1.目的
プログラミングの学習を始めたのが2019年1月で、オンラインのプログラミングスクールに通って本格的に学習を始めたのが2019年7月でした。
練習としてkaggleに取り組んでいましたが、機械学習のモデルを構築するなんてもっと前の、データ可視化の部分で躓くことが多すぎて、何回も心が折れました。
でも実は悩んでいるのは自分だけじゃなくて、意外に躓いたりする部分が皆一緒なんじゃないかと思い、今苦しんでいる超初心者の方に少しでも役立つ記事を投稿すること/が目的です。
また、結論だけでなく、自分が考えたことも一緒に書くようにしています。こんな私でも、まだまだ初心者のレベルですが、次の4月からAI専門の企業で働けることになったので、そういう意味で初学者の方のモチベーションアップにも貢献できますと幸いです。
※注意※
この記事は、「こうしたら解決できるようになりますよ」という、知識を教える記事ではありません。あくまで今の超初心者の自分の知識を元に、こうしたらなんとかなりそう・・という奮闘の記録を綴ったものです。
もっとこうしたらうまくいきますよ、ということがありましたら、大変お手数ですがご教示いただけますと幸いです。
2.今回取り上げるkaggle紹介
Kickstarter Projects
おそらくですが、タイタニックとかより前の、超入門用という感じでしょうか。
クラウドファンディングの成否を分類するものです。
https://www.kaggle.com/kemical/kickstarter-projects
3.今回取り上げる、EDA奮闘記紹介
【1】データ可視化をした際に外れ値があった
データの可視化はまずはやるべき一歩目だと思うのですが、実は外れ値があってうまく可視化できていない、という事実それ自体に気が付くのにだいぶ時間がかかった記録です。
【2】図示で特徴量が多すぎて文字が読めない
まずは可視化だよね!と意気込み、とりあえず本やネットで調べた棒グラフを作ってみましたが、変数が多すぎて可視化した文字が全く読めず、上位の項目だけ可視化したい・・というやり方を調べるのにめちゃくちゃ時間がかかった記録です。
4.奮闘記【1】データ可視化をした際に外れ値があった
(1)本題に入る前に
必要なもののインポート、データの読み込みをしておきます。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import math
import pandas as pd
import seaborn as sns
df = pd.read_csv(r"C:~~\ks-projects-201801.csv")
(2)可視化を色々してみる
よし、兎にも角にもまずはデータをしっかり調べて、外観を見ることが大切なんだよね!と思い、このkaggle自体は特徴量が多くないので1つずつ見ていくことにしました。
◆state(成功か失敗かの結果の分類)
このコードを書いて、可視化すると次のようになります。
df["state"].value_counts().plot(kind = "bar")
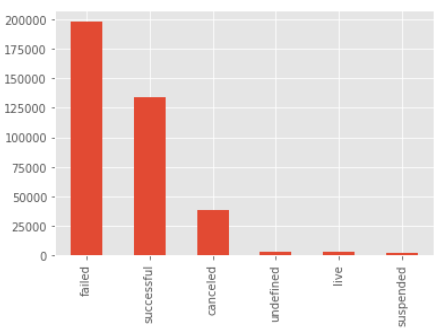
ほうほう・・そこそこ失敗してるんだな・・・。ただ、失敗と成功以外にも途中で終わってしまったものとか、色々ありそう・・でも、ほとんどが失敗と成功だから、この2つ以外は最初はデータから切ってみるか!
なるほど、こういうことを考えるためにデータの可視化や考察って大切なんだなあ・・と思っていました。
他の特徴量も様々可視化をして、ついに、問題の特徴量にたどり着いたのです。
◆goal(目標金額)
クラウドファンディングの目標額によっても成否って結構わかれそう!と思い、一般的なヒストグラムで可視化してみました。
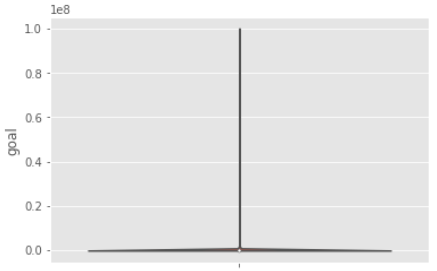
plt.hist(df["goal"])
すると・・・こんなヒストグラムができあがりました。

今考えたらこれって外れ値があるからなんですが、この時の私はそんなこと全く気が付かず(外れ値自体は知っていましたが、結び付かなかった)、「なにこれ・・?みんな一緒なんだけど・・・でいうかx軸の右にある1e8って何?10の何乗みたいなやつだっけ」状態でした。
特徴量のgoalの中の数値を見れば気づくはずなのですが全く気が付かず、でした。
おそらく、「可視化すること」自体が目的になってしまっていて、本来的なデータ分析になっていなかったのだと、今考察すると感じます。
これ、実は1~2日空き時間に調べても全くわからず、途方に暮れていました。というより、そもそも何て調べたらいいのか全然検討がつかなかったのです。
(3)奥の手・・先生に聞く
これはまずい、多分超初歩的なんだろうけど全然わからない・・となり、あまり汎用的な解決策ではなく申し訳ないのですが、その時とある企業の機械学習講座を取っていたのでその先生に質問しました。
その先生に私のコードと可視化したヒストグラムを見せると、一瞬で「外れ値があるからじゃない?」と返ってきました。
外れ値・・・・ええ・・・まじか・・・くらいしか感想は浮かんでこなかったですが、先生もそれ以上は私の勉強のために教えてはくださらなかったので、家に帰る道中、外れ値ってことは、箱ひげ図で見てみればいいんじゃないかなとぼんやり考え、家で続きを行いました。
(4)すぐには解決しない・・
箱ひげ図自体は統計検定3級を受験した際に勉強していたので、予備知識はありました。
先生からの外れ値の助言から、とりあえず箱ひげ図作ってみるか、と作ってみたのがこれです。
sns.boxplot(y = "goal",data=df)

なんか・・思ってたのと違う・・・。
箱ひげ図って、こんな変なやつじゃないよね・・?
今考えればそもそも0.0付近にデータが多すぎて箱が潰れてしまっていて、外れ値自体が点で描写されているのですが、0.0付近の太線なんて気づきもせず、意味わからない、と思っていました。
そこで、「そうだ、ヴァイオリンプロットを使えばどのあたりにどれくらいデータが集まっているかもわかるんだった。ちょっとやってみよう」と思い、下記を実行しました。
sns.violinplot(y = "goal",data=df)
箱ひげ図と変わり映えのしないこのヴァイオリンプロットを見てようやく、0.0付近にめちゃくちゃデータが多すぎて変な図になっているのだと気づいたのです。
たぶんデータのほとんどは0.0付近のはずだから、とりあえず大きめのデータを取ってみよう!と考えました。
とりあえず100万以上はデータから切るべく、下記を実行しました。
df_goal_train = df[(df["goal"]<1000000)]
sns.boxplot(y = "goal",data=df_goal_train)

まだ駄目だな・・と思い、次は10万以下にしてみます。
df_goal_train = df[(df["goal"]<100000)]
sns.boxplot(y = "goal",data=df_goal_train)

だいぶ、自分が思っていた箱ひげ図に近づきました!!
この状態でヴァイオリンプロットを試してみます。
sns.violinplot(y = "goal",data=df_goal_train)
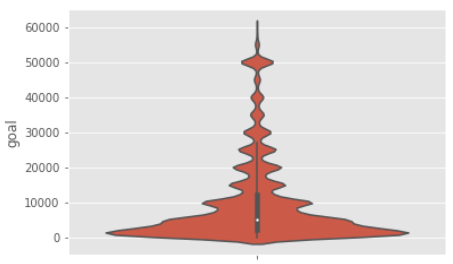
良い感じです!!
ここまで来てようやく、削ったデータもありますが、目標金額の中央値はおおよそ10,000以下で、ボリュームゾーンもヴァイオリンプロットを見ると5,000以下であることが分かります。つまり、比較的少額なクラウドファンディングが多いのだということがデータの分析からわかったと思います。
但し、今回一旦図示のために外した超高額のクラウドファンディングをデータから消したらいいわけではなく、今後も超高額のクラウドファンディングがあった際にそのデータはうまく予測できないことになってしまうので、データの扱い自体は慎重に見極める必要がありそう、ということが今回の可視化からわかると思います。
これで、goalの可視化の章は終了です。
※このKickstarter Projectsは精度を上げたり各モデルの精度比較を今でも行っているので、別途このコンペを終えるための記事を投稿したいと考えています。
5.奮闘記【2】図示で特徴量が多すぎて文字が読めない
(1)本題に入る前に
使うのは【1】と同様、Kickstarter Projectsです。先ほどと全く同じになりますが、必要なものをインポートしておきましょう。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import math
import pandas as pd
import seaborn as sns
df = pd.read_csv(r"C:~~\ks-projects-201801.csv")
(2)可視化を色々してみる
先ほどと全く同様に、1つずつ特徴量を見ていく中でこの問題に直面しました。
まずは「maincategory」の件数を見てみよう!と思い、図示してみました。
df["main_category"].value_counts().plot(kind = "bar", stacked = True
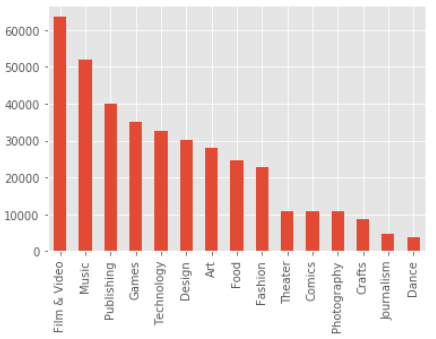
ほうほう、ものすごくどれかに偏ってるわけじゃないんだな・・この後は、成功・失敗別に図示していきたいな、とぼんやり思っていました。
まあ、とりあえず次に似たような「category」を図示してみようかと思い、試してみました。
df["category"].value_counts().plot(kind ="bar")

・・・。読めない・・・・・。
実はこれ、前にも全く同じことで行き詰って、その時は調べてもわからなかったので放置してしまっていたのです。
これは今後もまた同じことになるなと思い、どうしたらいいか考えました。
自分が知りたいのは、頻度が多いcategoryの種類だったので、上位の項目が何かを一旦見てみようと考えました。
そこで、10,000回以上出現するデータだけに絞ってみようと思い、下記のようにしました
df["category"].value_counts()[df["category"].value_counts() > 10000].plot(kind="bar")
plt.show()
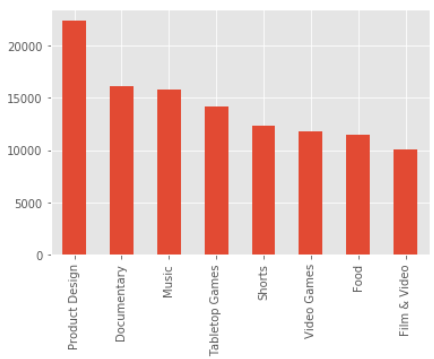
すると、上位の項目だけがきれいに表示されました!!
いくらか調べてみましたが、おそらくこのやり方が最初のとりあえずデータを見てみる、レベルでは一番適しているような気がしました。
冷静に考えたら普通なのですが、プログラミングを勉強したてのころは、一発できれいに見える何か魔法の様なやり方があるのでは・・とかいろいろ考えて時間を浪費していましたが、自分がやりたいことを考えるとこのやり方でいいという結論に今は行きついています。
6.結び
以上になります。
このように言葉で書けば一瞬ですし、多くの方が「そりゃそうだろう」という内容だと思うのですが、やはり超初心者の自分はこういう所に毎回躓き、なかなかうまく進められないという経験を今でもしています。
**「誰しも最初からうまいやり方を知っているわけではない」「皆、1つ1つ粘り強く取り組んで少しずつできるようになっているのだ」**ということが伝わりますと幸いです。
「こうすればいい」という本やサイトはありますが、「こういうところで苦しんで、こう考えて解決した」という過程を記したコンテンツが少ないと思うので、自分の様な初学者の方へのモチベーションアップや、知識増強の一助になりましたら幸いです。