1.目的
2018年12月頃からプログラミング(python)の勉強を始めて、kaggleに取り組み始めたのはこの数か月です。
その中で、「これってどうやるんだろう」と思ったものがたくさんあり、色々調べながら進めていったので、今回はその「前処理」にフォーカスし、そのまとめをしておこうと思います。
2.使用するデータと必要なもののインポート
kaggleではおなじみのタイタニックです。
https://www.kaggle.com/c/titanic
import matplotlib
import matplotlib.pyplot as plt
matplotlib.style.use('ggplot')
import seaborn as sns
import numpy as np
import pandas as pd
データの読み込みをしていきます。
df_train = pd.read_csv(r"C:///train.csv")
df_test = pd.read_csv(r"C:///test.csv")
3.データ外観(統計量)
(1)データ数の確認【.shape】
df_train.shape
df_test.shape
これで訓練データが(891, 12)、テストデータが(418, 11)と分かります。
(2)データをちょっと見る【.head()】
どんなデータが入っているのかを見るために、先頭5行を出してみます。
df_train.head()
df_test.head()
こんな感じのデータになっているようです。
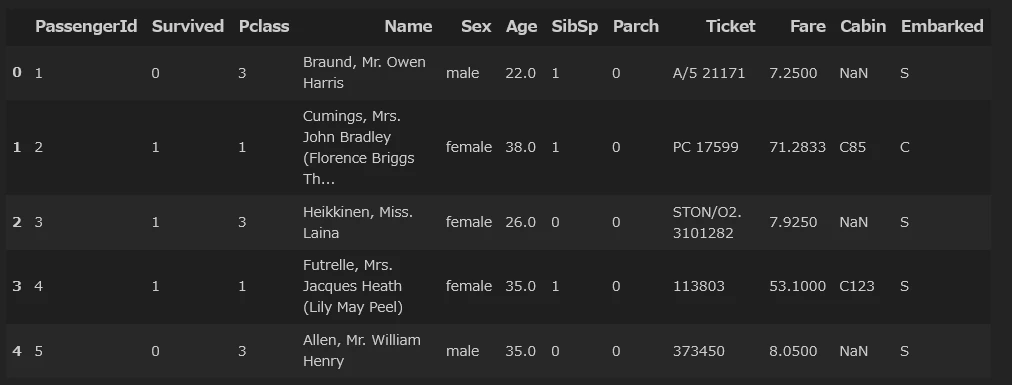
df_test.head()もすればわかりますが、列は訓練データの列から目的変数である「Survived」が消えた列が表示されます。
(3)データの型を見てみる【.info()】
訓練データとテストデータの情報を1つにまとめてみてみましょう。
df_train.info()
print("-"*48)
df_test.info()
各列のデータ数やデータ型をざっと確認することができます。

(4)数値データ・カテゴリデータの情報を見てみる【.describe()】
◆数値データ
df_train.describe()

数値データの情報が表示されます。
◆カテゴリデータ
df_train.describe(include=['O'])

カテゴリ変数であるName,Sex,Ticket,Cabin,Embarkedがそれぞれの個数・ユニーク値、トップの頻度のカテゴリ、その出現回数が表示されます。
4.訓練データとテストデータを統合する
これは初期のころに非常に躓いたので、私としては重要です。
最終的には訓練データとテストデータで分けて学習していくのですが、欠損値処理やカテゴリ変数処理といった前処理を訓練データとテストデータそれぞれに行うと煩雑なので、最初はまとめておき、後からまた分けていきます。
# TrainFlagという列を新たに作り、訓練データにはTrue、テストデータにはFalseとしておく。
df_train["TrainFlag"] = True
df_test["TrainFlag"] = False
# 訓練データとテストデータを結合する
df_all = df_train.append(df_test)
# PassengerIdはおそらく特徴量には使われないと思われるので、消したい。
# しかし後からテストデータの提出の際にどうせ必要なので完全には削除しないために、
# インデックスとして残しておく
df_all.index = df_all["PassengerId"]
df_all.drop("PassengerId", axis = 1, inplace = True)
ここで、df_allを見てみると、このようになります。
インデックスがPassengerIdになり、一番右には先ほど追加したTrainFlag列があります。
Trueが訓練データ、(ここには写っていないですが)Falseがテストデータです。

5.欠損値処理
(1)欠損値の数を調べる
このようにすると、降順に並び替えられます。
df_all.isnull().sum().sort_values(ascending=False)

今回くらいの変数数ならいいのですが、もっと変数が増えた際に、全説明変数の欠損値の数値が出されたら非常に見づらいです。
そこで、「欠損値がある」変数だけに絞って、降順に並び替えてみましょう。
df_all.isnull().sum()[df_train.isnull().sum()>0].sort_values(ascending = False)

そうすると、欠損値がある変数だけが降順に並び替えられました!
(2)欠損値処理を行う
◆Cabin
df_all.shapeをすると、訓練データとテストデータを結合したらデータ数は1,309です。
このうちCabinの欠損は1,014もあるので、今回は分析の対象から列ごと外そうと思いますので、ここでの欠損値処理は行わないこととします。
◆Age
Ageもそこそこ欠損値がありますが、すごく多いわけではないことと、今回は触れないのですが年齢はモデルに影響を与えそうなので、欠損値処理を行います。
やり方はいくるかあるのですが、今回はオーソドックスに平均値で埋めようと思います。
df_all["Age"] = df_all["Age"].fillna(df_all["Age"].mean())
◆Embarked
df_all.describe(include=['O'])をすると、Embarkedはユニーク値が3つしかなく、しかもそのほとんどが「S」であることがわかるので、今回は欠損値をSで補完します。
※本来はもう少ししっかりデータ可視化や分析をした方がいいです。

df_all["Embarked"] = df_all["Embarked"].fillna("S")
(3)最後に、欠損値がなくなったか確認
df_all.isnull().sum()[df_train.isnull().sum()>0].sort_values(ascending = False)
すると、Cabinのみ欠損が残った状態だとわかるので、欠損値処理はこれで完成です。
6.不要行の削除
今回は細かい検討は割愛しますが、データ分析の結果、Cabin,Name,PassengerId,Ticketは今回のモデル構築には不要と判断したとします。
これらの列を消していきましょう。
df_all = df_train.drop(["Cabin", 'Name','PassengerId','Ticket'], axis = 1)
7.カテゴリ変数の変換
df_all = pd.get_dummies(df_all, drop_first=True)
df_all.head()で確認すると、このようにカテゴリ変数が処理できたことが分かります。

以上で、めちゃくちゃオーソドックスな前処理が完了し、この後本格的なモデル構築へと進んでいきます。
8.結び
中級以上の方には非常に初歩的な内容ですが、最初はこれらを調べながら進めていくのにもすごく苦労し、そのたびにストレスを抱えていました。
そのような方に、少しでも理解の深化の一助になりましたら幸いです。