この記事では以下の内容をはなします
- バイナリデータをそのままニューラルネットワークに突っ込むことができる
- グリッチJPEG画像も認識できる
- CNN+LSTMの構造がよくバイナリデータを学習する
- JPEGはロバストな画像的特徴を捉えやすいバイナリフォーマットである
| バイナリデータ認識と画像認識の違い |
|---|
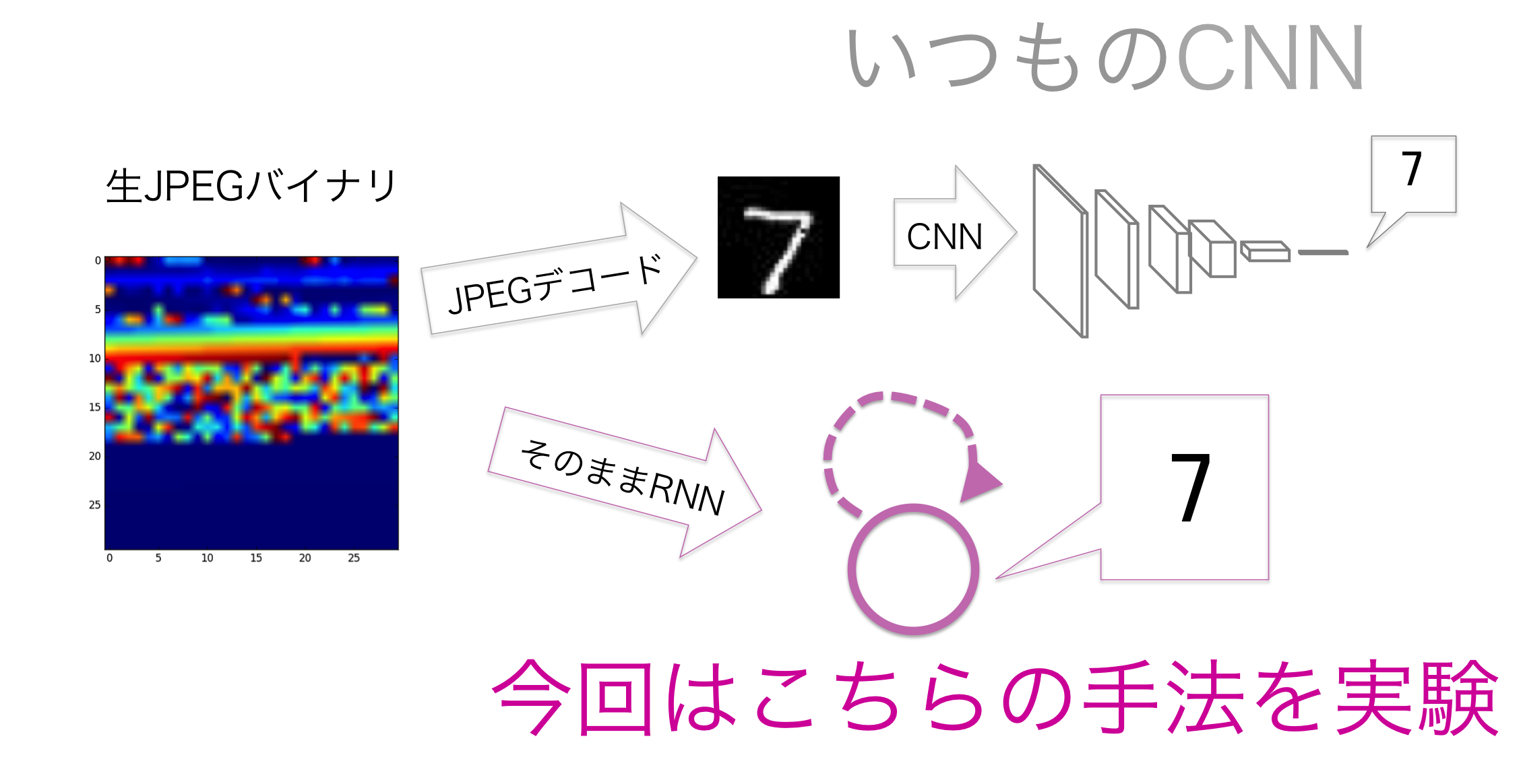 |
| "画像"認識をしないで画像データを認識する |
| バイナリデータ認識で認識できるようになるグリッチ画像 |
|---|
 |
| まったくもとの画像が推測できない壊れ方でも認識できる |
学会発表のためバンコクに来ています。 @Hi-king です。この記事は ドワンゴ Advent Calendar 2017 初日の記事です。
早速ですが、今日のテーマの背景のポエムを読みます。コンピュータビジョンは機械の目を作る学問だと言われていて,特に近年のディープラーニングの技術により,"特に前処理とかしなくても、生の画像を直接ニューラルネットに入力すれば画像認識できる"という能力を獲得したと言われています。
しかし、ちょっと待って下さい。我々エンジニアにとって、生の画像データって本当に画像の形をしているでしょうか?我々が扱ってるデータは何らかのフォーマットで保存したバイナリデータであり,そのバイナリデータをそのまま扱えてこそ"生データから学習"といえるのではないでしょうか。
今回のテーマはJPEGデータを対象とし、JPEGデータから画像データにエンコードして、画像データの特性を活かしCNN(畳み込みニューラルネットワーク)を学習する従来の手法に対して、JPEGのバイナリデータをそのままただのデータ列と扱っても画像認識ができるということを示します。さらに、この手法では 何らかの理由で壊れてしまったバイナリデータ(グリッチ画像)でも頑健に動く こともわかりました。
バイナリデータ読み取りネットワーク
ソースコードはgithubで公開しているので、ネットワークのパラメタや学習方法についてさらに知りたい方はそちらをご覧ください。
| どんな層を重ねたネットワークになっているか |
|---|
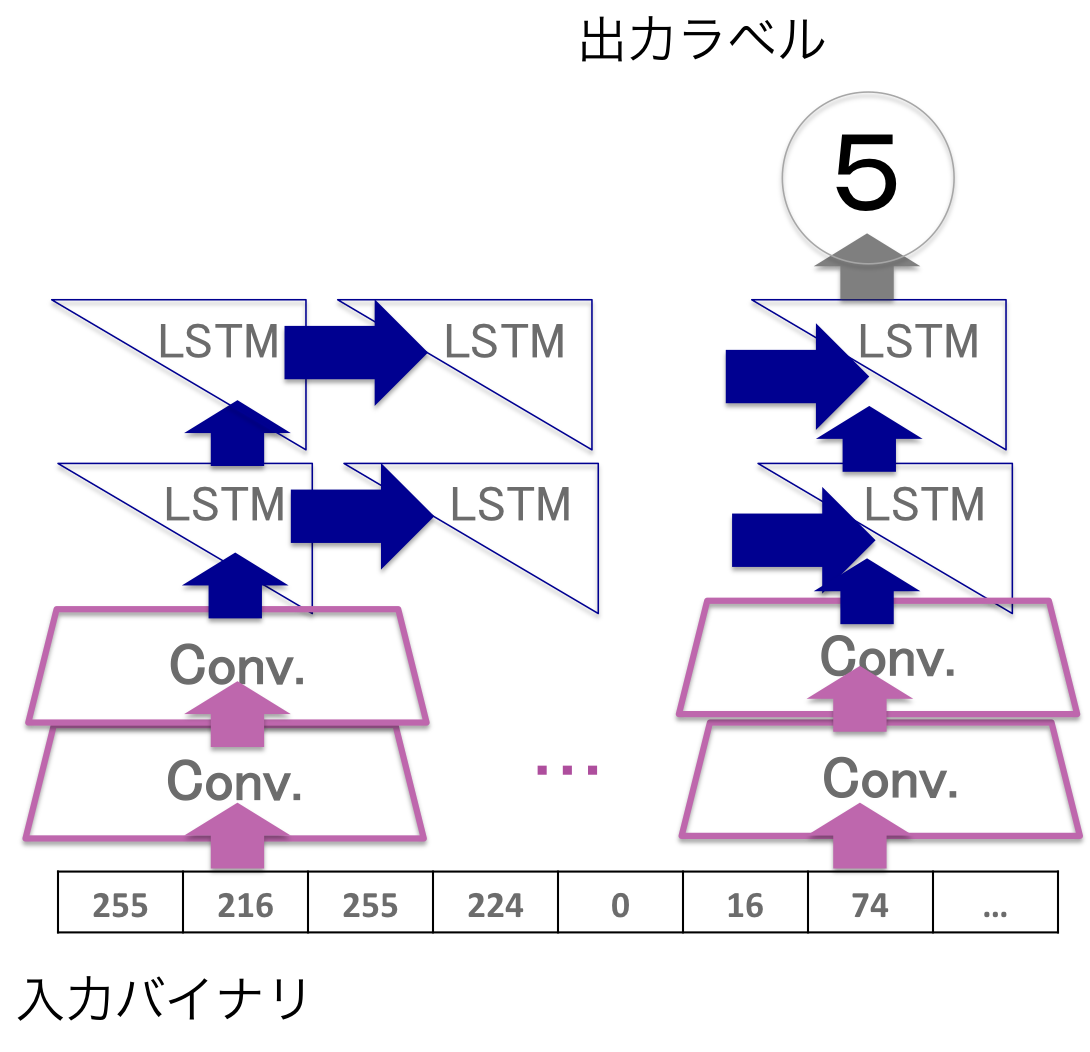 |
幾つかのネットワークを試した結果、このネットワークでテスト精度98%以上を達成しました。
バイナリデータの性質上2バイト4バイトなどをひとまとめにして扱う部分が存在することを考慮し、生バイナリの上に1次元畳み込み層を2つ重ねて置きました。実験したところ、これはテスト精度の向上に大きく寄与したので期待通り動いたと考えられます。更に、確かめられては居ないのですが、このCNNがハフマン符号のデコードに近いこともやってくれているのかも?しれません。
その上にLSTM(Long short-term memory)を載せることで、Conv.によって得られた単位表現の、 可変長の 特徴を捉えるようにしています。同じ画像サイズのものをJPEGで圧縮しても符号化の過程でバイナリデータサイズは異なってしまうため、固定サイズの画像データのようには行かないのです。文字列・音声・動画などの時系列情報に用いられることの多いLSTMですが、今回のような不定長の特徴を読み取るのにも使えます。
LSTMの読み取り方向には幾つかの方法が考えられるのですが、今回はシンプルに、先頭バイトから読んでいって、終端まで行ったときの出力をそのバイナリデータの読み取り結果としました。
学習方法と精度向上
学習に用いたデータは、画像認識で幅広くベンチマークとして使われている手書き数字データセットMNISTです。これを読み込み時に、逐次以下のコードのようにして任意のバイナリフォーマットに変換しながら読み込んでいます。
def convert(base_image, format):
with io.BytesIO() as f:
image_array = (base_image * 256).astype(numpy.uint8)
image = Image.fromarray(image_array)
image.save(fp=f, format=format)
d = numpy.frombuffer(f.getvalue(), dtype=numpy.uint8).astype(numpy.int32)
return d
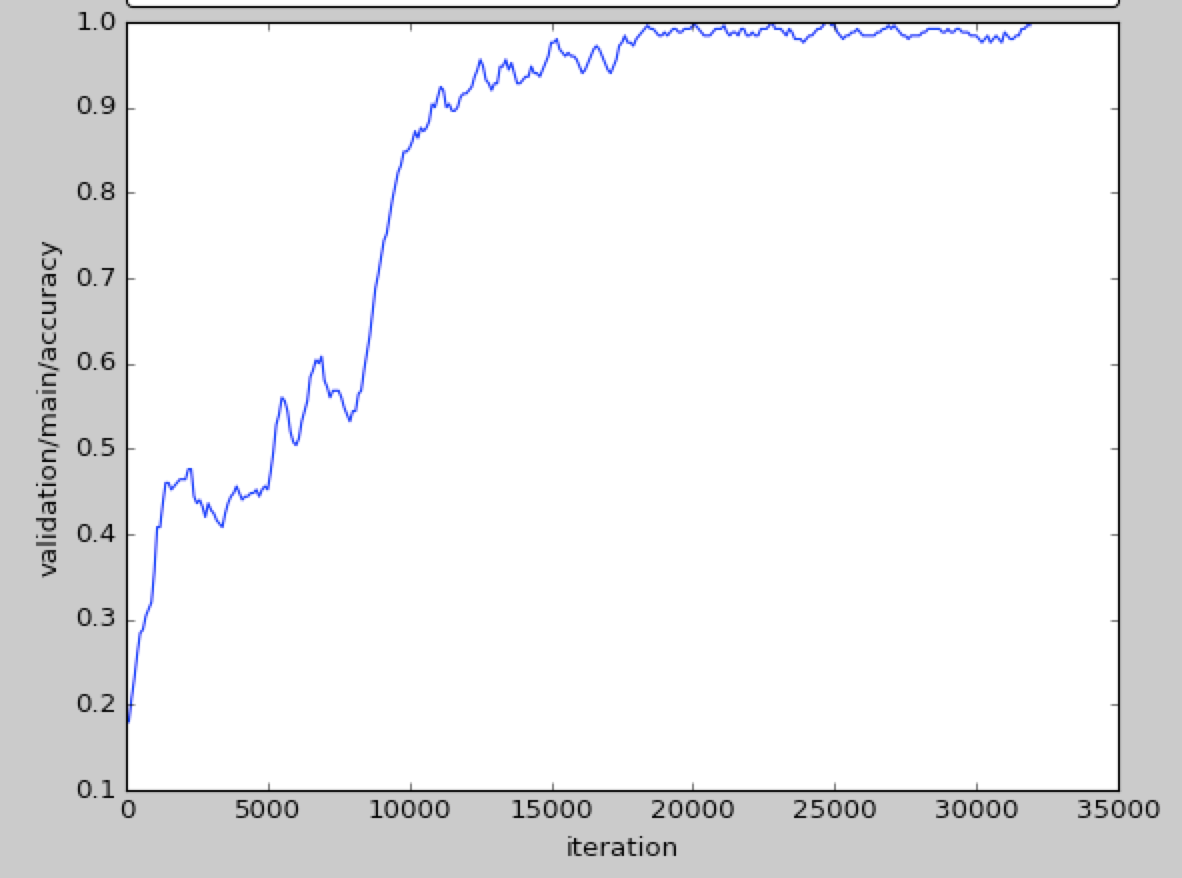
| テストデータ(学習時に使ってない画像)での精度 | 学習データでの精度 |
|---|---|
 |
 |
学習時とテスト時の精度の推移はこのようなグラフになります。ちなみに1イテレーションで1000データをバッチとして読んでるので、結構な量を読ませないと学習が進まないともいえます。
テスト精度のほうが学習時精度より良い理由は、過学習を防ぐために学習時のみランダムに平行移動させたデータを使ってデータオーギュメンテーションしているからです。
| 設定の違いによるテスト精度の比較 |
|---|
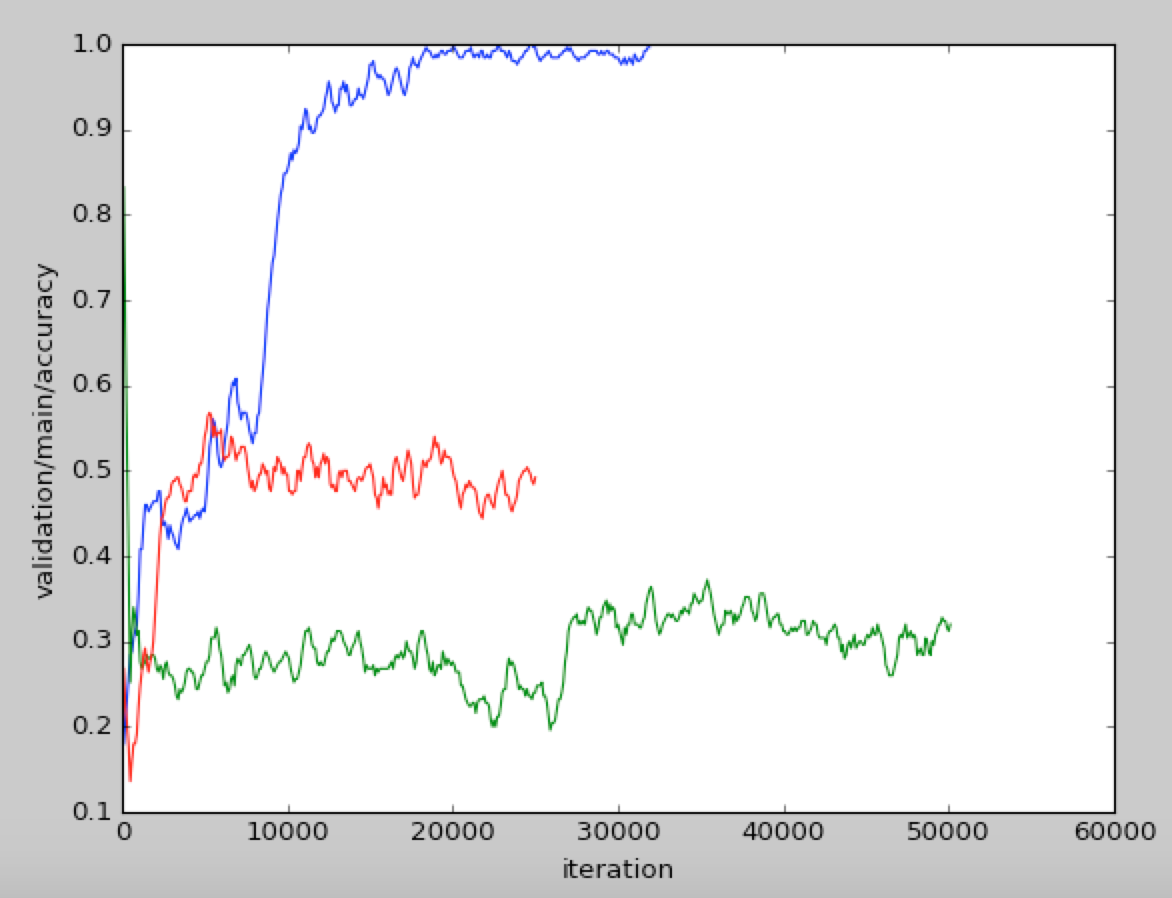 |
| 青: 完成したもの |
| 赤: -データオーギュメンテーション |
| 緑: -データオーギュメンテーション-CNN |
このグラフは、今まで話したテクニックをそれぞれなくしたときのテスト精度で、データオーギュメンテーション、CNNがそれぞれテスト精度を上げるのに貢献しています。全ての実験で学習時精度はほぼ100%なので、これらは汎化性能の向上に寄与しています。
グリッチ画像の認識
さて、ここまでは一般の画像認識でもできることをバイナリデータ認識で達成したという話でした。ここでは、バイナリデータ認識でしか認識できない問題についてはなしていこうと思います。
| グリッチ画像とは |
|---|
 |
JPEGが画像を効率的に圧縮したフォーマットであるため、その圧縮結果を一部でも破損するとデコードした画像が大きく破損してしまう、その結果生まれるのがグリッチ画像です。伝送や保存時などのエラーによってまれに起こるのですが、そのグリッチした画像がカッコイイという感性により、あえてアートとしてグリッチ画像を使う人もいます。
画像認識では、画像のなかで多少のノイズが乗ってもかなり頑健に認識できるのですが、このようにバイナリとしてはほんの些細なノイズであっても、グリッチ画像は大きく画像認識を狂わせてしまいます。バイナリをそのまま認識する今回の手法ではこれを解決しました。
| 何バイトまで壊しても認識できるか |
|---|
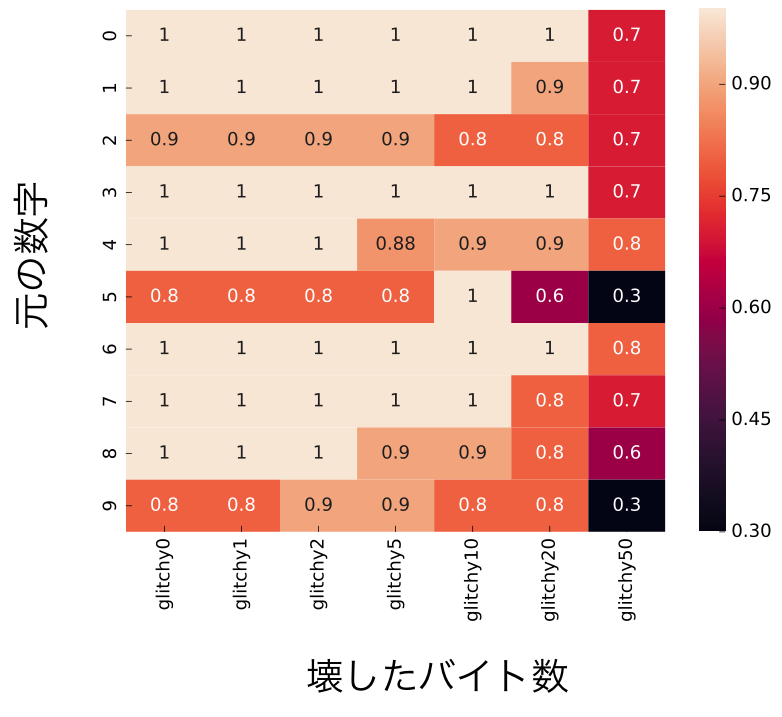 |
この表は、きれいなJPEGバイナリにどんどんノイズを加えて行って、どこまで認識精度を保てるかの実験です。MNISTの画像をJPEGとして保存した時、平均して650Bほどのデータとなるのですが、なんとそのうち50B程をランダムに0に変えてしまってもほとんどのクラスで70%ほどの精度で認識できるのです。10バイト以上も破壊してしまうと、ほぼ元の画像は推測できず、JPEGとしてそもそもデコードできない状態になることがほとんどなので、これはかなり驚きです。
今回は学習時にはきれいなデータしか使っていないんですが、データオーギュメンテーションとしてグリッチさせながら学習するとさらにノイズに頑健な職別器も作れそうに思います。
考察: なぜJPEGのバイナリでこれほどロバストな認識ができるのか
このセクションはさらに動作原理を理解したい方向けです。
バイナリデータ認識では、非常にノイズに強い認識が行えました。ネタバラシをすると、これは任意の圧縮フォーマットについてCNN+LSTMで学習すればこれほどの認識精度が出るとは流石にいえません。JPEGの圧縮アルゴリズムを考えてみると、この秘密は、DCT(離散コサイン変換: 画像の周波数変換し、その係数のみを保存する)とブロック(パッチ)ごとの圧縮という特性によるものだと考えられます。[1] これ以降の考察は@kusano_k の協力により得られたものです。ありがとうございます。
まずDCTについてですが、広く知られているフーリエ変換と同様に画像の周波数ごとの係数をもってその画像を近似するものです。この特性により、ある周波数帯、たとえば高周波の特徴が全て消されてしまっても、その物体の概型は実は保たれたりします。
次にブロック(パッチ)ごとの圧縮ですが、JPEGでは画像をその2次元空間でのいくつかのパッチに区切って上記のDCTによる圧縮を行うため、あるパッチでエラーが発生しても、他のパッチの情報は完全に保たれるという特性があります。これにより、部分的なマッチングはバイナリエラーに影響されにくいという特性があります。
つまりこの二点から、ブロック内でのエラーにある程度頑健、ブロック間では独立にマッチングできるという頑健さがあるのです。
余談ですが、画像処理界隈の方であればこれらの特徴にピンとくるかと思います。つまり、JPEG自体がある種局所特徴量の集合になっている、といえるのです。
この原理を考えると、何だ簡単じゃないかと思われるかもしれませんが、実際にはそれぞれのブロックで可変長の圧縮が行われているので、これを特徴量として利用可能にするのはそこまで簡単ではありません。LSTMによる可変長のマッチングはここで役割を果たしているといえます。
また、ハフマン符号化が行われているため、データの中身によってビット数が異なる表現になっています。今回のネットワークがどのような原理でこれをデコードできているのかはわからないですが、CNNによってある程度元の値に戻したりしているのかもしれません。検証してみたいです。
最後に問題設定についてもう一度いいますが、このセクションではJPEGの特徴から、バイナリデータでも画像認識可能である理由を述べましたが、今回のネットワークの学習時には JPEGデータをたくさんニューラルネットワークに入力しただけ であり、JPEGがこういう特徴を備えていることは全く事前知識として使っていません。実際に、筆者も、実験結果がでた後に考察しています。
感想
あんまり普段はニューラルネットが何を判断基準にしているか、とか考えないんですが、今回JPEGのことをニューラルネットのお気持ちを考えながら調べるの楽しかったです。他のフォーマットも実はコード上は対応してるので、色々実験してみたいです。この研究が、もっともっと雑にニューラルネットを使うための手助けになれば幸いです。
アドベントカレンダー、明日は @MIRO さんの担当です。楽しみです〜