1. はじめに
Speech To TextはIBM Bluemixから提供されている音声認識APIです。
このAPIを使用することで、音声から文字を書き起こすことができます。
今回は、Speech To TextとNode.jsを使用して、簡単な音声認識システムの開発を行います。
2. 準備
開発の前に、以下のものを準備してください。
- Bluemixのアカウント
Speech To Textを利用するには、Bluemixのアカウントが必要になります。
アカウント作成は、以下のリンク先で行います。
Bluemix ログインページ
https://console.bluemix.net/
- Node.js開発環境
公式サイトからNode.jsをダウンロード・インストールしてください。
Node.js 公式サイト
https://nodejs.org/en/
- 音声ファイル
音声認識に使用する音声ファイルを準備してください。
今回は、wav形式の音声ファイルを使用します。
3. 開発
3-1. Speech To Textサービス追加
Speech To Textサービス利用するため、Bluemix上でサービスを追加します。
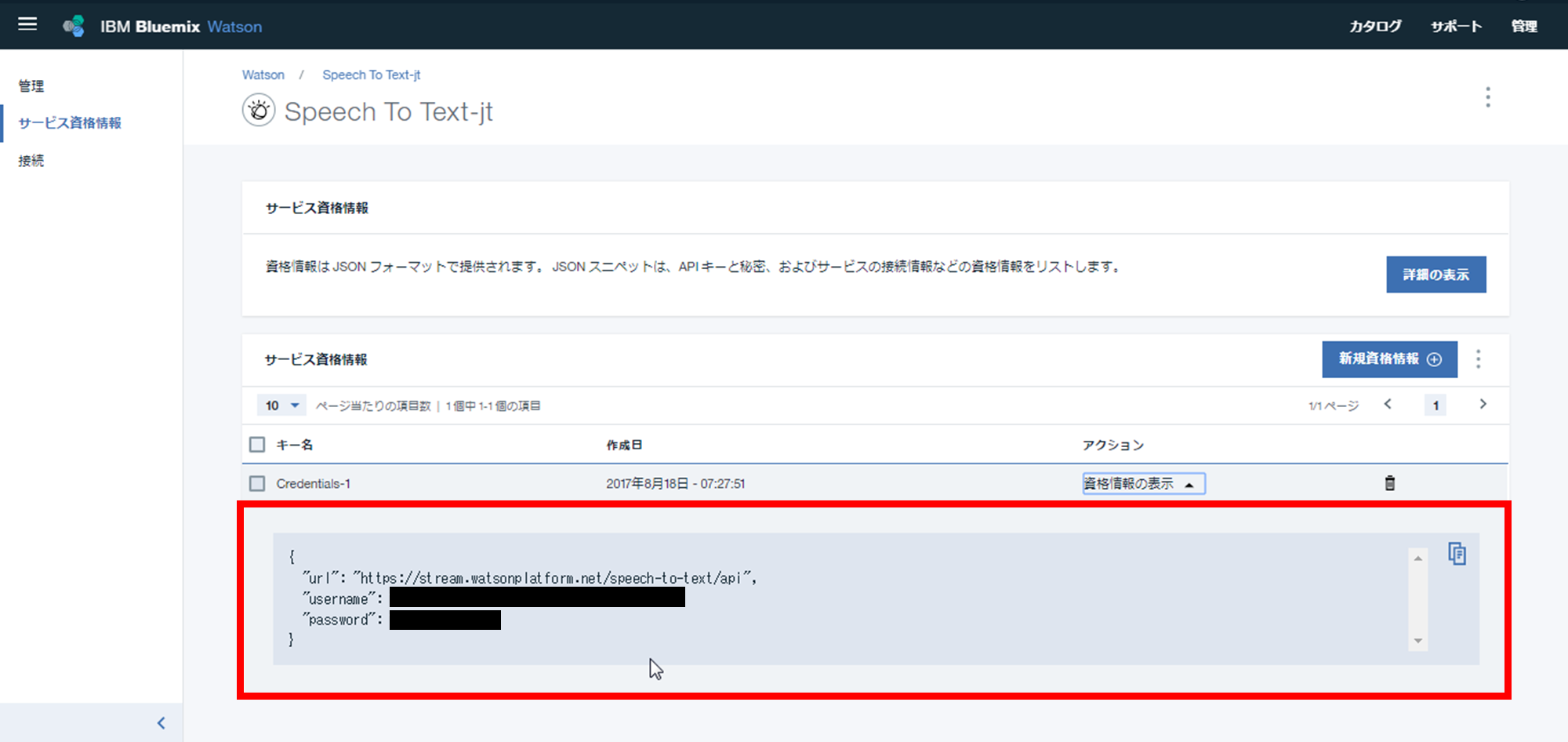
また、後ほど"username"と"password"の資格情報が必要になりますので、それらの情報を確認します。
手順は以下の通りです。
① カタログでSpeech To Textを検索し、サービスを作成する
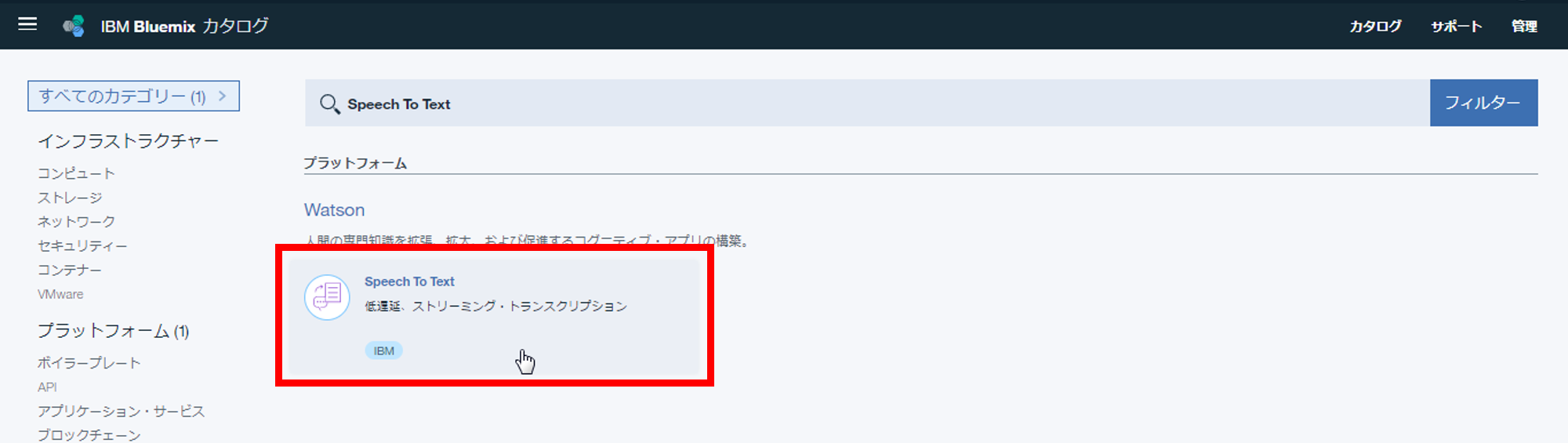
② ダッシュボードのサービス欄にて、Speech To Textをクリックし、サービスの詳細画面を開く
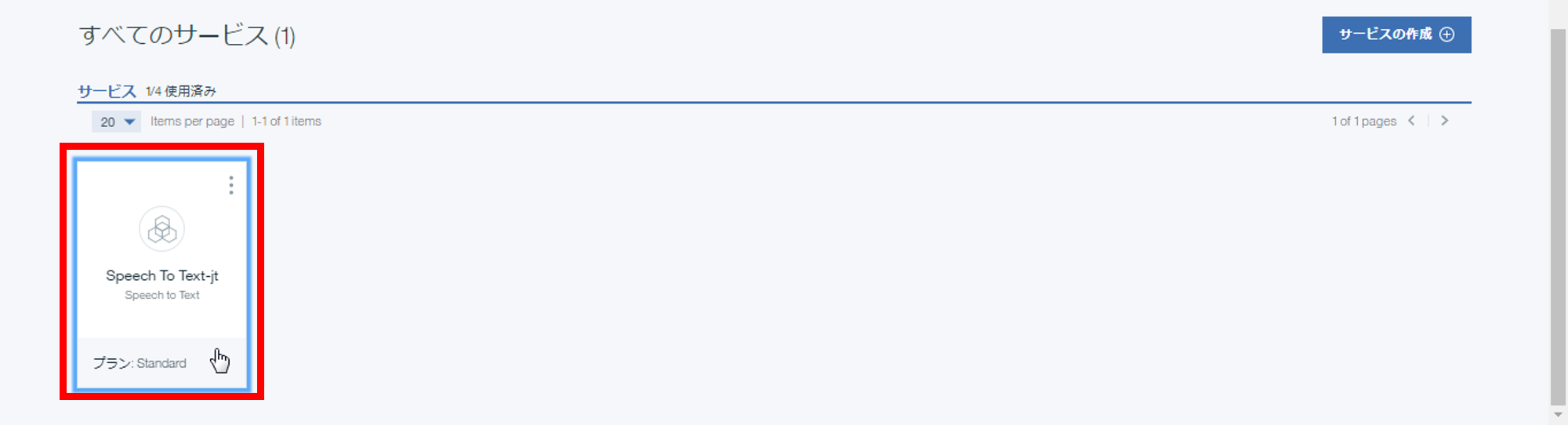
③ サービス資格情報を開き、"username"と"password"を確認する
3-2. Node.jsによるコーディング
Speech To Textを使用して、簡単な音声認識ツールを作成します。
このツールでは、音声ファイルを読み込み、認識結果をコンソールに表示するようにします。
・開発用ディレクトリの作成
開発用のディレクトリを作成します。
以下の作業は、主にこのディレクトリ配下で行います。
・npmパッケージ導入
必要なnpmパッケージをインストールします。
今回は、以下の2つのパッケージを使用します。
| パッケージ | 説明 |
|---|---|
| watson-developer-cloud | Watson Developer Cloudサービスが使用できる |
| fs | ファイルの読み書きや操作ができる |
以下のコマンドでパッケージをインストールします。
> npm install パッケージ
インストールしたモジュールを使用するには、require()でモジュールを読み込みます。
var fs = require('fs');
const watson = require('watson-developer-cloud');
・認証
Speech To Textを使用するには、サービス資格情報に提供されているユーザー名とパスワードを入力して認証を行います。
ここでは、先程サービスの作成にて確認した、ユーザー名とパスワードを指定します。
※Bluemixアカウントのユーザー名とパスワードとは異なります。
var SpeechToTextV1 = require('watson-developer-cloud/speech-to-text/v1');
var speech_to_text = new SpeechToTextV1({
username: 'ユーザー名',
password: 'パスワード'
});
・パラメータ設定
パラメーターを設定します。
今回は、以下の3つの項目を設定します。
| 設定パラメータ | 説明 |
|---|---|
| model | 音声認識に使用されるモデル 英語(US)のブロード・バンドモデル(en-US_BroadbandModel)がデフォルト. 日本語のモデルは、ja-JP_BroadbandModel と ja-JP_NarrowbandModelが使用可能. 【使用可能な言語】 英語 (US)、英語 (UK)、日本語、アラビア語 (MSA、ブロードバンド・モデルのみ)、北京語、ポルトガル語 (ブラジル)、スペイン語、フランス語 (ブロードバンド・モデルのみ) |
| audio | 音声ファイル |
| content_type | 音声データのMIMEタイプ 以下のタイプが使用可能. ・audio/flac ・audio/mp3 ・audio/mpeg ・audio/l16 ・audio/wav ・audio/ogg ・audio/ogg;codecs=opus ・audio/ogg;codecs=vorbis ・audio/webm ・audio/webm;codecs=opus ・audio/webm;codecs=vorbis ・audio/mulawv ・audio/basic |
上記以外にも、パラメータが存在します。
パラメータについて、詳細はSpeech To TextのAPIリファレンスをご参照ください。
Speech To Text APIリファレンス
https://www.ibm.com/watson/developercloud/speech-to-text/api/v1/
ソースコード上では 以下のようにしてパラメータの設定をします。
var params = {
model: '音声認識モデル',
audio: fs.createReadStream('音声ファイル名'),
content_type: '音声ファイルのタイプ',
};
・音声認識
設定したパラメータを用いて、音声認識を実行します。
今回、音声認識結果は、コンソール上に表示されるようにしています。
speech_to_text.recognize(params, function (error, transcript) {
if (error)
console.log('Error:', error);
else
console.log(JSON.stringify(transcript, null, 2));
});
ソースコード例
作成したコード(test.js)が以下の通りになります。
var fs = require('fs');
const watson = require('watson-developer-cloud');
var SpeechToTextV1 = require('watson-developer-cloud/speech-to-text/v1');
var speech_to_text = new SpeechToTextV1({
username: 'ユーザー名',
password: 'パスワード'
});
var params = {
model: 'ja-JP_BroadbandModel', // 日本語-ブロードバンドを使用
audio: fs.createReadStream('./wav/sample.wav'), // 音声ファイル./wav/sample.wavを音声認識する
content_type: 'audio/wav' //wavファイルを使用
};
speech_to_text.recognize(params, function (error, transcript) {
if (error)
console.log('Error:', error);
else
console.log(JSON.stringify(transcript, null, 2));
});
4. 実行
コンソール画面から、test.jsを実行します。
test.jsのあるディレクトリに移動し、以下のコマンドを実行してください。
> node test.js
しばらく待つと、コンソール画面に音声認識結果が表示されます。
{
"results": [
{
"alternatives": [
{
"confidence": 0.461,
“transcript”: “こんにちは 今日 は 良い天気 です ね "
}
],
"final": true
}
],
"result_index": 0
}
"transcript"に読み込ませた音声から書き起こしたスクリプトが表示されます。
また、"confidence"には"transcript"の信頼度が0~1の間の数値で示されます。
参考
Speech to Text Demo
https://speech-to-text-demo.mybluemix.net/
Speech To Text APIリファレンス
https://www.ibm.com/watson/developercloud/speech-to-text/api/v1/