Difyが面白そうだったので、自身の管理するWordPressサイトにチャットボットを埋め込んでみました。
その際の気付きなどを共有します。
設置したサイトはこちらです。
https://vocaloid.haruinoue.net/
目的・前提
最終的な目的はWordPressサイトに、サイトの内容を元にして回答してくれるチャットボットを埋め込むことです。
Difyにはローカル環境や自身の用意したサーバー上で動かせるOSS版と、ブラウザでアクセスするだけで利用できるクラウド版があります。
今回はサイト内に埋め込む=常時稼働していて外部から接続できるようにしておく必要があるため、クラウド版を利用します。
またOSS版のDifyはすべての機能を無料で利用できますが、クラウド版では無料の範囲には制限があります。
使った分のAPI利用代ぐらいは全然払いますが、ちょっとお試ししてみるのに月59ドル(2024年8月現在のプロフェッショナルプラン)は高いなと感じるので、Difyは無料の範囲で利用します。
メインで使用するOpenAPIと、RAGのRerankに使用するCohereのAPIキーは用意します。無料枠もありますが有料です。
Firecrawlを利用する場合の問題点
DifyでWebサイトの内容をRAGとして利用する場合、一番初めに選択肢に上がるのはFirecrawlを利用する方法です。
Firecrawlは指定したサイトをクロールして、LLMが読みやすいMarkdown形式にしてくれるもので、Difyと簡単に連携できます。
ただこの方法は以下の制約があります。
Firecrawlの無料枠は500ページ分
Firecrawlにも無料枠が用意されています。500ページは無料でクロールしてくれるのですが、私のサイトは投稿記事が260程ありました。
足りないことはないですが、2周はできないのでミスは許されません。
ローカル版はDifyのクラウドと連携できない
FirecrawlにもDifyと同じくOSS版があります。ローカルで動かすのであれば何ページでもクロールできます。
ローカル版Firecrawlとローカル版Difyを繋いでクロールした後でデータをクラウド版に持ってこれないかなと思いましたが無理でした。
Dify無料版は50ページまで
上2つはFirecrawlにAPI代を払えば解決なのですが、この制約が致命的でした。
Firecrawlでクロールした内容は、1ページ1ドキュメントとして扱われます。Firecrawl自体は500ページまで無料なのですが、Difyの無料版は50ドキュメントをまでしか扱えません。
260記事の内50記事しか読み込めないのでは困ります。
なので今回はFirecrawlを使うのは諦めました。
WordPressのエクスポートデータを使う
自身の管理するサイトなら、わざわざ外からクロールしてデータを集めなくても良いですよね。
WordPressには記事の内容をXML形式でエクスポートする機能があります。
ダッシュボードから「ツール>エクスポート」からエクスポートできます。
それをMarkdownに変換すれば、Difyで「ウェブサイトから同期」でなく「テキストファイルからインポート」で読み込めます。
Markdownへの変換
WordPressから出力したXMLファイルをMarkdownに変換するツールはいくつかあります。
今回はwpxml2mdを利用しました。
小ネタ:WordPressの添付ファイルページを無効にする
WordPressでは記事内の添付ファイルごとに「添付ファイルページ(attachment pages)」が作成されていることがあります。
添付ファイルページは内部的には固定ページとして扱われるので、wpxml2mdで変換した際に画像などのファイル名が書かれただけのMarkdownが出力されてしまいます。
添付ファイルページを利用しないのであれば、設定から無効にしてしまえば余計なページが出力されなくて良いです。
ファイルの結合
wpxml2mdで出力されるファイルは、以下のように投稿された年と月別のフォルダに入った日付のファイル名になっていて、1記事1ファイルです。
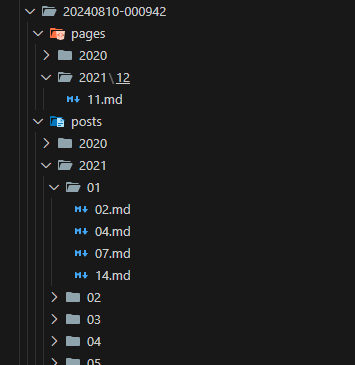
Dify無料版の50ドキュメント制限はFirecrawlだけでなくファイルのアップロード時にも適用されるので、全部のファイルを結合してしまいます。
以下のPythonスクリプトを書きました。これで全てのMarkdownファイルを1つにまとめます。
import os
import shutil
import re
# 定数の定義
INPUT_DIR = './DIR_NAME' #ここにwpxml2mdで出力したMarkdownファイルが入ったフォルダ
OUTPUT_DIR = './FOLDER' #ここに出力先
OUTPUT_FILE_NAME = 'blog' #ここにファイル名
# Markdownファイルを取得する
def get_markdown_files(directory):
markdown_files = []
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith('.md'):
markdown_files.append(os.path.join(root, file))
return markdown_files
# Markdownファイルの内容を整形する
def format_markdown(text):
# HTMLタグを削除
text = re.sub(r'<.*?>', '', text)
# 無駄な改行を削除
text = re.sub(r'\n\s*\n', '\n', text)
# 見出しの前に改行を追加
text = re.sub(r'\n#', '\n\n#', text)
return text
# ファイルを結合して新しいファイルに書き出す
def main():
# 出力ディレクトリ内の既存ファイルを削除
if os.path.exists(OUTPUT_DIR):
shutil.rmtree(OUTPUT_DIR)
os.makedirs(OUTPUT_DIR)
markdown_files = get_markdown_files(INPUT_DIR)
output_file_path = os.path.join(OUTPUT_DIR, f"{OUTPUT_FILE_NAME}.md")
with open(output_file_path, 'w', encoding='utf-8') as outfile:
for fname in markdown_files:
with open(fname, 'r', encoding='utf-8') as infile:
content = infile.read()
clean_content = format_markdown(content)
outfile.write(clean_content)
# ファイル間に改行を追加
outfile.write("\n\n")
if __name__ == "__main__":
main()
ついでで、Markdownの整形も少ししています。
HTMLタグの削除
元のMarkdownにはHTMLタグが残っていたりします。

WordPressサイトから他のブログに引っ越す時には消すと困るかもしれませんが、今回はRAGとして使用するだけなので見栄えを整えるようなHTMLは不要です。
なのでファイルの結合と同時にHTMLタグの削除もしています。
見出しごとに空行
以下のように整形もしています。
元がこうだとして
## こんにちは
今日はこれについて説明します
## おわりに
いかがでしたか?
こうします。
## こんにちは
今日はこれについて説明します
## おわりに
いかがでしたか?
1行ずつに空行が入っていたのを、見出しと本文はくっつけ、見出しの前は1行空けます。
なぜこの整形をしたいかというと、Difyに読み込んだときのためです。
テキストをアップロードした後、チャンク(データをどこで区切るか)が設定できます。
「セグメント識別子」部分の設定か、一定の文字数ごとでデータが区切られます。

「カスタム」を選んだ時の元の設定だとセグメント識別子が\nになっているのですが、元がブログ記事な性質上、書籍などと比べると改行が多めな文章になっていると思います。
1文ごとにデータを区切られたらまとまった意味を持ちにくそうなので、見出しごとがひとかたまりとして扱われるようにしたかったです。
1ファイルに結合して問題ないか
1ファイルに結合しても、ファイル容量的には問題なさそうです。
Difyでは15MBまでのファイルがアップロードできますが、私のサイトを1ファイルにまとめたものは2MB程度でした。
1文字3バイトとした場合、15MBの中には520万文字ぐらい、1記事3,000文字としたら1,700記事分の内容が入るので、15MBを超えることは少なそうです。
一方で容量以外の問題はあります。
RAGを元に回答を作成した場合、引用元としてファイル名が表示されます。
Firecrawlなどで1ファイル1記事の状態になっていれば、参照したページのタイトルが表示されるので、情報源が分かります。
1ファイルにまとめた場合、どの記事を参照したとしても引用元として同じファイル名が表示されることになります。

50記事の制限を取るか、正しい引用元を取るかの選択ですね。
引用元が出ないようにする
結合したMarkdownファイルをRAGとして使用する方法などは他の記事にお任せします。
ファイルをまとめたため当てにならなくなった引用を消す工夫について書いておきます。
RAGを使用する場合、LLMブロックのコンテキスト欄に知識取得ブロックの結果を設定するのが通常の使い方です。
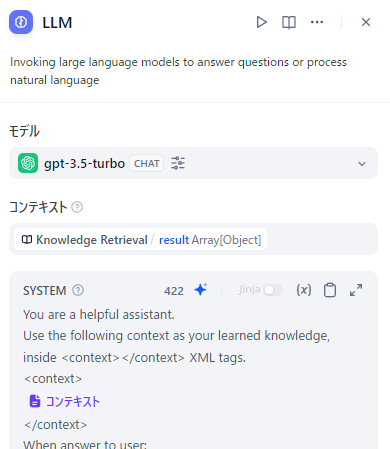
このコンテキスト欄で情報を渡すと引用元が表示されてしまいます。
なのでコンテキスト欄でなくプロンプトに直接埋め込みます。
ただし知識取得の結果はオブジェクト型になっていて、文字列型ではないのでそのままでは埋め込めません。
そこでテンプレートブロックを使用して文字列に変換し、後続のLLMではテンプレートブロックの出力値を利用します。

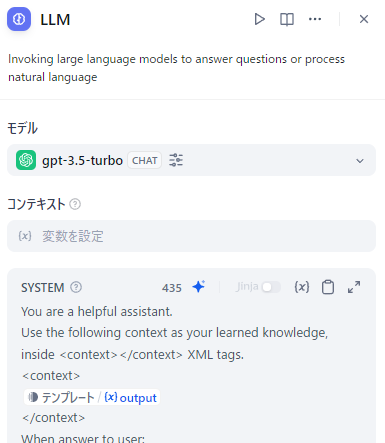
これで知識取得の結果を使用しつつ、引用元が表示されないようになりました。
併せてトークンの節約もする
知識取得の結果は以下のようにメタデータも含まれています。
{
"result": [
{
"metadata": {
"_source": "knowledge",
"position": 1,
"dataset_id": "08448dec-c5bd-4d54-a45a-1c10d36d32a3",
"dataset_name": "新潟VOCALOID愛好会.md...",
"document_id": "f4a5be44-aa46-4f8e-9608-13b9a9fd1903",
"document_name": "新潟VOCALOID愛好会.md",
"document_data_source_type": "upload_file",
"segment_id": "b36a4c6a-1126-44af-9392-c09feca5601f",
"retriever_from": "workflow",
"score": 0.9981178,
"segment_hit_count": 1,
"segment_word_count": 201,
"segment_position": 386,
"segment_index_node_hash": "e59e5d0a9cf4d112e7c85437120c16d87b997a15231e15113859e8a720098417"
},
"title": "新潟VOCALOID愛好会.md",
"content": "ボカコレ\n2020年12月に初開催されて好評だった「ボカコレ(The VOCALOID Collection)」ですが、2021年4月に2回目が開催されます!\n**正式なNicoBoxアプリのリニューアルは2021年5月を予定**しているそうです。\nボカロのイベントなので、NicoBoxとも相性が良い!ということで、正式アップデートに先立ってボカコレに合わせてNicoBoxの先行体験版が配布されます"
}
]
}
どのファイルを参照したのかなどのデータが含まれていますが、1ファイルにまとめているのでメタデータは要らない気がします。
(強いて言えばscore(入力との関連度)は回答の時に参考にされるのかもですが……)
余計な内容が含まれていると余計なトークンを消費してしまうので、テンプレートブロックで文字列に変換する際にcontent部分のみを取り出すようにします。
テンプレートブロックのコードを以下のようにすると取り出せます。
{% for result in arg1 %}
{{ result.content }}
{% endfor %}
これでLLMブロックにメタデータを除いたデータを渡せるようになりました。
おわりに
雑多に色々書いてしまいました!
Difyは日本語ドキュメントが整備されていてありがたいですね。
Difyに関する技術記事を見てると、ローカルで動かす話が多くてクラウド版の制約で困った![]() みたいな話は少ないなと思いました。
みたいな話は少ないなと思いました。
クラウド版でRAGを使う時の参考になれば幸いです。
もっと良い方法とかあったらぜひ教えてください。
あとせっかく設置したので良かったらサイトに行って右下のボタンから話し掛けてみてください。