はじめに
ファイル名のバグが起こるようなケースに対処したい.


同じ日本語記載のファイル名でも,文字コードがutf-8かshift-jisかでは全く別物.ファイル名を表示するUIが頭よく解釈してくれるおかげで,普段は頭を使わず作業ができるものの,pythonでその処理が必要となった場合,文字コードの混交(扱うファイルによって文字コードが異なる状況)は非常に厄介となる.
というわけで,今回はそれぞれの文字コードの表示や変換を理解しつつ,最終的にはshift-jisの日本語ファイル名を,python3のデフォルトであるutf-8に変換することを目指す.
想定は3系です.3系です(文字コード関連なので大事).
本記事の文字コード関連で必要な知識は,ほとんどは公式サイト(引用含む),一部このサイトから得たものです.
「傷口に貼るアレ」の呼び方で例える文字コード
「傷口に貼るアレ」の画像をいらすとやからダウンロードした.この呼び名は地域によって(?)異なるらしい.本記事では,それら呼び名の関係を下記のように扱うことにする.
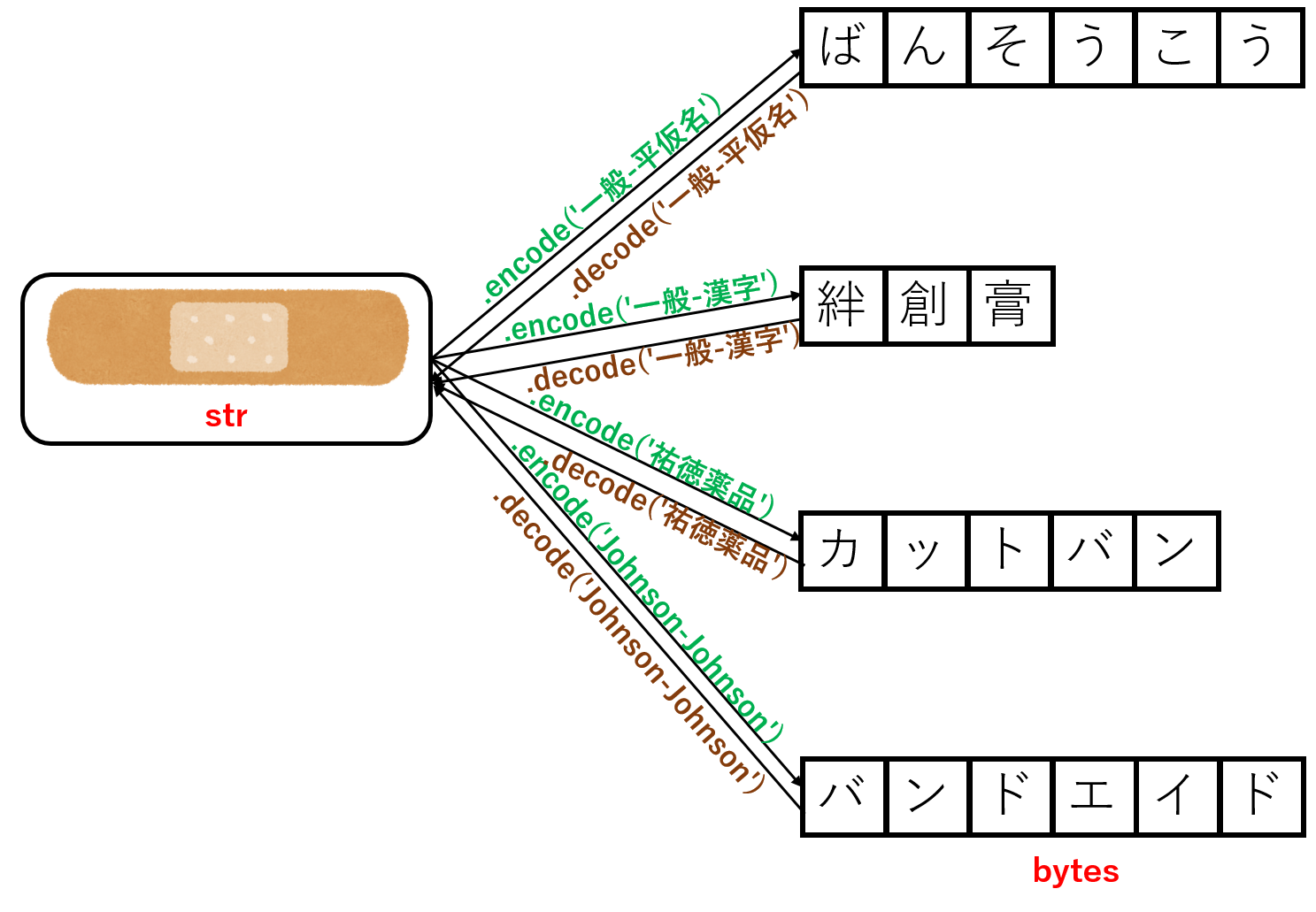
『絆創膏(ばんそうこう)』という呼び名は大辞林に掲載される普通名詞であり,一方で『カットバン(祐徳薬品工業株式会社)』や『バンドエイド(ジョンソン・エンド・ジョンソン株式会社)』といった呼び名はそれぞれ商品名である.販売会社によって性能や材質の差異があることは承知している(比較したことはない)が,本記事では,簡単のために,これらの呼び名がすべて同一の「傷口に貼るアレ」を指す単語であると想定する.
言い換えると,「傷口に貼るアレ」は,図中の4種類の言語化規則(文字コード)によって固有の〈呼び名(商品名)や表記〉で表される.この言語化規則を適用して〈対象(アレ)〉を翻訳することを,エンコード(encode)と呼ぶ.
python3では,表現する〈対象(アレ)〉をstr型,言語化規則によって異なる〈呼び名(商品名)や表記〉をbytes型と定義している.
Unicode 文字列はコードポイントの列であり、コードポイントとは 0 から 0x10FFFF (10 進表記で 1,114,111) までの数値です。このコードポイント列はメモリ上では コードユニット 列として表され、その コードユニット 列は 8-bit のバイト列にマップされます。Unicode 文字列をバイト列として翻訳する規則を 文字エンコーディング または単に エンコーディング と呼びます。
(中略)
Python ソースコードのデフォルトエンコーディングは UTF-8 なので、文字列リテラルの中に Unicode 文字をそのまま含めることができます
pythonコード内では,str型の「傷口に貼るアレ」を,unicode文字列(と対応されるコードポイント)を用いて表現する.そして,文字列処理の中でエンコードが必要な場合,デフォルトの文字コード(例では平仮名,pythonではUTF-8)を用いて『ばんそうこう』とエンコードされる.
デフォルトの文字コードは下記コードで確認できる.
import sys
print(sys.getdefaultencoding()) # → utf-8
逆に,〈呼び名〉を用いて〈対象〉を表示させることを**デコード(decode)**と呼ぶ.
bytes クラスの decode() メソッドを使って文字列を作ることもできます。このメソッドは UTF-8 のような値を encoding 引数に取り、オプションで errors 引数を取ります。
〈呼び名〉と〈対象〉との対応がうまくいかない場合があるため,<str>.encode()にも<bytes>.decode()にもerrors引数を取ることができる.この変数に指定したルールに従って例外処理を行う.
「あかさたな」のエンコードとデコード
早速,「あかさたな」という文字列に対して4種類の文字コードを用いてエンコードを実施する.
str_src = 'あかさたな'
enc_utf = str_src.encode() # default: encoding="utf-8"
enc_u16 = str_src.encode('utf-16')
enc_euc = str_src.encode('euc_jp')
enc_jis = str_src.encode('shift-jis')
print('--- ENCODE ---')
print('encoded by utf-8:', enc_utf, '(length={})'.format(len(enc_utf)))
print('encoded by utf-16:', enc_u16, '(length={})'.format(len(enc_u16)))
print('encoded by euc_jp:', enc_euc, '(length={})'.format(len(enc_euc)))
print('encoded by shift-jis:', enc_jis, '(length={})'.format(len(enc_jis)))
print('--- DECODE ---')
print(enc_utf.decode(), enc_u16.decode('utf-16'), enc_euc.decode('euc_jp'), enc_jis.decode('shift-jis'))
'''
--- ENCODE ---
encoded by utf-8: b'\xe3\x81\x82\xe3\x81\x8b\xe3\x81\x95\xe3\x81\x9f\xe3\x81\xaa' (length=15)
encoded by utf-16: b'\xff\xfeB0K0U0_0j0' (length=12)
encoded by euc_jp: b'\xa4\xa2\xa4\xab\xa4\xb5\xa4\xbf\xa4\xca' (length=10)
encoded by shift-jis: b'\x82\xa0\x82\xa9\x82\xb3\x82\xbd\x82\xc8' (length=10)
--- DECODE ---
あかさたな あかさたな あかさたな あかさたな
'''
出力を図化すると下記のようになる(utf-16についても16進法表示をしている).

utf-16を用いたエンコードで先頭に登場する2バイト分は,BOMと呼ばれる符号である.
Unicode 文字 U+FEFF は byte-order mark (BOM) として使われ、ファイルのバイト順の自動判定を支援するために、ファイルの最初の文字として書かれます。UTF-16 のようないくつかのエンコーディングは、ファイルの先頭に BOM があることを要求します; そのようなエンコーディングが使われるとき、自動的に BOM が最初の文字として書かれ、ファイルを読むときに暗黙の内に取り除かれます。
「傷口に貼るアレ」で例えるファイルの作成
今度は,pythonコード内でファイル名を指定し,ファイルの作成を行うことを考える.例によって,「傷口に貼るアレ」で原理を考える.繰り返しになるが,ここでは「ファイル名」に注目し,作成したファイルの中身についてはあまり気にせず議論を進める.
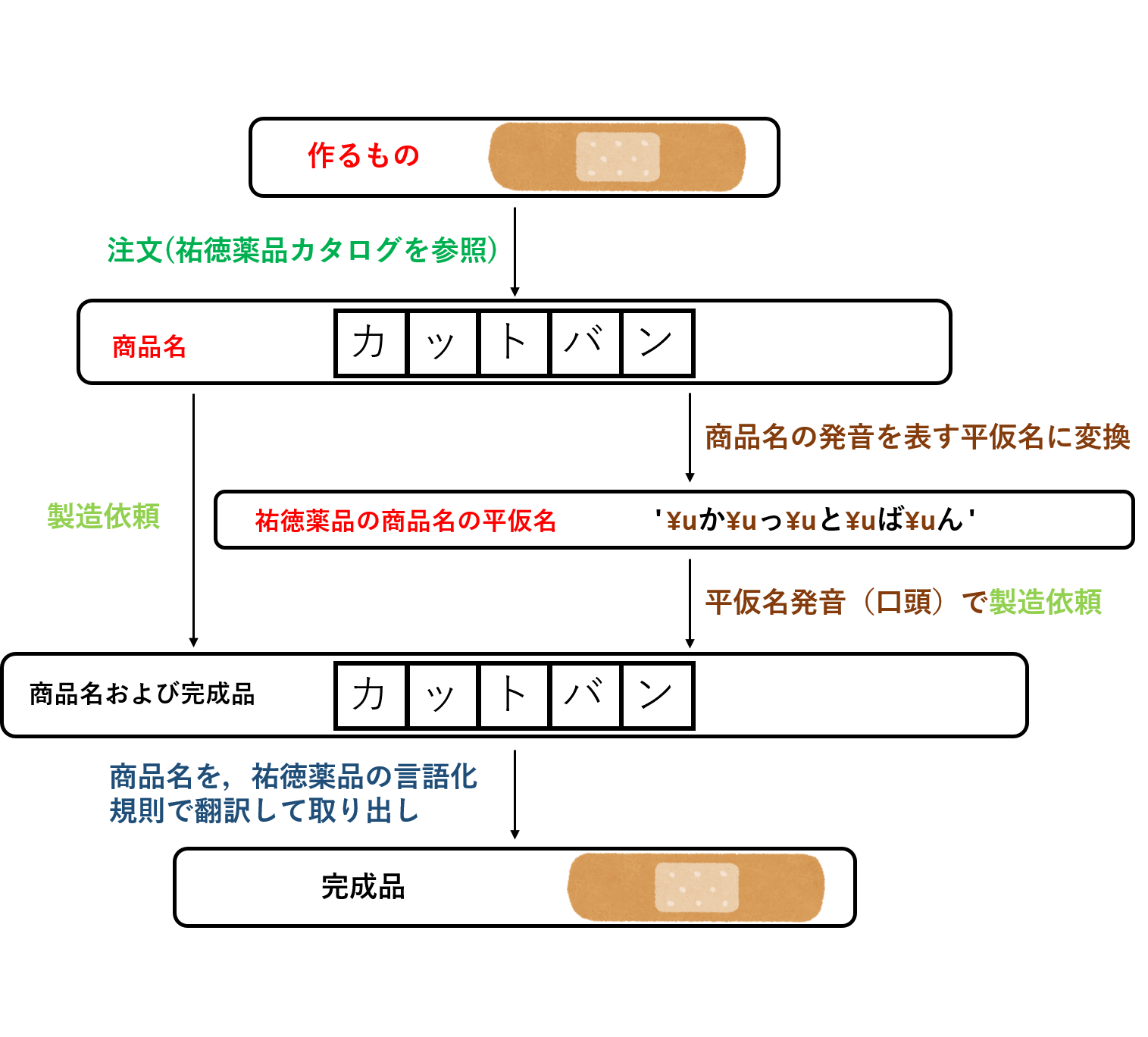
「傷口に貼るアレ」を製造する際,その名前は〈呼び方〉のほうがディスクに記録される.そして,「アレ」が必要になった際,予想している言語化規則の脳みそでその〈呼び方〉から「傷口に貼るアレ」に毎回翻訳(デコード)することになる.
ここでは,その予想している言語化規則が祐徳薬品のものしかない,というケースを考える.この規則に『ばんそうこう』という〈呼び方〉が渡されると,「『ばんそうこう』?『カットバン』しか知らん」といって,わけのわからない翻訳が行われてしまう(=文字化けしてしまう).
そのため,「傷口に貼るアレ」の製造時に適切な〈呼び方〉を選択しておかなければならない.祐徳薬品の言語化規則で定められる〈呼び方〉『カットバン』で製造を行うにはどうすればよいか.
まずは,「傷口に貼るアレ」を祐徳薬品の〈呼び方〉に翻訳する.次に,この〈呼び方〉を用いて製造依頼を行うことで,完成品の〈呼び方〉も祐徳薬品の規則で翻訳可能なものとなる.
これで何も問題はないのだが,普段の作業が平仮名で翻訳(デコード)されたstr型によるものに慣れている場合,str型を用いて製造依頼がしたくなる.この場合,依頼に用いる文字列は,**祐徳薬品の〈呼び方〉を平仮名で翻訳したstr(=『'\uか\uっ\uと\uば\uん'』)**でなければならない.
何も考えずに作業を行うと,ファイル生成時のファイル名には,python3においてデフォルトで指定されているエンコード用文字コードが適用される.さらに,errors引数もデフォルトが決定している.これらも,下記コードによって確認が可能である.
import sys
print(sys.getfilesystemencoding())
print(sys.getfilesystemencodeerrors())
'''
utf-8
surrogateescape
'''
「サロゲート(surrogate)」自体は,unicodeの表現領域をより拡張するための符号として新しく導入されたものである.Python3のbytes型デコード時のerrors=surrogateescapeでは,デコードがうまくいかないbytesの該当箇所を,surrogateで用いられるunicode文字列で置換する.これにより,デコード自体は不完全ではあるものの,元のbytes型の情報が損失されることなくエラーを避けることができる.同コードを再度エンコードしたい際には,errors=surrogateescapeの指定によって挿入したunicode文字列を削除して元の形を復元できるようにしている.
surrogateescapeエラーハンドラはU + DC80からU + DCFFに至るまでのUnicode私用領域のコードポイントとして任意の非ASCIIのバイトをデコードします。これらのプライベートコードポイントはsurrogateescape、データをエンコードして書き戻すときにエラーハンドラーを使用すると、同じバイトに戻されます。
日本語ディレクトリ・ファイルの作成
さて,上記で言及したことに注意しつつ,日本語名のファイルをutf-8およびshift-jisで保存することを考える.
準備
使用モジュールをインポートし,作業用ディレクトリを作成する.本記事ではcodecsなどの文字コード処理モジュールは用いません(よくわかりません).
import os
import glob
testdir = './testdir'
if not os.path.exists(testdir):
os.mkdir(testdir)
# ディレクトリに限定して,カレントディレクトリからパスを検索して表示
print([p for p in glob.glob('./*') if os.path.isdir(p)])
'''
[..., './testdir', ...]
'''
utf-8でファイルを作成
先述の通り,文字コードがutf-8である際はpython3のデフォルトに指定されているため,特になにも気を付けることはない.
utf-8のディレクトリ作成
os.mkdir()を用いて,作業用ディレクトリにutf-8のディレクトリ「あいうえお」を作成する.
utf_dirname = os.path.join(testdir, 'あいうえお')
os.mkdir(utf_dirname)
utf-8でtxtファイルの保存
さらに,「あいうえお」内に「かきくけこ.txt」を作成する.本記事では使わないが,ファイル内にはutf-8による文字列を出力しておく.
utf_filename = os.path.join(utf_dirname, 'かきくけこ.txt')
with open(utf_filename, 'w') as f:
f.write('さしすせそ\nたちつてと')
shift-jisでファイルを作成
いよいよ,ファイル名がshift-jisで定義されるファイルを新規作成する.
shift-jisのディレクトリ作成(by bytes型)
作業用ディレクトリにshift-jisのディレクトリ「あかさたな」を作成する.
これまではos.mkdir()にstr型を与えていたが,bytes型を入れても正常に動いてくれる.
jis_dirname = os.path.join(testdir, 'あかさたな').encode('shift-jis')
print(jis_dirname)
os.mkdir(jis_dirname)
'''
b'./testdir/\x82\xa0\x82\xa9\x82\xb3\x82\xbd\x82\xc8'
'''
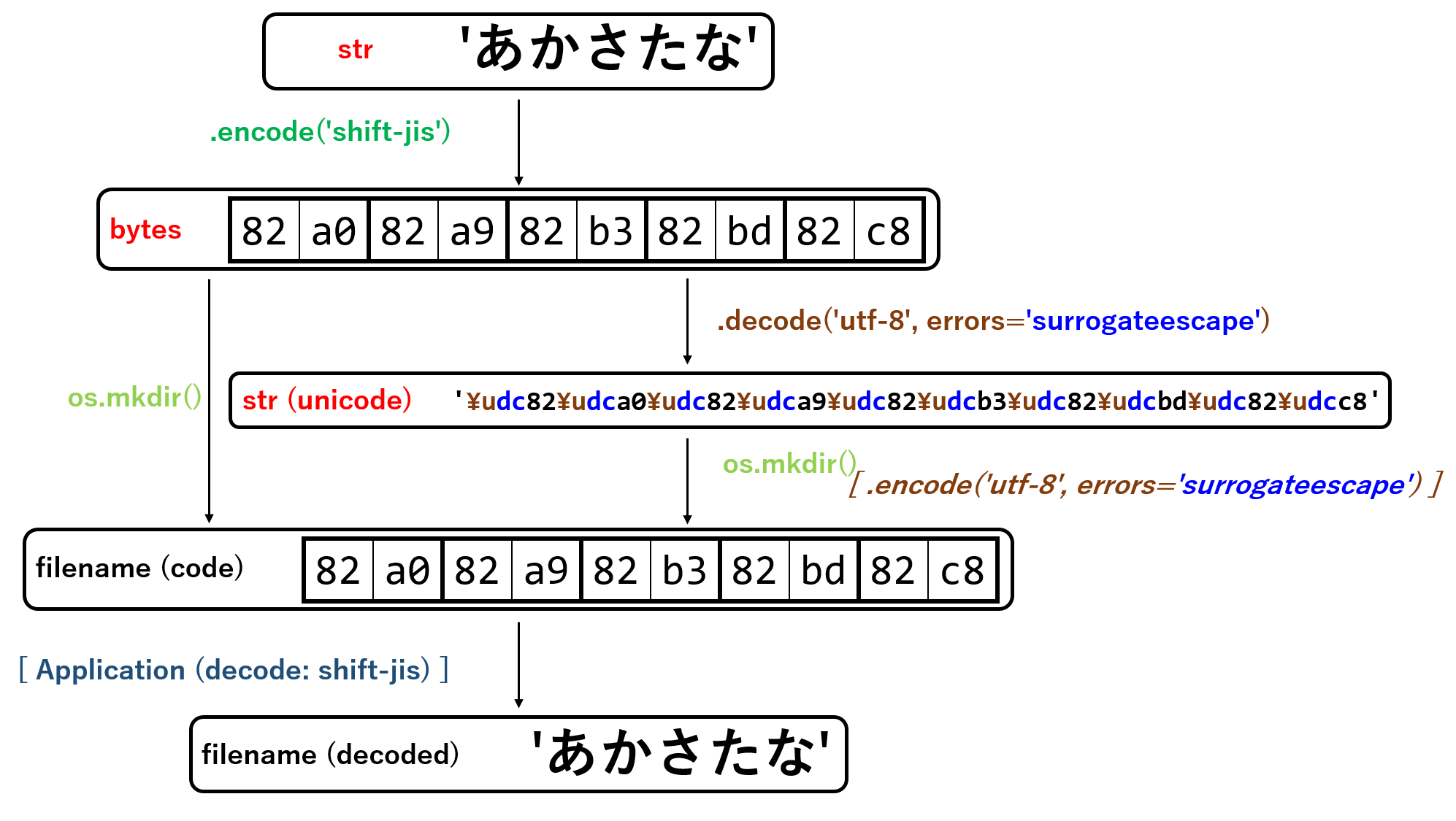
shift-jisのディレクトリ作成(by str型)
先ほどはbytes型のパス名を用いてディレクトリの新規作成ができることを示したが,今度はstr型を用いて,shift-jisのディレクトリ「あかさたな」を作成する.
先述の通り,デフォルトでファイル名のエンコード時には,encoding='utf-8',およびerrors='surrogateescape'を用いることがわかっているので,これらのオプションを用いてbytes型をstr型に変換(デコード)する.errorsの指定により,出力したunicode文字列の各頭に'dc'が付与されたことがかわる.
この特殊なデコードにより,生成されたstr型のunicode文字列はprint()に入れるとエラー(UnicodeDecodeError)を吐く.そのため,repr()で囲むことによって,unicode文字列そのままの表現で出力するようにしている.
jis_dirname_bytes = os.path.join(testdir, 'あかさたな'.encode('shift-jis')
jis_dirname_str = jis_dirname_bytes.decode(errors='surrogateescape'))
print(repr(jis_dirname_str))
os.mkdir(jis_dirname_str)
'''
'./testdir/\udc82\udca0\udc82\udca9\udc82\udcb3\udc82\udcbd\udc82\udcc8'
'''
shift-jisでtxtファイル名の作成
ディレクトリ「あかさたな」の中に,「はまやらわ.txt」を,shift-jisで作成する.ファイル内のテキストの文字コードもencoding='shift-jis'によってshift-jisにしている.
jis_filename = os.path.join(jis_dirname, 'はまやらわ.txt'.encode('shift-jis'))
# encode()のあとに.decode(errors='surrogateescape')をつけてもよい
with open(jis_filename, 'w', encoding='shift-jis') as f:
f.write('いきしちに\nひみりゐ')
一旦,保存ファイルの確認
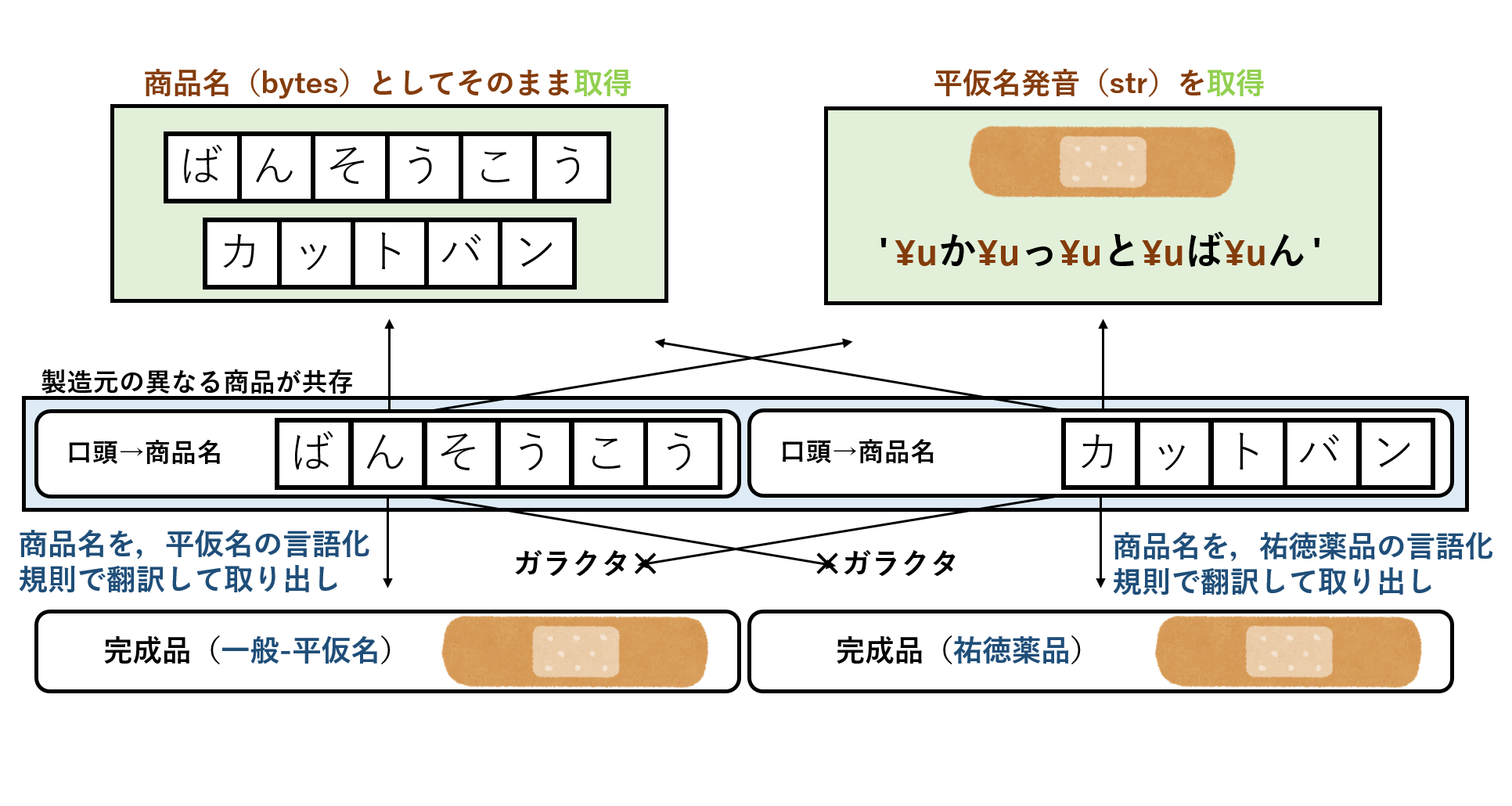
これまでに,2種類の文字コードでファイル名を定義したが,それをUIとglob.glob()で表示させてみる.下図で,真ん中の青い四角内が保存されたファイル名(bytes)である.その下側には,UIが文字コードを指定してファイル名を翻訳した結果を,上側には,pythonにおいてstr型かbytes型でファイル名一覧を取得した結果を表している.
utf-8によるUI表示
使用したのはJupyter Notebookのトップページである.utf-8で作成した「あいうえお」ディレクトリは正常に表示されているものの.shift-jisで作成した「あかさたな」ディレクトリは文字化けし,選択することもできない.
「あいうえお」ディレクトリ内の「かきくけこ.txt」も問題なく表示される.

shift-jisによるUI表示
使用したのはWinSCPである.shift-jisで作成した「あかさたな」ディレクトリは正常に表示されているものの.utf-8で作成した「あいうえお」ディレクトリは文字化けし,選択するとエラーとなる.
「あかさたな」ディレクトリ内の「はまやらわ.txt」も問題なく表示される.

glob.glob()による一覧表示
普通に作業ディレクトリ内のファイル一覧を取得しようとすると,デフォルトのutf-8でファイル名がデコードされるため,「あかさたな」ディレクトリがsurrogateescapeされたstr型となる.
print(glob.glob(os.path.join(testdir, '*')))
print(glob.glob(os.path.join(testdir, 'あいうえお', '*')))
'''
['./testdir/あいうえお',
'./testdir/\udc82\udca0\udc82\udca9\udc82\udcb3\udc82\udcbd\udc82\udcc8']
['./testdir/あいうえお/かきくけこ.txt']
'''
ここでは,glob.glob()にbytes型を代入し,得られた出力を任意のコードでデコードする方法でファイル名の取得を行う.
shift-jisでデコードしたほうは,「あかさたな」ディレクトリの名前が正常に表示され,「あいうえお」ディレクトリは文字化けを起こす.
# bytes型でファイル名の取得
bytes_paths = glob.glob(os.path.join(testdir, '*').encode())
print(bytes_paths)
# utf-8でデコード
print([f.decode(errors='surrogateescape') for f in bytes_paths])
# shift-jisでデコード
print([f.decode('shift-jis', errors='surrogateescape') for f in bytes_paths])
'''
[b'./testdir/\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86\xe3\x81\x88\xe3\x81\x8a',
b'./testdir/\x82\xa0\x82\xa9\x82\xb3\x82\xbd\x82\xc8']
['./testdir/あいうえお',
'./testdir/\udc82\udca0\udc82\udca9\udc82\udcb3\udc82\udcbd\udc82\udcc8']
['./testdir/縺ゅ>縺\udc86縺医♀',
'./testdir/あかさたな']
'''
ファイル名の文字コード変換(shift-jis → utf-8)
最後に,shift-jisで保存したファイル名を,utf-8で定義されたファイル名に変更する.
ディレクトリ名(shift-jis)の変換
shift-jisで定義されたディレクトリのパスを直接取得して,os.rename()によってutf-8の文字列と置換する.
target = glob.glob(os.path.join(testdir, '*').encode())[1]
print(repr(target))
print(target.decode('shift-jis'))
os.rename(target, target.decode('shift-jis'))
'''
b'./testdir/\x82\xa0\x82\xa9\x82\xb3\x82\xbd\x82\xc8'
./testdir/あかさたな
'''
結果が下図.無事文字コードが変換されて「あかさたな」が見れるようになった.

ファイル名(shift-jis)の一括変換
「あかさたな」ディレクトリ内に入る.

本記事では一つしかファイルがないが,複数ファイルの文字コード変換が必要な場合を想定し,ループ処理を加えたコードで対応した.
日本語部分に注目して,「あかさたな」部分がutf-8の文字列,「はまやらわ.txt」がshift-jisの文字列となっており,これらを混交したbytes型のデコードはエラーを返す(「./testdir」部分はascii文字列に含まれるため,utf-8でもshift-jisでも共通のbytesで動くため考えなくてよい).この2つを分けてから処理を行う必要がある.
for f in glob.glob(os.path.join(testdir, 'あかさたな', '*').encode()):
# ディレクトリ名(utf-8でデコード)
d_str = os.path.dirname(f).decode()
# ファイル名(shift-jisでデコード)
b_str = os.path.basename(f).decode('shift-jis')
# 文字コード変換
os.rename(f, os.path.join(d_str, b_str))
これで「はまやらわ.txt」も無事utf-8の文字コードで定義された.

終わりに
ここまでまとめて,やっと文字列操作のコツが分かってきたように思う.特に,普段str型に慣れていて全く気にかけなかったbytes型をうまく生かすと作業がかなり楽になることがわかった.これに加え,エンコード・デコード時のerrorsの扱いを適宜選ぶことができれば,大半の作業ができるようになりそう.
あと,結局公式ドキュメントが一番わかりやすい気がする.