はじめに
こんにちは!今回の記事では、私たちの日常生活でもよく耳にする「対話システム」についてご紹介します。たとえば、スマートスピーカーやカスタマーサポートのチャットボットなど、機械が人間の言葉を理解して答える技術がこれにあたります。
こうした対話システムの背後には、言葉の意味を理解し、適切な返答を生成するための高度な技術が使われています。この技術は「自然言語処理(NLP)」と呼ばれる分野の一部で、最近の周辺分野(本記事のタグ記載のような)の発展によって急速に進化しています。
この記事では、対話システムに関する研究の中でも、特に深層学習を活用した最新の手法について整理します。また、どのような場面で使われているのか、これからどのように進化していくのかについても触れていきます。
今回もアウトプットを出す過程で筆者自身の知識整理ができればと思っています。
参考文献
【補足】
- 本論文は2022年に発表された当該分野における比較的新しいサーベイ論文です。
- 近年発表された高品質な研究を包括的にレビューし、深層学習ベースのアプローチに焦点を当てることで、モデルの観点とシステムの観点から最先端の研究に関する洞察を提供してくれています。
- 本記事において、いくつか情報が不足していたり、わかりにくい箇所がありましたら、ぜひリンクから元の論文を読んでみてください。
対話システムとは?
- 対話システムとは、人間の言語を理解し、適切な応答を生成することで、人間と自然な形でコミュニケーションを取ることを目的としたシステムです。現実世界での応用が期待されるため、自然言語処理(NLP)の中でも人気のあるタスクの一つです。
- 一方で、対話システムを構築するには、自然言語理解、対話状態追跡、自然言語生成等の複数のタスクを組み合わせる必要があり、そのタスクは非常に高度かつ複雑な課題でもあります。
- また、近年の対話システムでは深層学習技術が活用されることが主流となり、従来手法よりも高い性能を発揮しています。
対話システムの種類
対話システムは、人間と会話を通じて雑談を行ったり、アシスタントとして機能する技術です。用途に応じて、以下の2つに分類されます。
-
タスク指向型対話システム(Task-Oriented Dialogue Systems, TOD)
映画チケットの予約やレストランのテーブル予約など、特定の分野での具体的な問題解決を目的とします。 -
オープンドメイン対話システム(Open-Domain Dialogue Systems, OOD)
特定のタスクや分野に制約されず、自由にユーザーと会話を行うことを目的とします。完全にデータ駆動型であることが一般的です。
タスク指向型とオープンドメイン型対話システムのアプローチ(概要)
タスク指向型対話システム
従来のタスク指向型対話システムは、以下の4つのモジュールからなるパイプライン構造で設計されています:
- 自然言語理解(NLU, Natural Language Understanding)
- 対話状態追跡(DST, Dialogue State Tracking)
- 方策学習(PL, Policy Learning)
- 自然言語生成(NLG, Natural Language Generation)

※ 近年では、これらを統合したエンドツーエンド方式が主流となり、パフォーマンスの向上が図られています。
オープンドメイン対話システム
オープンドメイン型システムは以下の3つのアプローチに分類されます:
-
生成型システム(generative systems)
文脈に応じて柔軟な応答を生成するが、一貫性や創造性に欠ける場合がある。 -
検索型システム(retrieval-based systems)
応答セットから最適なものを選択し、高い表面的な一貫性を持つが、応答セットの有限性が制約となる。 -
アンサンブルシステム(ensemble systems)
生成型と検索型を組み合わせ、検索応答を生成で改善するなど、両方の長所を活用する。
【研究論文例】
これらの手法は、対話の目的や特性に応じて使い分けられています。
タスク指向型対話システム
- タスク指向型対話システムは、ユーザーのメッセージを正確に処理することを目的としているため、厳密な応答制約が求められます。そのため、より制御可能な形で応答を生成するためにモジュール型の手法が提案されてきました。
- 構成図は前章に示しましたが、本節ではその1つ1つのモジュールについて詳細に掘り下げます。
自然言語理解(Natural Language Understanding, NLU)
役割
- ユーザーの入力メッセージをセマンティックスロット(=ユーザーの発話に含まれる意味的な情報を構造化して表現するための「属性名」と「値」のペア)に変換し、ドメイン分類、意図検出、スロット埋めを実行。
主要タスク
- ドメイン分類: 入力を特定のドメインにマッピングする分類タスク
- 意図検出: 入力の目的や意図を予測する分類タスク
- スロット埋め: ユーザー入力をタグ付けし、情報を抽出するシーケンス分類タスク
-
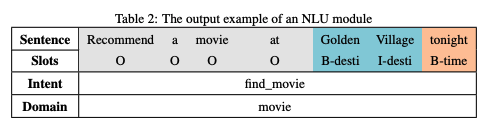
ドメイン分類と意図検出は分類問題であり、入力された言語列を事前定義されたラベルセットにマッピングするために分類器を使用します。例では、予測されたドメインが「movie(映画)」、意図が「find_movie(映画を探す)」です。
-
スロット埋めはタグ付け問題であり、シーケンス間のマッピングタスクとして扱われます。例えば、発話「Recommend a movie at Golden Village tonight.」では、「Golden Village」は場所として認識され「B_desti(開始チャンク)」「I_desti(内部チャンク)」にタグ付けされ、「tonight」は「B_time」として時間を表します。関連しない単語は「O」でタグ付けされます。この手法は名前付きエンティティ認識(NER)で一般的なIOBタグ付け(Inside-Outside-Beginning)を利用しています。
技術動向
※ 少し込み入った話になりますので、必要に応じてスキップしてください。
※ 以下で登場するいくつかの研究は関連研究に記載します。
ドメイン分類と意図検出
- 初期の研究では、Deep Convex Networkが対話意図の認識精度を向上させ(Deng 2012)、分類の基礎を築きました。
- 半教師付き学習を用いたフレームワーク(Yann et al., 2014)や、Restricted Boltzmann Machine(RBM) や Deep Belief Networks(DBN)(Sarikaya et al., 2014)を活用したモデルが、ニューラルネットワークの効率的なトレーニングを実現しました
- RNNを発話エンコーダとして利用し、文脈情報を考慮した意図検出(Ravuri, 2015)や、CNNを用いて短い発話の階層的特徴を抽出する手法(Hashemi et al., 2016)が提案されました。
- 最近では、Task-Oriented Dialogue BERT(TOD-BERT)(Wu et al., 2020)が事前学習を通じて高い精度を達成し、少ないデータでのfew-shot学習の可能性を広げました。
スロット埋め
- 初期には、DBNを初期化に使用してシーケンスタグ付けを行う研究(Sarikaya et al., 2011)や、従来のNER特徴に品詞や構文情報を統合する手法(Deoras & Sarikaya, 2013)が提案されました。
- (深層学習の活用)Recurrent Neural Networks(RNNs)を使用したシーケンスタグ付け(Yao et al., 2013)は、シーケンスデータを活用して高い精度を達成しました。LSTMはATISデータセットで特に高い精度を示し、ゲート機構を活用して文脈情報を効果的に保持できることがしまされました(Yao et al., 2014)。
- 最近の研究では、テンプレートベースの木構造デコーディング(Gangadharaiah & Narayanaswamy, 2020)や、会話型事前学習モデル(ConveRT)を使用したスパン抽出(Coope et al., 2020)など、新たなアプローチが提案されています
統合版(ドメイン分類/意図検出/スロット埋め)
- ドメイン分類、意図検出、スロット埋めを統合することにより、タスク指向型対話システムの効率性や柔軟性が大幅に向上します。これにより、これらのタスクを単一のフレームワークで最適化できるようになりました。
- 2016年に、双方向RNN-LSTMを使用して3つのタスクを同時に実行するマルチタスク学習(Hakkani-Tür et al., 2016)、RNNエンコーダデコーダモデルに注意機構を導入し、スロット埋めと意図検出を統合(Liu & Lane, 2016)が提案されました。
- 最近では、エンドツーエンドメモリーネットワーク(Chen et al., 2016)(履歴の発話から意図とスロット値を保存し、注意機構を用いて重要な情報を抽出する手法)やCapsule Networksを用いて対話の階層的なセマンティクスをモデル化(Zhang et al., 2018)するアプローチが提案されています。
- また、音声信号を直接処理する手法(Singla et al., 2020)や、NLUとNLGの双方向性を活用するデュアル学習フレームワーク(Su et al., 2019)はさらに発展的な手法として注目されています。
関連研究
ドメイン分類と意図検出
-
Deng, L., Tur, G., He, X., & Hakkani-Tur, D. (2012). Use of kernel deep convex networks and end-to-end learning for spoken language understanding. In 2012 IEEE Spoken Language Technology Workshop (SLT) (pp. 210-215).
深層凸ネットワーク(deep convex networks)を構築し、事前ネットワークと現在の発話の予測を統合することで、対話意図の認識精度を向上。 -
Yann N. Dauphin, Gokhan Tur, Dilek Hakkani-Tur, & Larry Heck. (2014). Zero-Shot Learning for Semantic Utterance Classification.
半教師付き方式で、対話のドメインと意図を分類する深層学習フレームワークを開発。 -
Sarikaya, R., Hinton, G., & Deoras, A. (2014). Application of Deep Belief Networks for Natural Language Understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(4), 778-784.
Restricted Boltzmann Machine(RBM)やDeep Belief Networks(DBN)を使用してニューラルネットワークの初期パラメータを学習し、トレーニングの難しさを軽減。 -
Ravuri, S., Stolcke, A. (2015) Recurrent neural network and LSTM models for lexical utterance classification. Proc. Interspeech 2015, 135-139, doi: 10.21437/Interspeech.2015-42
RNNを使用して発話エンコーダとして、対話の意図とドメインカテゴリを予測する手法を提案。 -
Hashemi, H.B. (2016). Query Intent Detection using Convolutional Neural Networks.
CNNを使用して意図検出のための階層的なテキスト特徴を抽出し、短い発話の分類性能を向上。 -
Chien-Sheng Wu, Steven Hoi, Richard Socher, & Caiming Xiong. (2020). TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue.
Task-Oriented Dialogue BERT(TOD-BERT)を事前トレーニングし、意図検出のサブタスクで精度を大幅に向上。少ないデータでも高い精度を実現。
対話状態追跡(Dialogue State Tracking, DST)
役割
- 対話状態追跡(DST)は、ユーザーの目的や関連情報を追跡し、方策学習(Policy Learning)モジュールが対話システムの行動を決定するための基礎データを提供します。
NLUとDSTの違い
- NLU(自然言語理解): 現在のユーザー発話に含まれる意図やドメイン、スロット情報を抽出し、タグ付けを行います。
- DST: 対話履歴全体を基に、事前定義されたスロットリストを埋め、ユーザーの目的や状態を管理します。
例: 発話「Recommend a movie at Golden Village tonight.」
- NLUの出力: 「inform(domain=movie; destination=Golden Village; date=today; time=evening)」
-
DST:
- スロットリスト:「intent : []; domain : []; destination : []; date : []」
- モジュールはDSTモジュールは全対話履歴を確認して特定のスロットに入力できる内容を決定します。
- 出力:「intent: inform; domain: movie; destination: Golden Village; date: today」
- まとめると、NLUモジュールは「ユーザーメッセージをタグ付けすること」を目的とし、DSTモジュールは「ユーザーメッセージから値を見つけ出して事前定義されたフォームに埋め込むこと」を目的としています。
- NLUモジュールの出力をDSTモジュールの入力として使用するものや、生のユーザーメッセージを直接使用して状態を追跡するものがあります。
技術動向
- 初期の研究では、(hand-craft)ルールベースの手法や統計的な手法が取られていましたが、それぞれ、ドメイン適応性の低さやノイズへの頑弱性の課題がありました。そのような課題を解決するためのアプローチとして、ニューラルネットワークを活用した手法が登場しました。
- また、ニューラルネットワークベースのアプローチにおいても、スロットが事前に固定されているかどうかという点でさらに細分化することが可能です。
※ここから込み入った話
事前定義されたスロット名と値を持つ手法
- このアプローチでは、対話履歴に基づて最も適切なスロットと値のペアを見つけることを目的とします。
- 各ターンで、事前定義されたスロットリストに基づいて値を選択する形を取ります。
- マルチクラス分類またはマルチホップ分類タスクとして扱われます。
- マルチタスク分類
- トラッカーは複数の値の中から正しいクラスを予測
- マルチホップ分類
- 各スロットと値のペアを個別に扱い、順次バイナリ予測を行う手法
- スロット値ペアを選択し、確率を予測。
- マルチタスク分類
固定されていないスロット名と値を持つ手法
- このアプローチでは、対話コンテキストから直接値を抽出したり、対話コンテキストに基づいて値を生成します。
- 固定されたスロットリストに依存しないため、より柔軟性が高く、特に新しいドメインに適応する際に有利です。
- このアプローチはDST(Dialogue State Tracking)タスクのモデルや時間的な複雑性を削減し、タスク指向型対話システムのエンドツーエンドトレーニングを可能にするため、注目を集めています。また、対象ドメインが変更された際にも柔軟に適応できるという利点があります。
関連研究
事前定義されたスロット名と値を持つ手法
- Henderson et al. (2013): DSTタスクに初めてディープラーニングモデルを適用。多くの特徴量(例: SLUスコア、ランクスコア、肯定スコアなど)をニューラルネットワークの入力として統合し、各スロットと値のペアの確率を予測しました。
- Mrkšic et al. (2015): RNNをニューラルトラッカーとして使用し、対話コンテキストを考慮した追跡を実現しました。
- Mrkšic et al. (2016): マルチホップニューラルトラッカーを提案。システムの出力とユーザーの発話を最初の2つの入力として使用し、候補のスロットと値のペアを3番目の入力として利用することで対話履歴をモデル化。最終的に、現在のスロットと値のペアに対してバイナリ予測を行う手法を導入しました。
固定されていないスロット名と値を持つ手法
-
Lei et al. (2018): ユーザーの対話履歴から、特定のスロット(予約する日付や場所など)に対応するテキストを抜き出す「Belief Span」を提案しました。この方法では、2段階の仕組みを使って、スロット値をコピーして保存することで、未知の単語にも対応できる柔軟な追跡精度を実現しました。
-
Lin et al. (2020): 必要な部分だけを効率的に更新する「Minimal Belief Span」という仕組みを活用し、会話の中でのスロットの情報を管理する「MinTLフレームワーク」を提案しました。この方法では、新しい情報が追加された場合でも、古い情報を全て作り直さずに必要な箇所だけを更新できるようにしました。
-
Wu et al. (2019): 会話の文脈(ユーザーとシステム間のやりとり全体)を考慮しながら、動的にスロット値を生成する「TRADEモデル」を提案しました。この方法では、対話の流れに応じて柔軟にスロットの値を決定でき、幅広い場面に適応可能です。
-
Cheng et al. (2020): 会話の状態(ユーザーの目的や要求に関する情報)を木構造(階層的に整理されたデータの形)で表現する「Tree Encoder-Decoder(TED)」を提案しました。この方法では、過去の会話の履歴を基に、現在の会話ターンに必要な情報を生成し、正確な応答を作ることが可能になりました。
-
Chen et al. (2020a): ユーザーとシステムのやりとりの依存関係(会話のつながりや関連性)を活用する「インタラクティブエンコーダ」を構築しました。また、「注意機構(重要な情報に注目して処理する仕組み)」を使用して、ユーザーとシステムそれぞれのスロット情報を整理しました。この手法により、会話の文脈(これまでの対話内容)から必要な値をコピーするための基盤を作りました。
-
Shan et al. (2020): 言語モデルBERTを用いてマルチタスク学習(複数のタスクを同時に学習させる方法)を行い、対話状態を生成しました。このモデルは、単語レベルとターン(会話の一往復)レベルの情報を整理した後、それらの情報から重要なスロット値を取得しました。この取得した情報をもとに、スロットの値を予測する仕組みを構築しました。
-
Wang et al. (2020e): Shanらと同様にBERTを活用しましたが、スロット値の予測をさらに強化するために「Slot Attention(SA)」を導入しました。SAは、スロットに関連する情報を選び出す仕組みで、取得した情報を「Value Normalization(VN)」という方法で最終的なスロット値に変換しました。
-
Huang et al. (2020c): 「Meta-Reinforced MultiDomain State Generator(MERET)」という対話状態生成モデルを提案しました。このモデルでは、「ポリシー勾配強化学習(AIが最適な動作を学習する手法の一種)」を用いてさらに調整を加え、多様なドメインに対応する柔軟性を実現しました。
ポリシー学習(Policy Learning, PL)
役割
-
ポリシー学習モジュールは、システムがどのアクションを取るべきかを制御する役割を持ちます。このモジュールでは、DSTモジュールの出力をもとに、現在の対話状態と可能なアクションの中から最適なアクションを選択します。
-
具体的には、現在のターンの対話状態 $S_t$ とアクションセット $A = \lbrace a_1, ..., a_n \rbrace $ が与えられた場合、このモジュールのタスクは、以下のようなマッピング関数を学習することでと定義できます。:
f: S_t → a_i \in A
-
このタスクは定義自体は他のモジュールよりも比較的シンプルですが、実際には複雑な状況を考慮する必要があるため、非常に難しい課題です。
- 例として、映画のチケット予約やレストランのテーブル予約を考えます。ユーザーが2時間の映画を予約した後、夕食を予定している場合、映画終了後の移動時間を考慮し、映画館からレストランまでの時間差を2時間以上にする必要があります。
ポリシー学習は単純なルールではなく、文脈に応じた高度な判断を行う必要があります。
教師あり学習と強化学習
- 対話ポリシー学習では、教師あり学習と強化学習が主流のトレーニング手法として利用されています。
- 近年の対話ポリシー学習に関する研究は、ほぼすべてが強化学習の手法に基づいています。
教師あり学習
- 教師あり学習によるポリシーは優れた意思決定能力を発揮することが示されています(Su et al., 2016; Dhingra et al., 2016; Williams et al., 2017; Liu and Lane, 2017)。
- しかし、そのトレーニングプロセスは完全にトレーニングデータの品質に依存します。さらに、アノテーション付きデータセットの作成には膨大な人的労力が必要であり、意思決定能力は特定のタスクやドメインに制限され、汎用性が低いことが課題です。
強化学習
- 強化学習手法の普及に伴い、多くのタスク指向型対話システムが強化学習を使用してポリシーを学習しています。
- 対話ポリシー学習は、エージェントが環境状態をアクションにマッピングする強化学習の仕組みに適合しています。
- 強化学習により、柔軟なポリシーの学習が可能になります。
- 学習のシナリオでゼロからポリシーを学習するのはデータや時間の消費が大きいため、トレーニングプロセスを高速化する「ウォームスタート」手法がとられます。
強化学習がなぜ適合できるのか
強化学習概説
-
強化学習は、特定の環境との相互作用を通じて、適切な行動を取るエージェントを訓練することを目的とした機械学習の一分野です。教師あり学習や教師なし学習と並ぶ機械学習の3つの基本的な分野の1つとして位置付けられています。
-
以下に参考文献より引用した強化学習の概念図を示します。

このフレームワークは「マルコフ決定過程(MDP)」として記述され、以下の5つの要素で構成されます:
- $S$(環境状態の集合): 現在の環境の状態を表す要素の集合。
- $A$(アクションの集合): エージェントが選択可能な行動の集合。
- $P$(状態遷移確率行列): ある状態で特定のアクションを実行したとき、次に遷移する状態の確率を示す。
- $R$(報酬): 状態と行動に基づいてエージェントが環境から得る報酬。
- $\gamma$(割引率): 将来の報酬をどれだけ重要視するかを決める値(0~1の範囲)。
フレームワークの流れ
- 観測とアクション選択: エージェントは現在の環境状態 $s_t$ を観測し、ポリシー(行動選択ルール)に基づいてアクションを選択します。
- 状態遷移と報酬取得: 環境は状態遷移確率 $P$ に基づいて次の状態 $s_{t+1}$ に遷移し、報酬 $r_t$ をエージェントに与えます。
このループを繰り返すことで、エージェントは最適な行動を学習していきます。
なぜ適合できるのか
-
対話ポリシー学習の本質は、システム(エージェント)がユーザー(環境)と対話を通じて適切なアクションを学習することです。
-
強化学習は、状態(ユーザーの発話や対話状態)をアクション(システムの応答や操作)にマッピングするポリシーを学習するための枠組みを提供します。
-
報酬(Reward)の仕組みを通じて、エージェントは「良い応答」と「悪い応答」を区別できるようになります。
-
強化学習(Reinforcement Learning, RL)が対話システムのポリシー学習(Policy Learning, PL)に適合する理由は、対話システムの構造と特性が強化学習のフレームワークと自然に一致するためです。
-
強化学習では、エージェントは環境の状態を観測し、その状態に基づいて最適な行動を選択するポリシーを学習します。同様に、対話システムにおけるポリシー学習の目的も、ユーザーの発話(環境の状態)に基づいて適切な応答(行動)を生成することです。さらに、強化学習の報酬システムは、対話の成功や失敗を数値的に評価する手段として機能し、対話の質を向上させる方向にエージェントを導きます。
-
また、対話システムのポリシー学習では、特定の状況における応答が将来の対話全体に与える影響を考慮する必要があります。このような長期的な影響の評価は、強化学習の報酬割引率(discount factor)を利用することで実現可能です。これにより、エージェントは現在の行動が将来の報酬にどのように影響するかを学習し、より優れた意思決定を行うことができます。
-
さらに、強化学習のオンライン学習(=データがリアルタイムで到着する環境下で、モデルがその場で学習を行い、即座に適応する手法)能力は、実際の対話データを利用して継続的にポリシーを改善するのに役立ちます。これは、事前にラベル付けされたデータに完全に依存する教師あり学習では実現が難しい柔軟性を提供します。特に、ユーザーの多様な行動や未知の状況に対応するために、リアルタイムで適応する能力は、強化学習を対話システムに適用する上で大きな利点です。
-
これらの特性により、強化学習は対話システムのポリシー学習において、応答の最適化、ユーザー体験の向上、未知の状況への適応など、多くの面で有効なアプローチとなっています。
関連研究
ポリシー学習
-
Zhang et al. (2019): ユーザーとの対話を「予算」として扱い、効率的な学習を行う手法「Budget-Conscious Scheduling (BCS)」を提案。
- 確率的スケジューラーを用いて予算を配分。
- 実際のユーザーインタラクションとシミュレーションを選択的に利用。
- ゴールベースの経験シミュレーションにより、限られたインタラクションでも高い学習性能を達成。
-
Takanobu et al. (2020): 2つのAIエージェントが互いにユーザーとシステム役割を演じながら学習する「Multi-Agent Dialog Policy Learning」を提案。
- 役割ごとの報酬設計で応答生成を促進。
- 高いタスク完了率を実現。
-
Wang et al. (2020): 意思決定時にモンテカルロ木探索(MCTS)を行う新しいプランニング手法「MCTS-DDU」を提案。
- 対話状態を効率的に探索。
- リアルタイムでの意思決定を強化。
-
Gordon-Hall et al. (2020): 専門家の模範データを使ってAIをトレーニングする「DQfD(Demonstrationsによる深層Q学習)」を提案。
- ドメイン適応を容易にする「Reinforced Fine-tune Learning」を導入。
- 学習効率を向上。
-
Huang et al. (2020): 専門家のデモ(模範例)を活用して、対話の進行を制約する革新的な報酬学習手法を提案。
- アノテーション済み・未済みのデータを柔軟に利用可能。
- 人的労力を削減。
-
Wang et al. (2020): 対話の意味構造を維持するため、アクション(行動)と応答を同時に生成する手法を提案。
- 一貫性のある対話生成を実現。
-
Le et al. (2020): 対話状態追跡・ポリシー学習・応答生成を1つに統合したフレームワークを提案。
- 各サブタスクの性能向上。
- 複数のドメイン(応用範囲)への適応力を強化。
-
Xu et al. (2020): 知識グラフを活用して行動選択に事前知識を提供する手法を提案。
- 長期的な視点で報酬を得られる設計。
- 学習の質と効率を向上。
自然言語生成 (Natural Language Generation, NLG)
役割
- 生成された対話アクションを、最終的な自然言語表現に変換する役割を担います。
- 例えば、ポリシー学習モジュールから「Inform (name = Wonder Woman; genre = Action; desti = Golden Village)」という対話アクションが生成された場合、NLGモジュールはこれを「There is an action movie named Wonder Woman at Golden Village.(ゴールデンビレッジで上映されているアクション映画の名前はワンダーウーマンです)」のような言語表現に変換します。
技術動向
従来型NLGのパイプラインシステム
- 従来型の自然言語生成(NLG)は、以下の3つのモジュールで構成されたパイプライン方式を採用していました。
-
内容決定(Content Determination): ユーザーに伝えるべき情報を選択。
-
文計画(Sentence Planning): 選択した情報をどのような文構造で表現するか計画。
-
表現実現(Surface Realization): 文法に基づいて最終的な自然言語の文を生成。

-
課題
-
モジュール間の情報伝達の曖昧さ
- 各モジュールが独立して処理を行うため、必要な文脈情報が欠落することがあります。例えば、内容決定で「場所の情報」を選択しても、その情報が文計画や表現実現の段階で適切に解釈されず、曖昧な出力になることがあります。
-
文脈を考慮できない構造
- パイプライン方式では、現在のターン(会話の一つの応答)だけを処理対象とし、過去の会話履歴やユーザーの意図を考慮しません。その結果、会話全体の流れを反映した自然な応答を生成するのが困難になります。
例: 「上映中の映画は?」という質問に対し、次のターンで「ゴールデンビレッジで何かありますか?」と聞かれても、システムは「映画の情報」を考慮できず文脈から外れた回答を返す可能性があります。
- パイプライン方式では、現在のターン(会話の一つの応答)だけを処理対象とし、過去の会話履歴やユーザーの意図を考慮しません。その結果、会話全体の流れを反映した自然な応答を生成するのが困難になります。
-
入力データの曖昧さ
- 従来型のNLGは、入力(例: 「Inform (name=Wonder Woman; genre=Action)」)が簡略化されており、詳細な情報や文脈が不足しています。このため、応答が機械的で、ユーザーにとって不自然に感じられることがあります。
エンドツーエンド(End-to-End)NLGの登場
-
これらの課題を克服するため、最近では深層学習を活用したエンドツーエンドNLGが採用され、文脈を考慮した自然な応答生成が可能になっています。
-
当該手法では、入力された対話アクションをそのまま自然言語に変換します。
-
Wenら(2015)は、「言語生成はデータ駆動型であるべきで、ルールに依存すべきではない」と主張し、以下の学習モジュールを活用することで、性能を改善させました。
-
RNN(再帰型ニューラルネットワーク)
- 会話の前後関係や長期的な依存関係や入力間の順序を考慮しながら応答を生成します。
- これにより、文法や意味的にも自然な応答と適切な内容を実現します。
-
CNNリランキング
- 複数の応答候補を生成し、その中から最適なものを選択します。
-
RNN(再帰型ニューラルネットワーク)
-
その後も、文脈認識性(文脈を考慮した上での応答生成)やドメイン適応性を向上させるためにLSTM(Zhouら(2016))や事前学習モデルの適用(Wenら(2016))などを試みる研究が発表されています。
☺️近年見られる音声アシスタントやチャットbotの急速な成長を考えると、当該研究の発展のスピードや活発さがに関して実感がモテるのではないでしょうか。
タスク指向型対話システムをEnd-to-Endで
手法の概要
-
エンドツーエンドにできた方が何かと楽そうであることは直感的にわかるのですが、「具体的にはどんな嬉しさがあるのか」という疑問について、前節までで説明したモジュール側のシステムにおける2つの欠点に対処できるという点が主な利点として挙げられます。
-
非微分可能性の問題
- 多くのパイプラインシステムにおいて、モジュールが非微分可能である場合があります。その結果、システム全体の出力エラーを各モジュールに遡って伝播することができません。
- 特に実際の対話システムの訓練では、唯一のフィードバック信号がユーザーの応答であることが多く、対話状態や対話行動といった他の教師信号は非常に限られています。
-
モジュール間の相互依存性の問題
- 特定のモジュールを改良しても、システム全体の応答精度や品質が向上するとは限りません。このため、他のモジュールに対する追加の訓練が必要となり、これが人的コストや時間を多く要する原因となります。
- さらに、パイプライン型タスク指向システムでは対話状態などの手動設計された特徴を使用するため、あらかじめ定義されたモジュール間の関係について修正が必要となり、別のドメインへの適用が困難です。
-
非微分可能性の問題
-
これらの問題に対処するために、タスク指向対話システムにおけるエンドツーエンド訓練の方法が2つ提案されています:
-
パイプライン全体の微分可能化
微分可能性を確保するための課題(知識ベースクエリ)と解決策
-
様々なモデルの開発や改善が進んだことにより、多くのモジュールが微分可能になり、エンドツーエンドでの訓練が可能となりました。しかし、いまだに微分を困難にする課題が存在します。その一つが 知識ベース(Knowledge Base, KB)クエリです。(レストランの空席情報などの外部知識リソースから情報を取得する必要がある)
-
従来のシステムでは、知識を探す際に「条件を指定してその条件に合う情報を探す」という方法が使われてきました。たとえば、「イタリア料理を出すお店で、20時に空いている席を探す」といった条件に基づいてデータベースから情報を検索するイメージです。しかし、このような方法には以下の問題がありました:
-
全体を一つの仕組みとして学習できない
- システムの一部(たとえば検索機能)が別の仕組みで動いていると、全体を一度に学習することができません。このため、個別に作業する必要があり、手間がかかります。
-
柔軟性が低い
- あらかじめ決められた方法でしか情報を探せないので、新しいタイプの質問や別の目的に対応するのが難しいことがあります。
-
-
上記の課題を解決するために、新しい方法が提案されました。(システム全体を一つの仕組みとして訓練することが可能になる)
-
知識の検索を柔軟にする仕組み
ユーザーの発言と知識ベースの情報を「関連性」で結びつける仕組みが導入されました。たとえば、ユーザーが「夜に空いているイタリアンのお店はどこ?」と聞いた場合、システムはその発言と「空席情報」や「料理の種類」といったデータを直接つなげて、関連性が高いものを見つけます。 -
あいまいな情報を扱う方法
従来の「完全一致」を求める検索ではなく、少しあいまいでも関連性が高そうな情報を見つける仕組みを使います。たとえば、ユーザーが「夜ご飯にイタリアンが食べたい」と言った場合でも、「イタリア料理」や「夕食時の空席情報」を結びつけて検索するようになります。 -
柔軟な応答の生成
システムは、途中の作業結果(たとえば、ユーザーが求めている条件や検索結果)を分かりやすい形で保存します。これにより、外部のシステムとも簡単にやり取りできる上、途中で何が起こったかを確認しやすくなります。
-
関連研究(知識ベースクエリの微分可能化へのアプローチ)
最近の研究では、知識ベースクエリを微分可能にするために、以下のような方法が提案されています。
Key-Value Memory Networks
- Miller et al. (2016) によって提案された Key-Value Memory Networks を使用し、Eric and Manning (2017) は発話表現と知識ベース内のキー表現の関連性を計算するために、注意機構(attention mechanism) を組み込んだキー・バリュー検索メカニズムを導入しました。これにより、関連する知識を効率的に取得可能としました。
Soft Retrieval Mechanism
- Dhingra et al. (2016) は、知識ベース内のエントリを「soft」な事後分布として扱う soft retrieval mechanism を提案しました。この手法では、シンボリッククエリ(ex.'料理の種類 = "イタリアン" AND 空席あり = TRUE')の代わりにソフト検索(あいまいな検索から関連度の高い知識を取得)を使用します。さらに、これを強化学習フレームワークに統合し、ユーザーからのフィードバックを基にエンドツーエンドの訓練を実現しました。
Hybrid Code Networks (HCNs)
- Williams et al. (2017) は、Hybrid Code Networks (HCNs) を提案しました。これは、ドメイン固有の知識をソフトウェアやシステムアクションテンプレートとしてエンコードし、知識取得モジュールを微分可能にしました。明示的に対話状態をモデル化するのではなく、潜在表現を学習し、教師あり学習と強化学習を併用して最適化を行いました。
GPT-2を用いたニューラルパイプライン
-
Ham et al. (2020) は、GPT-2を用いてパイプラインを構築しました。
-
各モジュールが明示的な中間結果を出力するため、解釈可能性が高く、外部システムとの連携も容易です。
-
-
単一のエンドツーエンドモジュールの使用
- この方法では複雑なモデルを使用して主要な機能を暗黙的に表現し、モジュールを統合します。通常、マルチタスク学習を採用したモデルが用いられます。
関連研究
Uncertainty Estimation Module
- Wang et al. (2019) は 不確実性推定モジュール を利用し、生成された応答の信頼度を評価しました。信頼度が高ければその応答を採用し、低ければ人間の応答を使用します。このモジュールはオンライン学習を通じて、エージェントが人間のフィードバックから学ぶことを可能にします。
Model-Agnostic Meta-Learning (MAML)
- Dai et al. (2020) は モデル無関係のメタ学習(MAML) を利用し、少数のサンプルでの適応性と信頼性の向上を目指しました。これにより、リアルなオンラインサービスタスクにおいても効果的にモデルが学習できるようになりました。
Minimalist Transfer Learning (MinTL)
- Lin et al. (2020) は Minimalist Transfer Learning (MinTL) を提案し、大規模な事前学習モデルを用いてタスク完了のためのドメイン転送を行います。この手法では、タスク間の転送を簡単に行い、効率的に異なるドメインに適応します。
Inconsistent Order Detection
- Wu et al. (2019) は 順序不整合検出モジュール を無監督で学習し、発話ペアが正しい順番かどうかを検出します。これにより、生成される応答の一貫性を保ち、より自然な対話を実現します。
Two-Teacher One-Student Framework
- He et al. (2020) は Two-Teacher One-Student トレーニングフレームワークを提案しました。最初の段階では2つの教師モデルを強化学習でトレーニングし、その後、生徒モデルが教師モデルの出力を模倣することで、専門知識を生徒モデルに移行します。
Constrained Decoding
- Balakrishnan et al. (2019) は 制約付きデコーディング手法 を導入し、生成される応答の意味的正確さを向上させました。この方法により、エンドツーエンドのシステムが生成する応答の品質が改善されます。
Memory Module for Knowledge Retrieval
- Chen et al. (2019) は 記憶モジュール を使用して知識事実や対話履歴を保持し、情報を正確に検索するために2つの長期記憶モジュールを利用しました。この手法では、より精密な情報取得が可能になります。
Graph-Based Reasoning
- Yang et al. (2020) は グラフ構造情報 を活用し、知識グラフと対話コンテキスト依存ツリーを利用してマルチホップ推論を行いました。このアーキテクチャにより、知識グラフのエンティティリンクを活用してタスク指向データセットにおける一貫した改善を達成しました。
技術動向
Pretrained Models for NLU
- 自然言語理解(NLU)タスクでは、ユーザーメッセージをあらかじめ定義されたセマンティックスロットの形式に変換します。最近では、大規模な事前学習済み言語モデルを微調整する方法が一般的です。これらのモデルは、タスク指向対話システムにおけるドメイン識別、意図検出、スロットタグ付けなどのサブタスクに応用され、少ない学習データでも効果的に動作します。
関連研究
- Wu and Xiong (2020) は、タスク指向対話システムにおけるドメイン識別、意図検出、スロットタグ付けの3つのサブタスクにおいて、BERTベースおよびGPTベースの事前学習済み言語モデルを比較し、どのモデルが最も効果的かを示す実証的な研究を行いました。この研究は、事前学習モデルの選択とその適用に関する洞察を提供しています。
TOD-BERT for Intent Detection (意図検出のためのTOD-BERT)
- Wu et al. (2020a) は、意図検出タスクにおいて強力なベースラインを上回る成果を示した TOD-BERT という事前学習モデルを提案しました。このモデルは、少ないデータでも効果的に学習できる「少数ショット学習(few-shot learning)」の能力を備えており、データ不足の問題を緩和するために使用されます。
Span-ConveRT for Slot Filling (スロット充填のためのSpan-ConveRT)
- Coope et al. (2020) は、スロット充填タスクに特化した事前学習モデル Span-ConveRT を提案しました。このモデルは、スロット充填タスクをターンベースのスパン抽出問題として捉え、少ないデータでの学習シナリオでも高いパフォーマンスを発揮することが示されています。
Domain Transfer for NLU
- 異なるドメイン間での知識の転送は、タスク指向対話システムにおける重要な課題です。複数のドメインに対応するためのモデルの適応や、異なるドメインのスロット間で共通のセマンティックな意味を活用する方法が研究されています。これにより、ドメイン間のモデルの汎用性やトレーニング効率を改善できます。
関連研究
RNN-LSTM for Multi Task Learning
- Hakkani-Tür et al. (2016) は、ドメイン分類、意図検出、スロット充填のマルチタスク学習のためのRNN-LSTMアーキテクチャを提案しました。このモデルでは、複数のドメインからの学習サンプルを1つのモデルに組み合わせ、各ドメインのデータが相互に強化される仕組みを作り出しました。
Multi-task Learning for Slot Alignment
- Bapna et al. (2017) は、スロット名エンコーディングとスロット記述エンコーディングを活用するマルチタスク学習フレームワークを提案しました。これにより、異なるドメイン間でスロット充填モデルを暗黙的に整合させることができ、ドメイン間でのスロット充填の精度を向上させました。
Slot Description for Multi-domain Slot-filling (マルチドメインスロット充填のためのスロット記述)
- Lee and Jha (2019) は、スロット記述を使用して異なるドメイン間で共通するセマンティックな概念を利用する手法を提案しました。この方法により、過去の研究で見られた最適でない概念整列や長時間の訓練時間の問題が解決されました。
Domain Transfer for DST
- 対話状態追跡(DST)におけるドメイン転送は特に難易度が高く、ドメイン間でスロット値やパラメータ数が異なるため、モデルが新しいドメインに適応することが困難です。過去の状態に基づいてドメイン間で状態を補完する技術や、アノテーションの少ないドメインでの学習を助ける方法が研究されています。
Tracking Efficiency for DST
- 対話状態追跡の効率化は、システムの反応時間を短縮するために重要です。無駄な計算を避け、スロットの状態を迅速に更新するために、スロット間の関係を計算して関連するスロットに集中する方法や、状態の予測を効率的に行う方法が探求されています。
Training Environment for PL
- ポリシー学習における環境構築は長年の課題です。ユーザーのフィードバックを報酬信号として取り込むためのシミュレーターを使用する方法が研究されており、エージェント同士が対話を行いながら学習するマルチエージェントのフレームワークが提案されています。
Response Consistency for NLG
- 応答の一貫性はNLG(自然言語生成)における重要な問題であり、単に学習データを増やすだけでは解決できません。ダイアログアクションの管理や、生成されたスロットとその値の整合性を保証するための補正メカニズムが導入され、反復的なチェックによって正確性を向上させる方法が研究されています。
後編へ続く...
内容が膨大になりすぎてしまっているので、後編(Open Domain編)を後日更新させていただこうと考えております。