こんにちは。
Neural Style Transfer(NST)を使って、自分で撮った写真を有名な絵画のようにアレンジしたり、好きな漫画やアニメの作画風にしてみたいと思ったことはありませんか?私はそのアイデアにとても興味を持ち、Neural Style Transferについてもっと詳しく知りたいと思い、論文を読みながら自分なりに整理しました。
この技術は、深層学習を活用して、画像のスタイルと内容を分離し、それぞれを自在に操作することができるというものです。例えば、写真をゴッホの「星月夜」のような絵画風に変えることができたり、アニメの特定のスタイルに変換することが可能です。この魔法のような技術がどのように実現されているのか、そしてその背後にあるアルゴリズムについて理解することで、さらに創造力が広がること間違いなしです!

ゴッホの「星月夜」、1889年。
今回のまとめ記事では、Neural Style Transferの基本原理から応用までを詳しく解説しています。具体的なアルゴリズムの仕組みや、実際に画像を生成するプロセス、さらには最適化手法についても触れています。これを読めば、あなたも自分の画像を驚くべきアート作品に変える第一歩を踏み出せるでしょう。
ぜひ、この記事を通じて、Neural Style Transferの魅力と可能性を感じ取っていただければと思います。それでは、どうぞお楽しみください!
論文
Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). A Neural Algorithm of Artistic Style. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
追記(2024/06/17):この記事を踏まえたプログラムの実装(InceptionV3)を後日公開いたしましたのでこちらもあわせてご覧ください。
1. 導入
- 【タスク】画像の意味的な内容(semantic content)を異なるスタイルで描画する
- 【用途】画像やビジュアルコンテンツの生成、編集、デザイン、高品質な画像生成技術の研究への寄与等…
- 【課題】従来のアプローチ(non-parametricな手法)では、画像の意味的内容(semantic content)とスタイルを明確に分離することが困難でした。具体的には、画像の意味的な情報を明示的に表現することができる画像表現が不足していたため、コンテンツ(内容)とスタイルを別々に操作することができなかったのです。
-
補足
-
Semantic Content(意味的内容):
- 画像の中に存在する物体やシーンの基本的な構造や形状、つまり「何が写っているのか」という情報。
- 例として、写真に写っている人物の輪郭や建物の形などがこれに該当します。
-
Styles(スタイル):
- 画像の視覚的な特性や質感、つまり「どのように見えるか」という情報。
- 例として、ゴッホの絵画のような筆遣い、印象派の色彩の使い方などがこれに該当します。
論文には以下のような記述もありました。
自然画像において、一般的に内容とスタイルを分離することは依然として非常に困難な問題です。しかし、最近の深層畳み込みニューラルネットワーク(Deep Convolutional Neural Networks, CNN)の進展により、自然画像から高レベルの意味情報を抽出する強力なコンピュータビジョンシステムが生まれました【18】。十分なラベル付きデータで特定のタスク(例:物体認識)に対して訓練されたCNNは、データセットを超えて一般化できる高レベルの画像内容を抽出することが示されています【6】。さらに、この汎用的な特徴表現は、テクスチャ認識【5】や芸術的スタイル分類【15】など、他の視覚情報処理タスクにも適用可能です【19, 4, 2, 9, 23】。
-
Semantic Content(意味的内容):
-
2. 技術的背景
2.1 基本原理
NSTの基本的な原理は、畳み込みニューラルネットワーク(Convolutional Neural Networks, CNN)を用いて、画像の意味的内容とスタイルを分離し、それらを再結合することにあります。CNNは、画像の高レベルな特徴を捉えるために最適化されており、これにより画像の内容とスタイルを独立して操作することが可能となります(意味的な画像コンテンツと提示されるスタイルのバリエーションを独立してモデル化する画像表現を見つけたいというモチベーション)。
2.2. コンテンツ表現とスタイル表現
-
コンテンツ表現(Content Representation):
- 画像の中の物体やシーンの基本的な構造や形状を捉えるものです。
- CNNの高レイヤーのフィルタ応答を用いて、高レベルな意味的情報を抽出します。
- 例えば、VGGネットワークのような深層CNNを用いることで、画像の詳細なピクセル情報を保持しつつ、物体の形状や位置などの意味的な内容を抽出します。
-
スタイル表現(Style Representation):
- 画像の見た目や質感を捉えるものです。
- CNNの複数のレイヤーにわたるフィルタ応答の相関(Gram行列)を用いて、テクスチャ情報を抽出します。
- これにより、画像全体の色彩や筆遣いなどのスタイル情報を捉えることができます。
3. 代表的な手法とモデル
※詳細は原論文をご参照ください。
Gatysらのアプローチは、CNNアーキテクチャであるVGGネットワーク(16層の畳み込み層と5層のプーリング層から構成されており、画像の高レベルな特徴を抽出するために最適化)を使用して、コンテンツとスタイルの両方の特徴を抽出し、これらを用いて画像を生成する手法です。以下に、その主要な手順を示します。
-
コンテンツ画像とスタイル画像の特徴抽出:
- コンテンツ画像: CNNの高レイヤー(例えば、conv4_2)のフィルタ応答を用いて、画像の意味的内容を抽出します。
- スタイル画像: CNNの複数レイヤー(例えば、conv1_1, conv2_1, conv3_1, conv4_1, conv5_1)のフィルタ応答の相関(Gram行列)を用いて、画像のスタイル情報を抽出します。
-
損失関数の定義:
- コンテンツ損失: 生成画像とコンテンツ画像の特徴マップ間の平方誤差を用いて定義されます。これは、生成画像がコンテンツ画像の意味的内容を保持するようにするためのものです。
- スタイル損失: 生成画像とスタイル画像のGram行列間の平方誤差を用いて定義されます。これは、生成画像がスタイル画像の視覚的な特徴(色彩、質感など)を持つようにするためのものです。
-
最適化:
- コンテンツ損失とスタイル損失の加重和を最小化するように、生成画像を最適化します。
- 具体的には、L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno)アルゴリズムを使用して、損失関数を最小化するための最適化を行います。
4. 技術的詳細
※詳細は原論文をご参照ください
Neural Style Transfer(NST)の技術的詳細について、Gatysらのアプローチを基に、各要素を詳細に説明します。
4.1 畳み込みニューラルネットワーク(CNN)のアーキテクチャ
Gatysらの研究では、VGGネットワーク(特にVGG-19)が使用されています。VGGネットワークは、画像分類タスクのために設計された深層ニューラルネットワークであり、以下のような特徴があります:
- 構造: 16層の畳み込み層(convolutional layers)と5層のプーリング層(pooling layers)から構成され、全体で19層あります。
- フィルタサイズ: 全ての畳み込み層は3x3のフィルタを使用しており、これは細かい画像特徴を捉えるのに適しています。
- プーリング: 畳み込み層の後に続くプーリング層は、2x2のマックスプーリング(max pooling)を使用し、画像の解像度を下げつつ重要な特徴を保持します。(average poolingより僅かに魅力的な結果が得られたそうです。)
このネットワークは、物体認識タスクにおいて高い性能を発揮し、そのフィルタ応答は高レベルな画像特徴を効果的に捉えることができます。
4.2 コンテンツ表現とスタイル表現の抽出
NSTでは、CNNの異なるレイヤーからコンテンツとスタイルの特徴を抽出します。以下に、その具体的な方法を説明します。
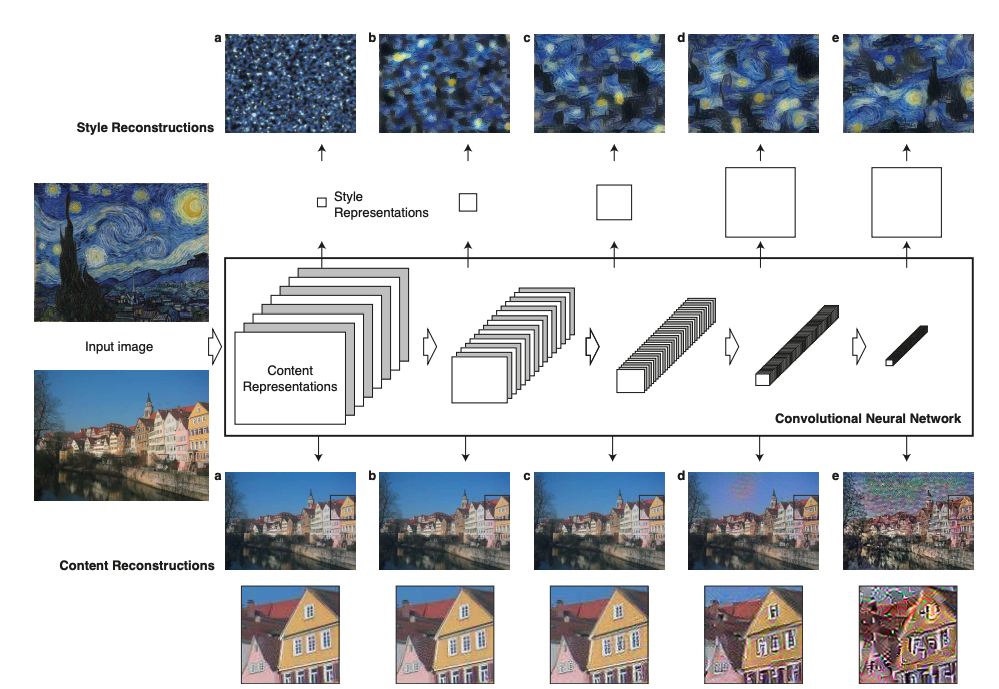
Figure 1. Image representations in a Convolutional Neural Network (CNN).
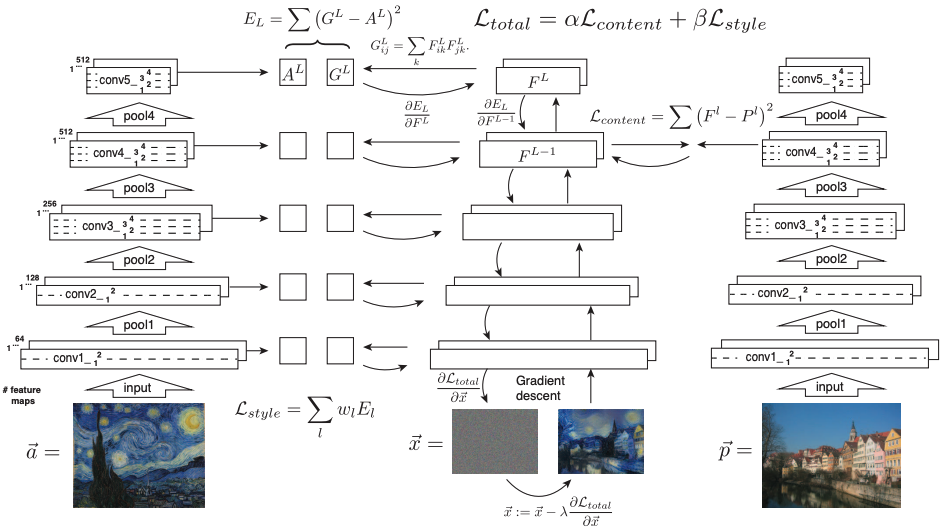
Figure 2. Style transfer algorithm.
4.2.1. コンテンツ表現の抽出
-
方法:
- 画像をCNNに入力し、各レイヤーでのフィルタ応答を取得します。
- 高レイヤーのフィルタ応答は、画像の大まかな形状や構造を保持しながら、詳細なピクセル情報を捨象します。ネットワークの高次層の特徴応答をコンテンツ表現と呼びます。
- これにより、画像の意味的な内容を効果的に捉えることができます。
- ネットワーク(の深いレイヤーのフィルタ応答)によって生成されたコンテンツの特徴と元のコンテンツから得た特徴を最小化するようにネットワークを最適化するように学習を行います。
詳細
- 与えられた入力画像 $\vec{x}$は、畳み込みニューラルネットワークの各層でその画像に対するフィルタ応答によってエンコードされます。
- $N_l$ 個の異なるフィルタを持つ層は、それぞれのサイズが $M_l$ ($F_W×F_H$)である $N_l$ 個の特徴マップを持ちます。したがって、層 $l$の応答は行列 $F^l \in \mathbb{R}^{N_l \times M_l}$に格納できます。ここで $F^l_{ij}$は、層 $l$ における $i$ 番目のフィルタが位置 $j$ で活性化した値です。
- ネットワークの異なる層にエンコードされた画像情報を視覚化するために、ホワイトノイズ画像(=画像生成や画像処理の初期状態としてよく使用されるランダムなピクセル値を持つ画像)に対して勾配降下を行い、元の画像の特徴応答に一致する別の画像を見つけることができます(図中の「content reconstruction」)【24】。ここで、$\vec{p}$ と $\vec{x}$を元の画像と生成された画像とし、$P^l$ と $F^l$ をそれぞれ層 $l$ における特徴表現とします。次に、2つの特徴表現間の二乗誤差損失を以下のように定義します。
L_{\text{content}}(\vec{p}, \vec{x}, l) = \frac{1}{2} \sum_{i,j} \left( F^l_{ij} - P^l_{ij} \right)^2
この損失の層 $l$ における活性化に対する導関数は以下のようになります。
\frac{\partial L_{\text{content}}}{\partial F^l_{ij}} =
\begin{cases}
F^l_{ij} - P^l_{ij} & \text{if } F^l_{ij} > 0 \\
0 & \text{if } F^l_{ij} < 0
\end{cases}
この導関数を用いて、標準的な誤差逆伝播法によって画像 $\vec{x}$ に対する勾配を計算できます(図2、右)。したがって、初期のランダムな画像 $\vec{x}$を変更し、元の画像 $\vec{p}$ と同じ層のニューラルネットワークにおける応答を生成するまで調整することができます。
4.2.2. スタイル表現の抽出
- 目的: 画像の視覚的特徴(visual style)を捉える。
-
方法:
- 各レイヤーでのフィルタ応答を取得し、それらの相関を計算してGram行列を作成します。
- 具体的には、あるレイヤーのフィルタ応答をベクトルとして扱い、それらの内積を計算することでGram行列を構成され、画像のテクスチャ情報を捉えます。
- 複数のレイヤーの情報を組み合わせることで、画像の多様な視覚的特徴を包括的に捉えることができます。
詳細
- 入力画像のスタイルを表現するために、テクスチャ情報を捉えるために設計された特徴空間を使用します(任意の層のフィルタ応答を利用できる)。 - この空間は、異なるフィルタ応答間の相関から成り、特徴マップの空間的範囲にわたって期待値(特徴マップのすべてのピクセル値の平均)が取られます。これらの特徴相関はGram行列 $G^l \in \mathbb{R}^{N_l \times N_l}$ によって与えられ、$G^l_{ij}$ は層 $l$ におけるベクトル化された特徴マップ $i$ と $j$ の内積です(kはピクセル):G^l_{ij} = \sum_k F^l_{ik} F^l_{jk}
- 複数の層の特徴相関を含めることで、入力画像のテクスチャ情報を捉えながらもグローバルな配置を捉えない、静的でマルチスケールな表現を得ることができます。
- 再度、ネットワークの異なる層に構築されたこれらのスタイル特徴空間によって捉えられた情報を視覚化するために、特定の入力画像のスタイル表現に一致する画像を構築します(図1、style reconstruction)。これは、ホワイトノイズ画像からの勾配降下を使用して、元の画像のGram行列のエントリと生成される画像のGram行列のエントリ間の平均二乗距離を最小化することで行われます。
- 元の画像 $\vec{a}$と生成された画像 $\vec{x}$ とし、それぞれの層 $l$ におけるスタイル表現を $A^l$ と $G^l$とします。層 $l$の総損失への寄与は次のようになります:
E^l = \frac{1}{4N_l^2 M_l^2} \sum_{i,j} \left( G^l_{ij} - A^l_{ij} \right)^2
そして、総スタイル損失は以下のようになります:
L_{\text{style}}(\vec{a}, \vec{x}) = \sum_{l=0}^{L} w_l E^l
ここで、$w_l$は各層の総損失への寄与の重み付け係数です(結果における具体的な値については以下を参照)。層 $l$ における活性化に関する $E^l$の導関数は解析的に計算できます:
\frac{\partial E^l}{\partial F^l_{ij}} =
\begin{cases}
\frac{1}{N_l^2 M_l^2} \left( (F^l)^T G^l - A^l \right){ji} & \text{if } F^l{ij} > 0 \\
0 & \text{if } F^l_{ij} < 0
\end{cases}
$E^l$のピクセル値 $\vec{x}$に関する勾配は、標準的な誤差逆伝播法を使用して容易に計算できます(図2、左)。
-
補足
異なるフィルタ応答間の相関
畳み込みニューラルネットワーク(CNN)の各層には、多数のフィルタ(カーネル)が存在し、これらは入力画像に対して異なる特徴を抽出します。各フィルタは、画像の特定のパターン(エッジ、テクスチャなど)に対して応答します。
- フィルタ応答: 各フィルタが画像をスキャンして得られる出力(特徴マップ)です。
- フィルタ応答間の相関: 異なるフィルタの応答がどの程度関連しているかを示します。例えば、あるフィルタがエッジを検出し、別のフィルタがそのエッジに沿ったテクスチャを検出する場合、これらのフィルタ応答には相関があります。
例えば、CNNのある層で2つのフィルタ(フィルタAとフィルタB)があるとします。それぞれのフィルタが入力画像に適用されると、対応する特徴マップが生成されます。
-
フィルタAの特徴マップを $\mathbf{F}^A$、フィルタBの特徴マップを $\mathbf{F}^B$とします。
-
これらの特徴マップは、それぞれ高さ $H$と幅 $W$ を持ち、各ピクセルの値はフィルタ応答を示します。
-
フィルタAとフィルタBの応答の相関を計算するために、各特徴マップのベクトル化(1次元配列に変換)を行います。次に、これらのベクトルの内積を計算します。
G_{AB} = \sum_{k} F^A_k \cdot F^B_kここで、$F^A_k$ と $F^B_k$は、それぞれのフィルタの特徴マップの $k$ 番目のピクセル値を示します。
特徴マップの空間的範囲にわたる期待値
特徴マップは、フィルタが入力画像に適用された結果得られるマップです。これらは通常、入力画像の特定の局所領域を表現しています。特徴マップの空間的範囲にわたる期待値とは、特徴マップ全体のピクセル値を平均化することで、そのフィルタの全体的な応答を評価することを意味します。
- 特徴マップ: フィルタが画像に適用されて得られる2次元のマップ。
- 空間的範囲: 特徴マップの高さと幅の全領域。各ピクセルが画像の異なる部分を表しています。
- 期待値: 特徴マップのすべてのピクセル値の平均。これにより、フィルタの全体的な応答を定量化できます。
特徴マップの空間的範囲にわたる期待値を計算するために、特徴マップ全体のピクセル値を平均化します。これにより、そのフィルタの全体的な応答が得られます。
例えば、フィルタAの特徴マップ $\mathbf{F}^A$の期待値は次のように計算されます。
$$
\text{mean}(\mathbf{F}^A) = \frac{1}{HW} \sum_{i=1}^{H} \sum_{j=1}^{W} F^A_{ij}
$$ここで、$F^A_{ij}$は特徴マップの位置 ((i, j)) におけるピクセル値です。
4.2.3. 最適化
以上を踏まえて、下記のように最適化を行います。
-
損失関数の定義:
-
総損失関数 $L_{\text{total}}$は、コンテンツ損失 $L_{\text{content}}$ とスタイル損失 $L_{\text{style}}$の加重和として定義されます。
L_{\text{total}}(\vec{p}, \vec{a}, \vec{x}) = \alpha L_{\text{content}}(\vec{p}, \vec{x}) + \beta L_{\text{style}}(\vec{a}, \vec{x})それぞれの損失に対する重み係数 $\alpha$と $\beta$ を調整することで、コンテンツとスタイルのバランスを取ります。
-
-
最適化手法:
- ピクセル値に関する損失関数の勾配を用いて、数値最適化を行います。ここでは、L-BFGSアルゴリズムを使用して画像を合成します。(L-BFGSは、より一般的なBFGSアルゴリズムの一種であり、二次計画問題を効率的に解くために使用されます。BFGSアルゴリズムは、準ニュートン法の一種であり、ヘッセ行列(2次導関数の行列)を明示的に計算せずに最適化を行います。L-BFGSは、特にヘッセ行列の逆行列を保存するために必要なメモリを削減するために設計されています。)
-
画像サイズの調整:
- スタイル画像とコンテンツ画像の特徴表現を比較するために、常にスタイル画像をコンテンツ画像と同じサイズにリサイズします。
-
正則化の有無:
- 他の研究と異なり、本研究では画像の事前情報を使用して合成結果を正則化しません。ただし、ネットワークの低層から得られるテクスチャ特徴が、事前情報として機能することもあります。
まとめ
Neural Style Transfer(NST)の技術は、私たちの画像編集や創作の可能性を大きく広げてくれます。自分で撮った写真を有名な絵画風にアレンジしたり、好きなアニメのスタイルに変換することで、新しい表現の幅を体験することができます。この魔法のような技術の背後には、深層学習や最適化アルゴリズムの複雑なメカニズムが隠されています。
今回、Neural Style Transferの論文を通じて、コンテンツとスタイルの分離、そしてそれらを再構成するプロセスについて理解を深めることができました。これにより、私たちが日常的に目にする画像がどのようにして生成されるのか、その背景にある技術の一端に触れることができました。
この記事を通じて、Neural Style Transferの魅力や可能性を少しでも感じていただけたなら幸いです。ぜひ、皆さんもこの技術を活用して、自分だけのユニークな画像を創り出してみてください。新たな発見や創造の喜びが、きっとあなたを待っています。
ご覧いただき、ありがとうございました。