作ったもの
紙の書類などスキャンして管理してると
↓こんな感じでファイル名がカオスになりがち…
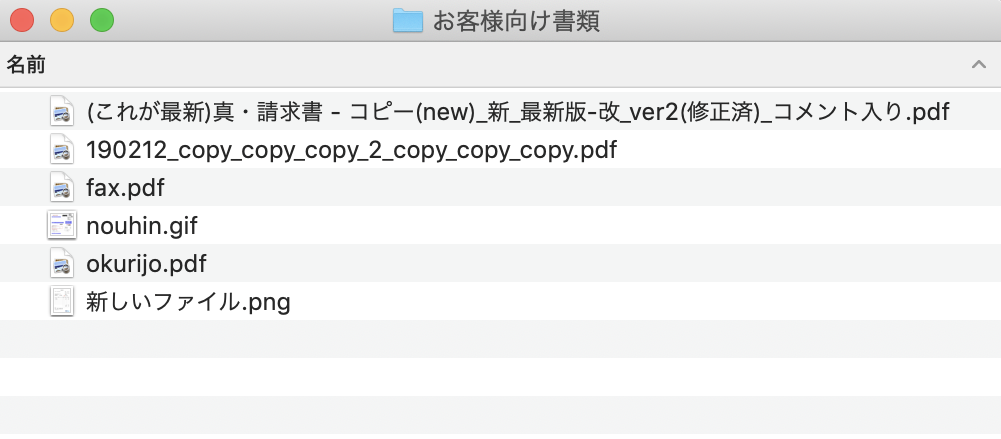
そこで、今回のツールを一発たたくとこうなります。
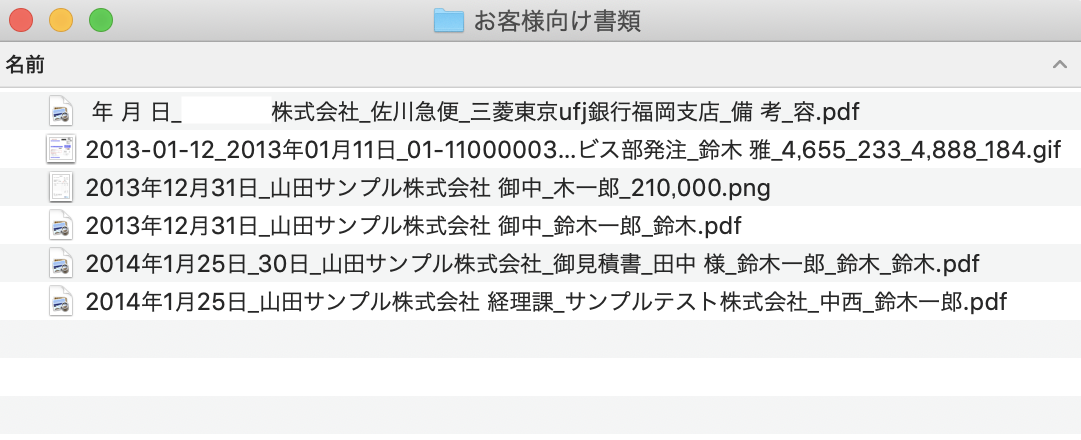
何となく中身が推測できるようになりました。
このツールは何?
請求書・名刺・Webページなどのpdf・画像ファイルの中身を読み取り、重要(っぽい)ワードで自動リネームするツールです。
内部では以下を行ってます。
- ファイルをGoogle Driveにアップロード (G Suiteが理想)
- OCRされたテキストを抽出
- 重要部分をNTTコミュニケーションズの固有表現抽出APIで抽出 (企業名とかの専門用語辞書使うと精度上がるっぽいけど無料版だと使えない…)
- 日付、会社名、人名を結合したファイル名を作りリネーム
動作確認環境
Mac 10.14.3
Python 3.7.2
動かし方手順
1.ファイルをGoogle Drive APIでアップロードできるようにする
Google Drive APIを使えるようにするために、
Python Quickstartを行います。
STEP1、STEP2をこなせばOKです。
STEP1でダウンロードしたcredentials.jsonは以降も使います。
2.ファイルをアップロードしてOCR結果を取得してみる
以下のコードをcredentials.jsonと同じフォルダにおいて実行します。
コードはこちら(クリックで展開する)
from __future__ import print_function
import httplib2
import os
import io
import sys
from apiclient import discovery
from oauth2client import client
from oauth2client import tools
from oauth2client.file import Storage
from apiclient.http import MediaFileUpload, MediaIoBaseDownload
SCOPES = 'https://www.googleapis.com/auth/drive'
CLIENT_SECRET_FILE = 'credentials.json'
APPLICATION_NAME = 'Drive API Python Quickstart'
def get_credentials():
"""Gets valid user credentials from storage.
If nothing has been stored, or if the stored credentials are invalid,
the OAuth2 flow is completed to obtain the new credentials.
Returns:
Credentials, the obtained credential.
"""
credential_path = os.path.join("./", 'drive-python-quickstart.json')
store = Storage(credential_path)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = APPLICATION_NAME
credentials = tools.run_flow(flow, store)
print('Storing credentials to ' + credential_path)
return credentials
if __name__ == '__main__':
credentials = get_credentials()
http = credentials.authorize(httplib2.Http())
service = discovery.build('drive', 'v3', http=http)
imgfile = 'sample.pdf' # Image with texts (png, jpg, bmp, gif, pdf)
txtfile = 'output.txt' # Text file outputted by OCR
args = sys.argv
if len(args) >= 2:
imgfile = str(args[1])
mime = 'application/vnd.google-apps.document'
res = service.files().create(
body={
'name': imgfile,
'mimeType': mime,
},
media_body=MediaFileUpload(imgfile, mimetype=mime, resumable=True),
ocrLanguage='ja',
).execute()
downloader = MediaIoBaseDownload(
io.FileIO(txtfile, 'wb'),
service.files().export_media(fileId=res['id'], mimeType="text/plain")
)
done = False
while done is False:
status, done = downloader.next_chunk()
service.files().delete(fileId=res['id']).execute()
print("----- OCR Done. -----")
f = open(txtfile, 'r')
line = f.readline()
while line:
print(line.strip())
line = f.readline()
f.close()
OCR結果
PDFeerさんの請求書サンプルをOCRしてみます。
output.txtというファイルにOCR結果を保存して、それを表示しています。
$ python3 ocr_img.py sample.pdf
----- OCR Done. -----
御請求書
山田サンプル株式会社 御中
発行日 : 2013年12月31日 請求書番号 : 12345678
サンプルテスト株式会社
平素は格別のご高配を賜り、厚く御礼申し上げます。 下記の通りご請求申し上げます。
鈴木一郎 〒123-4567 東京都品川区1-1-1 御請求金額 ¥ 210,000
アパートメント1F TEL 090-123-4567 FAX 090-123-4568
項 目 数 量 単 価 金 額
デザイン費用 5 10,000 50,000
コーディング費用 10 5,000 50,000
プロデュース費用 1 100,000 100,000
小計 200,000
消費税 10,000
合計金額 210,000
備考振込先 : サンプル銀行 サンプル支店 普通 123456789 振込先 : サンプル銀行 サンプル支店 普通 123456780 振込先 : サンプル銀行 サンプル支店 普通 123456781
いつもお世話になっております。
鈴木
無事OCRできました。
2.OCR結果を固有表現抽出APIに投げてみる
日付や会社名など重要そうなところをファイル名にしたいので、まずはOCR結果を一行ずつ固有表現抽出APIに投げて、固有名詞として認識されたものをカテゴリとともに表示します。
コードはこちら(クリックで展開する)
(COTOHA APIに登録して、CLIENT IDとシークレットを書き換える必要があります。)
from __future__ import print_function
import httplib2
import os
import io
import requests
import json
import sys
from apiclient import discovery
from oauth2client import client
from oauth2client import tools
from oauth2client.file import Storage
from apiclient.http import MediaFileUpload, MediaIoBaseDownload
# If modifying these scopes, delete your previously saved credentials
# at ~/.credentials/drive-python-quickstart.json
SCOPES = 'https://www.googleapis.com/auth/drive'
CLIENT_SECRET_FILE = 'credentials.json'
APPLICATION_NAME = 'Drive API Python Quickstart'
BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/"
CLIENT_ID = "COTOHA APIクライアントID"
CLIENT_SECRET = "COTOHA APIクライアントSecret"
def auth(client_id, client_secret):
token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
headers = {
"Content-Type": "application/json",
"charset": "UTF-8"
}
data = {
"grantType": "client_credentials",
"clientId": client_id,
"clientSecret": client_secret
}
r = requests.post(token_url,
headers=headers,
data=json.dumps(data))
return r.json()["access_token"]
def ne(sentence, access_token):
base_url = BASE_URL
headers = {
"Content-Type": "application/json",
"charset": "UTF-8",
"Authorization": "Bearer {}".format(access_token)
}
data = {
"sentence": sentence,
}
r = requests.post(base_url + "v1/ne",
headers=headers,
data=json.dumps(data))
return r.json()
def get_credentials():
"""Gets valid user credentials from storage.
If nothing has been stored, or if the stored credentials are invalid,
the OAuth2 flow is completed to obtain the new credentials.
Returns:
Credentials, the obtained credential.
"""
credential_path = os.path.join("./", 'drive-python-quickstart.json')
store = Storage(credential_path)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = APPLICATION_NAME
credentials = tools.run_flow(flow, store)
print('Storing credentials to ' + credential_path)
return credentials
if __name__ == '__main__':
credentials = get_credentials()
http = credentials.authorize(httplib2.Http())
service = discovery.build('drive', 'v3', http=http)
imgfile = 'sample.pdf' # Image with texts (png, jpg, bmp, gif, pdf)
txtfile = 'output.txt' # Text file outputted by OCR
args = sys.argv
if len(args) >= 2:
imgfile = str(args[1])
mime = 'application/vnd.google-apps.document'
res = service.files().create(
body={
'name': imgfile,
'mimeType': mime
},
media_body=MediaFileUpload(imgfile, mimetype=mime, resumable=True),
ocrLanguage='ja',
).execute()
downloader = MediaIoBaseDownload(
io.FileIO(txtfile, 'wb'),
service.files().export_media(fileId=res['id'], mimeType="text/plain")
)
done = False
while done is False:
status, done = downloader.next_chunk()
service.files().delete(fileId=res['id']).execute()
print("----- OCR Done. -----")
access_token = auth(CLIENT_ID, CLIENT_SECRET)
f = open(txtfile, 'r')
line = f.readline()
while line:
ne_document = ne(line.strip(),access_token)
for chunks in ne_document['result']:
if chunks['form'] is not None:
print(chunks['class'] + ':' + chunks['form'])
line = f.readline()
f.close()
固有名詞抽出結果
$ python3 ocr_img_cotoha.py sample.pdf
----- OCR Done. -----
ORG:山田サンプル株式会社 御中
DAT:2013年12月31日
ART:発行日
PSN:鈴木一郎
LOC:〒123-4567 東京都
LOC:品川区1-1-1
MNY:¥ 210,000
LOC:アパートメント1f
ART:tel
LOC:090-123-4567
NUM:
NUM:fax 090-123-4568
NUM:
NUM: 50,000
NUM:
NUM: 50,000
NUM:
NUM: 100,000
NUM: 200,000
ART:消費税
ART:普通 123456789
ART:普通 123456780
ART:普通
PSN:鈴木
日付はDAT、会社名はORG、人名はPSNで認識されているようなので、
その辺りを使いたいと思います。
3.ファイル名を生成してみる
上記のコードを少し変えて、
日付、会社名、人名として出てきたものを結合してファイル名を生成します。
それを標準出力に吐くようにします。
コードはこちら(クリックで展開する)
(COTOHA APIに登録して、CLIENT IDとシークレットを書き換える必要があります。)
from __future__ import print_function
import httplib2
import os
import io
import requests
import json
import sys
import re
from apiclient import discovery
from oauth2client import client
from oauth2client import tools
from oauth2client.file import Storage
from apiclient.http import MediaFileUpload, MediaIoBaseDownload
from collections import defaultdict
# If modifying these scopes, delete your previously saved credentials
# at ~/.credentials/drive-python-quickstart.json
SCOPES = 'https://www.googleapis.com/auth/drive'
CLIENT_SECRET_FILE = 'credentials.json'
APPLICATION_NAME = 'Drive API Python Quickstart'
BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/"
CLIENT_ID = "COTOHA APIクライアントID"
CLIENT_SECRET = "COTOHA APIシークレット"
def auth(client_id, client_secret):
token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
headers = {
"Content-Type": "application/json",
"charset": "UTF-8"
}
data = {
"grantType": "client_credentials",
"clientId": client_id,
"clientSecret": client_secret
}
r = requests.post(token_url,
headers=headers,
data=json.dumps(data))
return r.json()["access_token"]
def ne(sentence, access_token):
base_url = BASE_URL
headers = {
"Content-Type": "application/json",
"charset": "UTF-8",
"Authorization": "Bearer {}".format(access_token)
}
data = {
"sentence": sentence,
}
r = requests.post(base_url + "v1/ne",
headers=headers,
data=json.dumps(data))
return r.json()
def get_credentials():
"""Gets valid user credentials from storage.
If nothing has been stored, or if the stored credentials are invalid,
the OAuth2 flow is completed to obtain the new credentials.
Returns:
Credentials, the obtained credential.
"""
credential_path = os.path.join("./", 'drive-python-quickstart.json')
store = Storage(credential_path)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = APPLICATION_NAME
credentials = tools.run_flow(flow, store)
print('Storing credentials to ' + credential_path)
return credentials
if __name__ == '__main__':
credentials = get_credentials()
http = credentials.authorize(httplib2.Http())
service = discovery.build('drive', 'v3', http=http)
imgfile = 'sample.pdf' # Image with texts (png, jpg, bmp, gif, pdf)
txtfile = 'output.txt' # Text file outputted by OCR
args = sys.argv
if len(args) >= 2:
imgfile = str(args[1])
mime = 'application/vnd.google-apps.document'
res = service.files().create(
body={
'name': imgfile,
'mimeType': mime
},
media_body=MediaFileUpload(imgfile, mimetype=mime, resumable=True),
ocrLanguage='ja',
).execute()
downloader = MediaIoBaseDownload(
io.FileIO(txtfile, 'wb'),
service.files().export_media(fileId=res['id'], mimeType="text/plain")
)
done = False
while done is False:
status, done = downloader.next_chunk()
service.files().delete(fileId=res['id']).execute()
access_token = auth(CLIENT_ID, CLIENT_SECRET)
f = open(txtfile, 'r')
line = f.readline()
result_d = defaultdict(list)
while line:
ne_document = ne(line.strip(),access_token)
for chunks in ne_document['result']:
if chunks['form'] is not None:
if chunks['class'] == 'ORG' or chunks['class'] == 'DAT' \
or chunks['class'] == 'PSN':
result_d[chunks['class']].append(chunks['form'])
line = f.readline()
f.close()
dirname = os.path.dirname(imgfile)
fn,ext = os.path.splitext(imgfile)
filename_tmp = '_'.join(result_d['DAT']) + '_' + '_'.join(result_d['ORG']) + '_' + '_'.join(result_d['PSN'])
filenewname = re.sub(r'[\\|/|:|?|.|"|<|>|\|]', '-', filename_tmp) + ext
print(filenewname)
ファイル名生成結果
$ python3 ocr_img_cotoha_filename.py sample.pdf
2013年12月31日_山田サンプル株式会社 御中_鈴木一郎_鈴木.pdf
いい感じにファイル名が生成できました。
4.上記スクリプトを利用してリネームする
一個ずつファイルリネームしてもいいんですが、面倒なのでディレクトリを指定しファイル名を読み取って上記のコードを実行するようなbashを書きます。
$ find [ディレクトリ名] -type f | while read -r f; do cp "$f" "$(dirname $f)/$(python3 ocr_img_cotoha_filename.py $f)" ;done
(一応cpコマンドで元ファイルも残してます。)
これで冒頭の画像のようにファイルを一括リネームすることができます。
まとめ
Google DriveのAPIでOCR、その結果をCOTOHA APIで言語処理してファイルをリネームするという、単純だけど面倒な作業を自動で行うツールを作りました。
毎日のように紙をスキャンしている部署などであれば、使い所はそこそこ有るような気もします。
「AIってやつでなんとかできないのか」とか言われたときにうってつけ
一方で、いくつか課題はあります。
- そもそも実業務で使えるレベルなのか検証できてない
- フォーマットのバリエーションを試せてない
- 手書き文字とか多言語とか入ってきた時にちゃんと認識できるかどうか未検証
- Google Driveにアップロードするのは実務だとセキュリティ的に難しそう。なにか別のOCRプロダクト使うか、G suite使えるならこのままでもいけるかも?
- Cloud Vision API使う手はあるけど、GCP登録必要でpdfをGCSにあげたりする必要もあり万人向けでは無さそう。今回は割愛
- OCR失敗する時のハンドリングしてない
- Google DriveのOCRはたまに超文字化けする(言語の認識ミス?)。そこを検知する仕組みは入れたい
- ファイル名が長すぎる場合のハンドリングしてない
- もう少しチューニングしてファイル名に入れるべき文言を選択すれば解決できそう
こんな感じで色々と未検証なので実際に利用される方がもしいましたらご注意ください。
特にセキュリティ周りなどは一切責任を負えませんので……。
とはいえ、社内システムと連携したり、スキャナに組み込んだり、サービス化したりと、うまくやればOCR×言語処理でまだまだ面白いことができる可能性はありそうだと感じました。