目的
韓国からSQL Serverチュニングガイドと言う本を購入して勉強していますが、SQLServerのIndexについて分かりやすかったので日本語で整理して見ました。
韓国語で書いている本なのでいい内容は日本語で整理するので初心者に参考になればと思います。
実行環境
Docker(mcr.microsoft.com/mssql/server:2017-latest)からSQL Server環境を作ってAzure Data Studioで実行しました。
使ったテーブル
CREATE TABLE [members](
[id] [int] IDENTITY(1,1) NOT NULL,
[name] [nvarchar](4000) NOT NULL,
[age] [int] NOT NULL,
[created_at] [datetime2](6) NOT NULL,
[updated_at] [datetime2](6) NOT NULL
)
Indexについて
B-Tree構造に保存されます。
以下のような構造になってデータはページ単位で保存されます。
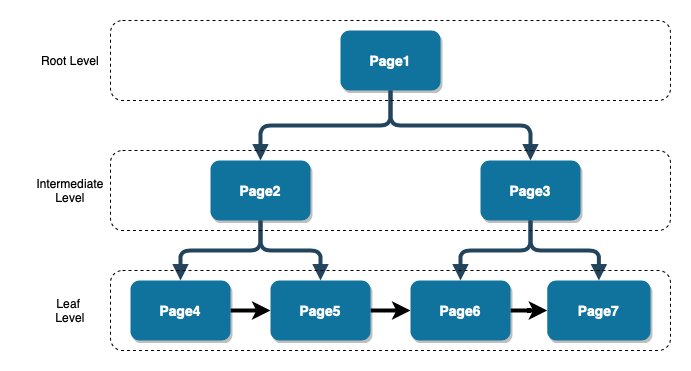
LeafページにはIndexキーを基準に整列されたデータが保存されます。
Intermediate/Rootページは子ページの最初Indexキーと一緒に該当するページの位置を指すポイントの役割をしています。
Indexの種類
IndexはClustered IndexとNon-Clustered Indexが存在します。
Clustered Index
1.テーブル自体をIndexにする。
2.キーカラムを基準にして整列された状態を維持する。
3.テーブルに1個だけ生成可能。
CREATE CLUSTERED INDEX [インデックス名]
ON [テーブル名] ([列名1],[列名2])
GO
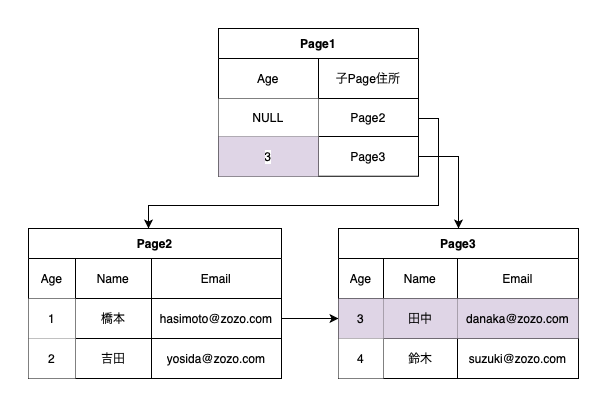
例)age列をキーにした場合、
ageが3のデータを探す場合、最初Page1のageで3のageがPage2の最初に存在するのがわかるのでLeafのPage2に移動、最初の行から全てのデータ取得可能。
Non-Clustered Index
1.Non-Clustered Indexはのテーブルと別に生成される。
2.キーと一緒にRID(テーブルの行位置アドレス)を保存する。
3.キーカラムを基準にして整列、最大999個作れる。
CREATE NONCLUSTERED INDEX [インデックス名]
ON [テーブル名] ([列名])
GO
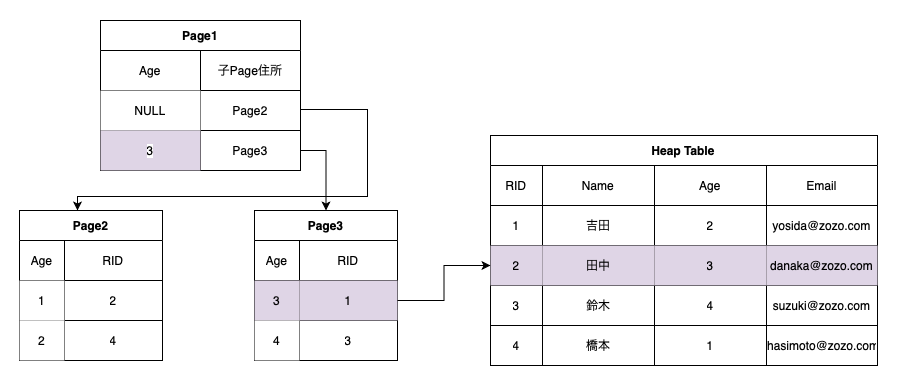
例)age列をキーにした場合、
ageが3のデータを探す場合、最初Page1のageで3のageがPage2の最初に存在するのがわかるのでLeafのPage2に移動、最初の行からRIDを取得してRIDからHeap Tableを参照して全てのデータ取得。
Non-Clustered Indexがあるテーブル検索の時に実行計画にRID Lookupが表示されるのはHeap Table(整列されてない元テーブル)を参照する意味になります。
Index Scan方式
データを照会するための使用される方法としてScanとSeekがあります。
Scanはテーブル全体もしくはIndex全体を読む方式、SeekはIndexを通じて条件に該当する特定範囲だけを読む方式です。
Table Scan
テーブル全体を最初から読みながらスキャンする方式
全てのデータを読んで最終結果を作る。
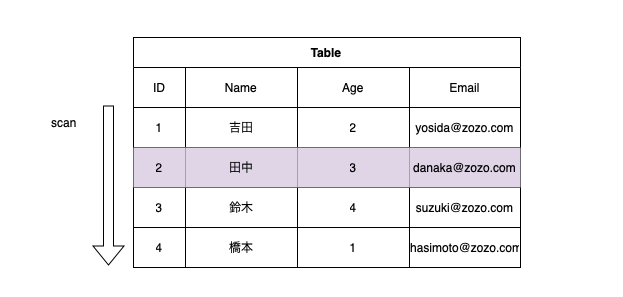
select * from members where age = 3
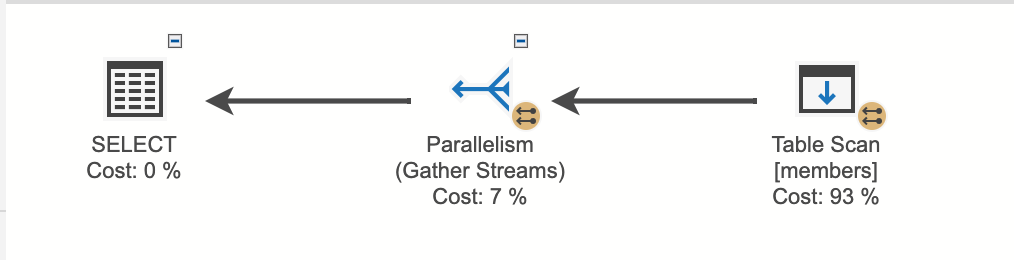
Clustered Index Scan
検索条件にIndexキーを指定してない場合、全ての行を読みながらスキャンする方式
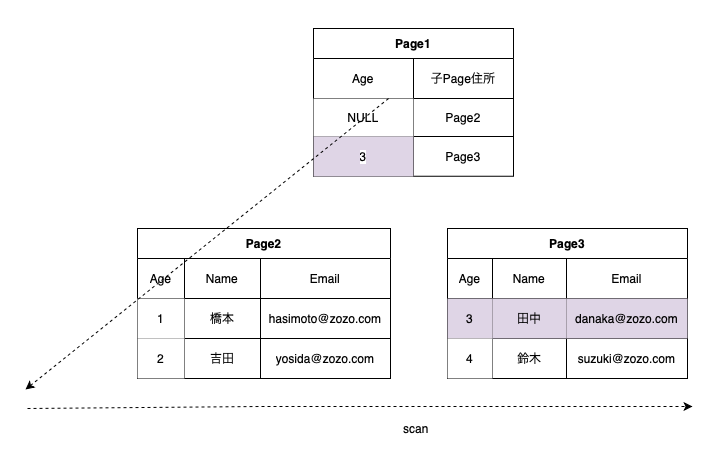
例)ageカラムのIndexが存在する時にnameカラムで検索
Indexが存在しないので全ての行を読む
CREATE CLUSTERED INDEX IX_members_age
ON [master].[dbo].[members] (age);
GO
select * from members where name = '田中'
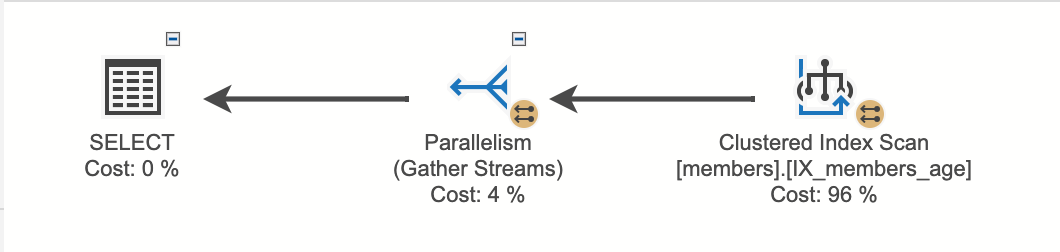
Clustered Index Seek
Clustered Indexキーカラムを検索条件に入れて検索する場合、B-Treeを利用して早く該当するデータを見つけられる。
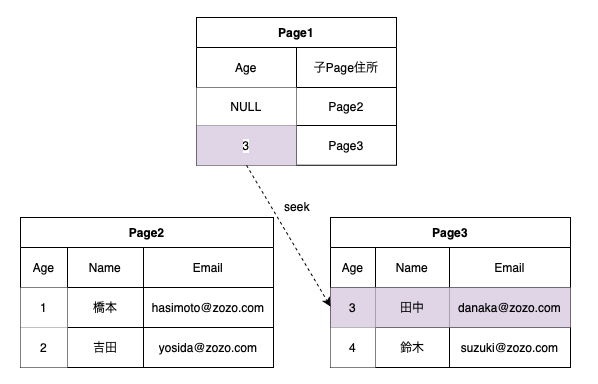
例)ageカラムのIndexが存在する時にageカラムを検索条件に入れて検索
CREATE CLUSTERED INDEX IX_members_age
ON [members] (age);
GO
select * from members where age = 2

Non-Clustered Index Scan
条件のカラムがNon-Clustered Indexに含まれているが、検索条件として使用できない場合発生
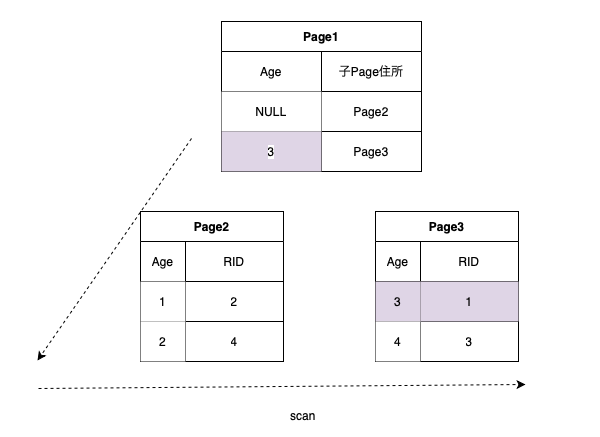
例)ageカラムのIndexが存在する時にageカラムを検索条件に入れて検索
CREATE NONCLUSTERED INDEX IX_members_age
ON [members] (age);
GO
select count(*) from members where age + 1 > 10

Non-Clustered Index Seek
要求されたカラムが Non-Clustered Indexに全て含まれた場合発生
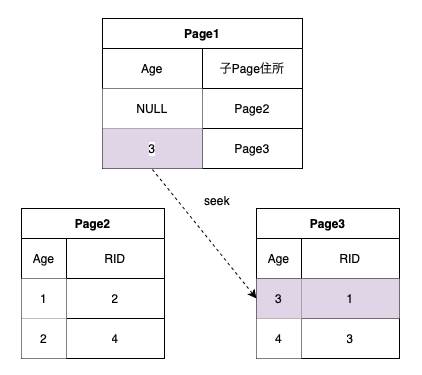
CREATE NONCLUSTERED INDEX IX_members_age
ON [master].[dbo].[members] (age);
GO
select name from members where age = 3
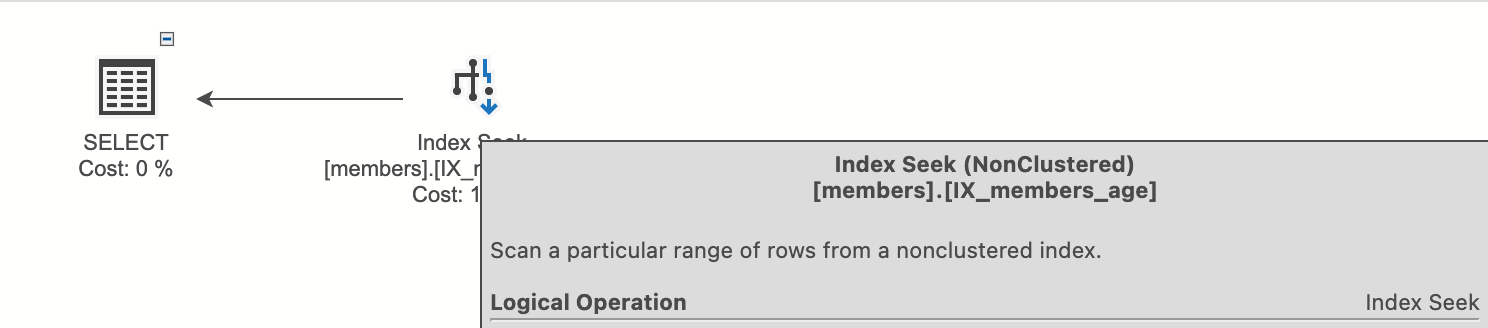
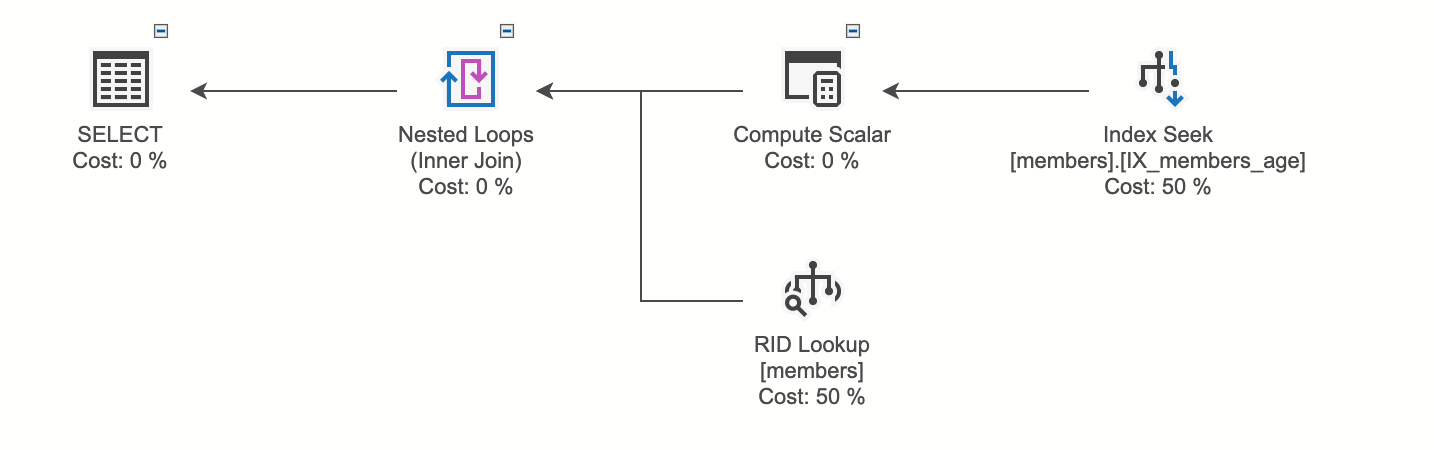
RID Lookup
Non-Clustered Index検索後参照したいカラムのデータがない場合、Heepテーブルをjoinする必要がある
Non-Clustered Indexがageカラムをキーにした場合、nameデータはIndexに存在しないため、RIDとHeap Tableをjoinしてnameを取得する過程
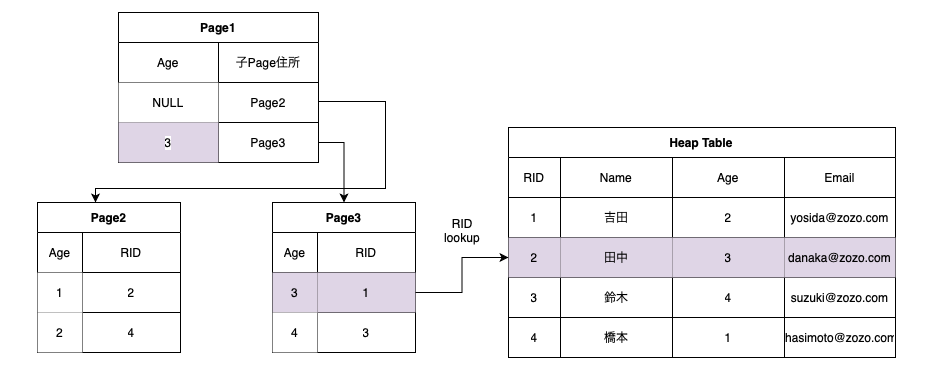
CREATE NONCLUSTERED INDEX IX_members_age
ON [master].[dbo].[members] (age);
GO
select name from members where age = 3
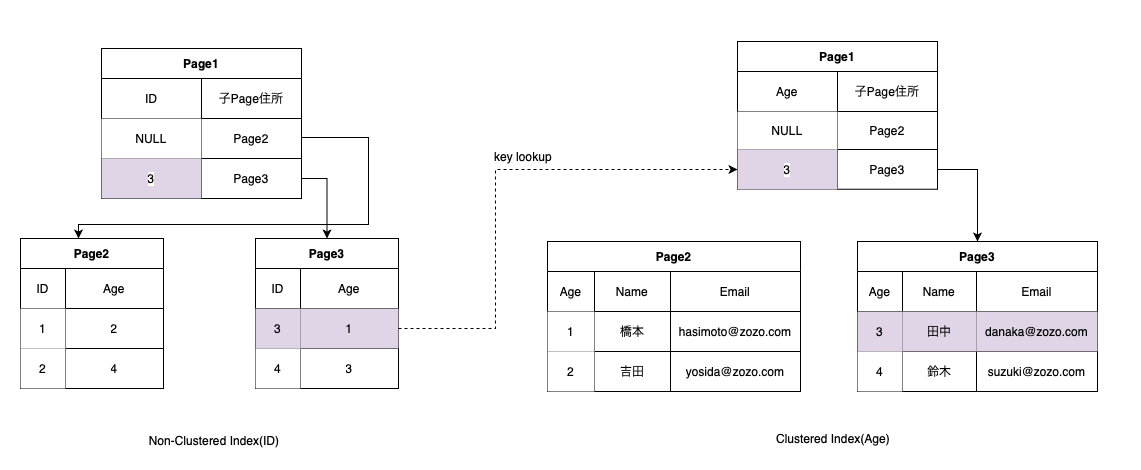
Key Lookup
Non-ClusteredIndexとClusteredIndexが両方存在するときにNon-ClusteredIndexに必要なカラムが存在しな場合、Clusered Indexから足りないデータを取得する過程
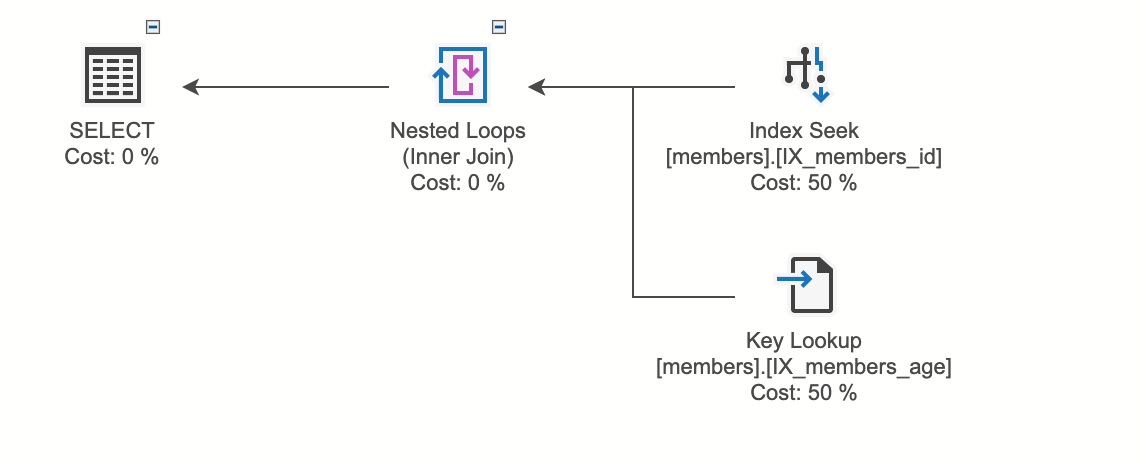
CREATE CLUSTERED INDEX IX_members_age
ON [master].[dbo].[members] (age);
GO
CREATE NONCLUSTERED INDEX IX_members_id
ON [master].[dbo].[members] (id);
GO
select name from members where id = 3
まとめ
SQLServerがIndexを使ってどのようにデータを検索してデータを取得するのか理解できたし実行計画で表示されるRID Lookup,Key Lookupについて理解できました!
この記事を読んだ人に少しは役に立つと幸いです。引き続き完読目指します!