1. はじめに
形態素解析とは、テキストを形態素の単位(=意味の最小単位)に分割することを指します。
データ解析専用のオープンソース・フリーソフトウェアのR言語においては、
ライブラリー RMeCabを使用することによって、形態素解析を行うことができます。
今回は、RMeCab を使用して、簡単な形態素解析を実行してみます。
※ Mac PCで実行します。
2. 準備
2-1. RStudio インストール
R言語を使用するために、RStudioをインストールします。
インストールイメージは、以下のリンク先からダウンロードできます。
R Studio
https://www.rstudio.com/products/rstudio/download/
2-2. MeCab 準備
オープンソースの形態素解析エンジン MeCabと MeCab 用の辞書 をインストールします。
① MeCabインストール
MacではHomebrewを使用することでインストールすることができます。
※ Homebrewがない場合は、以下リンク先を参考にインストールします。
https://brew.sh/index_ja.html
以下をターミナルで実行し、MeCabをインストールします。
brew install mecab
② 辞書インストール
辞書についてもHomebrewを使用してインストールします。
以下をターミナルで実行し、辞書をインストールします。
brew install mecab-ipadic
2-3. RMeCabインストール
MeCabをRで使うため、ライブラリーRMeCabをインストールします。
以下を RStudioのコンソール上で実行し、
ライブラリーRMeCabをインストールします。
install.packages("RMeCab", repos = "https://rmecab.jp/R", type = "source")
2-4. 動作確認
インストールしたRMeCabが正常に使用できるか、簡単な実行をして確認します。
① ライブラリー読み込み
RMeCabで用意されている関数を実行する前に、
ライブラリーRMeCabを読み込みます。
以下を RStudio コンソール上で実行します。
library(RMeCab)
② RMeCabC関数 実行
RMeCabC関数 を使用して、指定した文字列を形態素解析してみます。
引数に日本語文字列を設定すると、MeCabで解析した結果が返されます。
RMeCabC関数に 日本語文字列 "すもももももももものうち" を引数として設定し、実行します。
> res <- RMeCabC("すもももももももものうち")
> res
[[1]]
名詞
"すもも"
[[2]]
助詞
"も"
[[3]]
名詞
"もも"
[[4]]
助詞
"も"
[[5]]
名詞
"もも"
[[6]]
助詞
"の"
[[7]]
名詞
"うち"
見やすさのため、unlist関数を使用して、結果resはリストからベクトルに変換します。
> unlist(res)
名詞 助詞 名詞 助詞 名詞 助詞 名詞
"すもも" "も" "もも" "も" "もも" "の" "うち"
引数に設定した文字列が分割されて、単語とその品詞が確認できます。
3. 形態素解析 実行
3-1. やりたいこと
前項では短文での形態素解析を実行しましたが、
ここではさらに長いテキストデータを読み込んで、単語の頻出数を確認してみます。
3-2. 実行
① テキストデータ 準備
今回は、以下リンク先の青空文庫のサイトから 作品をダウンロードして、
形態素解析を実施します。
青空文庫
https://www.aozora.gr.jp/
読み込みには Aozora関数 を使用します。
事前に 以下をRStudioコンソールで実行し、Aozora関数 を読み込んでおきます。
source("http://rmecab.jp/R/Aozora.R")
Aozora関数の引数に、
青空文庫サイト内の 読み込みたいテキストファイルのリンクを指定します。
ここでは、以下リンク先のファイルを読み込みます。
・夏目漱石 『吾輩は猫である』
https://www.aozora.gr.jp/cards/000148/files/789_ruby_5639.zip
実行例は以下の通りです。
読み込んだファイルは text に入力します。
> text <- Aozora("https://www.aozora.gr.jp/cards/000148/files/789_ruby_5639.zip")
example: folder_name <- Aozora('http://www.aozora.gr.jp/cards/000081/files/462_ruby_716.zip')
URL 'https://www.aozora.gr.jp/cards/000148/files/789_ruby_5639.zip' を試しています
Content type 'application/zip' length 344964 bytes (336 KB)
==================================================
downloaded 336 KB
② RMeCabFreq関数 実行
RMeCabFreq関数 を使用して、読み込んだテキスト内での各単語の出現頻度を確認します。
RMeCabFreq関数は、引数にファイルを設定すると、
ファイル内のテキストを形態素解析し、活用形は原形に変換した上で、
各単語の頻度がデータフレームで返されます。
※ まだの場合は、事前に RMeCabを読み込んでおきます。
> library(RMeCab)
RMeCabFreq関数に、前工程で テキストを読み込んだ text を引数に指定します。
実行結果はresに入力します。
> res <- RMeCabFreq(text)
file = ./NORUBY/wagahaiwa_nekodearu2.txt
length = 12835
結果を入力した resの中身を確認すると、以下のようになります。
> res
Term Info1 Info2 Freq
1 よ その他 間投 1
2 あ フィラー * 66
3 あの フィラー * 30
4 あー フィラー * 2
5 うんと フィラー * 5
~~~(省略)~~~
RMeCabFreq関数の実行結果として、以下項目が確認できます。
| 列名 | 説明 |
|---|---|
| Term | 形態素 |
| Info1 | 品詞 |
| Info2 | 品詞細分類 |
| Freq | 頻度 |
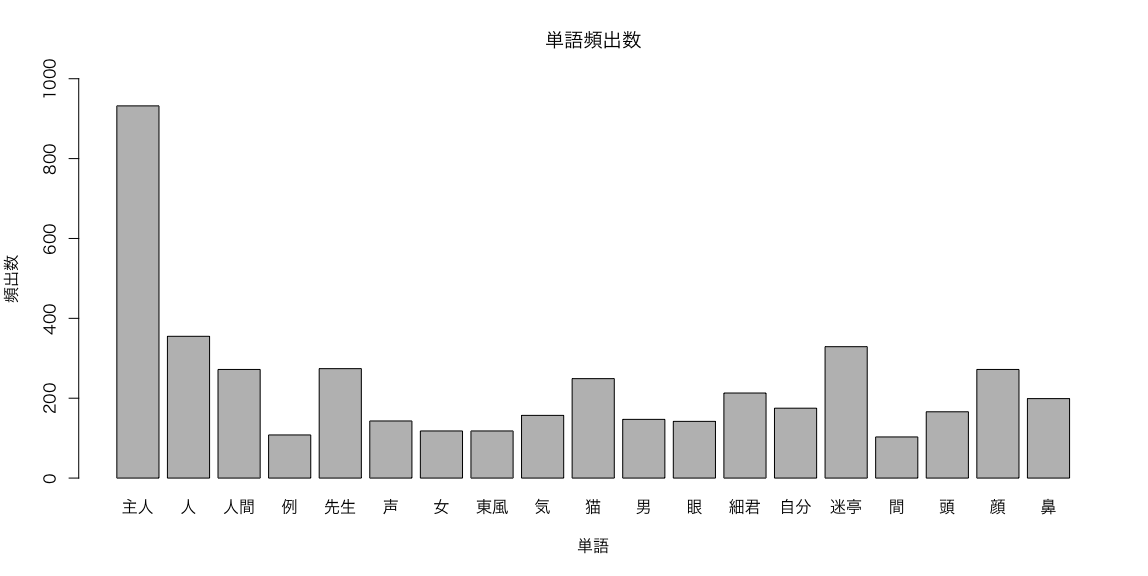
③ グラフ描画
各形態素の頻出数を棒グラフにまとめます。
ここでは、品詞(Info1)が名詞かつ品詞細分類(Info2)が一般であり、頻度(Freq)が100より大きい単語に絞ります。
まず、以下のようにして 単語を絞り込んで、res2に入力します。
> res2 <- res[res[,2]=="名詞" & glove[,3]=="一般" & glove$Freq>100,]
> res2
Term Info1 Info2 Freq
5374 主人 名詞 一般 932
5436 人 名詞 一般 355
5470 人間 名詞 一般 272
5584 例 名詞 一般 108
5691 先生 名詞 一般 274
6341 声 名詞 一般 143
6511 女 名詞 一般 118
7708 東風 名詞 一般 118
7952 気 名詞 一般 157
8343 猫 名詞 一般 249
8439 男 名詞 一般 147
8607 眼 名詞 一般 142
8874 細君 名詞 一般 213
9109 自分 名詞 一般 175
9728 迷亭 名詞 一般 329
9946 間 名詞 一般 103
10113 頭 名詞 一般 166
10130 顔 名詞 一般 272
10304 鼻 名詞 一般 199
barplot関数を使用して、棒グラフを描画します。
引数には、先ほど絞り込んだデータを入力した res2の Freq列 を指定し、
各単語の頻出数を棒グラフに表示させます。
また、barplot関数のオプションとして 以下を設定しています。
| オプション | 説明 | 設定値 |
|---|---|---|
| main | グラフタイトル | "単語頻出数" |
| names.arg | 各要素名 | res2$Term |
| xlab | x軸 ラベル | "単語" |
| ylab | y軸 ラベル | "頻出数" |
| ylim | y軸 表示範囲 | c(0, 1000) |
以下のように barplot関数を実行します。
> barplot(res2$Freq, main = "単語頻出数", names.arg=res2$Term, xlab = "単語", ylab = "頻出数", ylim=c(0, 1000))
実行結果として、以下のような棒グラフが表示されます。
4. おわりに
今回は RMeCabを使用して、簡単な形態素解析を実行してみました。
RMeCabには、RMeCabC関数、RMeCabFreq関数の他にも様々な関数が用意されています。
RMeCabの詳細な使用方法は、マニュアルにて確認することができます。
RMeCab の使い方
http://rmecab.jp/wiki/index.php?plugin=attach&pcmd=open&file=manual.pdf&refer=RMeCab
参考情報
RMeCab の使い方
http://rmecab.jp/wiki/index.php?plugin=attach&pcmd=open&file=manual.pdf&refer=RMeCab
アールメカブ
http://rmecab.jp/wiki/index.php?FrontPage
RMeCabを用いた日本語テキストマイニング
https://www.oreilly.co.jp/pub/9784873118307/appa.html
RMeCab
https://sites.google.com/view/rmecab/
R-Tips
http://cse.naro.affrc.go.jp/takezawa/r-tips/r.html
データ科学便覧
https://data-science.gr.jp/