cutコマンド
ファイルなどから行ごとに一部の文字を切り取るコマンドです。
下はよく使うオプションです。
| オプション | 意味 |
|---|---|
| -c | 取り出す文字の位置を指定して取り出す |
| -f | 取り出すフィールド番号を指定する |
| -d | デリミタ(区切り文字)を指定 |
オプションなどの資料です。
いろいろオプションを使って行きます。
●-c
1行目から4文字目を取り出します。
% echo "ABCDEF" | cut -c 1-4
ABCD
echoに-eを入れてみます。nを入れてみると下のように出力できます。
% echo -e "ABCDEFGH\n12345678" | cut -c 3-7
CDEFG
34567
このような書き方もできます。
% echo -e "ABCDEFGHI\nabcdefgh\n12345678" | cut -c "3,5,7"
CEG
ceg
357
他のオプションも試してみてください。
cutコマンドは各行から1行を切り出します。以下がオプションです。

上のオプションをベースに実行していきます。
Animal % cut -c 1 wanko_cut.txt
1
2
3
4
5
6
1列目から5列目を抽出。
Animal % cut -c 1-5 wanko_cut.txt
1.柴犬
2.チワワ
3. ゴー
4.ポメラ
5. ダッ
6. 雑種
4列目以降を抽出します。
Animal % cut -c 4- wanko_cut.txt
犬
ワワ
ゴールデンレトリバー
メラニアン
ダックスフンド
雑種
trコマンド
文字列の変換、削除をするコマンドです。
| オプション | 意味 |
|---|---|
| -s | 取り出す文字の位置を指定して取り出す |
| -s [:space] | 取り出すフィールド番号を指定する |
| -d | デリミタ(区切り文字)を指定 |
-d
Animal % echo "ABC" | tr -d "A" #-dでAが削除されます。
BC
Animal % echo "ABCDEFG" | tr -d "B,C,D"
AEFG
-s
% echo "ABBBCCDD" | tr -s "B,C,D" # -sで重複している文字を削除
ABCD
-s [:space]
Animal % echo "AABCA aaa dftggg ffff" | tr -s "[:space:]"
AABCA aaa dftggg ffff
headコマンド
ファイルや行数出力の行頭から何行か指定した行数分出力します。
| オプション | 意味 |
|---|---|
| -n | ファイルの行頭から◯◯行表示 |
| -c | ファイルの先頭から◯◯バイト取得 |
-n
Animal % cat dog.txt
雑種 黒 5
柴犬 肌色 8
プードル 白 3
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
Animal % head -n 1 dog.txt #1行目取得
雑種 黒 5
Animal % head -n 3 dog.txt #上3行を取得
雑種 黒 5
柴犬 肌色 8
プードル 白 3
Animal % head -2 dog.txt #-nがなくても大丈夫です。
雑種 黒 5
柴犬 肌色 8
-c
headコマンドと考えが似ています。
Animal % cat dog.txt
雑種 黒 5
柴犬 肌色 8
プードル 白 3
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
Animal % head -c 1 dog.txt
?%
Animal % head -c 20 dog.txt
雑種 黒 5
Animal % tail -n 3 dog.txt
プードル 白 3
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
Animal % tail -2 dog.txt
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
tailコマンド
ファイルや行数出力の行頭から何行か指定した行数分出力します。
| オプション | 意味 |
|---|---|
| -n | ファイルの行末から◯◯行表示 |
| -c | ファイルの末尾から◯◯バイト取得 |
| -F | ファイルの行末に追加されるテキストをリアルタイム表示 |
-n
Animal % cat dog.txt
雑種 黒 5
柴犬 肌色 8
プードル 白 3
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
Animal % tail -n 1 dog.txt
シベリアンハスキー 白黒 7
Animal % tail -n 3 dog.txt
プードル 白 3
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
Animal % tail -2 dog.txt
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
-c
Animal % tail -c 42 dog.txt
シベリアンハスキー 白黒 7
-F
history
コマンドの履歴を表示するコマンドです。

引用 https://atmarkit.itmedia.co.jp/ait/articles/1710/20/news015.html
Animal % history | tail -n 10 #過去10件のコマンド
1312 tail -c 38 dog.txt
1313 tail -c 48 dog.txt
1314 tail -c 40 dog.txt
1315 tail -c 43 dog.txt
1316 tail -c 42 dog.txt
1317 clear
1318 tail -42 dog.txt
1319 history
1320 clear
1321 cat dog.txt
Animal % history | grep clear #過去のclearを使った数 grepで絞り込み
1320 clear
1326 clear
wcコマンド
標準出力やファイルのサイズ、単語数、行数などの情報を取得するコマンドです。
| オプション | 意味 |
|---|---|
| wc -l | ファイルの行数を表示 |
| wc -c | ファイルの文字数を表示 |
| wc -W | ファイルの単語数を表示 |
Animal % cat dog.txt
雑種 黒 5
柴犬 肌色 8
プードル 白 3
シェパード 黒肌色 8
シベリアンハスキー 白黒 7
Animal % wc dog.txt
5 5 136 dog.txt
#5行 ワード数 文字
Animal % wc -l dog.txt #行数
5 dog.txt
Animal % wc -w dog.txt #単語数
5 dog.txt
Animal % wc -c dog.txt #文字数
136 dog.txt
catコマンド
ファイルなどの中身を見るコマンドです。
wanko_cut.txtの中をみてみます。
Animal % cat wanko_cut.txt
1.柴犬
2.チワワ
3. ゴールデンレトリバー
4.ポメラニアン
5. ダックスフンド
6. 雑種
catコマンドオプション
オプションを使ってみてみます。
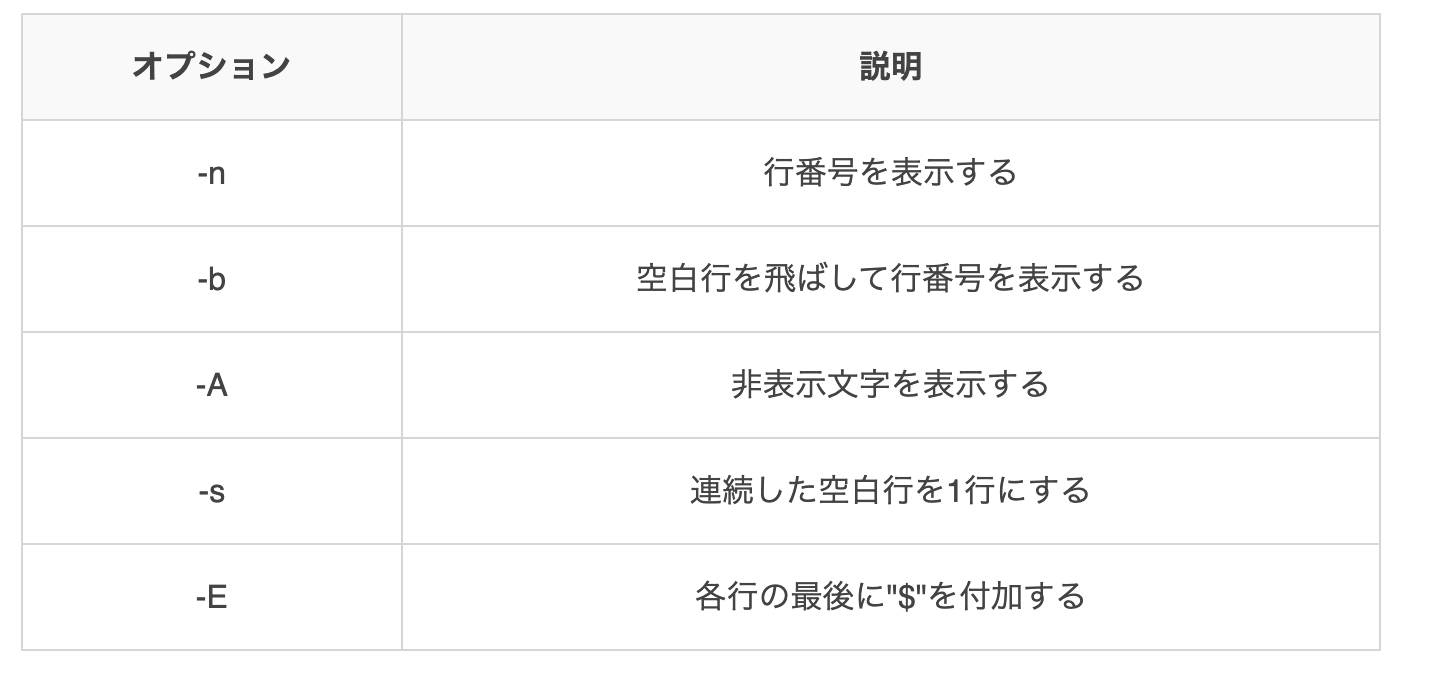
Animal % cat -n wanko_cut.txt
1 1.柴犬
2
3 2.チワワ
4
5 3. ゴールデンレトリバー
6
7 4.ポメラニアン
8
9
10 5. ダックスフンド
11
12
13 6. 雑種
14
15
expandコマンド
タブ区切りテキストファイルのデータを揃えて表示します。タブをスペースに変換するコマンドです。
| -t(オプション--tabs) | 揃える文字数 |
|---|---|
| -i(オプション--initial) | 行頭のタブ文字のみ変換 |
Animal % expand dog_expand.txt
1. 柴犬
2. チワワ
3. ゴールデンレトリバー
4. ポメラニアン
5. ダックスフンド
6. 雑種
Animal % expand -t 3 dog_expand.txt
1. 柴犬
2. チワワ
3. ゴールデンレトリバー
4. ポメラニアン
5. ダックスフンド
6. 雑種
lessコマンド
Animal % less dog_expand.txt
1. 柴犬
2. チワワ
3. ゴールデンレトリバー
4. ポメラニアン
5. ダックスフンド
6. 雑種
fmtコマンド
指定した桁に整形するコマンドです。
| オプション | 内容 |
|---|---|
| -w <行幅> | 1行の幅を指定する |
| -s | 行の分割のみ行い、結合はしない |
Animal % fmt -w 1 dog_fmt.txt
"I
love
dog
very
much"
join
2つのファイルから列の値が共通する要素に結合するコマンドです。
$ cat soccer1.txt
1 Neymar ブラジル
2 Messi アルゼンチン
3 Ronald ポルトガル
noriaki@PC-AIR-00259:~/day13$ cat soccer2.txt
1 30歳
2 35歳
3 37歳
$ join soccer1.txt soccer2.txt
1 Neymar ブラジル 30歳
2 Messi アルゼンチン 35歳
3 Ronald ポルトガル 37歳
$ cat soccer2.txt
1 30歳
2 35歳
3 37歳
$ cat soccer3.txt
30歳 パリ
35歳 パリ
37歳 マンチェスター
$ join -1 2 -2 1 soccer2.txt soccer3.txt
30歳 1 パリ
35歳 2 パリ
37歳 3 マンチェスター
$ sed -i 's/ /,/g' soccer2.txt
$ sed -i 's/ /,/g' soccer3.txt
$ cat soccer2.txt
1,30歳
2,35歳
3,37歳
$ cat soccer3.txt
30歳,パリ
35歳,パリ
37歳,マンチェスター
$ join -t "," -1 2 -2 1 soccer2.txt soccer3.txt | grep 3
30歳,1,パリ
35歳,2,パリ
37歳,3,マンチェスター
grep
ファイルや標準出力から、特定の文字を含んだ行だけ取り出す。
| オプション | 説明 |
|---|---|
| -v ○◯ | ○◯を含まない行だけ取り出す |
| -n | 行数も表示 |
| -i | 文字列の大文字と小文字を区別しない |
$ history | grep cat #catコマンドを使った履歴を調べる
$ history | grep 22 #22がつく履歴を調べます
$ history | grep -v cat #catがつくコマンド以外の履歴を表示
$ history | grep -v -n cat
nlコマンド
行番号をつける時に使います。
$ cat soccer1.txt
1 Neymar ブラジル
2 Messi アルゼンチン
3 Ronald ポルトガル
$ nl soccer1.txt
1 1 Neymar ブラジル
2 2 Messi アルゼンチン
3 3 Ronald ポルトガル
lessコマンド
ファイルの中身を表示するコマンドです。
$ less soccer1.txt
1 Neymar ブラジル
2 Messi アルゼンチン
3 Ronald ポルトガル
paste
複数のファイルを行単位で連結するコマンドです。
$ paste soccer1.txt soccer2.txt soccer3.txt
1 Neymar ブラジル 1,30歳 30歳,パリ
2 Messi アルゼンチン 2,35歳 35歳,パリ
3 Ronald ポルトガル 3,37歳 37歳,マンチェスター
splitコマンド
ファイルを特定のサイズで分割します。
| コマンド | 説明 |
|---|---|
| -b | |
| -l |
$ cat file.sh #file.shの中身確認
for i in {1..10}
do
echo "ABCDEFG" i>> newfile.txt
done
$ chmod 755 file.sh #権限を与える
$./file.sh #実行
$ ls
file.sh newfile.txt #newfile.txtが作成されているのを確認
split$ cat newfile.txt
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
ABCDEFG
$ wc -l newfile.txt
10 newfile.txt
$ split -b 10 newfile.txt
$ ls
file.sh xaa xac xae xag
newfile.txt xab xad xaf xah
$ ls -l
total 40
-rwxr-xr-x 1 noriaki noriaki 63 Aug 8 17:20 file.sh
-rw-r--r-- 1 noriaki noriaki 80 Aug 8 17:21 newfile.txt
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xaa
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xab
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xac
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xad
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xae
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xaf
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xag
-rw-r--r-- 1 noriaki noriaki 10 Aug 8 17:24 xah
$ head -1 newfile.txt
ABCDEFG
findコマンド
ファイルなどを検索するコマンドです。
$ mkdir tmp
$ mkdir tmp/tmp2
$ touch tmp/file1
$ touch tmp/file2
$ touch tmp/file3
$ touch tmp/file4
$ touch tmp/tmp2/new_file
$ find ./ -name "file*"
./file.sh
./tmp/file3
./tmp/file2
./tmp/file1
$ find ./ -name "*file*"
./file.sh
./new2_file.txt
./newfile.txt
./tmp/file3
./tmp/file2
./tmp/file1
./tmp/tmp2/new_file
$ find ./ -name "*file"
./tmp/tmp2/new_file
$ find ./ -type f #ファイルを検索
./file.sh
./new2_file.txt
./newfile.txt
./tmp/file3
./tmp/file2
./tmp/file1
./tmp/tmp2/new_file
$ find ./ -type d #ディレクトリを検索
./
./tmp
./tmp/tmp2
$ find ./ -mtime -3 #更新日時が3日以内
./
./file.sh
./new2_file.txt
./newfile.txt
./tmp
./tmp/file3
./tmp/file2
./tmp/file1
./tmp/tmp2
./tmp/tmp2/new_file
$ find ./ -size -10k
./
./file.sh
./new2_file.txt
./newfile.txt
./tmp
./tmp/file3
./tmp/file2
./tmp/file1
./tmp/tmp2
./tmp/tmp2/new_file
$ find ./ -size +1k
./
./tmp
./tmp/tmp2
sedコマンド
指定したファイルをコマンドに従って処理することが出来るコマンドです。
以下がオプションです。
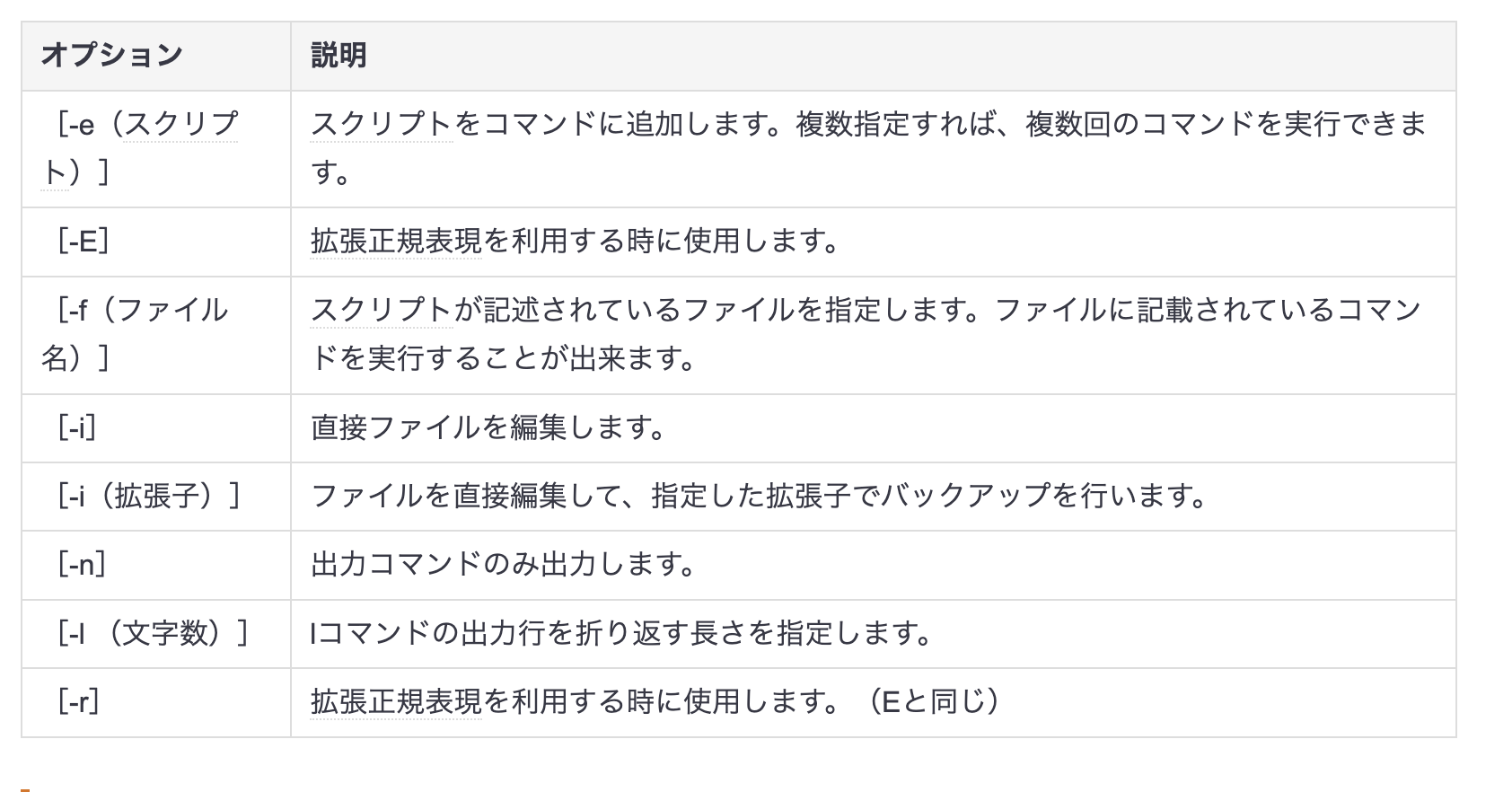
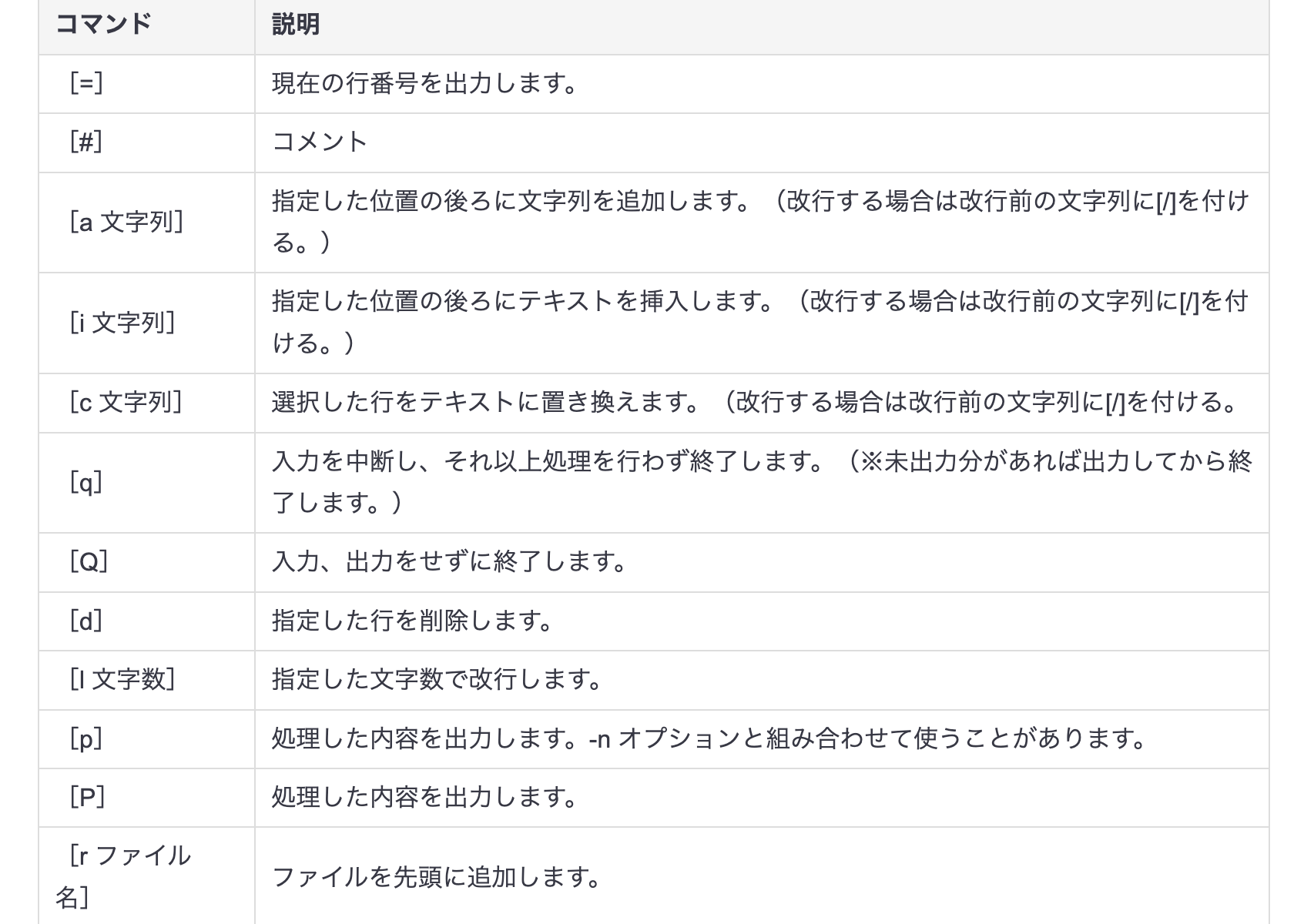

Dogを犬に変換します。上の表を参考にしながら確認してみてください。
Animal % echo "Dog Cat Monkey"
Dog Cat Monkey
Animal % echo "Dog
Cat Monkey" | sed "s/Dog/inu/g"
inu Cat Monkey
1文字のみを書き換えます。
Animal % cat sample_sed.txt
1, Dog
2, Cat
3, Monkey
4, Lion
Animal % sed s/o/a/ sample_sed.txt
1, Dag
2, Cat
3, Mankey
4, Lian
単語を書き換えます。
Animal % cat sample_sed.txt
1, Dog
2, Cat
3, Monkey
4, Lion
Animal % sed s/Dog/Bird/ sample_sed.txt
1, Bird
2, Cat
3, Monkey
4, Lion
ファイルを作ってみてその中に文章を記述します。
Animal % vim sed.txt #ファイルの中身作成
Animal % cat sed.txt
This dog is very pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
#3行目を消す
Animal % sed "3d" sed.txt
This dog is very pure.
This cat is very cute.
That lion looks strong.
#1行目から3行目を消す
Animal % sed "1,3d" sed.txt
That lion looks strong.
注意点としてファイルの中身が消えたわけではないです。
3行目などが消えて出力されているだけです。
'$d'で最終行を消せます。
Animal % sed '$d' sed.txt
This dog is very pure.
This cat is very cute.
That monkey is calm.
Animal % cat sed.txt
This dog is very pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
指定の行を取り出す方法です。
Animal % cat sample_sed.txt
1, Dog
2, Cat
3, Monkey
4, Lion
Animal % sed -n 1p sample_sed.txt #1行目を取り出す
1, Dog
Animal % sed -n 1,3p sample_sed.txt #1行目から3行目を取り出す
1, Dog
2, Cat
3, Monkey
Animal % sed 1,3d sample_sed.txt #1行目から3行目を消した状態で取り出す
4, Lion
Animal % sed y/1o/2b/ sample_sed.txt
2, Dbg
2, Cat
3, Mbnkey
4, Libn
下は文字を指定した削除法です。
Animal % cat sed.txt
This dog is very pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
Animal % sed '/cute/d' sed.txt #cuteが入っている行を消します。
This dog is very pure.
That monkey is calm.
That lion looks strong.
何も書いていない行を削除します。
Animal % cat sed.txt
This dog is very pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
Animal % sed '/^$/d' sed.txt #^$を使う
This dog is very pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
指定した文字を変換します。
Animal % cat sed.txt
This dog is very pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
Animal % sed 's/pure/loyal/g' sed.txt #pureをloyalに変えます。
This dog is very loyal.
This cat is very cute.
That monkey is calm.
That lion looks strong.
同じ行にある同じ文字を変換します。
Animal % cat sed.txt
This dog is very pure. That girl is pure.
This cat is very cute.
That monkey is calm.
That lion looks strong.
Animal % sed "s/pure/loyal/2" sed.txt
This dog is very pure. That girl is loyal.
This cat is very cute.
That monkey is calm.
That lion looks strong.
ファイルの中の文字を変える場合です。
Animal % sed -i s/cute/kind/g sed.txt
#今回は出力結果省略
sortコマンドで
ファイルの行を 降順と昇順に並び替えて出力します。
こちらの記事にオプションが詳しく載っています。
Animal % cat sort.txt
1, Dog
4, zebra
3, Monkey
13, elephant
15, cat
Animal % sort sort.txt #
1, Dog
13, elephant
15, cat
3, Monkey
4, zebra
Animal % sort -n sort.txt #数値順で並べる
1, Dog
3, Monkey
4, zebra
13, elephant
15, cat
Animal % sort -R sort.txt #ランダムに並びかえ
15,cat
4, zebra
3, Monkey
1, Dog
13,elephant
Animal % sort -rn sort.txt #逆順に並び変える
15,cat
13,elephant
4, zebra
3, Monkey
1, Dog
Animal % sort -t "," -k 2 sort.txt #カンマ区切りの2列目を起点にsort -kはkey
1, Dog
3, Monkey
4, zebra
15,cat
13,elephant
Animal % sort -t "," -k 3 -n -r sort.txt #3列目を基準にsortし逆順にする
4, zebra
3, Monkey
15,cat
13,elephant
1, Dog
uniqコマンド
重複している行を削除します。
以下の記事にオプションが載っています。
Animal % cat test.txt
A
A
V
V
C
C
D
D
Animal % uniq test.txt
A
V
C
D
ABC順の並べ方です。
Animal % sort uniq.txt
A
A
C
C
D
D
E
V
V
Animal % sort uniq.txt | uniq
A
C
D
E
V
Animal % sort uniq.txt | uniq -d #重複していない文字は含まれないのでEはなし
A
C
D
V
Animal % sort uniq.txt | uniq -u #重複していない文字を取り出す
E
テキスト処理コマンド
フィルタコマンド
フィルタとはファイルやテキストのデータを読み込み、
コマンドで何か処理をし出力するプログラムのことです。
catコマンド
ファイルの中身を見れるコマンドですが、複数のファイルを1つのファイルにまとめることができます。
-nをつけると各行の左端に行番号をつけます。
まずファイルの中身を書きます。
Animal % touch dog
Animal % touch cat
Animal % echo ‘犬’ >> dog
Animal % echo ‘猫’ >> cat
Animal % cat dog
‘犬’
Animal % cat cat
‘猫’
Animal % touch zoo
複数のファイルを1つのファイルにまとめる処理をやっていきます。
Animal % ls
cat dog zoo
Animal % cat dog cat > zoo #複数のファイルを1つのファイルにまとめる処理
Animal % ls
cat dog zoo
Animal % cat zoo
‘犬’
‘猫’
これでzooにdogとcatファイルの内容をまとめることができました。
odコマンド
ファイルの内容を指定の形式で出力します。バイナリファイルをテキスト形式で見たい時に使います。
-tで出力する形式を指定します。
cでASCil文字、oで8進数、xで16進数で出力します。
Animal % od -tc dog
0000000 犬 ** ** ** ** \n
0000007
Animal % od -tx monkey
0000000 e3bf8ce7 000a8080
0000007
バイナリファイルをこの記事をベースに作成することができそうです。
https://blog.katsubemakito.net/linux/dd-createfile
headとtailコマンド
headコマンドはファイルの先頭部分を表示します。
tailコマンドはファイルの末尾の部分を表示します。
- 表示する行数でどこまで見たいかが表示できます。
オプションを使わない場合は10行目までそれぞれ表示します。
tailだと-fオプションでリアルタイム表示ができます。
headを使います。
practice.txt % head practice.txt
dog
cat
monkey
elephant
fox
wolf
crocodile
zebra
gorilla
tiger
practice.txt % head -3 practice.txt
dog
cat
monkey
tailを使うと
practice.txt % tail -3 practice.txt
zebra
gorilla
tiger
cutコマンド
ファイル内から指定したところを取り出して出力します。
文字数を1-9に指定して1文字から9文字まで抜き出します。
区切りに使用される文字をデリミタというみたいです。
区切られたかたまりをフィールドというみたいです。
$ cut -d: -f 3 practice.txt
区切りの手順が:で区切られたかたまり3番目をpractice.txtから取り出すという意味です。
-c文字数取り出す文字の位置指定、-d区切り文字文字列の区切れ目となる文字指定、
-fフィールド番号 取り出す文字列の固まりを指定します。
taro % cat practice.txt
dog
cat
monkey
elephant
fox
wolf
crocodile
zebra
gorilla
tiger
taro % cut -do -f 3 practice.txt
cat
elephant
dile
zebra
tiger
join
2つのファイルを読み込んで、共通するフィールドがある行を水平に連結します。
オプション-j番号で左から何番目のフィールドを使い比較するか指定します。
expandとunexpand
expandコマンドはテキストファイルの中にあるタブをスペース(8文字分)に変換します。
-iは 行の最初のタブのみ変換し、-tタブの幅は1つのタブがスペースいくつ分になるか指定。
unexpandコマンドはテキストファイルの最初にある空白をタブに変換します。
-aは 行の最初以外の空白も変換し、-tタブの幅は1つのタブがスペースいくつ分になるか指定。
fmt
fmtコマンドはテキストを決まった文字数で改行します。-w文字数で1行あたりの文字数を指定します。
Animal % cat dog #dogはファイル名
犬
チワワ トイプードル
柴犬
Animal % fmt -w6 dog
犬
チワワ
トイプードル
柴犬
pr
prコマンドはファイルをページごとの形式に整えます。
オプションは+開始:終了ページ番号は開始、終了ページを指定します。
-l行数は1ページあたりの行数を指定します。
tr
trコマンドは文字列から、指定の文字列を変換したり削除できます。
オプションは-dは引数で指定した文字列を削除し、
-sは引数で指定した文字列が連続する時、1つだけにする。
split
splitコマンドは指定した行数で別のファイルにファイルを分割します。
オプションは-行数は何行ごとに分割するか指定します。
uniq
uniqコマンドはテキストデータの内容で重複している行を1つにします。
オプションは-dは重複している行のみ出力、-uは重複していない行だけを出力します。
wc
ファイルの行数、単語数、文字数を表示します。
Animal % cat dog
犬
チワワ トイプードル
柴犬
Animal % wc -c dog #dogはファイル名
49 dog
Animal % wc -l dog
6 dog
Animal % wc -w dog
5 dog
-c(バイト数で)文字数を表示し、-l行数を表示し、-wは単語数を表示します。
資料