はじめに
この記事はHRBrain Advent Calendar 2022 カレンダー3の19日目の記事です。
こんにちは!株式会社HRBrainでエンジニアをしているZamaです。
みなさんは負荷試験してますか?
画面をポチポチする機能テストはちゃんとやっていても、負荷試験は忘れられていたり先送りにされてしまいがちですよね……
そんな負荷試験ですが、k6を用いて実施したら結果表示がイマイチだったので詳細なログファイルをpandasで集計した話です!
k6とは
k6は負荷試験のツールで、JavaScriptでAPIの呼び出しなどを記述します。
import http from 'k6/http';
export default function () {
const res = http.get('https://example.com');
check(res, {
'response code was 200': (res) => res.status == 200,
});
}
OSSなのでローカル環境から負荷試験を実施できますが、k6 Cloudというサービスを利用すれば複数台のEC2インスタンスから負荷をかけられたり、詳細でリッチに可視化された結果を確認できたりします。
k6の結果表示
今回はローカルから負荷試験を実施しました。
その結果がこんな感じです。
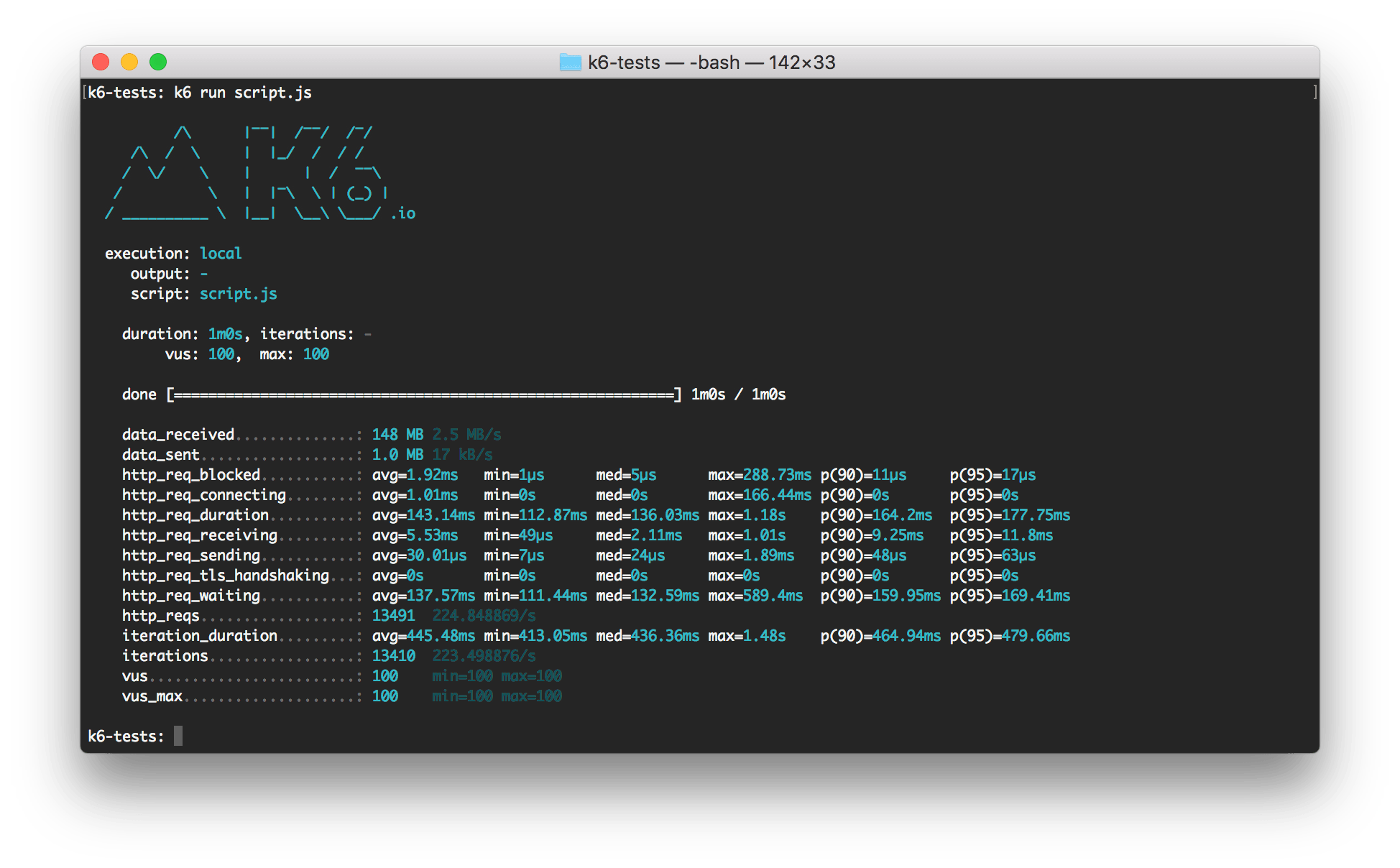
試験の中では複数のAPIを叩いているのですが、結果がまとまってしまっています……
APIごとにレイテンシーのパーセンタイルを見たりできず、どのAPIが要改善なのか分かりません……
APIごとの結果を出力できないかとドキュメントを確認しましたが、それらしい記述は見当たりませんでした。
k6 Cloudを使えばAPIごとの結果含め色々見られますが、アカウント登録とか面倒くさい。
そこでもうちょっとドキュメントを漁ったところ、CSV出力が実行時のオプションにありました!
$ k6 run --out csv=test_results.gz script.js
上記のように--out csv=<ファイル名>とオプションを付けて実行すれば、詳細なログがCSVファイルに吐き出されます。
さらにファイル名を~.gzとすればgzipまでしてくれ、ログファイルは巨大になりがちなので至れり尽くせりです。
そのCSVファイルの中身はこんな感じです。
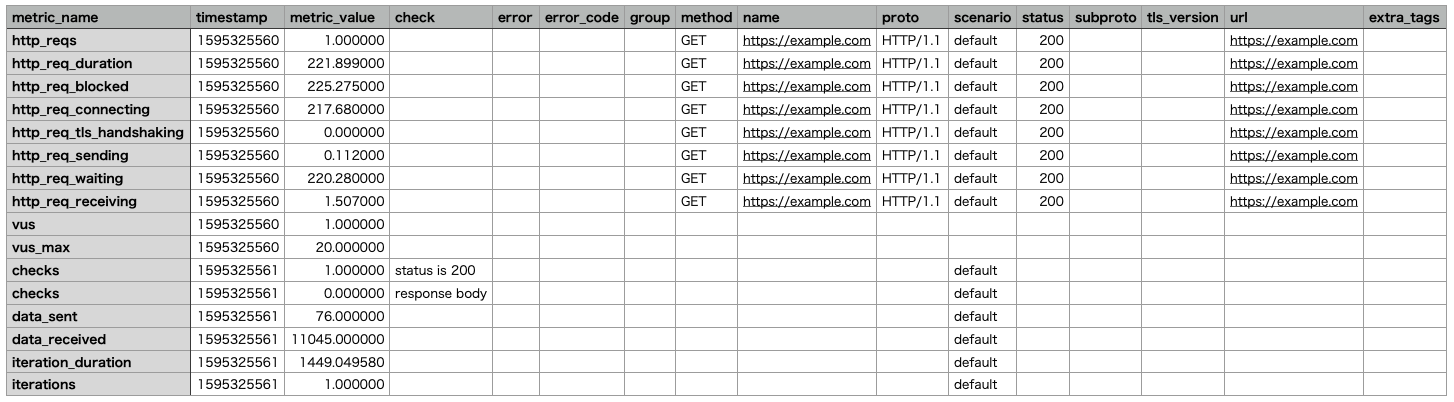
1リクエストあたり複数行(http_req~)出力され、url列に叩いたAPIのURLが入ります。
http_req_durationが
-
http_req_sending- サーバーにリクエストを送信するのにかかった時間
-
http_req_waiting- サーバーからレスポンスが来るまでに待った時間
- TTFB (Time to first byte)
-
http_req_receiving- サーバーからレスポンスを受信するのにかかった時間
の合計になるので、これをAPIごとに集計してあげれば良さそうです。
集計の前に
後はhttp_req_durationをAPIごとに集計してあげるだけなのですが、その前に1つ問題があります。
URLのパスにIDが含まれる(e.g. ~/users/123/)ことがよくありますが、単純にurl列でGroupByしてあげるとこういったID違いが別のAPIとして集計されてしまいます。
集計の際に正規表現で何とかすることもできそうですが面倒くさい。
そこで再びk6のドキュメントを漁るとありました!
JavaScript内でAPIを呼ぶ際に、下記のようにname列を指定できます。
const res = http.get(
'https://example.com/users/100/',
{
tags: {
name: 'GET retrieve user'
}
}
);
これでname列でGroupByして集計すればOKです!
pandasで集計
集計にはPythonのデータ解析ライブラリーであるpandasを使いました。
CSVファイルはこんな感じなので(関係ない列は割愛)

pandasではこうなりました。
(pandasは不慣れで汚いコードですがご容赦ください)
import os.path
import sys
import pandas as pd
input_file_path = sys.args[1]
df = pd.read_csv(
input_file_path,
usecols=['metric_name', 'metric_value', 'name']
)
output_columns = [
'API', '50%', '60%', '70%', '80%', '90%', '95%', '99%'
]
output = pd.DataFrame(columns=output_columns)
for endpoint in sorted(df['name'].unique()):
output_row = [endpoint]
rows = df[df['name'] == endpoint]
http_req_durations = rows[rows['metric_name'] == 'http_req_duration']
percentiles = http_req_durations['metric_value'].quantile([
0.5, 0.6, 0.7, 0.8, 0.9, 0.95, 0.99
])
output_row.extend(percentiles.values)
output = pd.concat([
output,
pd.DataFrame([output_row], columns=output_columns)
])
root, ext = os.path.splitext(input_file_path)
output.to_csv(f'{root}_集計結果.csv', index=False)
これでpython aggregate.py test_results.gzと実行すると、下表のようにAPIごとのレイテンシーのパーセンタイルが集計されます。

やりました!
これで同時接続数を変えたり、サーバーのスペックを変えたりして、負荷試験ができるようになりました!
まとめ
k6を用いて負荷試験を行うにあたり、詳細なログをCSVファイルに出力し、pandasでその集計を行いました。
name列を指定してあげると集計が楽になるよというだけの話ですが、誰かの役に立つと幸いです。
We are hiring!
株式会社HRBrainでは、Power to the peopleを合言葉に多種多様な人事課題を解決するプロダクトを開発・運営しています。
日本の労働環境を良くしてやるぜ!みんなが元気に活躍できる社会にしてやるぜ!
そんな熱い気持ちを持った方、一緒に働きませんか?
皆様のご応募をお待ちしております!