このページに書いてあるように、いつの間にかtensorboardじゃなくてperfettoとかいうのが推奨になっています。
で、サーバー環境でもsshでオプションをつければいけるのですごい楽:
ssh -L 9001:127.0.0.1:9001 \<user\>@\<host\>
私の例では、とあるコードが繰り返し計算するとなんか遅くて理由わかんない、みたいな感じでした
Perfettoの画面はでかいので貼るの大変なんですけど、CPU部分は例えばこんな感じで
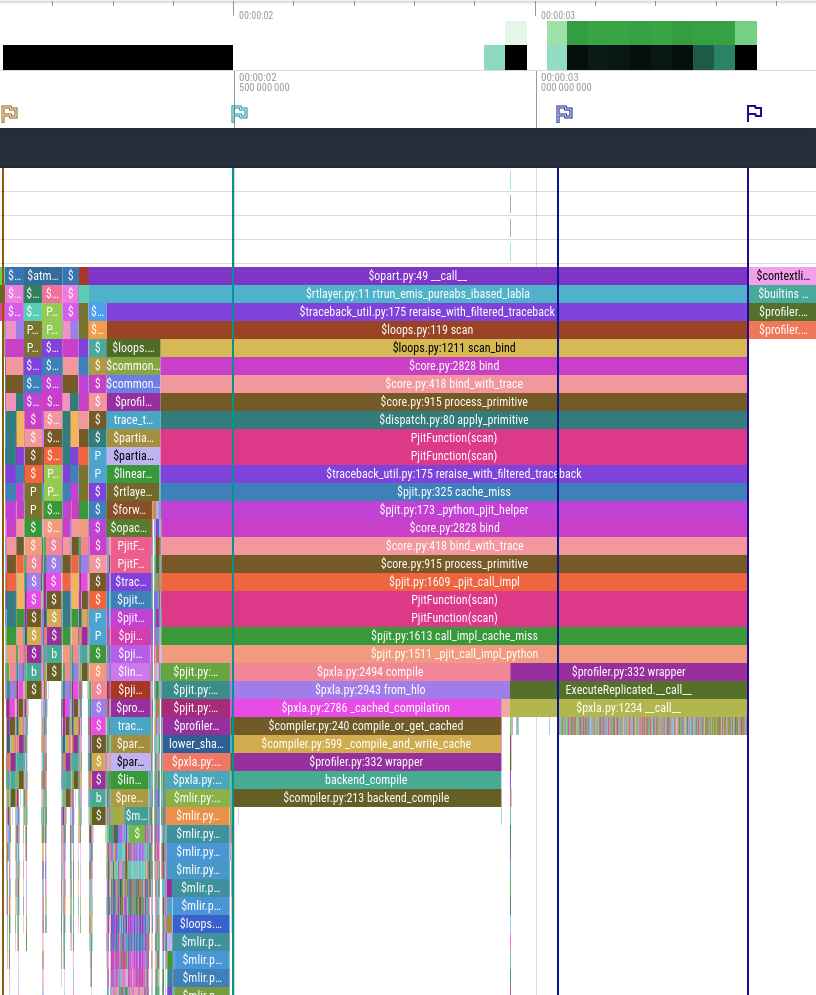
下にGPU部分があります。(スクショ撮り忘れた)で、みるとGPU部分は一番右の旗と一番右から二番目旗の間でしか動いていなくて、その前に巨大なオーバーヘッドがある。
このoverheadのところみるとpxla.py:2454 compileとか書いてあって
XLAのコンパイルしてるんだな、ってわかります。
で、問題は、これがfor loopの回ごとにcompileしなおされてました
そうすると、JIT compile自体が計算速度を律速していることに。GPUが全然効率的に使われてない。で、これは調べるとclassの中にscanが入っていて、なんらかの理由で毎回コンパイルされてました。scanを外に出すと...
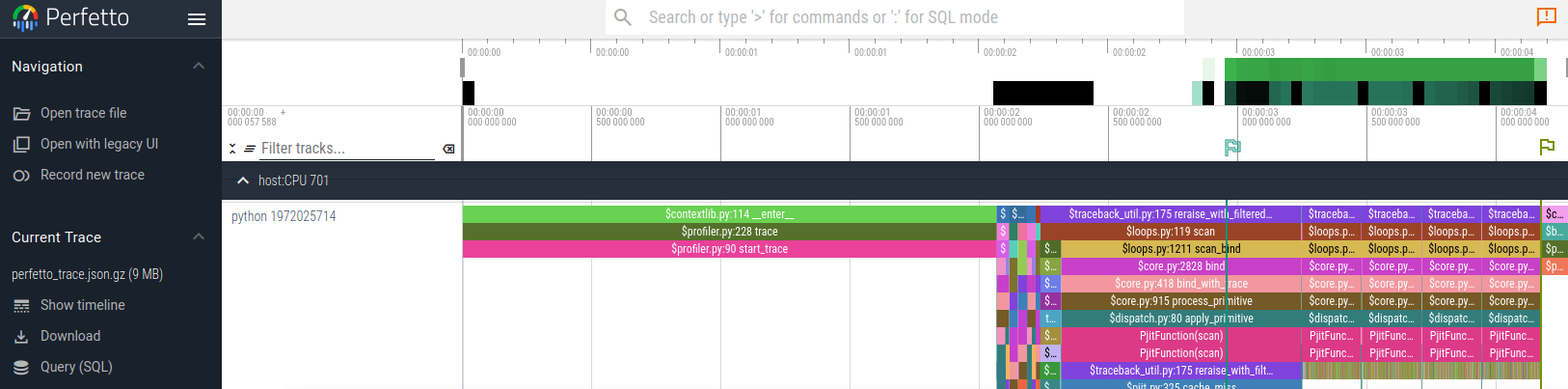
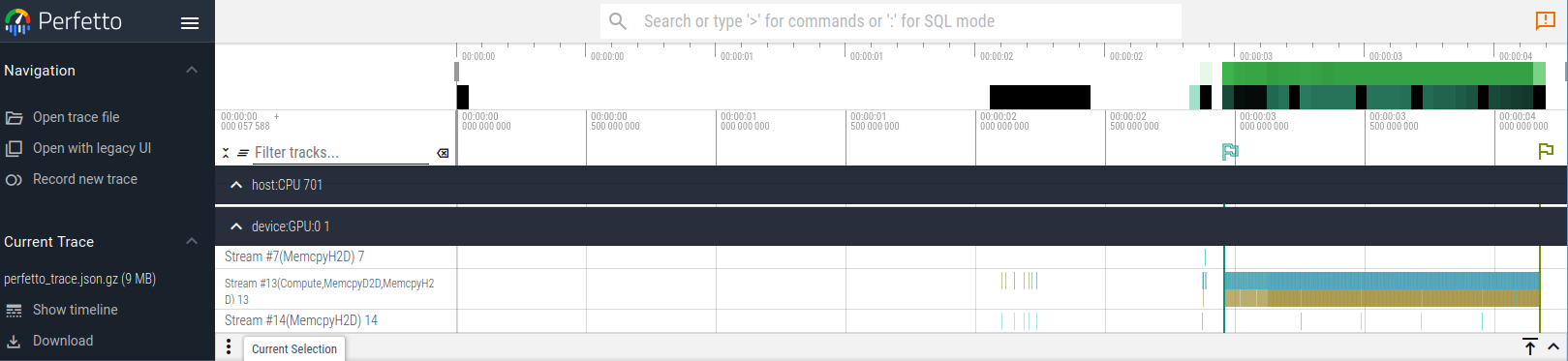
こんな感じになって(上がCPU、下がGPU)
これ、5回分for loopまわしてるんですが
compileは右から二番目の旗のところで終わっていて、その後、はcompileされていなくて、XLAされた関数が再利用されていることが分かります
で、実際にoverheadはなくなって、1 loopあたり0.7s -> 0.2sになりました
という感じで、tensorboard つかってたとき(わけわかんないであんま使ってなかった)より圧倒的に見やすくなってます