PEFT(Parameter Efficient FineTuning)とは
LLMはその名の通り非常に大規模なパラメータを持ちます。パラメータ数は数十億から下手をすると数兆パラメータになります。
そのため、全てのパラメータを更新しようとすると数千個のGPUを利用して数か月の学習が必要になってしまい、個人や普通の企業ではとても0から学習することはできません。幸い、MetaやDeepSeekが大規模コーパスで事前学習したモデルをオープンソースとして公開してくれているため、我々はそのモデルをファインチューニングすることで目的のタスクや業務内容にあったLLMを構築することができます。
しかし、全てのパラメータをファインチューニングしようとすれば、必要な計算リソースは事前学習の時と同様になり、一般人では用意できません。そこで、元のモデルのパラメータは固定してファインチューニングすべきパラメータを追加したり、パラメータを選んでファインチューニングしたり、モデルパラメータを変換したりすることで学習すべきパラメータを削減して、少ないGPUでもファインチューニング可能にした手法がParameter Efficient FineTuningです。
ここでは、Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Surveyを参考にPEFTの手法をざっくりと紹介します。
Transformerの計算量
まずはLlamaを例にTransformerのおさらいです。

Llamaは上図(a)のようにEmbedding層, Decoder(Transformer)層, Linear&Softmax層からなり、さらにDecoder層はSelf-Attention層とFeed-Forward Network層からなります。
Embedding層
入力トークン系列を$\boldsymbol{x}\in \mathbb{R}^{l}$とすると、Embedding層は各トークンを$d$次元に埋め込み、以下のように変換する。
H = (\boldsymbol{h}_1, \boldsymbol{h}_2, \boldsymbol{h}_3, \cdots \boldsymbol{h}_l) = Emb(\boldsymbol{x})\in \mathbb{R}^{d\times l}
このあと、各トークンの文章中での位置を示す位置符号の追加がありますが、一旦割愛します。
Self-Attention
Self-Attentionでは入力系列をQuery, Key, Valueに変換します。つまり、各変換パラメータを$W_q, W_k, W_v\in \mathbb{R}^{d\times d}$とすると、以下のようになる
Q, K, V = W_qH, W_kH, W_vH\in \mathbb{R}^{d\times l}
実際にはmulti-head Attentionなので、各パラメータをm個のヘッドに分割するとi番目の$Q, K, V$は次のようになる。
Q_i, K_i, V_i = W_{q, i}H, W_{k, i}H, W_{v, i}H\in \mathbb{R}^{\frac{d}{m}\times l}
これらを使って以下のようにSelf-Attention機構によって各トークン間の関係性を計算する。
SA_i(H) = Softmax\Bigl(\frac{Q_iK_i^T}{\sqrt{d/m}}\Bigr)V_i \in \mathbb{R}^{\frac{d}{m}\times l}
各ヘッドでのSelf-Attentionの結果を以下のように行方向に結合して$d\times d$次元のパラメータ$W_o$をかけることでSelf-Attentionの出力となる。
U = MSA(H) = W_o
\left(
\begin{array}{c}
SA_1(H)\\
SA_2(H)\\
\vdots\\
SA_m(H)
\end{array}
\right)
\in \mathbb{R}^{d\times l}
Feed-Forward Network
大層な名前してますが、ただの2層のニューラルネットワークです。Llamaでは残差結合もしているため、$W_{up}\in \mathbb{R}^{d\times d_f}, W_{down}, W_{gate}\in \mathbb{R}^{d_f\times d}$の3つのパラメータがあります。
FFN(U) = W_{up}(SiLU(W_{gate}U)\odot(W_{down}U)) + U
$d_f$は通常$4d$に設定されることが多く、FFNのパラメータ数はLLM全体の2/3を占めるほど大きいです。
パラメータ数と計算量
ここまでの説明から、Transformerのパラメータ数と計算量は以下の表のようになることが分かります。
| 操作 | パラメータ | 次元 | 入力次元 | 計算量 |
|---|---|---|---|---|
| Query, Key, Value変換 | $W_q, W_k, W_v$ | $m\times \frac{d}{m}\times d$ | $d\times l$ | $O(l)$ |
| Self-Attention | - | - | $m\times \frac{d}{m}\times 3$ | $O(l^2)$ |
| Attentionの出力 | $W_o$ | $d\times d$ | $d\times l$ | $O(l)$ |
| FFN | $W_{up}, W_{down}, W_{gate}$ | $d\times 4d, 4d\times d$ | $d\times l, 4d\times l$ | $O(l)$ |
この表からパラメータ数は埋め込みベクトル次元$d$に支配され、FFNのパラメータが大半を占めることと、計算量は入力系列長$l$に支配され、特にSelf-Attentionにおいて深刻となることが分かる。
LLMでは一回の計算で次のトークンのみを予測するため、長い出力のためには同じ計算を何度もする必要がでてくるが、これは$O(l), O(l^2)$の計算を何度もすることになるため効率が悪い。
そこで、Attention部分のパラメータや出力をキャッシュしておくことで効率的に計算でき、これをKV-Cacheという。(Open AIやAnthropicのprompt cachingはおそらくこれ)
KV-Cacheのサイズは次のように表される。
\text{KV-Cache} = L \times 2 \times l \times \frac{d}{m} \times m
$L$はレイヤーの数を表します。
よって、LLMの推論時に使われるパラメータ数は以下のようになる。
10d^2 \times L + \text{KV-Cache}
事前学習では、これらのパラメータを全て自己教師あり学習にて学習しますが、そのためには何千台、何万台というGPUを何十日も動かす必要があり、非常にコストがかかります。事後学習はデータ数が少なくできるといっても、全てのパラメータを馬鹿正直にチューニングするには大量のGPUが必要になり、現実的ではありません。
PEFTの手法を利用すれば、個人でもあつかえるような少ないGPU数でLLMをファインチューニングすることができるようになります。
PEFTの概要
以下の図が示すように、PEFTの手法は加算型(Additive), 選択型(Selective), 再パラメータ化(Reparameterized), ハイブリッド(Hybrid) に分類されます。

各手法のアルゴリズムのイメージは以下のようになります。

加算型PEFT(Additive PEFT)
加算型PEFTは上図(a)のように、事前学習済みモデルのパラメータを固定し、トレーニング可能なパラメータを持つモジュールを追加して、そのモジュールのみを学習する手法です。加算型の一般的なアプローチとして、Adapterとsoft promptがあります。
Adapter
AdapterアプローチではTransformerレイヤーに学習可能なAdapter層を追加します。AdapterはFFNのように2層のNNからなります。本来のFFNであれば2つの層のパラメータサイズは$d_f\times d, (d_f>d)$ですが、パラメータサイズを小さくするため、Adapterのパラメータサイズは$r\times d, (r<d)$とします。入力系列を$X$とするとAdapterは次のように表せます。
\begin{align}
Adapter(X) = W_{up}ReLU((W_{down}X)) + X \\
W_{up}\in \mathbb{R}^{d\times r},
W_{down}\in \mathbb{R}^{r\times d},
X\in \mathbb{R}^{d\times l}
\end{align}
Adapterをどこに挿入するかという問題については様々な研究が行われています。

上図はAdapterアプローチのバリエーションです。
Serial Adapter(上図a)では、AdapterをAttention層とFFN層の直後の2つに追加しています。この手法ではAdapterを直列に配置しているため、モデルを並列化することが難しくなります。
そこで、Parallel Adapter(上図b)の手法ではAdapterをTransformer層と並列に追加し、結合することで並列性を上げ、精度を保ったまま推論効率を向上させています。
CoDA(上図c)では、重要性の高いk個のトークンをTransformerに通し、Adapterにすべてのトークンを通すことでTransformer層での計算効率をさらに高めています。
Soft-prompt
Soft-promptアプローチはprompt tuningの一種と考えられ、入力系列の先頭にタスク固有の学習可能なベクトル(パラメータ)を付与して、そのパラメータを学習します。この手法はin-context learningを通じて離散的なトークン表現を学習するより、連続的な埋め込みであるベクトルの方が情報量が多いという仮説に基づいています。
prompt tuningでは事前学習で学習済みのembedding層によってトークンが埋め込まれますが、あるタスクに適応した埋め込みベクトルを学習することで、その埋め込みベクトルを追加したときのみタスクに対応できるようになるというイメージです。
レイヤーへの入力系列を$X$とすると、学習可能なベクトルを付加された系列$X_S$は次のように表されます。
X_S = (\boldsymbol{s_1}, \cdots, \boldsymbol{s_k},\boldsymbol{x_1}, \cdots \boldsymbol{x_l})
Prefix-tuningでは、全てのTransformer層のkeyとvalueの先頭に学習可能なベクトルを追加します。
学習されたパラメータのみ保存されるので、タスクに応じて付け替えることが可能です。Prefix-tuningでは直接パラメータを最適化せず、MLPを用いた再パラメータ化戦略をとっています。
p-tuning v2では、再パラメータ化を排除することでより広範なモデルに適用できるようになっています。
上の二つの手法は全てのレイヤーのパラメータを等しく扱っていますが、APT(Adaptive Prefix Tuning)ではprefixの重要度を制御する適応ゲートメカニズムを導入することにより性能を有効性を強化しています。
Soft-promptの手法は一定の有効性を示していますが、学習が不安定になりやすく収束が遅くなる可能性があります。これに対処する手法として、SPoT, TPT, PTP などの手法が提案されています。
選択型PEFT(Selective PEFT)
加算型の手法はパラメータを追加するため、モデルが複雑になってしまう恐れがあります。選択型では事前学習済みモデルのパラメータの一部を選択し、その部分だけをFinetuningする方法をとります。
Diff Pruningはfinetuning中に学習可能なバイナリマスクをモデルの重みに適用する手法です。
PaFiは絶対値が小さいパラメータのみを学習可能として選択し、学習します。FishMaskでは、フィッシャー情報量を利用してパラメータの重要度を計算し、それに基づいて学習可能なパラメータを決定します。
これらの手法は下図(a)のようにパラメータを非構造的にマスキングするため、学習可能なパラメータが各GPUに不均一に分布してハードウェア効率を下げてしまいます。
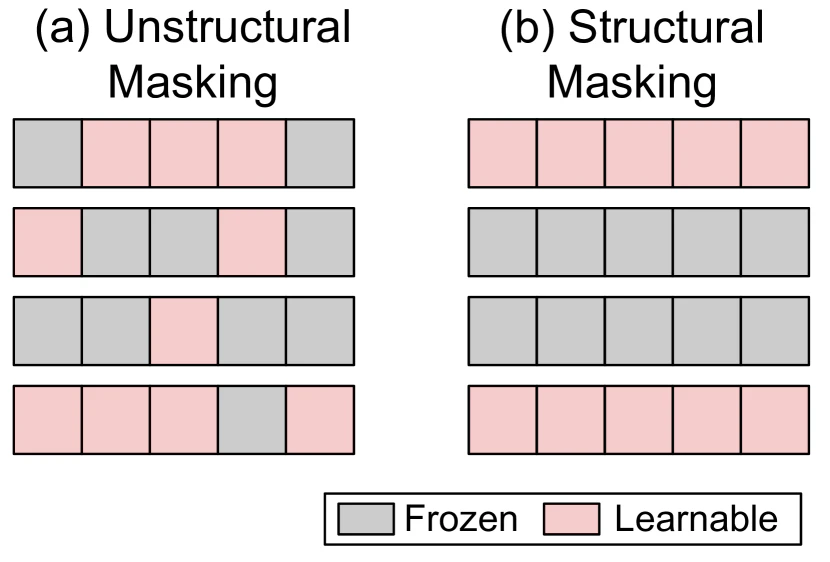
一方、(b)のように構造的にマスキングすればハードウェアを無駄にせずに済むため、構造的マスキングの研究も進められています。
先ほど紹介したDiff Pruningではパラメータをローカルグループに分割し、戦略的に排除することで構造化された刈り込み戦略を提案しています。
SPTでは、学習時の損失減少によって測定されるパラメータの感度が閾値を超えたパラメータ行列を見つけ、そこに対してのみLoRAやAdapterを適用してチューニングを行います。
再パラメータ化PEFT(Reparameterization PEFT)
再パラメータ化のアプローチはモデルのアーキテクチャをあるアーキテクチャから別のアーキテクチャに変換します。多くの研究ではパラメータ効率をよくするために低ランクのパラメータに変換します。
推論の際には、変換したアーキテクチャを元のアーキテクチャのパラメータに変換するため、推論速度を効率化することはできません。
Intrinsic SAIDという手法では、一般的にLLMは非常に低い固有次元を持つことを示しており、LLMの巨大なパラメータ空間は非常に小さい次元で表現でき、学習効率を上げることができるということを示しています。
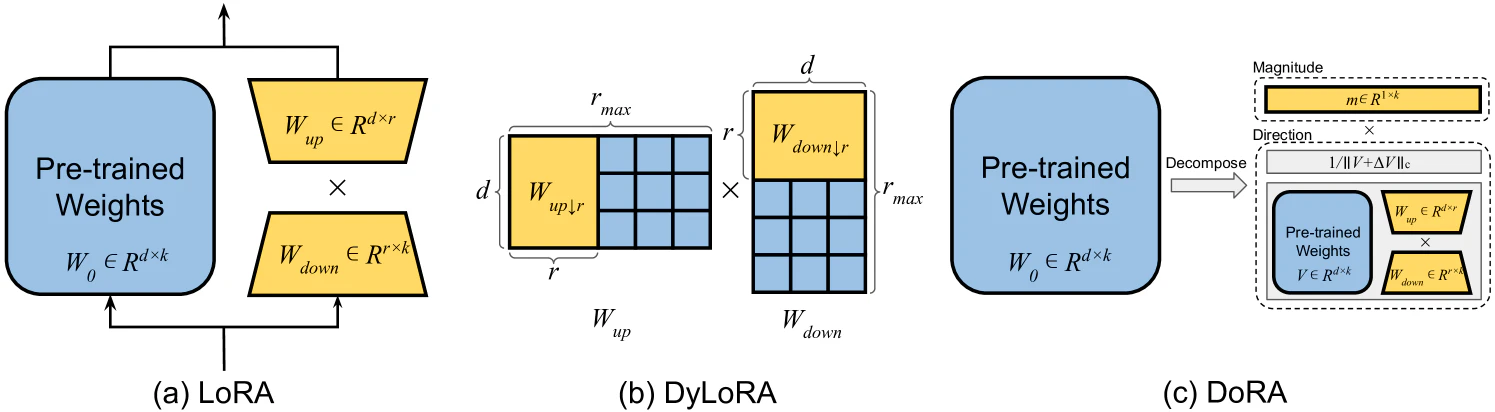
現在最も広く使われる手法として**LoRA(Low-Rank Adaption)**があります。LoRAでは上図(a)が示すように、事前学習済みLLMのパラメータ$W_0\in \mathbb{R}^{d\times k}$に対して、次のような2つのパラメータを導入します。
\begin{align}
W_{up}\in \mathbb{R}^{d\times r} \\
W_{down}\in \mathbb{R}^{r\times k} \\
r \ll min(d, k)
\end{align}
このパラメータは上図(a)のように$W_0$と並列に扱われます。
通常のfinetuningであれば、$W_0$を更新するとパラメータは$\Delta W$だけ変化しますが、LoRAでは次のように$\Delta W$を$W_{up}, W_{down}$で表します。
h_{out} = (W_0 + \frac{\alpha}{r}\Delta W)h_{in} = (W_0 + \frac{\alpha}{r}W_{up}W_{down})h_{in}
ここで、$\alpha$はスケーリング係数を示します。$W_{down}$は正規分布で初期化され、$W_{up}$は0で初期化されるため、$\Delta W$は0で初期化されます。
これによってLoRAでは$W_{up}, W_{down}$のみを学習すればよく、非常に効率的に学習を進められます。
しかし、LoRAではハイパーパラメータとして適切なランク$r$を決定するのが困難です。そこでDyLoRAでは上図(b)のように固定のランクではなく、計算リソースの予算に応じて探索するランクの範囲を決め、その範囲のランクで適切なランクを探索しながら学習を進めます。
ランクを適応的に決めるLoRAの派生としてAdaLoRAがあります。
AdaLoRAでは$\Delta W$をSVD分解して次のように表します。
\begin{align}
\Delta W = P\Lambda Q \\
P\in \mathbb{R}^{d\times r} \\
Q\in \mathbb{R}^{r\times k} \\
\end{align}
ここで、$\Lambda$は特異値$\bigl[ \lambda_i \bigr] _{1\leq i \leq r}$を含む対角行列です。これらの行列は全て学習可能パラメータです。
学習中、特異値は勾配重みの積の大きさの移動平均からなる重要度スコアに基づいて刈り取られます。
$P, Q$の直交性を保証するために、次の正則化項が損失に追加されます。
R(P, Q) = ||P^TP-I||^2 + ||QQ^T-I||^2
この手法によって学習中にランクを動的に調整し、パラメータ数を効果的に管理することができます。
SoRAではAdaLoRAの重要度スコアがヒューリスティックに構築されていることと移動平均の計算に余計な計算リソースが必要になることを指摘し、これに対処する手法を提案している。
SoRAでは$P, Q$の直交性を排除し、代わりに$g\in \mathbb{R}^r$のゲートユニットを利用し、次のように$W_{up}, W_{down}$を直接最適化している。
h_{out} = W_{up}(g\odot (W_{down}h_{in}))
$g$はL1 lossを利用した近接勾配法によって最適化される。
LoRAはLLMのFinetuningに最も使われているといっても過言ではなく、研究も盛んで様々な派生形が提案されている。
まとめと課題
PEFTは限られたデータと計算リソースでタスクに適応したLLMを作成できる手法であり、様々なバリエーションがあります。
しかし、多くのPEFT手法はAdapterのサイズやLoRAのランクのようにハイパーパラメータに敏感でこれらのハイパーパラメータの最適化手法やシンプルで効率的なソリューションが必要です。
また、PEFT手法によるパラメータ効率化と計算リソース、およびメモリの節約度合いは必ずしも一致しません。学習するパラメータの選び方によっては元のパラメータの勾配の計算と保存を大量にしなければいけないため、対して計算リソースを節約できない場合があります。
そのため、実現したい事と予算に応じて適切な手法を選択する必要があります。