1.目的
Kaggleを始めとしてデータ分析を行う際、
ほぼ毎回使うにも拘らず書き方を忘れて、都度検索しているコードがある。
毎回「これを使いたい」というコードは割と定例化されているので、蓄積しておくことが目的です。
2.使用データ
広く知られている、kaggleのタイタニックをテーマにします。
3.目的別コード
(1)その前に・・
必要なもののインポートとデータ読み込みをします。
# インポート(不要なものも一部あり)
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
matplotlib.style.use('ggplot')
%matplotlib inline
# データ読み込み
df_train = pd.read_csv("C:train.csv")
df_test = pd.read_csv("C:test.csv")
(2)特定の条件の情報を見たい
(ⅰ)単一条件の場合
例えば、まずはFareをヒストグラム化します。
sns.distplot(df_train["Fare"])

すると、大半が低いところに固まっているにも関わらず、ほんの一部、
500を超えている人たちがいますね。
この人たちの他の説明変数の情報も見たい場合、下記のようにします。
この、[]と()の使い方を毎回忘れてしまうのです・・・。
df_train_Fare = df_train[(df_train["Fare"] > 500)]
df_train_Fare
するとこのように、Fareが500以上の人が表示(この場合は3人)されるので、
何か他の変数に特徴がないか?等を分析することができます。

ちなみに条件が数値(先ほどの例で言うと500以上)ではなくカテゴリ(文字列)の場合はこのようにします。
# 例えば、男性だけのデータをdf_train_Sexに格納
df_train_Sex = df_train[(df_train["Sex"] == "male")]
# 男性だけのFareのヒストグラムを描画
sns.distplot(df_train_Sex["Fare"])

(ⅱ)複数条件の場合
先ほどの例で、例えばFareが500以上かつ男性のデータを参照したいとします。
(データ分析上、需要があるかは別として)
その場合、下記のように複数条件をつなぎます。
私はこの書き方を頻繁に忘れてしまいます。
df_train_male_Fare = df_train[(df_train["Fare"] > 500) & (df_train["Sex"] == "male")]
df_train_male_Fare
するとこのように、Fareが500以上の男性のデータが抽出されます!

上記は「かつ(&)」で結びましたが、「または(or)」で結びたい場合は「&」を「|」で結んでください。
(3)groupbyしたい
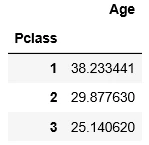
例えばPclass毎のAgeの平均を見たいとします。
そういったときはgroupbyをするのがいいですが、このやり方もよく
忘れてしまいます。
groupby = df_train["Age"].groupby(df_train["Pclass"]).mean()
# データフレーム化
groupby = pd.DataFrame(groupby)
groupby
Pclassごとの平均年齢を出すことができました!
4.結び
よく使うコードを控えておくのも煩雑だし、かといって都度調べるのも非効率と感じる場面が多いと思います。
今回のコードは割と細かい調査をする時に使う場面が多いと思うので、
少しでもお役に立てますと幸いです。