はじめに
この記事では、RAG(Retrieval-Augmented Generation)という技術を使って、オリジナルのチャットボット型Webアプリケーションを作り、それを無料でデプロイする方法を紹介します。自分が実際に作成したものをベースに、どのように開発を進めたか、どんなツールを使ったかをステップごとに解説していきます。この記事をみて頂いたら、初心者でも1からオリジナルのRAGのwebアプリを作ることができます。
※この記事では、まず初心者がRAGのwebアプリを作ってみて、デプロイすることを目的として説明します。 精度向上のために、様々な手法が知られていますがここでは、細かい話については省略します。
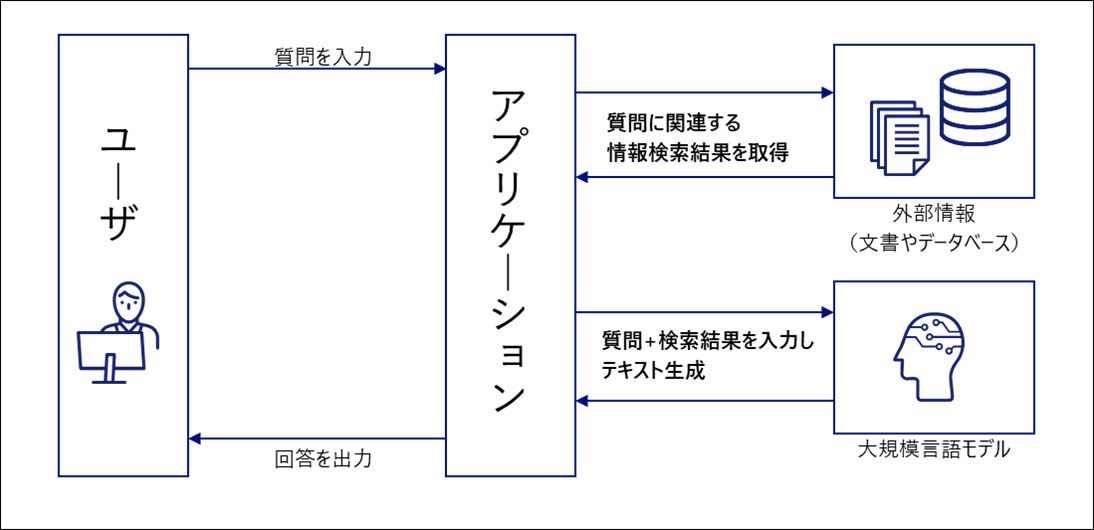
そもそも、RAGってなに?と思う方もいるかもしれません。簡単に説明すると、RAGは「検索」と「生成」を組み合わせた技術です。普通の検索システムだと、キーワードに基づいてリスト形式で結果が返されますが、RAGでは検索結果を元に、自然な形で情報を生成して回答を返してくれます。まるでAIが人間のように、質問に対して的確な答えを返してくれます。
以下はイメージ図です。
さきに、今回、私が最終的に作った自分が運営する団体専用のRAGのwebアプリを公開しておきます。
ここからアクセスできます。
この記事を最後までみてもらえれば、誰でも無料で自分オリジナルのRAGを作ることができるので、ぜひチャレンジしてみてください!
使用ツール・サービス
今回使ったツールとサービスを簡単に紹介しておきます。すべて無料で使えるものを中心に選んでいるので、コストを気にせず手軽に始められます。
Python: 皆さんおなじみのプログラミング言語ですね。今回のアプリケーション全体をPythonで書いています。
Streamlit: Pythonで超簡単にWebアプリケーションを作れるフレームワークです。UIを素早く構築できて、デプロイもワンクリックでできます。
Langchain: RAGのコア部分を担当するライブラリです。データベースを検索したり、LLM(大規模言語モデル)を使って生成する部分をサポートしてくれます。
FAISS: 検索を高速に処理するためのライブラリ。特に大量のデータから必要な情報を効率的に取り出すときに使います。
Google Generative AI: AIによる生成部分を担当するAPIです。ユーザーの質問に対して、適切な応答を生成します。今回は無料で使える範囲でこのサービスを利用しています。
BeautifulSoup: Webスクレイピングをするためのライブラリです。Webページから情報を自動で取得し、データベースに格納するために使います。
これらのツールを組み合わせることで、手軽に強力なアプリケーションを作り上げることができます。個別にインストールしたり設定したりすることもありますが、それぞれの役割を理解すれば、自分のプロジェクトに応用できるはずです。
以下のステップで解説していきます。
- ~APIキーを発行する~
- ~データベースへ文章を格納する~
- ~チャットボットを作る~
- ~Webアプリにする~
- ~Webアプリをデプロイする~
APIキーを発行する
RAGでは、ChatGPTやGeminiなどのLLMのAPIをもちいて、実装しています。
今回は、Google Generative AIのAPIを利用して、ユーザーの質問に対して自然な応答を生成します。そのためには、まずGoogle Cloud Platform(GCP)からAPIキーを発行し、それをアプリケーション内で使用する必要があります。ここでは、Google Generative AI APIキーの取得方法とその使い方を説明します。※既に取得したことがある方はスキップしてください。
まずは、ここ にアクセスします。
すると、以下のような画面が出てくるので、Sign in to Google AI Studioを押してサインします。
すると、以下のような画面が出てくるので、左上のGet API key を押してください。
すると以下のような画面が出るので、APIキーを作成するから、APIを作成してください。
そこででてきた、APIキー(文字列)をメモっておいてください。次に、このAPIキーを使うので、この文字列を保存しておいてください。
※このAPIキーは、セキュリティ的に公開しないようにしてください。
GoogleのAPIは無料枠が豊富です。(2024/9/5時点)
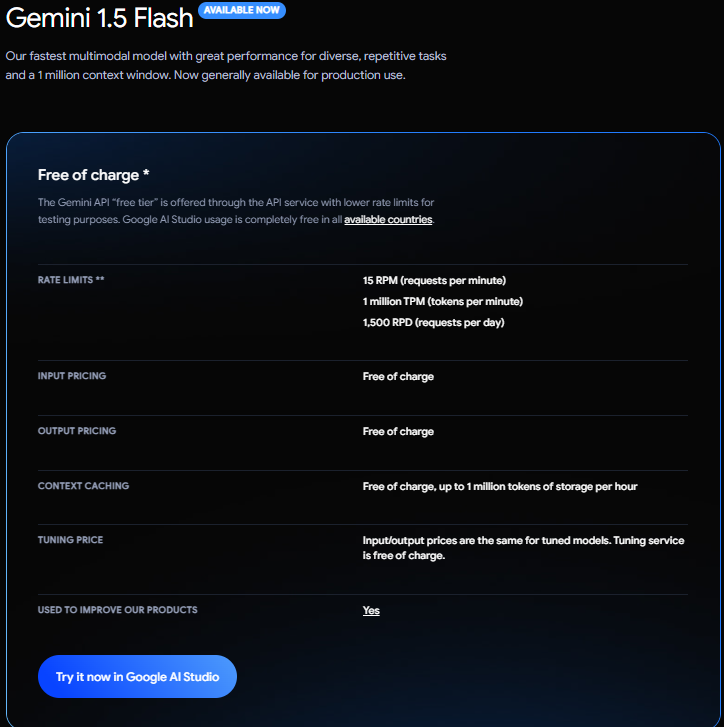
Gemini 1.5 Flashの 無料利用の場合の制限は以下のようになっているので、個人で開発する分には気にしなくても大丈夫なくらい豊富です。
•1分間に15回のリクエ ストまで
•1分間に100万トークンまで
•一日に1500回のリクエストまで
•利用したデータや結果については、 Googleの製品改善に利用される
※秘匿性の高いデータは利用しないでください
万が一制限を超えてしまった場合も、クレジット情報を渡さない限り自動でAPIが使えなくなり、請求がくることはないと思われます。※間違っていたらすみません。
いざ開発
ここでは、環境構築不要な、GoogleColabでのやり方を説明します。
GoogleColabの基本的な使い方については、この記事などを参考にしてください。
自分の環境で行う場合は、適宜、ライブラリをインストールしてください。
APIキーを環境変数に追加
・GoogleColabの場合以下の手順に従ってください。
まず画面の左にある鍵マークを押す
新しいシークレットを追加を押す

新しいシークレットに、APIキーいれる。
名前を GEMINI_API_KEY 値をご自身で発行したAPIキーの文字列を入れて、ノードブックからのアクセスを許可するようにします、
以下のように実行して、表示されればAPIキーが環境変数に追加されていることを確認できます。
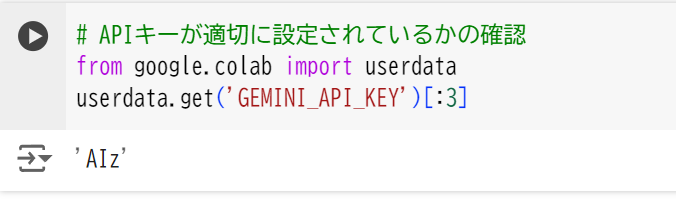
ご自身の環境で行う場合は、envファイルをつくってAPIキーを置くことをお勧めします。
データベースへ文章を格納する
ここでは、ウェブサイトからデータを収集していきます。
文章であれば、どんなものでもできますが、今回はウェブサイトから情報をとってくるとこにしています。
以下では、GoogleColabでのコードをかきます。
必要なライブラリのインストール
#必要なライブラリをインストール
%pip install --upgrade --quiet langchain langchain-google-genai langchain-community faiss-cpu streamlit langchain-text-splitters beautifulsoup4
必要なライブラリのインポート
# 必要なライブラリのインポート
import requests
from bs4 import BeautifulSoup
from langchain.schema import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS
こでは、いくつかのライブラリをインポートしています。それぞれの役割は以下の通りです:
・requests: Webページにアクセスして、HTMLデータを取得するためのライブラリ。
・BeautifulSoup: 取得したHTMLデータを解析し、テキストを抽出するためのライブラリ。
・Document: テキストデータを扱うためのオブジェクト形式(Langchainの一部)。
・CharacterTextSplitter: 長いテキストを複数のチャンク(小さなブロック)に分割するためのクラス。
・GoogleGenerativeAIEmbeddings: Google Generative AIを使ってテキストデータをベクトル化(数値表現)するためのクラス。
・FAISS: ベクトル化したデータを効率的に検索するためのライブラリ。
スクレイピング対象のURLリストを定義
# スクレイピング対象のURLリスト
urls = [
"https://example.com/page1",
"https://example.com/page2"
]
urlsには、スクレイピングを行いたいWebページのURLをリスト形式で指定しています。この例では2つのページを対象にしていますが、任意のページ(自分が教えこみたい情報を)追加することが可能です。
WebページのHTMLデータを取得して保存
# ファイル名とURLのペアを保存するリスト
fnames = []
# WebページにアクセスしてHTMLデータをローカルに保存
for url in urls:
fname = f"{url[url.rfind('/', 0, -1) + 1:-1]}.html"
fnames.append((fname, url)) # ファイル名とURLのタプルを保存
response = requests.get(url)
with open(fname, mode='w', encoding='utf-8') as fout:
fout.write(response.text)
この部分のコードでは、指定されたURLからWebページのHTMLデータを取得して、ローカルファイルに保存しています。
・requests.get(url): 指定したURLのWebページの内容を取得します。
・fname: URLからファイル名を作成して、保存時に使います。例えば、"example.com/page1"というURLは"page1.html"として保存されます。
・response.text: 取得したHTMLデータです。
・with open(): 取得したHTMLデータをファイルとして保存します。
テキストをチャンクに分割するための設定
# チャンクを分割するための設定
text_splitter = CharacterTextSplitter(
separator='\n\n', # 改行で分割
chunk_size=500, # 各チャンクのサイズ
chunk_overlap=0, # チャンク間の重複なし
length_function=len # 文字数でチャンクを計測
)
ここでは、Webページから抽出した長いテキストを「チャンク」と呼ばれる小さなブロックに分割するための設定をしています。
・separator='\n\n': 2つの改行を基準にしてテキストを分割します。文章の段落が分かれる場所の基準です。
・chunk_size=500: 各チャンクの最大文字数は500文字です。
・chunk_overlap=0: チャンク同士が重複しない設定です。
・length_function=len: チャンクの長さを計測する関数です。ここでは、文字数を計測します。
ここではこのように、上記のチャンクに分けていますが、ここでどのように分けるかで、精度が変わったりするので、ご自身でかえて見てください。
Webページのテキストを取得してチャンクに分割
# 全てのチャンクを保持するリスト
all_chunks = []
# テキストを取得してチャンクに分割し、メタデータにURLを含める
for fname, url in fnames:
with open(fname, 'r', encoding='utf-8') as file:
html_content = file.read()
soup = BeautifulSoup(html_content, 'html.parser')
text = soup.get_text(separator="\n")
# 抽出したテキストをチャンクに分割
chunks = text_splitter.split_text(text)
# 各チャンクをDocumentオブジェクトに変換してリストに追加
for i, chunk in enumerate(chunks):
# メタデータにURLを保存
doc = Document(page_content=chunk, metadata={"source_url": url, "chunk_index": i})
all_chunks.append(doc)
print(f"Processed {fname}, {len(chunks)} chunks extracted.")
ここでは、保存したHTMLファイルを開き、その中からテキストを抽出して、さらにチャンクに分割しています。
BeautifulSoup(html_content, 'html.parser'): HTMLデータを解析し、テキストデータを取り出します。
text_splitter.split_text(text): 先ほど設定した条件に基づいてテキストをチャンクに分割します。
Document: 各チャンクをDocumentオブジェクトに変換し、メタデータとしてsource_url(元のURL)を追加します。
all_chunks.append(doc): すべてのチャンクをリストに保存します。
ベクトル化とベクトルストアへの保存
# Geminiに対応したベクトル変換を実施
embeddings = GoogleGenerativeAIEmbeddings(
google_api_key=userdata.get('GEMINI_API_KEY'),# APIキーを指定
model="models/embedding-001"
)
# ベクトルストアにチャンクを保存
db = FAISS.from_documents(all_chunks, embeddings)
db.save_local('faiss_store')
最後に、Google Generative AIを使ってテキストをベクトル化し、FAISSに保存しています。
GoogleGenerativeAIEmbeddings: テキストをベクトルに変換するためのモデルです。google_api_keyにはGoogleのAPIキーを設定しています。
FAISS.from_documents(all_chunks, embeddings): ベクトル化されたチャンクをFAISSに保存し、効率的に検索できるようにします。
db.save_local('faiss_store'): ベクトルストアをローカルに保存します。この保存されたデータベースは、後で検索や質問応答の処理に利用されます。
これで一旦、データベースへ文章を格納するのが完了です。
データベースへの格納まとめ
以下にデータベースへの格納の所の全部のコードをまとめておきます。
# 必要なライブラリをインストール
%pip install --upgrade --quiet langchain langchain-google-genai langchain-community faiss-cpu streamlit langchain-text-splitters beautifulsoup4
# 必要なライブラリのインポート
import requests
from bs4 import BeautifulSoup
from langchain.schema import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS
# スクレイピング対象のURLリスト
urls = [
"https://lalala-takahira.github.io/homepage/",
"https://www.instagram.com/lalala_takahira/",
"https://lalala-takahira.github.io/homepage/events",
"https://lalala-takahira.github.io/homepage/reports",
"https://lalala-takahira.github.io/homepage/about",
"https://lalala-takahira.github.io/homepage/media"
]
# ファイル名とURLのペアを保存するリスト
fnames = []
# WebページにアクセスしてHTMLデータをローカルに保存
for url in urls:
fname = f"{url[url.rfind('/', 0, -1) + 1:-1]}.html"
fnames.append((fname, url)) # ファイル名とURLのタプルを保存
response = requests.get(url)
with open(fname, mode='w', encoding='utf-8') as fout:
fout.write(response.text)
# チャンクを分割するための設定
text_splitter = CharacterTextSplitter(
separator='\n\n', # 改行で分割
chunk_size=500, # 各チャンクのサイズ
chunk_overlap=0, # チャンク間の重複なし
length_function=len # 文字数でチャンクを計測
)
# 全てのチャンクを保持するリスト
all_chunks = []
# テキストを取得してチャンクに分割し、メタデータにURLを含める
for fname, url in fnames:
with open(fname, 'r', encoding='utf-8') as file:
html_content = file.read()
soup = BeautifulSoup(html_content, 'html.parser')
text = soup.get_text(separator="\n")
# 抽出したテキストをチャンクに分割
chunks = text_splitter.split_text(text)
# 各チャンクをDocumentオブジェクトに変換してリストに追加
for i, chunk in enumerate(chunks):
# メタデータにURLを保存
doc = Document(page_content=chunk, metadata={"source_url": url, "chunk_index": i})
all_chunks.append(doc)
print(f"Processed {fname}, {len(chunks)} chunks extracted.")
# Geminiに対応したベクトル変換を実施
embeddings = GoogleGenerativeAIEmbeddings(
google_api_key=userdata.get('GEMINI_API_KEY'),# APIキーを指定
model="models/embedding-001"
)
# ベクトルストアにチャンクを保存
db = FAISS.from_documents(all_chunks, embeddings)
db.save_local('faiss_store')
チャットボットを作る
ここでも、引き続き、GoogleColabを用いて行う前提ですすめます。自分の環境で行う場合は適宜、環境変数にAPIキーを入れたり、データベースのパスをご自身のものに変えてください。
必要なライブラリのインポート
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
ここでは、3つの重要なライブラリをインポートしています。
・ChatGoogleGenerativeAI: Google Generative AIを使って、自然言語応答を生成するためのライブラリです。
・RetrievalQA: 質問応答の仕組みを構築するためのクラスです。これは、データベースから関連情報を取得し、その情報を元に応答を生成します。
・PromptTemplate: モデルに対してどのような形式でプロンプト(入力)を与えるかを定義するためのクラスです。
Google Generative AIの設定
# Geminiモデルを定義する
llm = ChatGoogleGenerativeAI(
google_api_key=userdata.get('GEMINI_API_KEY'),
model="gemini-1.5-flash",
temperature=0.0,
max_retries=2,
)
ここでは、Google Generative AIの「Geminiモデル」を使って、チャットボットがユーザーの質問に答えるように設定しています。
・google_api_key: 事前に発行したGoogle APIキーを設定します。ここでは、環境変数やファイルなどから取得しています。
・model: 使用するGenerative AIのモデルです。ここでは「gemini-1.5-flash」というモデルを使用しています。
・temperature: 応答の多様性をコントロールするパラメータです。0に設定しているので、決定論的な(毎回同じ結果を返す)応答を得ることができます。
・max_retries: 応答が失敗した際に再試行する回数を設定します。
プロンプトの設定
# オリジナルのSystem Instructionを定義する
prompt_template = """
あなたは、「ラララたかひら」という団体専用のチャットボットです。
背景情報を参考に、質問に対して団体の人間になりきって、質問に回答してくだい。
ラララたかひらに全く関係のない質問と思われる質問に関しては、「ラララたかひらに関係することについて聞いてください」と答えてください。
以下の背景情報を参照してください。情報がなければ、その内容については言及しないでください。
# 背景情報
{context}
# 質問
{question}"""
ここでは、チャットボットに対して、どのように応答を生成するかを指示する「プロンプト」を設定しています。
このプロンプトを制御することで、精度がかなり変わってきます。
{context}と{question}: プロンプト内にユーザーの質問と関連情報を挿入するためのプレースホルダです。
リトリーバーの設定
# リトリーバーが上位2つのドキュメントを返すように設定
retriever = db.as_retriever(search_kwargs={"k": 2})
ここでは、リトリーバー(検索機能)が、データベースから関連するドキュメントを取得する設定を行っています。
search_kwargs={"k": 2}: kというパラメータにより、検索結果の上位2つのドキュメントを返すように設定しています。この場合、質問に対して最も関連性の高い2つのドキュメントが選ばれます。
このいくつドキュメントを選ぶかによって、回答の精度が変わるので試してみてください。
質問応答システムの設定
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
この部分では、実際に質問応答システムを作成しています。
・llm=llm: 先ほど定義したGoogle Generative AIモデルを使用します。
・retriever=retriever: データベースから関連ドキュメントを取得するリトリーバーを設定します。
・return_source_documents=True: 質問に対する応答を生成する際に、使用された元のドキュメントも返すようにしています。
・chain_type_kwargs={"prompt": PROMPT}: チャットボットが応答を生成する際に使用するプロンプトを指定します。
応答生成関数の定義
def generate_answer(query):
content = qa.invoke(query)
# 応答文の表示
print("応答文:")
print(content["result"])
# 参照されたドキュメントを表示
print("\n参照元のURL:")
doc_urls = []
for doc in content["source_documents"]:
#既に出力したのは、出力しない
if doc.metadata["source_url"] not in doc_urls:
doc_urls.append(doc.metadata["source_url"])
print(doc.metadata["source_url"])
この関数では、ユーザーの質問に対して応答を生成し、その結果を表示します。
・qa.invoke(query): 質問(query)を使って、質問応答システムを呼び出し、応答を生成します。
・content["result"]: 生成された応答文です。これがユーザーに対する回答となります。
・content["source_documents"]: 質問に対して参考にしたドキュメントのリストです。それぞれのドキュメントのメタデータ(ここではsource_url)を使って、どのWebページから情報が取得されたかを表示しています。
・doc_urls: URLが重複して表示されないように、一度表示したURLはリストに追加して、同じURLが複数回出力されないようにしています。
実際の質問を処理
query = "ラララたかひらってどんな団体?"
generate_answer(query)
ここでは、具体的な質問「ラララたかひらってどんな団体?」を入力し、生成された応答と参照元のURLを表示しています。
ここまで、いったんRAGの技術を使った受け答えができるようになりました。
ここで、データベースへの格納の仕方を変えたり、プロンプトを変えたりするなど、ご自身でパラメータを調整して、いいものを作成してくだい。
チャットボットを作る編~まとめ
このコードは、ユーザーからの質問に対して、Google Generative AIを利用して適切な応答を生成するチャットボットの仕組みを実現しています。データベースから関連ドキュメントを検索し、その情報を元に応答を生成します。また、どのドキュメントを参照して回答が作られたのかも表示されるため、出典元の情報も確認できる仕組みになっています。
以下はチャットボットを作る編のコード全文です。
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# Geminiモデルを定義する
llm = ChatGoogleGenerativeAI(
google_api_key=userdata.get('GEMINI_API_KEY'),
model="gemini-1.5-flash",
temperature=1.0,
max_retries=2,
)
# オリジナルのSystem Instructionを定義する
prompt_template = """
あなたは、「ラララたかひら」という団体専用のチャットボットです。
背景情報を参考に、質問に対して団体の人間になりきって、質問に回答してくだい。
ラララたかひらに全く関係のない質問と思われる質問に関しては、「ラララたかひらに関係することについて聞いてください」と答えてください。
以下の背景情報を参照してください。情報がなければ、その内容については言及しないでください。
# 背景情報
{context}
# 質問
{question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# リトリーバーが上位2つのドキュメントを返すように設定
retriever = db.as_retriever(search_kwargs={"k": 5})
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
def generate_answer(query):
content = qa.invoke(query)
# 応答文の表示
print("応答文:")
print(content["result"])
# 参照されたドキュメントを表示
print("\n参照元のURL:")
doc_urls = []
for doc in content["source_documents"]:
#既に出力したのは、出力しない
if doc.metadata["source_url"] not in doc_urls:
doc_urls.append(doc.metadata["source_url"])
print(doc.metadata["source_url"])
query = "ラララたかひらってどんな団体?"
generate_answer(query)
Webアプリにする
先ほど、作ったものを、Webアプリにしていきます。
ここでは詳しい説明は省かせていただきます。RAGの動きとして、先ほど、チャットボットを作る編で説明した通りです。もしも、ご自身でパラメータを変更した場合は適宜、変更してください。
GoogleColabでやっている方は、まずは、以下コードを実行して、環境変数にAPIキーをいれます。
%env GOOGLE_API_KEY={userdata.get('GEMINI_API_KEY')}
以下のコードで、ウェブアプリのためのコードを書きます。実行してください。
GoogleColabでない方は、最初の一行はいりません。そして、app.pyとして保存してくだい。
%%writefile app.py
from langchain.chains import RetrievalQA
from langchain.schema import (SystemMessage, HumanMessage, AIMessage)
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS
import os
import streamlit as st
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.prompts import PromptTemplate
def load_db(embeddings):
return FAISS.load_local('faiss_store', embeddings, allow_dangerous_deserialization=True)
def init_page():
st.set_page_config(
page_title='オリジナルチャットボット',
page_icon='🧑💻',
)
def main():
embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001"
)
db = load_db(embeddings)
init_page()
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-flash",
temperature=0.0,
max_retries=2,
)
# オリジナルのSystem Instructionを定義する
prompt_template = """
あなたは、「ラララたかひら」という団体専用のチャットボットです。
背景情報を参考に、質問に対して団体の人間になりきって、質問に回答してくだい。
ラララたかひらに全く関係のない質問と思われる質問に関しては、「ラララたかひらに関係することについて聞いてください」と答えてください。
以下の背景情報を参照してください。情報がなければ、その内容については言及しないでください。
# 背景情報
{context}
# 質問
{question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}# システムプロンプトを追加
)
if "messages" not in st.session_state:
st.session_state.messages = []
if user_input := st.chat_input('質問しよう!'):
# 以前のチャットログを表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
print(user_input)
with st.chat_message('user'):
st.markdown(user_input)
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message('assistant'):
with st.spinner('Gemini is typing ...'):
response = qa.invoke(user_input)
st.markdown(response['result'])
#参考元を表示
doc_urls = []
for doc in response["source_documents"]:
#既に出力したのは、出力しない
if doc.metadata["source_url"] not in doc_urls:
doc_urls.append(doc.metadata["source_url"])
st.markdown(f"参考元:{doc.metadata['source_url']}")
st.session_state.messages.append({"role": "assistant", "content": response["result"]})
if __name__ == "__main__":
main()
GoogleColabの場合、以下のコードを実行してください。
!npm install -g localtunnel
!streamlit run app.py & sleep 3 && npx localtunnel --port 8501
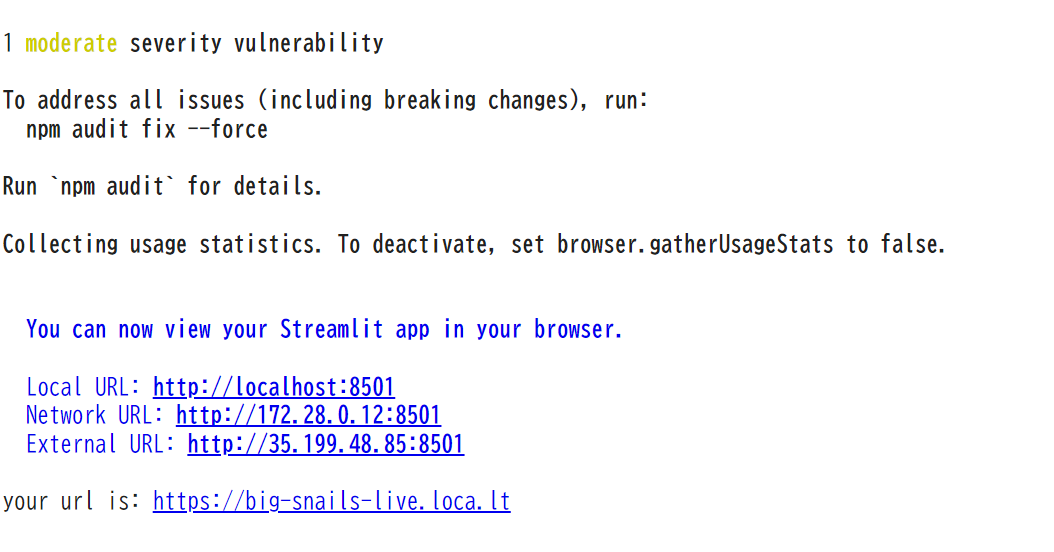
実行すると以下のようにでてくるので、your url is: https://big-snails-live.loca.lt
の部分を押してリンク開いてください。
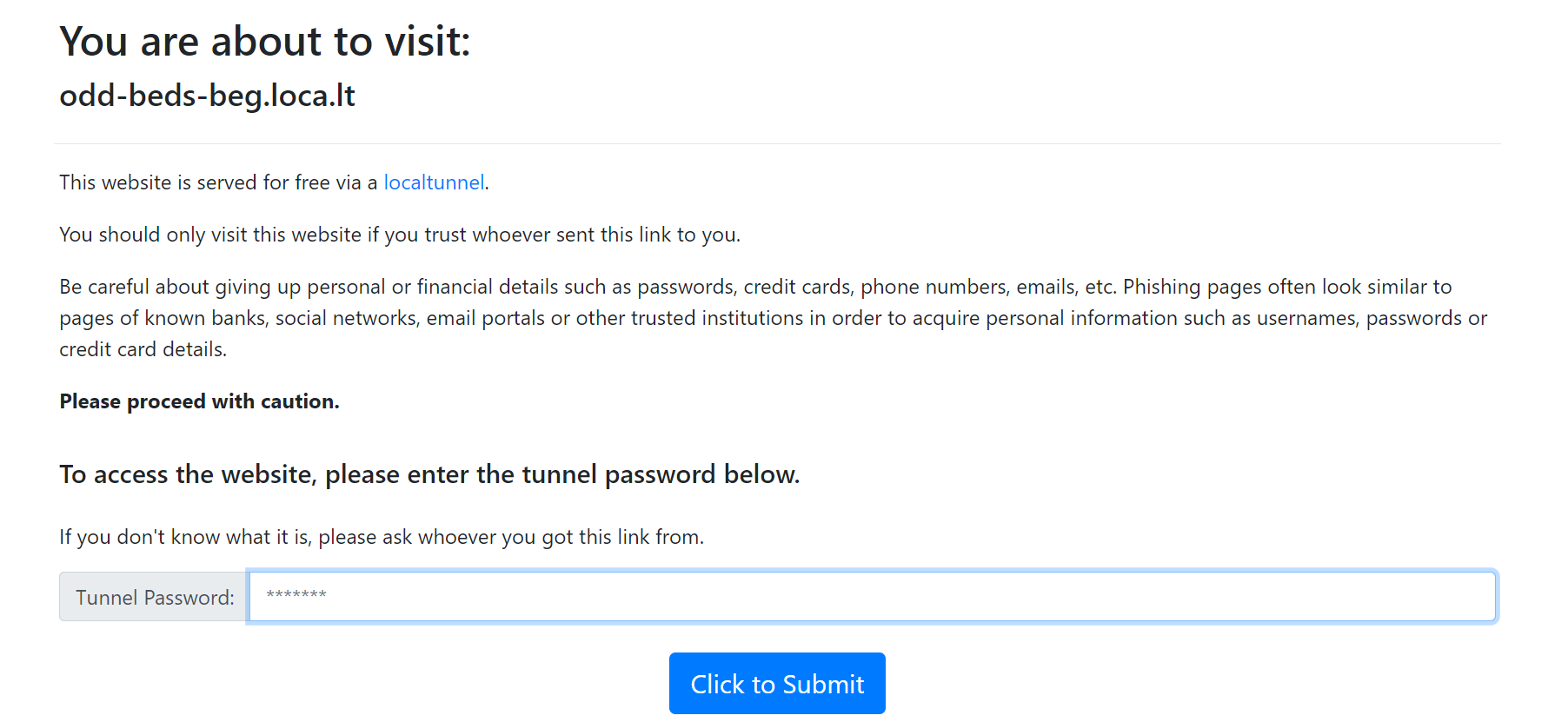
このような画面が出てくるので、先ほどの画面で出ていたExternal URLにでているアドレス を上記であれば、35.199.48.85を入力して、Click to Submitを押す。
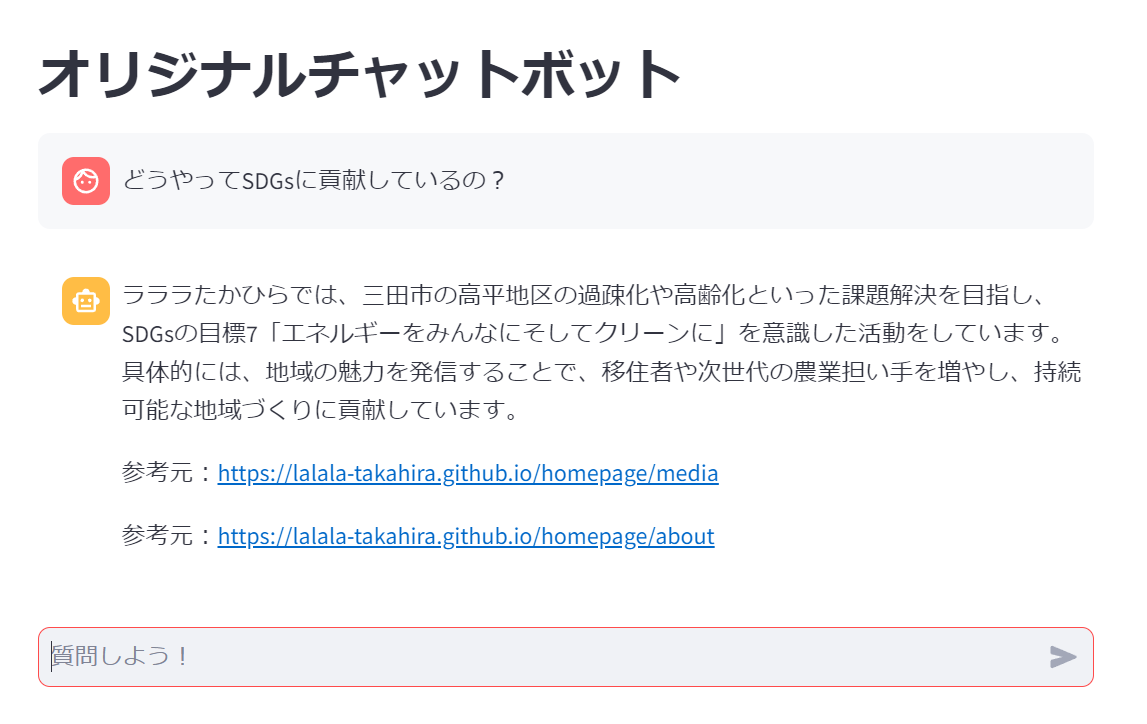
すると、以下のようにRAGのアプリがご自身の端末から使えるになります。
自分の環境で行っている場合は、streamlit run app.py でローカルでアプリを確認することができます。
ここまで、行けば完成です。ここからは、自分以外のユーザーでも使えるようにデプロイしていきます。
Webアプリをデプロイする
ここからは、Webアプリをデプロイする方法について解説していきます。
作成したチャットボットを実際にWebアプリとして公開するには、Streamlitを使って簡単にデプロイができます。ここでは、Streamlit Cloudを使ってWebアプリを公開する手順を紹介します。 他にも方法はたくさんありますが、これが一番簡単です。
GitHubにコードをアップロードする
まず、作成したアプリケーションのコードをGitHubのご自身のレポジトリにアップロードしていきます。
※GitHubについてわかない方は、こちら参考にするか、ご自身で調べてください。
また、GoogleColabでやっていた方は、以下のようにファイルの中に、データベースのフォルダ(faiss_store)と、app.pyというファイルができているのでダウンロードして、ご自身のGitHubのレポジトリにおいてください。
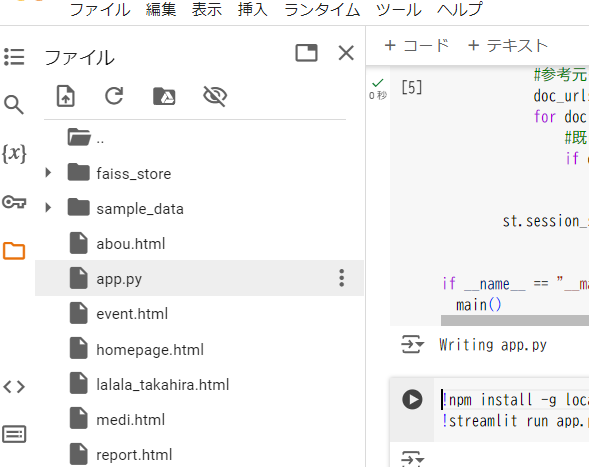
更に、requirements.txtというファイルを作ってレポジトリ内においてください。
streamlit
langchain
langchain_google_genai
faiss-cpu
langchain-community
レポジトリ内の構造はこうなっています。
├── app.py # Streamlitアプリケーションのメインファイル
├── faiss_store/ # FAISSのベクトルストアデータ
│ ├── index.faiss # ベクトルデータを格納したFAISSインデックスファイル
│ ├── index.pkl # メタデータを格納したピクルファイル(ドキュメント情報)
├── requirements.txt # 必要なライブラリ一覧
└── README.md # プロジェクトの概要説明(任意)
ここまでできたら、次に、Streamlit Cloudにアクセスして、GitHubのアカウントでサインインしてください。
すると、画面右上に、Create appとでているところタップすると以下のような画面が出てくるの左をタップします。
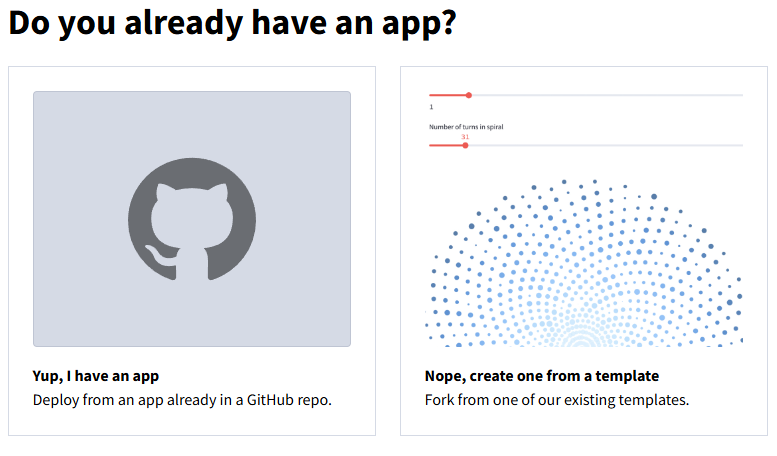
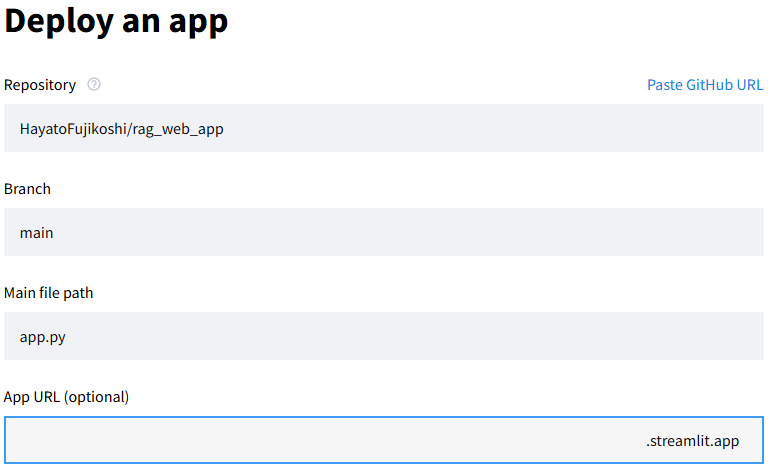
すると以下のような画面が出てくるので、ご自身のレポジトリ、ブランチ、メインファイル(app.py)を選択して、好きなurlを入力してください(既に存在しているurlは不可)
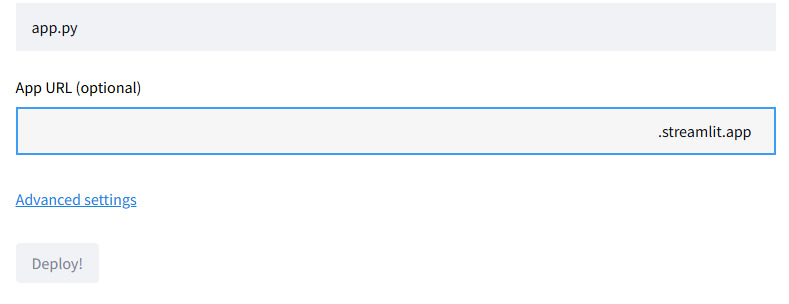
ここで,環境変数にAPIを設定するために、Advanced settingsを押します。
次に、このような画面が出てくるので、GOOGLE_API_KEY="ここにご自身のAPIキーをかく"
を設定してください。
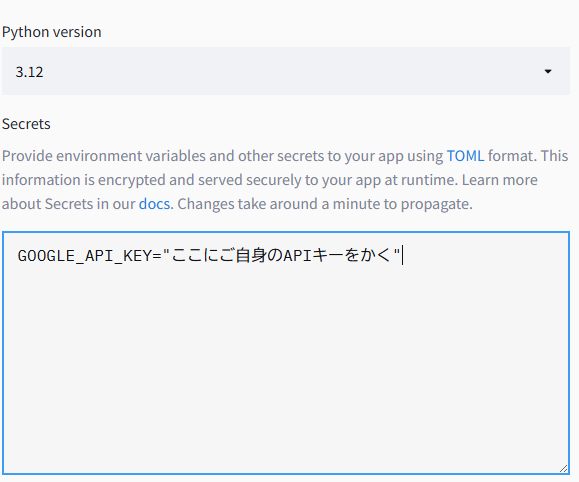
それができたら、後はDeploy!を押すだけで、数分でデプロイが完成します。
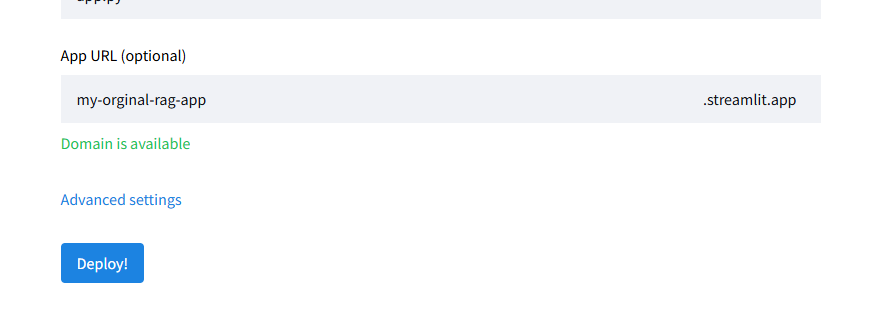
これで、ご自身が設定したURLからだれでもそのチャットボットを使うことができるようになります。
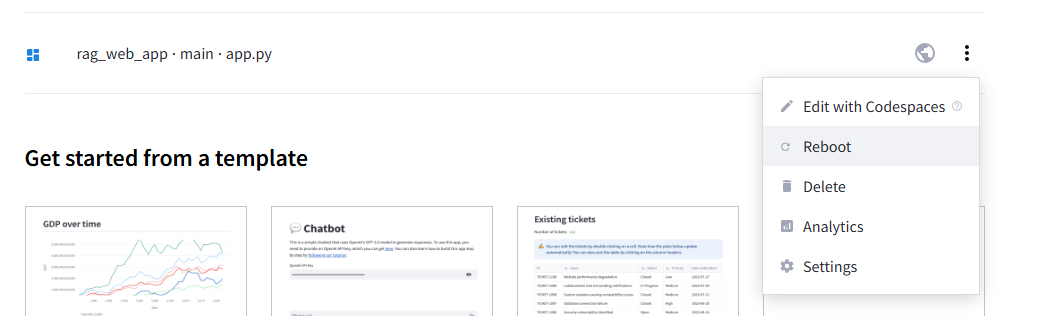
※変更もGitHubにあげている内容を変更して、以下の画面でRebootを押すだけで変更できます。
おわりに
今回の記事では、RAG(Retrieval-Augmented Generation)という技術を活用したオリジナルチャットボットを作成し、Streamlitを使ってWebアプリとしてデプロイするまでの一連の流れを解説しました。データの収集から、検索システムの構築、AIによる応答生成、そしてWeb上での公開まで、全体のプロセスを体験することができたと思います。
RAGは、シンプルなFAQシステムを超えて、ユーザーの質問に対してより自然で具体的な応答を提供する強力なツールです。特に、特定のドメインに関連する情報を提供する場合に非常に有効です。今回のチャットボットでは僕が運営している「ラララたかひら」という団体に焦点を当てましたが、さまざまな応用が考えられます。
このプロジェクトを通して、チャットボットの精度や応答の質は、使用するデータの量や質、プロンプトの設計によって大きく変わることが実感できたと思います。プロンプトの工夫次第で、より正確で自然な応答を引き出せる一方で、不適切なプロンプトや不十分なデータによっては、期待する結果が得られないこともあります。
さらに、FAISSを用いたベクトル検索によって、膨大なデータの中から関連性の高い情報を効率的に検索できることも学びました。今回はベクトル検索を使用しましたが、単語ベースの検索(例えば、従来のキーワード検索)を組み合わせる方法もあります。これにより、特定の単語に基づいた検索を強化し、より柔軟で多様な情報提供が可能になります。ベクトル検索とキーワード検索を使い分けることで、幅広いユースケースに対応できるチャットボットを構築することができるでしょう。
しかし、RAGには課題もあります。特に、AIが正しい情報に基づいていない答えを生成してしまう「ハルシネーション」の問題があります。AIモデルは、たとえ根拠がない場合でも応答を生成する能力を持つため、誤った情報を提供するリスクがあります。この問題を解決するためには、データソースの信頼性を高めることや、出典を明確に示すことが重要です。また、応答に含まれる情報の正確さをユーザーが検証できるように、生成された情報の出典元を常に確認できる仕組みを取り入れることも大切です。
今後、このチャットボットをさらに改善していくためには、データの追加やより高度なプロンプト設計の調整を試みてください。例えば、ベクトル検索だけでなく、従来の単語検索とのハイブリッドなアプローチを導入したり、ハルシネーションを抑えるための検証プロセスを追加したりすることが考えられます。また、他のAIモデルや検索エンジンと組み合わせることで、より多機能なアプリケーションの構築も視野に入れられるでしょう。
このプロジェクトを通して得た知識と経験を活かし、自分だけのオリジナルなアプリケーションを構築する楽しさを感じていただければ幸いです。今後も、さまざまなユースケースに応用して、新たな挑戦に取り組んでみてください!