初めに
初めまして Hayaa6211 です.僕は普段たくさん音楽を聴いていてお勧めしたい曲だったりその日何を聴いていたかまとめたいと思っていました.
なので今回は毎日、その日聞いていた音楽を自動でツイートするコードを書きました.
注意点として、[プログラミング初心者]です.この作品が初めて自力で作ったものとなるので一般的に見たら汚いと思われるコードが多数あるかと思います.そこはわが子の成長を見守るかのように大目に見てください(よかったアドバイスお願いします.)
また、この記事では僕と同じくらいのスキルを持った人を対象として書いているのでかなり初歩のことにも足を突っ込んでいます.しかし構文の節女などは書かないので各自で調べてみてください.
さらにこのコードはiPhoneユーザであり、Apple Musicを使っている人限定となってしまっています.ご了承ください.
pipでtweepyとunicodedataをインストールしてきましょう
全体像
- その日聞いた音楽の情報を取り出す.(ぼくがApple Musicを使っているのでそれの情報)
- その情報からツイート文を作成する.
- ツイートする
大まかに動作を書くとこんな感じです.
音楽の情報を取り出そう.
まず僕はここで長期間つまずきました.Apple MusicのAPIがまずDevelopper限定であることから一般的には利用できない上に大学生には痛すぎる出費です.
ここでiPhone純正で備わっている機能.「ショートカット」に目を付けました.これはiPhoneでできることを自動化してくれる感じのアプリです.Apple Musicにももちろん対応していて楽曲の検索やプレイリストの作成などができます.(詳しくは調べてみてね)
ではここから実際に作ったショートカットの画面を見つつ解説していきます.
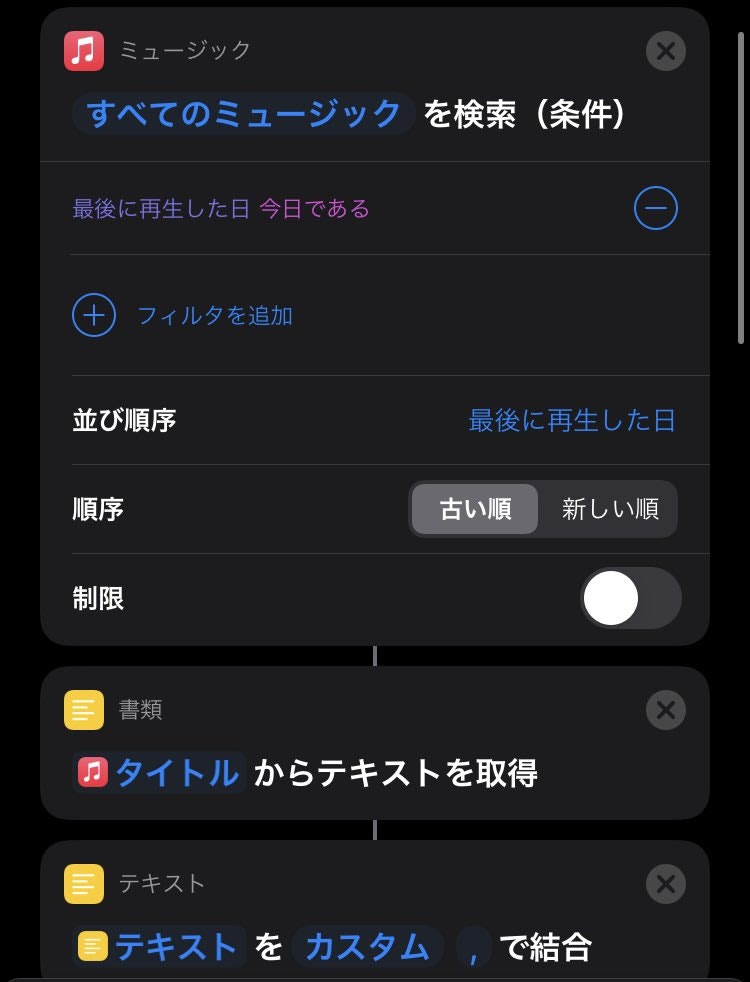
詳しい使い方は実際に遊ぶのが一番なのでここでは軽く動作を説明します.
ミュージックから検索をするのですがフィルターに「最後に再生した日 今日である」とすることで今日流した曲を検索できます.これはlistみたいな感じで渡されます.(ブロック一個一個が関数?)
そのlistをテキストで受取、再度","で区切ります.
するとそのテキストは
"Aritist1,Aritist2,Artist3"
といった感じでStr形式になります.そしたら作ったテキストを.txtとしてiCloud Driveに保存します.
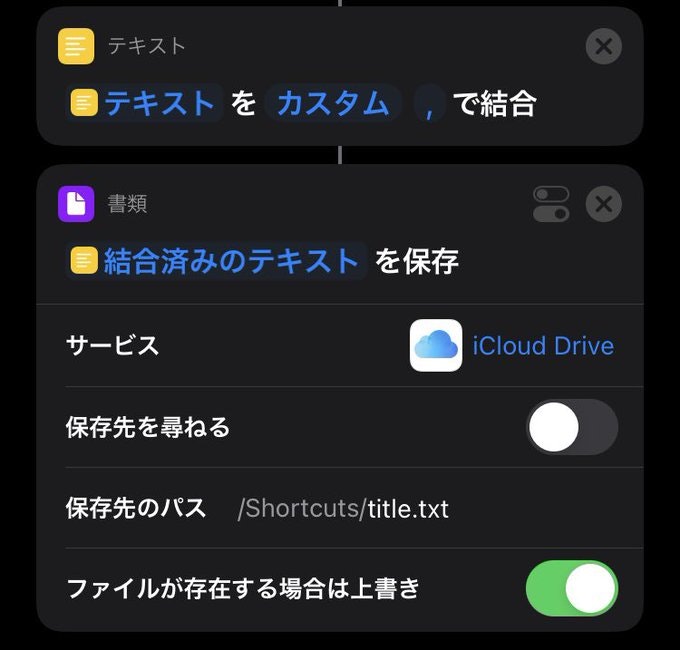
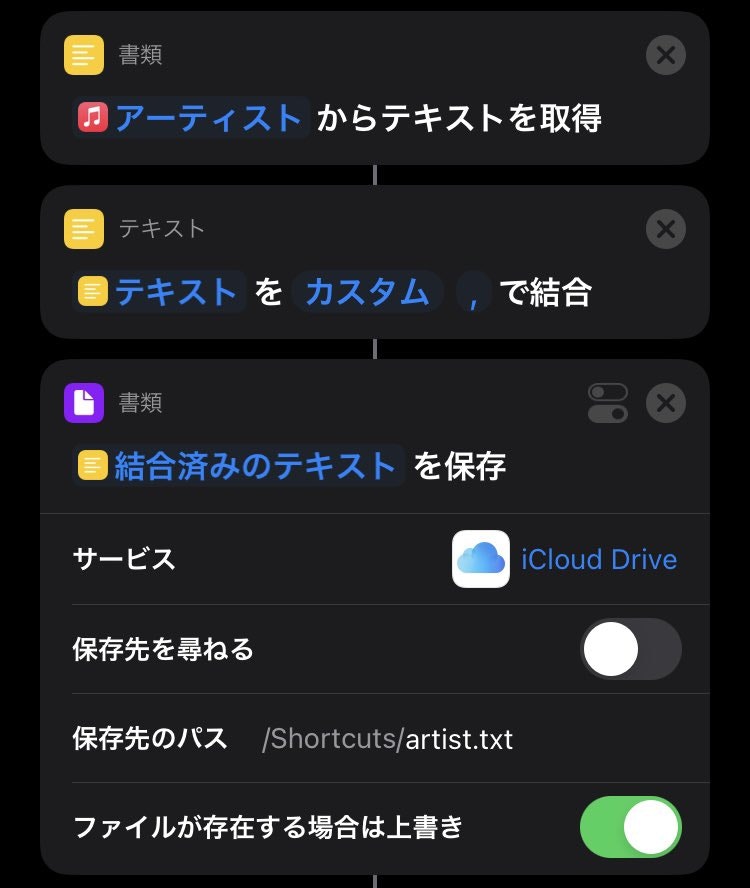
これをタイトルとアーティスト両方で作ります.
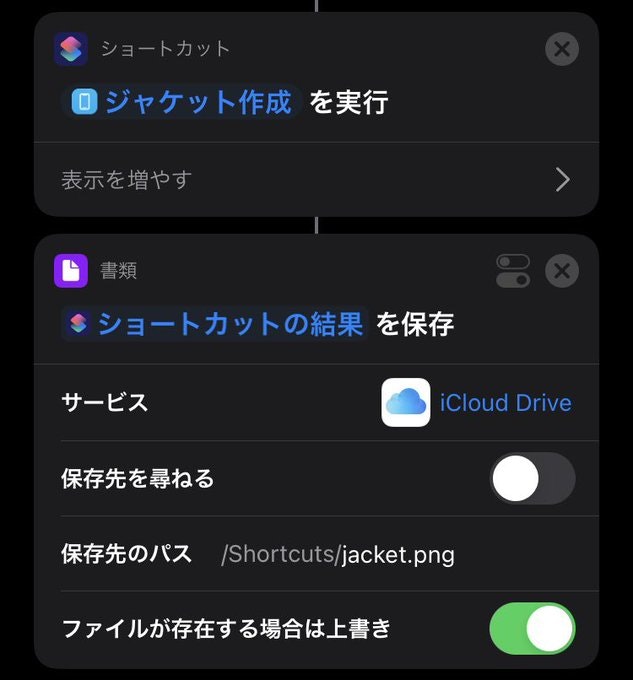
そしたらこの調子でジャケットも保存しましょう.
このジャケット作成はこんな感じです.聞いたジャケットをまとめてくれてますたくさん聞いた日は圧巻
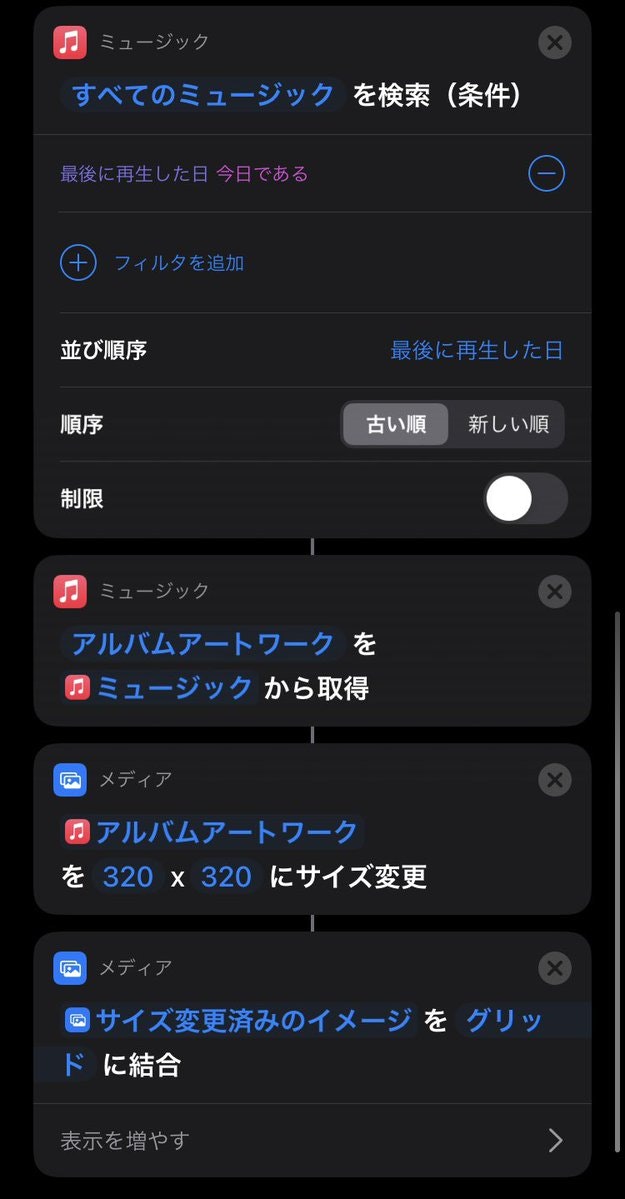
ショートカットの作業はこれで終わりです.ちゃんとファイルがあるか確認してみましょう.
title.txt,aritist.txt,jacket.pngの三種類があれば大丈夫です.
いざPythonでのコーディングへ
ここまで来たら慣れないアプリでの作業も終わりです.
ファイルを取り出して好きなように編集しましょう.
import tweepy,datetime,unicodedata
from PIL import Image
consumer_key = ""
consumer_secret = ""
access_token = ""
access_token_secret = "" #TwitterのAPI情報を入れてね
dt = datetime.datetime.now() #今の時間の情報をインスタンス生成
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth) #ここはまんまコピーでおけ
tweet = f"#僕の聴いてる音楽\n\n{dt.month}/{dt.day}\n" #実際のツイート文.
ここは最初の定義の部分です.おわり
ジャケットを取り出そう
先ほどiCloudに置いたジャケットを取り出します.
の前に、パスを指定しなきゃいけないので icloud for Windowsを入れて設定してください.
エクスプローラーにiCloudがあればオッケーです
def make_image(pic_file):
img = Image.open(pic_file)
img_resize_lanczos = img.resize((img.width//2, img.height//2), Image.LANCZOS)
img_resize_lanczos.save('C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/jacket_resize.png')
pic_file_resize = 'C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/jacket_resize.png'
return pic_file_resize
これでジャケットが取り出せました.ちなみに画像サイズを変更している理由はサイズが大きすぎると投稿できないことがあるみたいだからです.ここはお好みで設定してみてください.
テキストを読み込もう
次はアーティストとタイトルを取り出します.
txtなので with open()で大丈夫ですね
def Artist_read(Artist_file):
with open(Artist_file,"r",encoding="utf-8") as f:
Artist_list = f.read()
Artist_list = Artist_list.split(",")
return Artist_list
def title_read(title_file):
with open(title_file,"r",encoding="utf-8") as f:
title_list = f.read()
title_list = title_list.split(",")
return title_list
文字数の制限の壁
さあここまででiPhoneで作ったテキストなどを取り出すことはできました.しかしここでTwitterの使用の壁が現れました.文字数ですね.半角で280文字、全角で140文字までと決まっています.
そこで文字数を数えるためにunicodedataライブラリを利用します.半角か全角か絵文字かなどを分類してくれるやべーやつ
def counter(tweet):
tweet_list = list(tweet)
text_counter = 0
for n in tweet_list:
j = unicodedata.east_asian_width(n)
if 'F' == j:
text_counter = text_counter + 2
elif 'H' == j:
text_counter = text_counter + 1
elif 'W' == j:
text_counter = text_counter + 2
elif 'Na' == j:
text_counter = text_counter + 1
elif 'A' == j:
text_counter = text_counter + 2
else:
text_counter = text_counter + 1
return text_counter
長い、、、もっと簡単にできないかな
ツイート文を作ろう
ここまで来たらあとはツイートするだけ!!!
def make_tweet(Artist_list,title_list):
global tweet
for Artist,title in zip(Artist_list,title_list):
text_counter = counter(tweet)
if text_counter < 240:
tweet += f"{title}/{Artist}\n"
else:
break
二つのリストをzipでまとめてます.
main関数です
さあコーディングはあとちょっとです!!!main関数を書きます
def main():
global tweet
pic_file_resize = make_image(pic_file)
Artist_list = Artist_read(Artist_file)
title_list = title_read(title_file)
counter(tweet)
make_tweet(Artist_list,title_list)
api.update_with_media(filename = pic_file_resize, status = tweet)
print("Done!")
return使いすぎてちょっと見づらくなってしまった.最後の`print("Done!")はいらないっちゃいらない.if文使ってるわけでもないし
最後
はい最後です.いつものあれを呼びます.
if __name__ == "__main__":
main()
実際の動作画面
ではここまで書いたら実際にデバッグします.
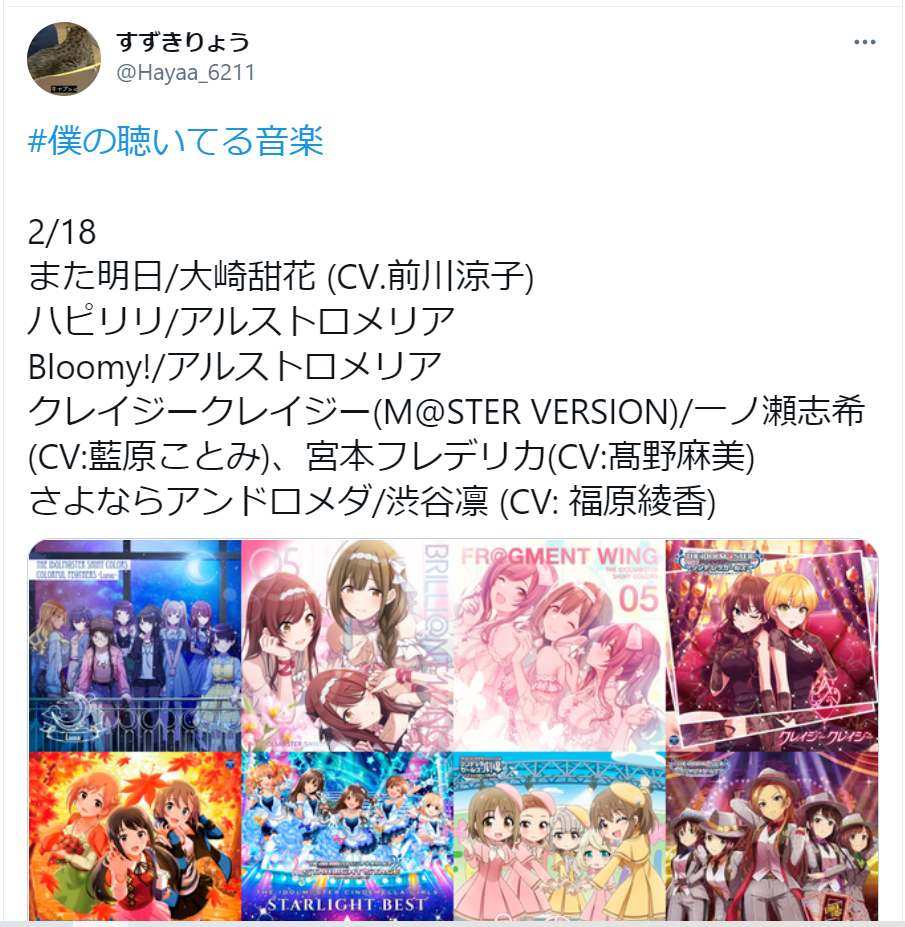
こんな感じでツイートされてるはずです.文字数数えても130くらいなのでちゃんとcounter()も働いてくれてますね
アイマスはいいぞ
これじゃあ手動じゃない?
はい.その通りですよ.pyの起動が必要ですね
ではここで自動化をしましょう..batでwindows君に「このファイルを実行してね」って教えてあげます.まあ「.py 定期実行」とかで調べるとたくさん出てくるのでどうぞ(他力本願寺住職)
コード
最後にコード全体乗せときますね(いらない)
import tweepy,datetime,unicodedata
from PIL import Image
consumer_key=''
consumer_secret=''
access_token=''
access_token_secret=''
dt = datetime.datetime.now()
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
Artist_file = "C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/artist.txt"
title_file = "C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/title.txt"
pic_file = "C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/jacket.png"
tweet = f"#僕の聴いてる音楽\n\n{dt.month}/{dt.day}\n"
def make_image(pic_file):
img = Image.open(pic_file)
img_resize_lanczos = img.resize((img.width//2, img.height//2), Image.LANCZOS)
img_resize_lanczos.save('C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/jacket_resize.png')
pic_file_resize = 'C:/Users/iCloudDrive/iCloud~is~workflow~my~workflows/jacket_resize.png'
return pic_file_resize
def Artist_read(Artist_file):
with open(Artist_file,"r",encoding="utf-8") as f:
Artist_list = f.read()
Artist_list = Artist_list.split(",")
return Artist_list
def title_read(title_file):
with open(title_file,"r",encoding="utf-8") as f:
title_list = f.read()
title_list = title_list.split(",")
return title_list
def counter(tweet):
tweet_list = list(tweet)
text_counter = 0
for n in tweet_list:
j = unicodedata.east_asian_width(n)
if 'F' == j:
text_counter = text_counter + 2
elif 'H' == j:
text_counter = text_counter + 1
elif 'W' == j:
text_counter = text_counter + 2
elif 'Na' == j:
text_counter = text_counter + 1
elif 'A' == j:
text_counter = text_counter + 2
else:
text_counter = text_counter + 1
return text_counter
def make_tweet(Artist_list,title_list):
global tweet
for Artist,title in zip(Artist_list,title_list):
text_counter = counter(tweet)
if text_counter < 240:
tweet += f"{title}/{Artist}\n"
else:
break
def main():
global tweet
pic_file_resize = make_image(pic_file)
Artist_list = Artist_read(Artist_file)
title_list = title_read(title_file)
counter(tweet)
make_tweet(Artist_list,title_list)
api.update_with_media(filename = pic_file_resize, status = tweet)
print("Done!")
if __name__ == "__main__":
main()
最後に
ここまで読んでいただきありがとうございました!!初めて自作した作品ということでかなり見づらくなってしまっているかもしれませんが頑張りました!!!
これからは読みやすくより軽量を意識してコーディングしていきたいと思います(誰かアイデアください)
ではまた次の記事で!!!