本記事はDeNA 23 新卒 Advent Calendar 2022 の23日目の記事です。
はじめに
初めまして。DeNA23卒内定者のHarrisonOwlと申します。
当たり前の話ですが、WebフレームワークのおかげでWebアプリの開発が結構楽になりましたよね。
Webフレームワークのおかげで色々やりやすくなった一方、例えばルーティングやスレッドの管理とか、ライブラリの中身どうなっているのか気になる時はありますよね。大学で情報系の勉強をしていたからなのか、自分も内部実装がどうなっているのか気になる時結構あります。
そんな思いがあって、約3日間かけてWebフレームワークを自力で実装してみたので、そちらについて紹介していきたいと思います。
作ったもの
rum_frameworkという名のWebフレームワークを作成しました。サーバーを立ち上げてバックエンド側の処理をメインで行うRust製Webフレームワークです。
察している人いるかもしれませんが、フレームワークの名前をrumにしたのはginへのリスペクトです。(どっちも頭文字が実装言語に一致しているアルコール類なので)
普段からよくexpressとgin-gonicでWebバックエンドの開発を行っていたので、rum_frameworkの設計思想もこの2つのフレームワークに寄せました。rum_frameworkを使うと下記のようにginとexpressっぽい感じでWebアプリを作ることができます:
use rum_framework::rum;
use rum_framework::context::RumContext;
use serde::{Serialize, Deserialize};
use tera::Context;
#[derive(Serialize, Deserialize, Debug)]
struct Point {
x: i32,
y: i32,
}
fn session(_: &mut RumContext){
println!("called first.");
}
fn verify(c: &mut RumContext){
println!("called second.");
let ua = c.get_request_header("User-Agent");
if ua.is_none(){
// Abort Operation if header is invalid.
c.text(400, "bad request");
}
}
fn is_admin(_: &mut RumContext){
println!("verifying permission.");
}
fn index(c: &mut RumContext){
println!("controller exected!");
c.set_response_header("Access-Control-Allow-Origin", "http://127.0.0.1:8000");
c.file(201, "static/test.jpg");
}
fn main() {
let mut rum_server = rum::new("127.0.0.1", 3000);
rum_server.use_html_template("templates/*.html");
rum_server.use_static_assets("static");
rum_server.global_middleware(vec![session, verify]);
rum_server.get("", index);
rum_server.post("/test/a1/:param1/b/:param2/c", |c:&mut RumContext|{
let point = Point { x: 1, y: 2 };
c.json(200, serde_json::to_string(&point).unwrap());
});
rum_server.get("/test/b1", |c: &mut RumContext|{
let mut context = Context::new();
context.insert("val1", &"Hello!");
context.insert("val2", &2023);
c.html(200, "index.html", &context);
});
rum_server.middleware("/test",vec![is_admin]);
rum_server.start();
}
実装しきれていない部分、あるいは改善が必要な部分はまだまだありますが、とりあえずバックエンドWebフレームワークとして最低限必要な機能を一通り実装しました。現状、下記の機能は使用できます。
- ルーティング
- Middleware(共通コントローラの設定)
- 静的ファイルの配信
-
HTMLのレンダリング
- teraを使用
- リクエストの抽出
- レスポンスのカスタマイズ
フレームワークの実装
Webサーバー
The Rust Programming Languageの中にマルチスレッドのWebサーバーを構築するチュートリアルがあったので、そちらを参考にフレームワークのベースとなるWebサーバーを実装しました。Webサーバーの具体的な実装はThe Rust Programming Languageの実装と結構似ているので割愛させていただきますが、フレームワーク化する為に工夫したことを軽く紹介します。
スレッドプール
The Rust Programming Languageではスレッドプールの数を4に設定していましたが、実際の設定可能なスレッド数はCPUのスペックと状態による為、スレッドプールの数もCPUの状況に合わせる必要があります。標準ライブラリには使用可能なスレッドの情報を取得できるモジュールがあるので、それを使ってスレッドプールの数を設定します。
use std::thread::available_parallelism;
let pool_size = available_parallelism().unwrap().get();
let pool = ThreadPool::new(pool_size);
共通オブジェクトのスレッド間共有
rum_frameworkはマルチスレッドに対応していますが、ルートの情報などサーバー起動前に設定したデータはスレッド間で共有されています。しかし、データのインスタンスがスレッドごとに生成されるのはメモリ的にはよろしく無いですし、同じオブジェクトをむやみに複数のスレッドから参照するのも危険です。この問題の対策として、参照カウンタを持つスマートポインタであるArcを利用すると、スレッドが複数存在しても、各スレッドは安全に同じオブジェクトに参照することができます。
let handler = Arc::new(self.handler);
for stream in listener.incoming() {
let stream = stream.unwrap();
let handler = Arc::clone(&handler); // Arcによる参照の複製
pool.execute(move || {
// 参照をワーカースレッドに移譲
handler.handle_connection(stream);
});
}
ルーティング
ルール
下記の条件を満足した場合、リクエストに指定されたターゲットルートとHTTPメソッドに紐づくコントローラが実行されます:
- 指定されたルートとHTTPメソッドにマッチするルートにコントローラが設定されている場合
- 指定されたルートと全文一致するルートは無いが、ルートパラメータを取り除くとマッチするルートが存在する場合
また、静的アセットの配信を許可する場合は、指定されたコンテンツがサーバー上に存在する場合にコンテンツを返すようにしています。
一方、ginの場合、サーバー側でルートを設定する際、以下のような設定がある場合は、サーバーは起動できず開発者にルート設定の修正が求められます:
- 例えば、
GET /api/:param1/a,GET /api/:param2/aのように、同じサブパスの位置で複数のルートパラメータを設定しようとした時 - 指定されたルートとHTTPメソッドに対応するControllerが既に存在していた時
rum_frameworkも、ginと同じような制限を設けてあります。
ルーティングアルゴリズムとデータ構造
初期化時に設定されたルートにはコントローラとその前に実行する共通コントローラの情報なども紐付いているので、Webサーバー起動後不変になる情報はほとんどルーティング用のデータ構造に集約できます。ルートを構成するサブパスは分解され、ツリー構造に集約されます。例えば下記のルーティングは:
GET /api/user/:userid/profile
PUT /api/user/:userid/profile
GET /api/user/rules
GET /api/admin/lists
POST /api/admin/login
図で表すと:
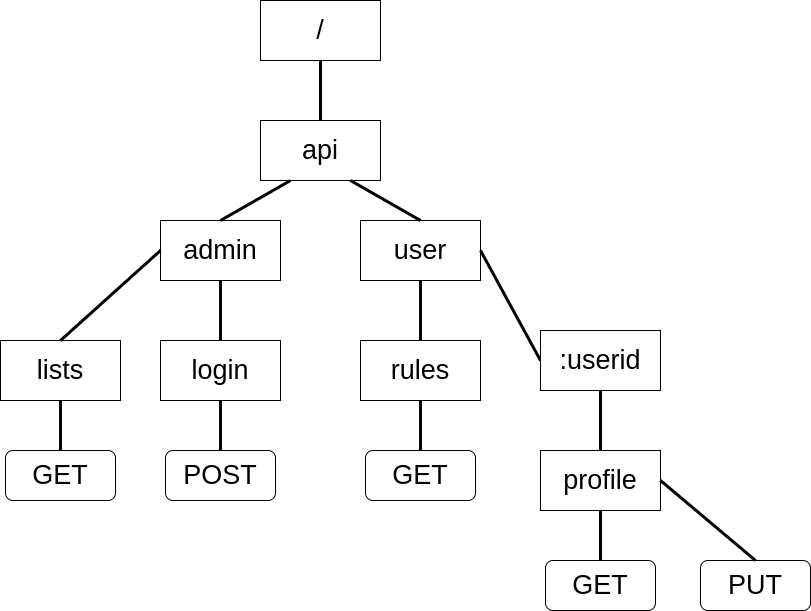
このような階層構造になります。探索する際は、一番上のノードから下に辿って、指定されたルートとHTTPメソッドのノードが存在するか確認します。ノードによっては、子パスの情報を持っていることがありますが、子パスの情報を普通の配列に保存すると、各ノードで子パスを検索する時の最悪計算量が$O(n)$になってしまいます。紐付いてる子パスが多いほど計算量が線形的に上がってしまうので、配列の代わりに要素の検索を$O(\log n)$で行われるBTreeMapを子パスのアドレスの保存に使いました。一応HashMapを使うと理論上は$O(1)$で要素を取り出せますが、rustのHashMapはハッシュ攻撃対策の為動作的に他言語のHashMapにより遅く、かつ$O(1)$はBTreeMapの$O(\log n)$と大きな差が無いため、最終的にBTreeMapを採用しました。実際に各サブパスを表すノードは下記の構造体で実装されています。
struct Router {
pub route: String, //サブパス名
children: BTreeMap<String, Router>, //サブパスに紐づく子パスの情報
params_child_route: String, //ノードに紐づくルートパラメータの情報
controllers: BTreeMap<String, fn(c: &mut RumContext)>, //各HTTPメソッドに紐づくコントローラ
full_route: Vec<String>, //ここまでの絶対パス、サブパスの配列で構成される
middlewares: Vec<fn(c: &mut RumContext)>, //共通コントローラ群
}
大体の場合は、送られてきたリクエスト上に記載されているパスとHTTPメソッドに一致するノードがあるかどうかで判断していますが、/app/v1/:param1/xxxxのように、ルートパラメータがある場合は全文一致のチェックで該当するパスがあるか判断できるとは限りません。一方、ルール的にルートパラメータがあっても、同じサブパスのノードには一種類のパラメータしか存在しないはずなので、ルート登録時に対象ノードでルートパラメータの名前を記録し、もし全文一致するパスが存在しない場合は、ルートパラメータの部分をワイルドカード扱いにして他のノードを探索します。実際にルートの探索で実装されたアルゴリズムは下記になります:
pub(crate) fn search_route(
&self,
route_segs: &[&str],
cur_index: usize,
) -> Option<(&[String], &Router)> {
if cur_index == route_segs.len() - 1 {
return Some((&self.full_route[..], &self));
} else {
return match self.children.get(route_segs[cur_index + 1]) {
None => {
if self.params_child_route != "" {
match self.children.get(&self.params_child_route) {
None => None,
Some(router) => router.search_route(route_segs, cur_index + 1),
}
} else {
None
}
}
Some(router) => router.search_route(route_segs, cur_index + 1),
};
}
}
コントローラや共通コントローラの登録時に似たようなアルゴリズムでチェックしていますが、ルートパラメータであるかどうかのチェックはスキップしています。
リクエストの解析
試しにPOST /宛のリクエストの中身を抽出してみると:
POST /test HTTP/1.1
User-Agent: PostmanRuntime/7.29.2
Accept: */*
Postman-Token: afdce974-4bb4-4070-be80-ef090142a8f9
Host: localhost:3000
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded
Content-Length: 21
test1=val1&test2=val2
このような出力が得られます。HTTPリクエストの場合、一番上の行はが使用されたHTTPメソッド、ターゲットルートとHTTPプロトコルのバージョンを表しており、それ以外はヘッダーとボディとなります。ヘッダーとボディは空行で分断されており、そのうちヘッダーは全部Key: Value形式で羅列されております。正規表現などを使うともっと綺麗にパースできると思いますが、HTTPリクエストのフォーマットを基づくと下記のようにリクエストをパースすることができます:
for (index, line) in requests.lines().enumerate() {
// リクエストヘッダーとボディのボーダー
if line.len() == 0 {
request_header_parsed = true;
continue;
}
//最初の行
if index == 0 {
let mut iter = line.splitn(3, " ");
http_method_str = iter.next().unwrap();
let route_with_query = iter.next().unwrap();
let mut iter_q = route_with_query.split("?");
route = iter_q.next().unwrap();
// クエリパラメータが存在する場合、抽出する
match iter_q.next() {
Some(q) => {
let queries = q.split("&").into_iter();
for query in queries {
let mut iter_qi = query.splitn(2, "=");
let key = iter_qi.next().unwrap_or_else(|| "");
let val = iter_qi.next().unwrap_or_else(|| "");
if key != "" && val != "" {
context.set_query_params(key, val);
}
}
}
None => {}
}
http_ver = iter.next().unwrap();
} else if !request_header_parsed {
//ヘッダーの解析
let mut iter = line.splitn(2, ": ");
let key = iter.next().unwrap();
let value = iter.next().unwrap();
context.set_request_header(key, value);
} else {
// ボディの解析
request_body = request_body + line;
}
}
コントローラの実行と通信データの管理
コンテキスト
リクエストの受信からレスポンスの生成までの間のデータの管理や、コントローラ間のコミュニケーションの土台としての役割を果たしている構造体です。コンテキストを通して、URLパラメータのリクエスト情報の取得、他のControllerとの情報やりとり、レスポンスヘッダーの設定およびレスポンスの返却、などができます。各通信において1個のコンテキストが用意されます。また、コントローラなどでデータの変更が発生することがあるので、各通信ではコンテキストをmutableオブジェクトとして扱っています。
struct RumContext<'a> {
template_engine: Option<&'a Tera>,
request_header: BTreeMap<String, String>,
request_body: String,
response_header: BTreeMap<String, String>,
url_params: BTreeMap<String, String>,
query_params: BTreeMap<String, String>,
form_params: BTreeMap<String, String>,
response: Option<Response>,
context_params: BTreeMap<String, String>,
}
コントローラ
開発者が送られて来たリクエストを元にどういうレスポンスを返すのか、そういったロジックを記述する為の関数とクロージャのことです。各コントローラの引数にMutableのコンテキストが用意されており、そのスコープの中でレスポンスの返却や他のControllerとのやりとりができます。コントローラは特定のルートとHTTPメソッドに紐付けてそのルート宛のリクエストだけ処理するのではなく、共通のコントローラとしてルートグループに紐付けて、認証やAPIのアクセス制限などに使うこともできます。
fn hello_controller(c: &mut RumContext){
//do stuff
...
c.text(200, "hello");
}
コントローラの実行フロー
各コントローラと共通コントローラのポインタは、ルート設定時に対象パスの末端ノードに紐付けられます。共通コントローラはルーティングと同じように、上から順番で実行され、すべての共通コントローラが正常に実行できた後に、通常のコントローラが実行されます。
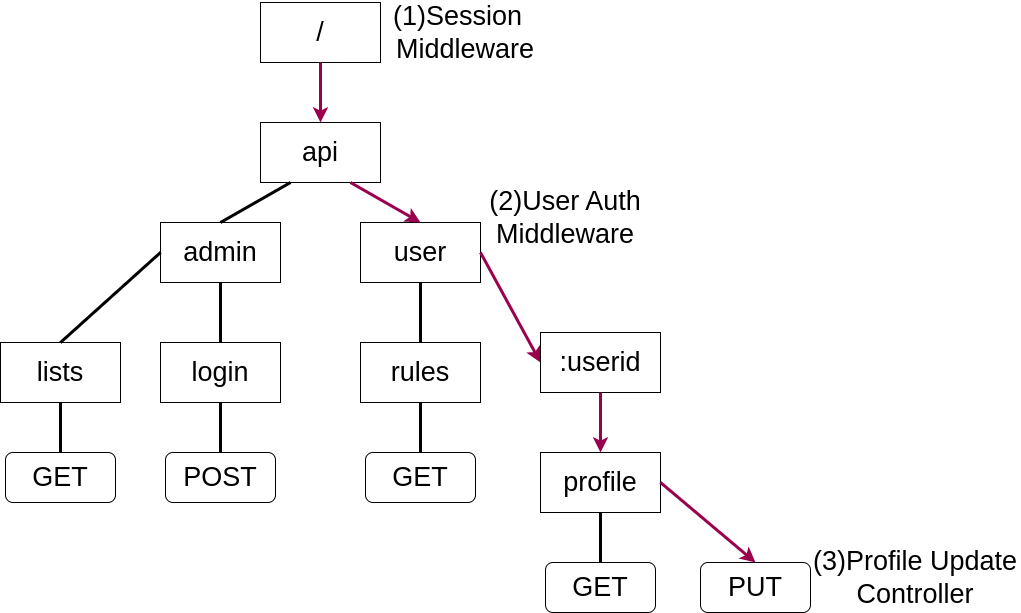
この図の例では、/と/api/userにそれぞれセッション管理とユーザー認証用の共通コントローラが紐付けられており、/api/user/:userid/profileをPUTするとセッション管理の共通コントローラとユーザー認証用の共通コントローラが実行され、最後に/api/user/:userid/profileに紐づくコントローラが実行されます。
fn exec_middleware(
&self,
full_route: &[String],
cur_index: usize,
context: &mut RumContext,
) {
for middleware in &self.middlewares {
middleware(context);
if context.has_response() {
return;
}
}
if cur_index + 1 < full_route.len() {
match self.children.get(&full_route[cur_index + 1]) {
Some(router) => router.exec_middleware(full_route, cur_index + 1, context),
None => (),
}
}
}
共通コントローラは各サブパスに複数設定することができ、複数設定した場合は配列内要素の順番で実行されます。共通コントローラの実行は上から順番に実行する必要がありますが、その前に既にルーティングでリクエストの有効性を検証できたので、必要の無い探索コストを減らす為に、ターゲットルートに紐づくfull_routeを利用して実行ルートを予め記憶しています。また、認証失敗などで処理を中断することを想定して、共通コントローラの中でレスポンスを返した場合、その後の共通コントローラとコントローラは実行され無いようにしています。
self.router.exec_middleware(full_route_info, 0, context);
if !context.has_response() {
controller(context);
}
context.get_response(http_ver)
レスポンスの生成
HTTPレスポンスを受け取ってそのまま出力すると、下記のフォーマットになります:
HTTP/1.1 200 OK
Content-Type: application/json
{"x":1,"y":2}
ご覧の通り、一行目のHTTPメソッドとターゲットルートの部分がステータスコードに変わった以外、他のフォーマットはHTTPリクエストと同じです。従って、レスポンスは下記のように生成することができます。
struct Response {
http_status: String,
response_body: String,
}
impl Response {
fn get_response(&self, http_ver: &str, response_header: String) -> String {
return format!(
"{} {}\r\n{}\r\n{}",
http_ver, self.http_status, response_header, self.response_body
);
}
}
静的アセットの配信
実際のWebサービスは、PDFやAPKなどのファイルを配信したり、Webページに画像などを読み込ませることがあると思います。一方、画像などのファイルを適切じゃない場所に置いたり、ファイルの読み込みとレスポンスへの書き込みがうまく行われていないとユーザーがコンテンツ正しく受信できないことがあるので、静的ファイルの配信にも対応させます。
ファイルバイナリを配布する需要を合わせて、静的アセットを配布する機能を実装しました。フローはJSONとHTMLをレスポンスに書き込むのとほぼ同じで、画像などのバイナリデータを文字列に変換してレスポンスボディに書き込めばユーザーにコンテンツを配布できます。しかし、配布しているコンテンツの種類はなんなのか、クライアントサイドに教えないと、コンテンツが正しく表示できなかったり、勝手にダウンロード扱いされるなどの現象が起こる可能性があります。Chromeなどのアプリは、リクエストヘッダー内に入っているContent-Typeの値でコンテンツの種類を判断しているので、ファイルの種類に合わせてContent-Typeヘッダーを設定してあげる必要があります。
しかし、Content-Typeに入れる値はファイルごとに判断する必要があるので、ファイルのメタ情報などを利用する必要があります。今回はサードパーティライブラリのmimeとmime_guessを使って、ファイルからMIMEを判断してそこからContent-Typeに入れる値を決めています。
let mut reader = BufReader::new(file);
let mut buffer = Vec::new();
match reader.read_to_end(&mut buffer) {
Ok(_) => {
self.set_response_header(
"Content-Type",
&(match mime_guess::from_path(file_path).first() {
Some(mime) => mime.to_string(),
None => mime::TEXT.to_string(),
}),
);
self.response = Some(Response {
http_status: status_code::from_status_code(status_code),
response_body: unsafe { from_utf8_unchecked(&buffer).to_string() },
})
}
Err(e) => {
self.set_response_header(
"Content-Type",
&(mime::TEXT_HTML_UTF_8.to_string()),
);
self.response = Some(Response {
http_status: status_code::from_status_code(
status_code::INTERNAL_SERVER_ERROR,
),
response_body: e.to_string(),
})
}
}
ファイルの種類によってはUTF-8文字列のバリデーションチェックが通らない可能性があるので、一旦unsafeであるfrom_utf8_uncheckedでバイナリを文字列に変換しています。ちなみにアセット配信用のパスを設定すると、通常のルーティングフローで考慮されないファイルのありなしのケースも考慮されるようにしています。
さいごに
いかがでしょうか。Webフレームワークが多く出回っている世の中で車輪の再発明をしてみたのですが、普段よく使われているWebフレームワークの思想とWebサーバーの仕組みを知るきっかけにもなったので大変勉強になりました。
一応rum_frameworkはGitHubリポジトリとcrate.ioにも公開してあるので、興味ある方はぜひ試してみてください!
Webフレームワークとして最低限の機能を実現できたものの、やはり改善点と問題点はまだまだあると思いますので、ご意見ある方はコメントやissue立てていただけると嬉しいです!
参考