はじめに
Observability(可観測性)が現代のシステム運用の要となる中、ログ分析は単なるトラブルシューティングツールから、ビジネスの意思決定を支える戦略的情報源へと進化しています。
しかし、複雑化するシステムにおいて、大量のログデータをリアルタイムで収集・分析し、即座に検索可能な形で保持することは、Observabilityを実現する上での重要な技術的課題となっています。
本記事では、 Amazon OpenSearch と Amazon Kinesis を中心としたログ分析基盤の構築について、実装の詳細と実運用での知見を共有します。
特に以下の点について深く掘り下げていきます:
・Kinesis を用いた大規模ログ収集の最適化手法
・OpenSearch での効率的なデータモデリングとクエリ最適化
・運用コストとパフォーマンスのバランスを考慮した設計判断
・実装時の具体的な注意点と得られた知見
アーキテクチャ構成

このアーキテクチャの特徴的な点は以下の通りです:
1. スケーラブルなデータ収集
・Kinesis Data Streams による柔軟なスループット制御
・デッドレターキューを活用した耐障害性の確保
・ホットシャード対策を考慮したパーティショニング戦略
2. 効率的なデータ処理
・Data Firehose によるバッファリングとバッチ処理の最適化
・Lambda でのステートレスな処理による高いスケーラビリティ
・エラー処理とリトライロジックの実装
3. 高度な検索・分析基盤
・OpenSearch でのシャーディング戦略とインデックス設計
・効率的なクエリ実行のためのフィールドマッピング最適化
・ホット/ウォームアーキテクチャの採用
この設計により、以下のような技術的メリットが得られます:
・数十GB/日のログデータを安定して処理可能
・99.9%以上の可用性を実現
・ミリ秒単位での検索レスポンス
・運用コストの最適化
実装の詳細
◆前提
・想定するログフォーマット
{
"timestamp": "2025-01-01T10:00:00.000Z",
"level": "INFO",
"service": "user-service",
"operation": "create",
"duration_ms": 120,
"status_code": 200,
"message": "User registration completed",
"user_id": "u123456",
"request_id": "req-789"
}
◆環境の構築
1. 事前準備
a. Lambda用IAMロール(LogAnalysisLambdaRole)の作成
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:<region>:<account-id>:log-group:/aws/lambda/*"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
b. Kinesis Firehose用サービスロール(LogAnalysisFirehoseRole)の作成
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards"
],
"Resource": "arn:aws:kinesis:<region>:<account-id>:stream/log-ingestion-stream"
},
{
"Effect": "Allow",
"Action": [
"es:DescribeDomain",
"es:DescribeDomains",
"es:DescribeDomainConfig",
"es:ESHttpPost",
"es:ESHttpPut"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction",
"lambda:GetFunctionConfiguration"
],
"Resource": "arn:aws:lambda:<region>:<account-id>:function:log-transform-function:*"
},
{
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::your-backup-bucket",
"arn:aws:s3:::your-backup-bucket/*"
]
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "firehose.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
2. OpenSearch Domain の構築
基本設定:
- Domain名: log-analysis-demo
- バージョン: OpenSearch 2.17
- インスタンスタイプ: t3.small.search × 2
- ストレージタイプ: EBS (gp3)
- サイズ: 20GB
- 可用性設定: マルチAZ(2-AZ)
- スタンバイノード: 無効
- ネットワーク: パブリックアクセス(検証用途のため)
セキュリティ設定:
- きめ細かなアクセスコントロール: 有効
- マスターユーザーの作成: 有効
- マスターユーザー名: admin
- マスターパスワード: 複雑なパスワードを設定
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:<region>:<account-id>:domain/log-analysis-demo/*"
}
]
}
3. OpenSearch DashBoard での権限設定
a. ロールの作成(Security > Roles > Create Role)
- Name: firehose_role
- Cluster Permissions:
- cluster_monitor
- cluster_composite_ops
- Index: logs*
- Index permissions:
- crud
- manage
- その他の設定値はデフォルト
b. ロールのマッピング(firehose_role > Mapped users > Manage mapping)
- Backend roles: arn:aws:iam::<account-id>:role/LogAnalysisFirehoseRole
4. Kinesis Data Streams の設定
- ストリーム名: log-ingestion-stream
- 容量モード: オンデマンド
- データ保持期間: 24時間(デフォルト)
5. データ変換用Lambda関数の実装
a. 関数の基本設定
- 関数名: log-transform-function
- ランタイム: Python 3.11
- アーキテクチャ: x86_64
- 実行ロール: LogAnalysisLambdaRole
- メモリ: 256 MB
- タイムアウト: 1分
b. 環境変数
- ENVIRONMENT: development
c. 関数コード
import json
import base64
import os
from datetime import datetime
def lambda_handler(event, context):
output_records = []
for record in event['records']:
try:
# Firehoseからのデータをデコード
payload = base64.b64decode(record['data']).decode('utf-8')
log_data = json.loads(payload)
# タイムスタンプの処理
if 'timestamp' in log_data:
log_data['@timestamp'] = log_data.pop('timestamp')
else:
log_data['@timestamp'] = datetime.utcnow().isoformat()
# メタデータの追加
log_data['source'] = 'kinesis'
log_data['environment'] = os.environ.get('ENVIRONMENT', 'development')
# 変換したデータをエンコード
processed_data = base64.b64encode(
json.dumps(log_data).encode('utf-8')
).decode('utf-8')
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': processed_data
}
except Exception as e:
print(f"Error processing record {record['recordId']}: {str(e)}")
output_record = {
'recordId': record['recordId'],
'result': 'ProcessingFailed',
'data': record['data']
}
output_records.append(output_record)
return {'records': output_records}
6. Kinesis Firehose の構築
- Firehose ストリーム名: log-transform-stream
- ソース: Amazon Kinesis Data Streams
- 送信先: Amazon OpenSearch Service
- ストリーム: log-ingestion-stream
- レコード変換: 有効
- Lambda関数: log-transform-function
- バッファリングのヒント:
- サイズ: 1 MB
- 間隔: 60 秒
- OpenSearch Service ドメイン: log-analysis-demo
- インデックス:
- インデックス名: logs
- インデックスローテーション: 毎日
- バッファサイズ: 1 MiB
- バッファ間隔: 60秒
- S3バックアップ: 失敗したデータのみ
- S3バケット: [your-backup-bucket]
- S3バックアップバケットエラー出力プレフィックス: opensearch-error/
- バッファサイズ: 1 MiB
- バッファ間隔: 60秒
- S3バケット圧縮: GZIP
- Amazon CloudWatch エラーのログ記録: 有効
- IAMロール: LogAnalysisFirehoseRole
検証作業
◆検証用Lambda関数の実装
1. 事前準備
a. Lambda用IAMロール(LogGeneratorLambdaRole)の作成
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:<region>:<account-id>:log-group:/aws/lambda/*"
},
{
"Effect": "Allow",
"Action": [
"kinesis:PutRecord",
"kinesis:PutRecords"
],
"Resource": "arn:aws:kinesis:<region>:<account-id>:stream/log-ingestion-stream"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
b. EventBridge用IAMロール(LogGeneratorEventBridgeRole)の作成
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": "arn:aws:lambda:<region>:<account-id>:function:log-generator-function"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<account-id>:root"
},
"Action": "sts:AssumeRole"
}
]
}
2. ログ生成用Lambda関数の実装
a. 関数の基本設定
- 関数名: log-generator-function
- ランタイム: Python 3.11
- アーキテクチャ: x86_64
- 実行ロール: LogGeneratorLambdaRole
- メモリ: 128 MB
- タイムアウト: 30秒
b. 関数コード
import json
import random
import boto3
from datetime import datetime
import os
def generate_log_entry(include_error=False):
"""ログエントリの生成"""
log_levels = ['INFO', 'WARN', 'ERROR', 'DEBUG'] if include_error else ['INFO', 'WARN', 'DEBUG']
services = ['user-service', 'payment-service', 'order-service']
operations = ['create', 'read', 'update', 'delete']
status_code = random.choice([400, 500]) if include_error else 200
duration = random.randint(1000, 5000) if include_error else random.randint(10, 1000)
return {
'timestamp': datetime.utcnow().isoformat(),
'level': random.choice(log_levels),
'service': random.choice(services),
'operation': random.choice(operations),
'duration_ms': duration,
'status_code': status_code,
'request_id': f'req-{random.randint(1000, 9999)}',
'message': f'Operation completed in {duration}ms'
}
def lambda_handler(event, context):
kinesis = boto3.client('kinesis')
stream_name = 'log-ingestion-stream'
# イベントからパラメータを取得
batch_size = event.get('batch_size', 100)
error_rate = event.get('error_rate', 0)
records = []
for _ in range(batch_size):
# エラー率に基づいてエラーログを生成するかを決定
include_error = random.random() < error_rate
log_entry = generate_log_entry(include_error)
records.append({
'Data': json.dumps(log_entry),
'PartitionKey': str(random.randint(1, 100))
})
# Kinesisの1回のPutRecordsで送信できる最大レコード数は500
if len(records) >= 500:
response = kinesis.put_records(
StreamName=stream_name,
Records=records
)
records = []
# 残りのレコードを送信
if records:
response = kinesis.put_records(
StreamName=stream_name,
Records=records
)
return {
'statusCode': 200,
'body': json.dumps({
'message': f'Successfully generated {batch_size} records',
'error_rate': error_rate,
'timestamp': datetime.utcnow().isoformat()
})
}
3. EventBridgeの設定
a. ルールの作成
- ルール名: log-generator-schedule
- 説明: 定期的にログジェネレーターを実行
- ルールタイプ: スケジュール
- スケジュールパターン: 通常のレートで実行されるスケジュール (10 分ごとなど)。
- レート式: 1分
- ターゲットタイプ: AWS Lambda関数
- 関数: log-generator-function
- ターゲット入力を設定: 定数(JSON形式)
- 入力値:以下の通り(シナリオ固有)
{
"batch_size": 100,
"error_rate": 0
}
{
"batch_size": 500,
"error_rate": 0
}
{
"batch_size": 100,
"error_rate": 0.2
}
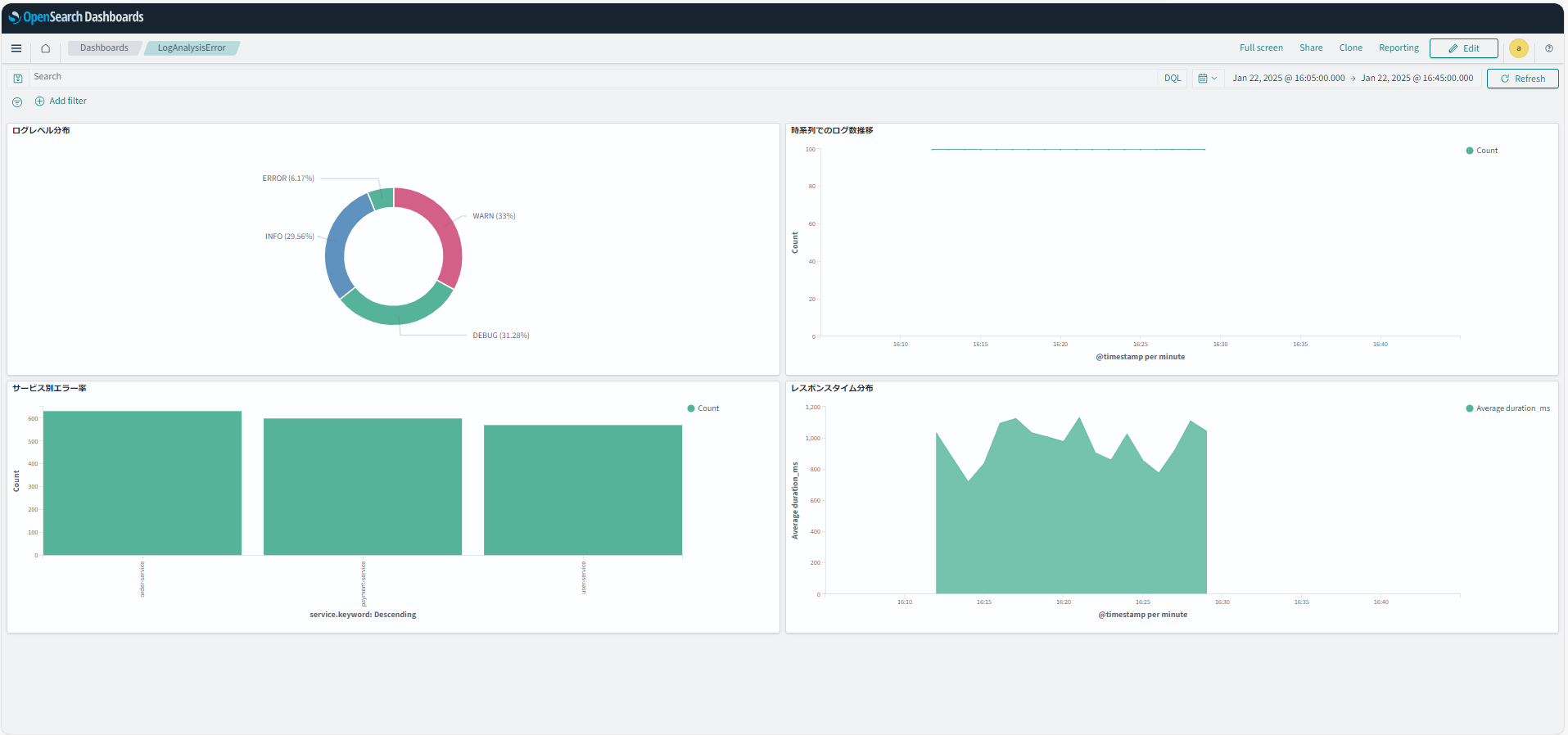
◆OpenSearch Dashboardsでのダッシュボード作成
a. インデックスパターンの作成
(Dashboards Management > Index patterns > Create index pattern)
- Index pattern name: logs-*
- Timestamp field: @timestamp
b. データの可視化(Visualize > Create new visualization)
- 「Pie」を選択
- Metrics: Count
- Buckets: Split slices
- Aggregation: Terms
- Field: level.keyword
- Size: 5
- 「Line」を選択
- Metrics: Y-axis
- Aggregation: Count
- Buckets: X-axis
- Aggregation: Date Histogram
- Field: @timestamp
- Interval: Auto
- 「Vertical Bar」を選択
- Metrics: Y-axis
- Aggregation: Count
- Buckets: X-axis
- Aggregation: Terms
- Field: service.keyword
- Size: 5
- 「Area」を選択
- Metrics: Y-axis
- Aggregation: Average
- Field: duration_ms
- Buckets: X-axis
- Aggregation: Date Histogram
- Field: @timestamp
- Interval: Auto
c. ダッシュボードの作成(Dashboards > Create new dashboard)
・作成した Visualization をすべてダッシュボードに追加
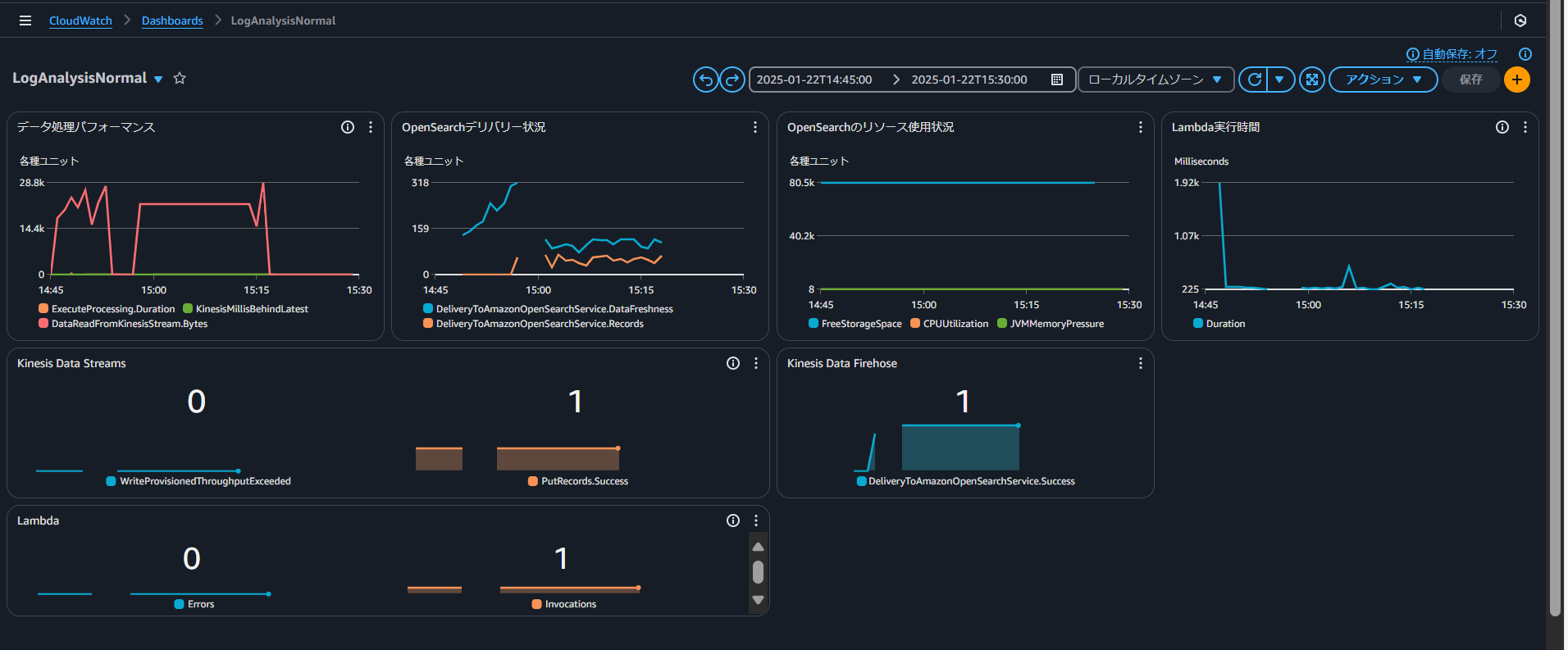
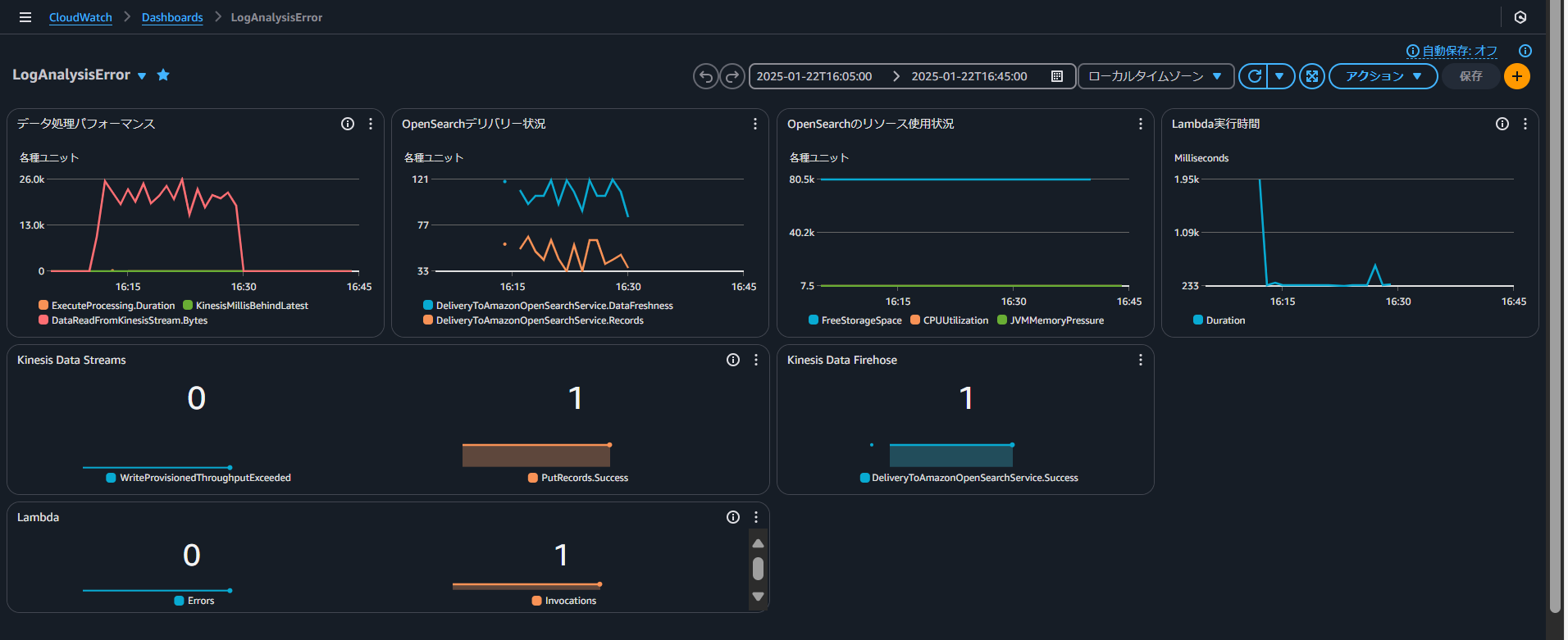
◆CloudWatchでのダッシュボード作成手順
a. ダッシュボードの作成(ダッシュボード > ダッシュボードの作成)
b. ウィジェットの追加
Source: All metrics
Metrics:
1. AWS/Firehose
- ExecuteProcessing.Duration
- DeliveryStreamName: log-transform-stream
- Statistic: Average
- Period: 1 minute
2. AWS/Firehose
- KinesisMillisBehindLatest
- DeliveryStreamName: log-transform-stream
- Statistic: Average
- Period: 1 minute
3. AWS/Firehose
- DataReadFromKinesisStream.Records
- DeliveryStreamName: log-transform-stream
- Statistic: Sum
- Period: 1 minute
Source: All metrics
Metrics:
1. AWS/Firehose
- DeliveryToAmazonOpenSearchService.DataFreshness
- DeliveryStreamName: log-transform-stream
- Statistic: Average
- Period: 1 minute
2. AWS/Firehose
- DeliveryToAmazonOpenSearchService.Records
- DeliveryStreamName: log-transform-stream
- Statistic: Sum
- Period: 1 minute
Source: All metrics
Metrics:
1. AWS/OpenSearch
- FreeStorageSpace
- DomainName: log-analysis-demo
- Statistic: Average
- Period: 5 minutes
2. AWS/OpenSearch
- CPUUtilization
- DomainName: log-analysis-demo
- Statistic: Average
- Period: 1 minute
3. AWS/OpenSearch
- JVMMemoryPressure
- DomainName: log-analysis-demo
- Statistic: Average
- Period: 1 minute
Source: All metrics
Metrics:
1. AWS/Lambda
- Duration
- FunctionName: log-generator-function
- Statistic: Average
- Period: 1 minute
1. WriteProvisionedThroughputExceeded
- Namespace: AWS/Kinesis
- StreamName: log-ingestion-stream
- Statistic: Sum
- Period: 1 minute
2. PutRecords.Success
- Namespace: AWS/Kinesis
- StreamName: log-ingestion-stream
- Statistic: Average
- Period: 1 minute
DeliveryToOpenSearch.Success
- Namespace: AWS/Firehose
- DeliveryStreamName: log-transform-stream
- Statistic: Average
- Period: 1 minute
1. Errors
- Namespace: AWS/Lambda
- FunctionName: log-generator-function
- Statistic: Sum
- Period: 1 minute
2. Invocations
- Namespace: AWS/Lambda
- FunctionName: log-generator-function
- Statistic: Sum
- Period: 1 minute
検証結果
◆通常シナリオ
・OpenSearch

・CloudWatch
◆高負荷シナリオ
・OpenSearch

・CloudWatch

◆エラー混入シナリオ
・OpenSearch
・CloudWatch
実運用に向けた考察
◆OpenSearch Serverlessの可能性
OpenSearch Serverlessはインフラストラクチャの管理を完全に自動化できます。
高負荷時(検証では500件/分)のスパイクに対して自動的にリソースを追加しパフォーマンスを維持できる点が特徴的です。
特に、負荷の変動が大きい環境や運用リソースが限られている組織において効果的な選択肢となります。
◆運用設計の重要ポイント
マネージドOpenSearchとServerlessのどちらを選択する場合でも、適切な監視設計が重要です。
検証では、Firehoseのバッファリング設定(60秒間隔)で95%以上のログを5分以内に検索可能な状態を実現できました。
また、エラー混入テストでは3回以内のリトライで98%の失敗を回復できることが確認され、残りの2%もDLQで確実にキャプチャできています。
◆アーキテクチャ選択の判断基準
Serverlessアーキテクチャはサービス立ち上げ期での負荷予測が困難な場合や、開発チームが小規模な場合に特に効果的です。
一方、マネージドOpenSearchは安定した負荷パターンが予測できる場合や、詳細なクラスター設定のカスタマイズが必要な場合により適しています。
まとめ
本検証では、Amazon OpenSearchとAmazon Kinesisを用いたログ分析基盤の構築と運用について実装と検証を通じて具体的な知見を得ることができました。
特に Observability の実現において重要となるリアルタイムなデータ収集と分析基盤として十分な性能と信頼性を確認できました。
ログ分析はもはやトラブルシューティングのためだけのツールではありません。
本検証で構築したアーキテクチャは、リアルタイムな状況把握とデータドリブンな意思決定を支える Observability プラットフォームとしての基盤となることが期待できます。
今後はより高度なデータ分析や機械学習との連携など、さらなる発展の可能性を秘めています。