渡します。
Windowsだと標準で
.oggは再生できないので、まず音が鳴らない!って事からハマリました
英語でHello Worldと喋るwavファイルを生成する。(GET)
curl -u "{username}:{password}" -o "en_get.wav" "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?text=HelloWorld&accept=audio/wav"
上のと比べてaccept=で音声ファイルの形式を指定しています。それに合わせて生成ファイルの拡張子も.wavに変えます。
英語でHello Worldと喋るoggファイルを生成する。(POST)
curl -X POST -u "{username}:{password}" -o "en_post.ogg" -H "content-type:application/json" -d "{\"text\":\"HelloWorld\"}" "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize"
これもAPIリファレンスのサンプル通りです。-Hでjson文字を送ることをヘッダーに明示した上で-dbodyに喋らせたい文字をjson(text:)で書きます。
英語でHello Worldと喋るwavファイルを生成する。(POST)
curl -X POST -u "{username}:{password}" -o "en_post.wav" -H "content-type:application/json" -d "{\"text\":\"HelloWorld\"}" "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?accept=audio/wav"
コレがミソで、POST要求の場合でも全ての引数がbodyのjson文字列に入るわけではなく、音声形式はquery(?accept=)で指定します。これを知るにはAPI explorerの方を活用します(後述)。
ややしばらく{"text":"hello", "accept"="audio/wev"}など間違ったjson文字列書いてハマリました
日本語で「こんにちわ わとそんはくし」と喋るoggファイルを生成する。(GET)
curl -u "{username}:{password}" -o "ja_get.ogg" "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?voice=ja-JP_EmiVoice&text=%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF%E3%80%81%E3%83%AF%E3%83%88%E3%82%BD%E3%83%B3%E5%8D%9A%E5%A3%AB%22"
日本語化は上記の応用で、voice=ja-JP_EmiVoiceをquery(URL)に追加します。GET要求なので喋らせたい文字はURLエンコードします。
日本語で「えいちいーえるえるおー・・・」と喋るwavファイルを生成する。(POST)
curl -X POST -u "{username}:{password}" -o "ja_post.wav" -H "content-type:application/json" -d "{\"text\":\"HelloWorld\"}" "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?voice=ja-JP_EmiVoice&accept=audio/wav"
これも上記の応用。bodyでtext:を、queryでvoice=とaccept=を指定します。
今のWatson君の日本語音声は英語が読めない様ですねw Helloも読めないなんて私より酷いです
日本語で「こんにちわ わとそんはくし」と喋るwavファイルを生成する。(POST)
curl -X POST -u "{username}:{password}" -o "ja_post.wav" -H "content-type:application/json" --data-binary @input.txt "https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?voice=ja-JP_EmiVoice&accept=audio/wav"
windowsのコマンドプロンプトの場合、BOM無しUTF-8でファイルを作り--data-binaryで指定なければなりません。コマンドプロンプト上の文字はcp932で送られてエラーになります。Linux系なら自然に-dで日本語書けばOKだと思います。
input.txtの中身は{"text":"こんにちは、ワトソン博士"}で、途中で改行してはダメです。
この文字コード問題でたっっぷりハマリました。しかもファイル化したらエディタがBOM付きUTF-8になってて、UTF-8でもダメかよ!?って
Text to Speechでは音声データを返しますが、エラー応答の場合json文字列を返す事に注意が必要です。プログラムからAPIを呼ぶ時は「まず応答データがjson文字か判断し、そうでなければ音声データである」といったコーディングが必要でしょう。下記はエラー応答の例です。
"code_description": "Bad Request",
"code": 400,
"error": "UnicodeDecodeError: request body does not contain legal UTF-8. 'utf8' codec can't decode byte 0x82 in position 9: invalid start byte"
} ```
# Speech to Text
Speech to Textは人が喋ってる言葉をリアルタイムにテキスト化するのが主目的なので、sessionを結んでストリーム処理するAPIが多数あります。ここでは音声wavファイルをテキスト化するのでsessionlessのrecognizeメソッドを使用します。
## 日本語の音声wavファイルをテキスト化する。(POST)
```curl -X POST -u "{username}:{password}" -H "content-type: audio/wav" --data-binary @ja_post.wav "https://stream.watsonplatform.net/speech-to-text/api/v1/recognize?model=ja-JP_BroadbandModel" -o ja_post_wav.txt```
Text to Speechで作った音声ファイルをテキストに逆変換してみました。```-H```で音声形式を、```model=```で認識言語をしていします。応答はUTF-8のjson文字列なのでWindowsコマンドプロンプトでは文字化けてしまうので```-o```でファイルに出力します。
>Text to SpeechでたっぷりハマったのでSpeech to Textの要求は比較的簡単に構築できました :smile:
試しに変換した文字と音声をBoxで公開してみました。参照にはBoxのIDが必要となりますが、アカウントは無料で作ることができます。
https://ibm.box.com/hyamazak-qiita
「昔々ある処に、お爺さんとお婆さんが・・・」
# bluemix Watson REST APIの読み解き方
## API ReferenceとAPI explorerを並べて見る。
WatsonサービスのドキュメントはいずれもAPI ReferenceとAPI explorerのペアが提供されています。読み解く際は両方とも並べて見る事をお勧めします。
例えばText to Speechの場合、

(新しいタブで開いて下さい)
API Reference: http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/text-to-speech/api/v1/#synthesize
API explorer: http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/text-to-speech
APIリファレンスの嬉しい所は、右側にcurl,node.js,Javaでのコードサンプルが提供される事です。まずはこのままコピペして疎通確認するのがはじめの一歩ですね。上記で書いたバリエーションの2つはここのサンプルのままです。
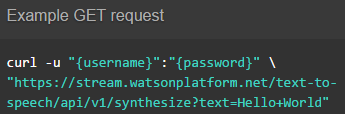
APIリファレンスを見ると、Synthesizeメソッにはtext,voice,acceptの3つが有ることが分かりますが、どう引数を設定するのか分かりません。ここで私はPOSTのbodyにacceptやvoiceを追記してハマった訳です。

## API explorerでParameter Typeを把握する
そこでAPI explorerの方を見ると、GETとPOSTでそれぞれ詳細な情報が見られます。
英語で一瞬圧倒されるのですが、引数は中段のParametersです。
そこの右側を見るとParameter TypeとData Typeがあります、ココが重要。
これでvoiceとacceptはquery(URL)で渡す事が分かるわけです。

これを踏まえた上でSpeech to Textを見ると、音声形式、言語モデル、音声ファイルがそれぞれheader,query,bodyに設定する事が分かるわけです。

API explorerはWatsonの全てのサービスのAPIを一覧できるので他のAPIと比較する事もAPIを読み解く参考になります。
日本語を扱う場合、追加のパラメータが必要で、そのパラメータの使用サンプルは提供さいないのが普通なので、APIを読み解くには推理力も試されるなぁと思う今日この頃ですw